

Nftables to nowy firewall systemu Linux, w którym mechanizm dopasowywania zaimplementowano w postaci podprogramów maszyny wirtualnej kompilowanych do pseudokodu w trakcie korzystania z narzędzia sterującego regułami. Jest to wysokowydajna i bardzo elastyczna aparatura zintegrowana z podsystemem Netfilter. Tworzenie reguł dla tej zapory sieciowej przypomina trochę pisanie programów bazujących na zdarzeniach.
Wprowadzenie
Zapora sieciowa, zwana też ścianą przeciwogniową (ang. firewall), to aktywny element sieciowy, którego zadaniem jest filtrowanie ruchu, czyli zarządzanie wzajemną widocznością stacji sieciowych, co pozwala realizować ochronę infrastruktury lub systemu przed intruzami. Istnieją sprzętowe firewalle, ale mamy też do czynienia z zaporami software’owymi, wbudowanymi w systemy operacyjne. Te ostatnie nie muszą być wcale mniej wydajne niż sprzętowe, a często są znacznie bardziej elastyczne w obsłudze, mają też więcej nowatorskich funkcji. Problem z nimi polega na awaryjności urządzeń, które składają się z wielu komponentów (komputery), a także na tym, że system może być obciążony przez inne realizowane zadania.
Zapora może działać w różnych warstwach modelu ISO/OSI. Spotkamy więc firewalle kontrolujące ruch na poziomie ramek sieciowych (w warstwie łącza danych), na poziomie IP (w warstwie sieciowej), a także na poziomie obsługi protokołów TCP i UDP (w warstwie transportowej). Bardziej zaawansowane zapory, tzw. firewalle aplikacyjne, dokonują inspekcji zawartości pakietów i zajmują się ochroną na poziomie warstwy aplikacyjnej (np. protokołu HTTP czy SMTP). Co do zasady wszystkie firewalle nie różnią się jednak – ich zadaniem jest sprawowanie kontroli nad tym kto z kim i w jaki sposób może się komunikować.
W dużym skrócie i uproszczeniu: warstwa łącza odpowiada za komunikację jednej stacji sieciowej z drugą w obrębie tego samego nośnika (np. segmentu ethernetowego); warstwa sieciowa pozwala wymieniać informacje między systemami operacyjnymi identyfikowanymi w sposób niezależny od medium (np. adresami IP); zaś warstwa transportowa pozwala wskazywać konkretne uruchomione programy działające w komunikujących systemach (np. z użyciem numeru portu).
Warstwa łącza przypomina samochód dostawczy, warstwa sieciowa naczepę zawierającą towary wysyłane pod konkretny adres, a warstwa transportowa paczki oznaczone numerami mieszkań, które mają trafić do odpowiednich lokatorów. Zawartość paczki to już warstwa konkretnego zastosowania, czyli aplikacyjna.
Proces umieszczania zawartości należącej do warstw wyższych w kontenerach warstw niższych nosi nazwę kapsułkowania (ang. encapsulation), a proces odwrotny odkapsułkowania (ang. deencapsulation).
W powyższej analogii z samochodem zapora przypomina osobę, która go zatrzymuje i dokonuje inspekcji. W zależności od kompetencji i uprawnień może to być tylko sprawdzenie dokąd kierowca się udaje (warstwa łącza), zbadanie trasy oraz kondycji naczepy (warstwa sieciowa) czy konkretnych paczek (warstwa transportowa), albo nawet rewidowanie zawartości przesyłek (warstwa aplikacyjna).
Historia
Przypomnijmy sobie jak wyglądało filtrowanie pakietów w kernelu Linux na przestrzeni lat.
Ipfwadm
Linux już w linii 2.0 był wyposażony w prosty mechanizm filtrowania pakietów sieciowych, który nazywał się ipfwadm (IP Firewall Administration). W owym czasie jądro systemowe nie zawierało jeszcze kodu odpowiedzialnego za kontrolowanie ruchu sieciowego, więc korzystanie z tej zapory wiązało się z włączeniem odpowiednich poprawek.
Dzięki ipfwadm i poleceniu o tej samej nazwie administrator mógł ustanawiać reguły w jednym z kilku z góry zdefiniowanych zestawów:
- input (pakiety przychodzące),
- output (pakiety wychodzące z systemu),
- forwarding (pakiety przekazywane między interfejsami sieciowymi),
- accounting (wszystkie pakiety poddawane zliczaniu).
Zapora działała w ten sposób, że każdy pakiet sieciowy był dopasowywany do kolejnych reguł odpowiedniego zestawu (w zależności od tego czy emitowany lokalnie, przekazywany, czy może kierowany do systemu). Filtr rozpoznawał protokoły IP, TCP, UDP oraz ICMP. Umożliwiał też zastosowanie jednej ze strategii ich obsługi:
- przyjmowanie pakietu (accept);
- odrzucanie pakietu (reject);
- ignorowanie pakietu (deny).
Ipfwadm pozwalał również na wprowadzenie prostej translacji adresów źródłowych w trybie jeden do jednego lub wiele do jednego (tzw. maskarada adresu lub podsieci).
Spójrzmy na przykład użycia polecenia, które do zestawu reguł wejściowych dodaje
blokowanie pakietów TCP kierowanych do portu o numerze 80 ze stacji o adresie IP
192.168.0.2:
ipfwadm -I -a deny -P tcp -S 192.168.0.2 -D 0.0.0.0/0 80
ipfwadm -I -a deny -P tcp -S 192.168.0.2 -D 0.0.0.0/0 80
Opcja -a z wartością deny określa tzw. cel reguły (ang. rule target),
natomiast specyfikacje protokołu, adresów i numeru portu to kryteria
dopasowywania (ang. match criteria). z tymi lub podobnymi terminami możemy się
spotkać we wszystkich firewallach.
Kryteriami reguły tej zapory mogły być adresy, numery portów, protokoły, nazwy interfejsów sieciowych i niektóre flagi nagłówków pakietów. Jeżeli administrator chciał uruchomić przekazywanie między portami (ang. port forwarding), musiał korzystać z narzędzia ipautofw działającego w przestrzeni użytkownika lub narzędzia ipportfw korzystającego z mechanizmów kernela.
Ipchains
Wraz z nadejściem kerneli z linii 2.2 pojawił się usprawniony mechanizm kontroli ruchu sieciowego nazwany ipchains (Linux IP Firewalling Chains). Bazował on na kodzie ipfwadm, w którym dokonano usprawnień dotyczących maksymalnych wartości liczników pakietowych czy filtrowania uszkodzonych i szkodliwych nagłówków. Wprowadzono również obsługę większej liczby protokołów sieciowych oraz możliwość odwróconego dopasowywania reguł. Podział na zestawy pozostał taki sam, jednak nazwano je łańcuchami (ang. chains).
Nowością było wprowadzenie drzewiastej struktury reguł. W ipfwadm mieliśmy do czynienia z kilkoma zestawami, do których mogliśmy dodawać reguły filtrujące, natomiast w ipchains pojawiła się możliwość tworzenia własnych. Stąd właśnie zmiana nazwy. Dzięki łańcuchom powtarzalne zestawy filtrów można było umieszczać w osobnych przestrzeniach (łańcuchach użytkownika), a następnie do łańcuchów wbudowanych (tj. input, output czy forward) dodawać reguły, które część ruchu przekażą do jednego z tych pierwszych w celu dalszego przetwarzania.
W związku z możliwością dodawania nowych łańcuchów reguł wprowadzono też opcję korzystania z ich identyfikatorów jako celów – zamiast accept czy reject, celem reguły mogło być przekazanie pakietu do łańcucha utworzonego przez administratora. Dodano też cel o nazwie return, którego użycie sprawia, że następuje powrót do łańcucha nadrzędnego (z którego przekazano kontrolę nad pasującym do danej reguły pakietem). Aby obsługiwać maskaradę IP (ang. IP masquerade) i przezroczystego pośrednika, dodano też cele masq i redirect.
Warto wspomnieć, że w samym narzędziu ipchains dodano również opcję replace, dzięki której można było zastępować reguły bez konieczności ich wcześniejszego kasowania i ponownego dodawania.
Netfilter i iptables
W kernelach z serii 2.4 mieliśmy do czynienia z pewnego rodzaju przełomem w kwestii obsługi sieci. Pojawił się wbudowany w jądro podsystem Netfilter – pierwszy mocno zintegrowany z innymi komponentami sieciowymi klasyfikator z ujednoliconym interfejsem służącym do sterowania mechanizmami kontroli ruchu. Dzięki bliskiej integracji z pozostałymi komponentami sterowania przepływem możliwe stało się stosowanie znacznie bardziej elastycznych i precyzyjnych strategii kontroli.
Gdy Netfilter był gotowy, pojawiło się też – użytkowane do dziś – narzędzie iptables (IP Tables) służące do sterowania ustawieniami filtra pakietowego i mechanizmów translacji adresów sieciowych (ang. Network Address Translation, skr. NAT). Do poprawnej pracy zapory sterowanej tym oprogramowaniem wymagane są odpowiednie moduły jądra (np. x_tables i ip_tables). Żeby sterować filtrami, których obsługę dodano w kernelu później, używa się dodatkowych programów: ip6tables (obsługa IPv6), arptables (filtrowanie ruchu ARP) czy ebtables (filtrowanie na poziomie mostków sieciowych).
Netfilter wprowadza następujące ulepszenia w stosunku do poprzedniego kodu filtrującego:
-
inspekcja stanu (ang. stateful inspection)
na poziomie protokołów (IPv4 i IPv6) oraz aplikacji (IPv4); -
port forwarding nie wymagający usług działających w przestrzeni użytkownika;
-
pełna obsługa NAT (1 do 1 oraz 1 do wielu);
-
integracja z podsystemem jakości usługi (ang. Quality of Service, skr. QoS);
-
integracja z IP sets (bazy adresów IP w wydajnych strukturach).
W samym podsystemie iptables poza wbudowanymi łańcuchami reguł (input, output i forward) pojawiły się dodatkowo prerouting oraz postrouting. Pierwszy łańcuch jest sprawdzany zanim zapadnie decyzja o wyborze trasy pakietu (lub uznania go za przeznaczony dla lokalnego procesu), a drugi wtedy, gdy decyzja taka już zapadła i pakiet ma opuścić system. Jest to możliwe dzięki mechanizmowi tzw. podpięć (ang. hooks). Pozwalają one, aby inne moduły jądra (np. x_tables i ip_tables, czy właśnie nf_tables) rejestrowały w Netfilterze własne funkcje, do których na różnych etapach przetwarzania pakietów i ramek będą kierowane datagramy.
Tabele iptables
W iptables łańcuchy reguł nie są najwyższym poziomem abstrakcji, lecz przynależą do tzw. tabel (ang. tables). Są one zbiorami zawierającymi łańcuchy, które sterują różnymi funkcjami firewalla – np. osobna tabela odpowiada za translację adresów (NAT), a osobna za filtrowanie.
Tabele nie pochodzą z Netfiltera, lecz są sposobem organizowania reguł w iptables, który odzwierciedla odpowiednie etapy „podróży” „pakietu przez stos obsługi sieci. Każda tabela zawiera pewne wbudowane łańcuchy, do których trafiają pakiety pochodzące z zarejestrowanych wcześniej podpięć. Nie należy wyobrażać sobie tabel jako pojedynczych punktów tranzytowych – wiele z nich jest „odwiedzanych” przez dany pakiet częściej niż raz, chociaż w kolejnych momentach trafi on do różnych wbudowanych w daną tabelę łańcuchów.
Ścieżki przepływu
Chociaż tabele i zawarte w nich łańcuchy reguł nie są ściśle związane z podsystemem Netfilter, pozwalają łatwiej zrozumieć, jak dokładnie wygląda klasyfikowanie pakietów. Taki przykład schematu ilustrującego drogę pakietu przez kolejne elementy mechanizmu obsługi sieci można znaleźć w zasobach Wikimedia Commons lub klikając obrazek umieszczony poniżej.
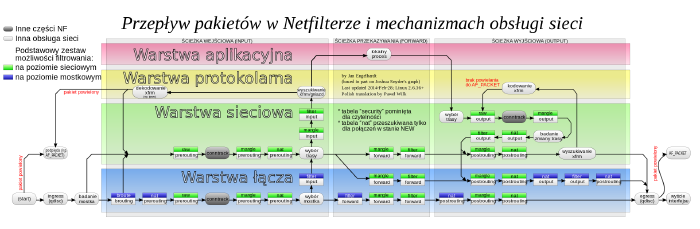
Przypomnijmy sobie funkcje poszczególnych tabel iptables i przypisane do nich wbudowane łańcuchy, do których z użyciem podpięć Netfiltera kierowane są pakiety sieciowe:
- tabela raw:
- łańcuchy: prerouting, output;
- przeznaczenie: filtrowanie tuż przy interfejsach sieciowych;
- tabela filter:
- łańcuchy: input, forward, output;
- przeznaczenie: filtrowanie ruchu sieciowego;
- tabela nat:
- łańcuchy: prerouting, output, postrouting;
- przeznaczenie: translacja adresów (NAT);
- tabela mangle:
- łańcuchy: prerouting, input, forward, output, postrouting;
- przeznaczenie: wprowadzanie zmian w pakietach;
- tabela security:
- łańcuchy: input, forward, output;
- przeznaczenie: współpraca z mechanizmami obowiązkowej kontroli dostępu (ang. Mandatory Access Control, skr. MAC), takimi jak np. SELinux.
Śledzenie i inspekcja stanu
Ponieważ Netfilter wyposażony jest w moduł śledzenia połączeń (ang. connection tracking), każdy badany pakiet będzie oznaczony jednym z abstrakcyjnych stanów w ramach przyporządkowania do wykrytej (bądź nie) sesji komunikacyjnej:
- new – pakiet nawiązujący połączenie;
- established – pakiet należący do ustanowionego połączenia;
- related – pakiet związany z istniejącym połączeniem;
- invalid – pakiet niepoprawny;
- untracked – pakiet nieśledzony.
Dzięki śledzeniu połączeń i znakowaniu pakietów przechodzących przez zestawy reguł, administrator może korzystać z kryteriów decyzyjnych bazujących na stanach.
Oznaczanie pakietów stanami odbywa się zaraz po etapie przetwarzania w łańcuchu prerouting przypisanego do tabeli raw. Jest to też miejsce, gdzie z użyciem specjalnych reguł możemy wpływać na to, jakie moduły śledzące zostaną wykorzystane w konkretnych przypadkach. W praktyce śledzenie połączeń polega nie tylko na uzyskiwaniu informacji z nagłówków (np. pakietów TCP), ale również z przenoszonych w pakietach danych aplikacyjnych.
Przykładem, gdy nie wystarcza samo śledzenie nagłówków warstwy transportowej może być protokół FTP. W jego sesjach korzysta się z dwóch połączeń TCP: jednego do wydawania poleceń, a drugiego do przesyłania plików. Nawiązanie połączenia z portem o numerze 21 i przesłanie żądania pobrania pliku sprawia, że serwer instruuje klienta do jakiego portu musi wykonać połączenie, aby pobrać dane. Aby śledzić tak nawiązywane, nowe połączenie, zaś jego pakietom nadać stan related, zapora sieciowa musi w jakiś sposób poznać treść komunikatu warstwy aplikacyjnej (dialogu klienta z serwerem) i na podstawie wykrytego łańcucha tekstowego (zawierającego numer portu) utworzyć wpis w tabeli śledzenia połączeń. Umożliwia to odpowiedni moduł, który bada zawartość pakietów, jeżeli komunikacja odbywa się na danym porcie.
Cele
W czyniącym użytek z Netfiltera narzędziu iptables możemy mieć do czynienia z celami reguł, których liczba zwiększyła się w stosunku do poprzedników. Podstawowy zestaw wygląda tak:
- accept – przyjęcie pakietu;
- reject – odrzucenie pakietu z poinformowaniem drugiej strony;
- drop – zablokowanie pakietu (w poprzednich: deny);
- queue – przekazanie pakietu do obsługi przez proces użytkownika;
- return – powrót do nadrzędnego łańcucha.
Poza wypisanymi powyżej istnieją też cele specyficzne dla konkretnych tabel i łańcuchów (np. log, mark i mirror), jednak nie będziemy ich teraz omawiać.
Nftables
Nftables (Netfilter Tables) to mechanizm zarządzania filtrami sieciowymi kernela Linux, który ma zastąpić iptables. Projekt został zapoczątkowany w roku 2008 przez Patricka McHardy’ego. Jak sama nazwa wskazuje, nftables również korzysta z podsystemu Netfilter i również mamy do czynienia z tabelami. Kod zapory został stworzony od podstaw i nie bazuje na iptables, chociaż zachowano sposób organizowania reguł w łańcuchy i tabele.
Składniki
Nftables składa się z kilku komponentów:
- podprogramów obsługi w jądrze;
- biblioteki libmnl (do obsługi komunikacji przez gniazda Netlink);
- biblioteki libnftnl (do obsługi API nftables za pośrednictwem libmnl);
- oprogramowania użytkowego (polecenie nft), które zastępuje iptables.
Administratorzy systemów z kernelami Linux w wersji 3.13 i wydaniami późniejszymi powinni mieć już możliwość korzystać z nftables, gdy tylko zainstalują potrzebne biblioteki i narzędzie nft. Niektóre dystrybucje GNU/Linuksa mają to oprogramowanie w repozytoriach, w innych konieczna jest samodzielna kompilacja ze źródeł.
Podobieństwa i różnice
Czym w skrócie różni się nftables od iptables? Uproszczono kernelowy interfejs binarny aplikacji (ang. Application Binary Interface, skr. ABI), „odchudzono” kod (w iptables niektóre fragmenty były po prostu powielane), ulepszono obsługę raportowania błędów, a także wprowadzono całkiem nowy sposób wyrażania i przetwarzania reguł.
Zamiast narzędzi iptables, ebtables, arptables i ip6tables mamy jedno polecenie, które steruje filtrami, a kod w kernelu jest niezależny od protokołów i warstw.
Podobnie jak w iptables wciąż mamy do czynienia z łańcuchami reguł, które są umieszczane w tabelach, jednak nie istnieją łańcuchy wbudowane, na stałe podpięte do Netfiltera. Zamiast tego administrator zapory bazującej na nftables może tworzyć dowolne tabele, a następnie umieszczać w nich dowolne łańcuchy. Te ostatnie mogą być (ale nie muszą) kojarzone z wybranymi punktami ścieżek przepływu.
Generyczne kryteria
Nftables wprowadza do kernela maszynę wirtualną, która odpowiedzialna jest za uruchamianie pseudokodu pochodzącego z przestrzeni użytkownika. Pseudokod ten jest wcześniej wysyłany przez gniazdo typu Netlink z narzędzia nft po dokonaniu interpretacji i kompilacji wprowadzonych reguł. Dzięki temu dodawanie nowych funkcji i strategii filtrowania ruchu jest ułatwione – dodatkowa warstwa abstrakcji pozwala wyeliminować sztywne struktury przechowujące reguły.
Zastosowanie maszyny wirtualnej eliminuje konieczność tworzenia osobnych modułów obsługi dla nowych protokołów czy selektorów kryteriów. Kod w kernelu, który jest odpowiedzialny za badanie kryteriów dopasowywania pakietów, został uproszczony w stosunku do poprzednich mechanizmów (takich jak iptables czy ipchains). Potrafi on odczytywać zawartość (ładunek) pakietu, informacje nagłówkowe i skojarzone z pakietem metadane (np. interfejs wejściowy i wejściowy bądź stan w kontekście śledzenia połączeń), a na bazie tych informacji i zestawu operatorów (arytmetycznych, bitowych i porównywania) mogą być konstruowane bardziej wyszukane filtry.
Co więcej, w przypadku rozwijającego się stosu TCP/IP i coraz liczniejszych miejsc klasyfikacji pakietów w jądrze, filtry bazujące na wykorzystaniu stałych struktur z czasem będą pracowały coraz mniej wydajnie. Wynika to z konieczności przeszukiwania wszystkich miejsc, w których potencjalnie mogą znajdować się klasyfikatory dla każdego przetwarzanego pakietu. Problem ten znika, gdy liczba punktów decyzyjnych zależy od faktycznie użytych reguł, a właśnie z taką sytuacją mamy do czynienia, gdy reguły są pseudoprogramami.
Użycie maszyny wirtualnej oszczędza czas programistów, daje elastyczność administratorowi i sprawia, że w przestrzeni jądra systemowego załadowanych jest jednocześnie mniej modułów z rozszerzeniami, które mogą potencjalnie zawierać usterki. Inspiracją dla takiego podejścia był znany z systemów typu BSD filtr Berekeley Packet Filter (skr. BPF).
Niektórzy zarzucają autorom nftables, że mogli skorzystać z jego kodu lub z wykorzystywanej przezeń biblioteki libpcap zamiast ponownie wymyślać koło. w reakcji na tego typu sugestie podnoszone jest na przykład, że BPF nie obsługuje przyrostowych aktualizacji i ma ograniczony do 64 kilobajtów rozmiar filtrów. Problemów takich nie mają podobno najnowsze wersje silnika BPF++, jednak trzeba przyznać, że BPF nie obsługuje tak specyficznych struktur danych, jakie używane są w nftables (np. omówionych w dalszej części zbiorów).
Przykład obsługi
Spójrzmy na nieco przerobiony diagram ilustrujący ścieżki przepływu ruchu sieciowego:
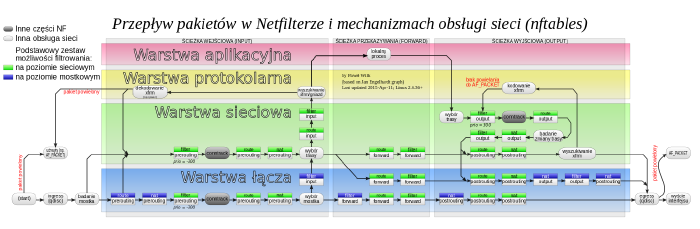
W stosunku do oryginalnej ilustracji zmienione zostało znaczenie prostokątnych figur, które wcześniej symbolizowały tabele i łańcuchy. Zamiast nazw tabel w górnych częściach komponentów klasyfikujących znajdziemy typy łańcuchów, a zamiast nazw łańcuchów wbudowanych tak zwane nazwy podpięć.
W nftables tabele nie są powiązane z etapami przetwarzania i grupują łańcuchy odnoszące się do danej rodziny protokołów (np. IPv4 czy ARP). Łańcuchy reguł zawsze tworzy się samodzielnie, chociaż można ustawiać ich typy. W kilku miejscach widać też dopisek prio i liczbę. Jest to adnotacja o konieczności zdefiniowania odpowiedniego priorytetu dodawanego łańcucha, aby działał zgodnie z oczekiwaniami. W ilustracji pokazano tylko ścieżki dla IPv4 i obsługi mostków sieciowych należące do większego zestawu rodzin protokołów obsługiwanych przez nftables.
Spróbujmy, patrząc na schemat, prześledzić los hipotetycznego pakietu
sieciowego. Załóżmy, że dla niego nasz system będzie tylko miejscem tranzytowym,
tzn. routerem, zaś celem serwer WWW w podsieci usługowej. Załóżmy też, że serwery
w tej podsieci posługują się adresami IP z prywatnych pul, a nasz firewall musi
dokonywać translacji adresów docelowych. Interfejsem wejściowym (publicznym) będzie
eth0, a wyjściowym (połączonym z usługami) eth1.
Przykład ten jest w miarę uniwersalny i ułatwia zrozumienie w jaki sposób działają zapory sieciowe korzystające z podsystemu Netfilter:
-
Na interfejsie eth0 pojawia się ramka zaadresowana do karty sieciowej, a w niej znajduje się pakiet IP przenoszący dane TCP z żądaniem nawiązania połączenia (ustawiona flaga SYN).
-
Podprogram obsługi warstwy łącza danych rezerwuje odpowiednią strukturę na obsługę ramki.
-
Ramka (reprezentująca ją struktura) jest przekazywana do podsystemu QoS (kolejka ingress klasy qdisc).
-
System decyduje czy przekazać ramkę do interfejsu mostkującego (ang. bridge) celem przesłania do innego segmentu. Ponieważ nie mamy do czynienia z taką sytuacją, kończy się obsługa ramki i jej zawartość zostaje odkapsułkowana. Wewnątrz znajduje się pakiet IP, który zostaje przekazany do podprogramu obsługi warstwy sieciowej.
-
Podprogram obsługi warstwy sieciowej rezerwuje odpowiednią strukturę i umieszcza w niej pakiet IP.
-
Dane pakietu dopasowywane są do reguł łańcucha typu filter, obsługiwanych przez niskopriorytetowe podpięcie prerouting (odpowiednik tabeli raw w iptables). W tym miejscu administrator może ustanowić regułę, która wyłączy inspekcję stanu dla pakietów o pewnych właściwościach, może też zdecydować o specjalnym potraktowaniu pakietów w tym zakresie (np. pakietów TCP kierowanych do portu 2111 tak, jakby przenosiły dane protokołu FTP).
-
Jeżeli pakiet nie został odrzucony lub zignorowany, trafia do podsystemu śledzenia połączeń (conntrack). Tam, na podstawie analizy jego nagłówka i danych, a także porównania z systemową tabelą połączeń, zostaje odpowiednio oznaczony, a w systemowej tabeli pojawia się lub zostaje zaktualizowany wpis o połączeniu. Wykorzystywane są tu niektóre znaczniki sterujące śledzeniem, jeżeli były wcześniej ustawione.
-
Pakiet trafia do łańcucha typu route przez podpięcie prerouting (odpowiednik tabeli mangle z iptables), gdzie może być zmieniony, jeżeli określono to regułami.
-
Pakiet trafia do łańcucha typu nat przez podpięcie prerouting, gdzie może być zmieniony jego adres docelowy. Znajdzie się tu reguła translacji sieciowych adresów docelowych (ang. Destination Network Address Translation, skr. DNAT), która mówi, żeby podmienić adres IP pakietu z publicznego na prywatny, przypisany do serwera WWW w chronionej podsieci. W tym przypadku również utrzymywana jest w systemie odpowiednia baza, aby mechanizmy obsługi NAT wiedziały jak modyfikować pakiety stanowiące odpowiedzi na przekształcone.
-
Następuje podjęcie decyzji o routingu na podstawie tablic trasowania (ang. routing tables). Podprogram obsługi wykrywa, że pakiet nie jest przeznaczony dla lokalnej stacji i że należy przesłać go dalej innym interfejsem sieciowym.
-
Pakiet trafia do łańcucha typu route przez podpięcie forward, gdzie może być zmieniony, jeżeli określono to regułami.
-
Pakiet trafia do łańcucha typu filter przez podpięcie forward, gdzie znajdują się reguły ochronne.
-
Pakiet trafia do łańcucha typu route przez podpięcie postrouting, gdzie może być zmieniony, jeżeli określono to regułami.
-
Pakiet trafia do łańcucha typu nat przez podpięcie postrouting, gdzie może być dokonana translacja sieciowego adresu źródłowego (ang. Source Network Address Translation, skr. SNAT). Nie trafia na żadną pasującą regułę, więc nie zostaje zastosowany NAT.
-
Pakiet trafia do podprogramu obsługi reguł XFRM, odpowiedzialnego za przekształcanie datagramów. Tu dokonywane są np. zmiany zawartości i nagłówków, jeżeli wykorzystywany jest zbiór protokołów ochronnych IP Security (ang. Internet Protocol Security, skr. IPSec). Ponieważ w systemie nie ma określonych zasad XFRM, więc pakiet jest przekazywany dalej w niezmienionej formie.
-
Pakiet jest kapsułkowany w ramkę zaadresowaną do stacji sieciowej będącej serwerem WWW.
-
Ramka trafia do kolejki egress klasy qdisc podsystemu QoS.
-
Ramka trafia do interfejsu sieciowego
eth1, gdzie jest transmitowana w medium do docelowej stacji sieciowej.
Architektura
Najogólniejszymi (zawierającymi pozostałe) strukturami nftables są tabele (ang. tables). Służą do przechowywania łańcuchów reguł i zbiorów. O zbiorach powiemy w dalszej części, a teraz warto wspomnieć, że łańcuchy reguł nie różnią się pod względem przeznaczenia od tych, które znamy z iptables czy ipchains – pozwalają grupować reguły.
Pakiety sieciowe z podsystemu Netfilter dzięki podpięciom trafiają do wybranych przez administratora łańcuchów, a w nich są przetwarzane przez każdą kolejną regułę, aż do momentu, gdy w którejś dojdzie do decyzji, że nie powinny być już analizowane.
Funkcją reguł jest badanie, czy pakiety można dopasować do kryteriów zawartych w tzw. wyrażeniach dopasowujących. W przypadku pozytywnego dopasowania wykonywane są umieszczone w regułach akcje, które wyrażane są odpowiednimi deklaracjami (ang. statements). Istnieje kilka rodzajów akcji, a najpopularniejsze dotyczą podejmowania decyzji w sprawie dalszego losu pakietu. Decyzje nazywane są też werdyktami, a ich symboliczny zapis deklaracjami decyzyjnymi.
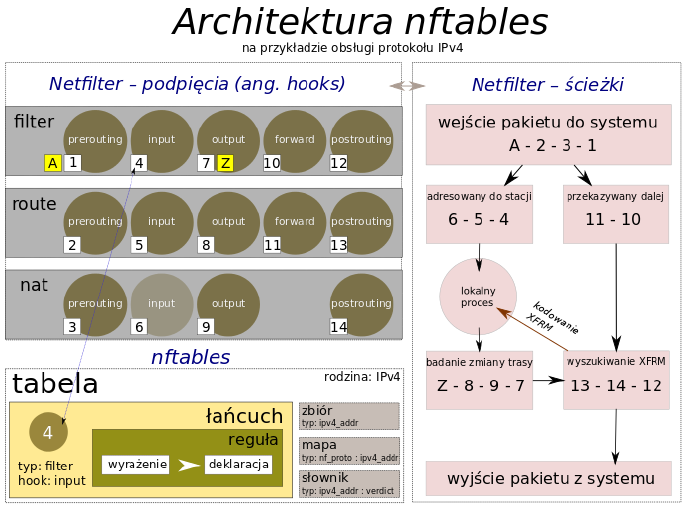
Schemat ilustrujący architekturę nftables w kontekście ścieżek przepływu i podpięć mechanizmu Netfilter
Powyższy schemat pokazuje, w jaki sposób podpięcia podsystemu Netfilter są integrowane z mechanizmami nftables. Po prawej stronie znajdziemy możliwe ścieżki przepływu pakietów przez filtr Netfilter, a umieszczone tam identyfikatory numeryczne (1–14) i literalne (A i Z) są potencjalnymi punktami wykonywania podpięć do kanałów Netfiltera, w których pojawiają się pakiety bądź ramki. Możliwe podpięcia znajdziemy po lewej stronie grafiki i odpowiadają one momentom „podróży” pakietów przez kolejne filtry kernela.
W lewym dolnym rogu mamy przykładową tabelę nftables wykorzystującą podpięcie pod wejściowy łańcuch tabeli filter Netfiltera. Do tabeli tej trafią więc pakiety adresowane do stacji (po uprzednim przejściu m.in. przez tabele nat i route podsystemu Netfilter; dokładna ścieżka potencjalnych podpięć: A, 2, 3, 1, 6, 5, 4). Od decyzji nftables i obecnych tam reguł będzie zależał dalszy los pakietu, tzn. to, czy zostanie on dostarczony do procesu działającego na lokalnej maszynie.
Warto mieć na uwadze, że predefiniowane tabele i łańcuchy filtra Netfilter są konstrukcjami różnymi od tak samo nazywanych w nftables.
Tabele
Tabela (ang. table) jest kontenerem zawierającym łańcuchy reguł i zbiory. Ma nazwę i przypisaną rodzinę protokołu (ang. protocol family). Rozróżnienie pod względem rodzin protokołów jest konieczne, ponieważ mamy do czynienia z odmiennymi sposobami adresowania, możliwymi do zastosowania testami i różnymi podpięciami podsystemu Netfilter.
Możliwe rodziny protokołów to:
-
ip – protokół internetowy w wersji 4
(ang. Internet Protocol version 4, skr. IPv4); -
ip6 – protokół internetowy w wersji 6
(ang. Internet Protocol version 6, skr. IPv6); -
inet – protokół internetowy
(hybryda łącząca IPv4 i IPv6); -
arp – protokół odwzorowywania adresów
(ang. Address Resolution Protocol, skr. ARP); -
bridge – protokoły związane z mostkami sieciowymi (ang. network bridges).
Łańcuchy reguł
Łańcuch reguł (ang. rule chain) to struktura zawierająca uszeregowane reguły, których zadaniem jest analiza przepływających pakietów. Istnieją dwa rodzaje łańcuchów:
- łańcuchy zwykłe (ang. regular chains) i
- łańcuchy bazowe (ang. base chains).
Te pierwsze mogą być używane w celu bardziej przejrzystej organizacji reguł – można wysyłać do nich pakiety korzystając z akcji decyzyjnej reguł o nazwie jump.
Łańcuchy bazowe służą do przechwytywania pakietów ze wskazanych miejsc ścieżki przepływu Netfiltera. Tworząc je należy podać:
-
typ łańcucha, którym może być:
- filter – oznaczający łańcuch filtrujący pakiety;
- nat – oznaczający łańcuch służący translacji adresów (NAT);
- route – oznaczający łańcuch do zmiany tras pakietów (odpowiednik mangle w iptables);
-
podpięcie – określające miejsce mechanizmu Netfilter, w które łańcuch ma być włączony:
- prerouting – pakiety przed podjęciem decyzji o trasowaniu (wszystkie pakiety wchodzące do systemu);
- input – pakiety kierowane do tego systemu;
- forward – pakiety dla innego systemu, dla których ten jest routerem;
- output – pakiety pochodzące z tego systemu;
- postrouting – pakiety po podjęciu decyzji o routingu (wszystkie pakiety opuszczające system);
-
priorytet – będący liczbą całkowitą decydującą o punkcie podpięcia do podsystemu Netfilter (domyślnie 0).
W przypadku tabel obsługujących protokół ARP możemy używać tylko podpięć input i output, a w przypadku rodziny bridge wyłącznie input, output i forward.
Typy danych
Podczas wyrażania parametrów reguł umieszczonych w łańcuchach korzysta się z określonych i zrozumiałych przez nftables typów danych (ang. data types). Ich symboliczna reprezentacja zostanie w procesie kompilacji zmieniona w odpowiednie struktury pseudokodu.
Pamięciowe obiekty większości typów mają stały rozmiar, ale zdarzają się takie, dla których obszar pamięci jest przydzielany dynamicznie (np. typy złożone bądź łańcuchy tekstowe).
Typy podstawowe
-
numeryczne:
- bitmask – maska bitowa, np.
0x00000002,0x01,established; - integer – liczba całkowita, np.
123; - mark – znacznik pakietu, np.
1024;
- bitmask – maska bitowa, np.
-
tekstowe:
- string – łańcuch tekstowy, np.
lancuchlub"lancuch";
- string – łańcuch tekstowy, np.
-
związane z datą i czasem:
- time – czas;
-
adresowe i identyfikacyjne:
- ipv4_addr – adres IPv4, np.
192.168.0.1– możliwa jest też notacja dziesiętna, ósemkowa i heksadecymalna (również z kropkami), jak i podanie nazwy DNS stacji, która zostanie zamieniona na adres przez zapytanie wysłane do resolvera; - ipv6_addr – adres IPv6, np.
fe80::122:fbff:facd:e48e; - ll_addr – adres warstwy łącza danych, np.
10:aa:be:ce:de:ef; - inet_service – usługa internetowa (numer portu), np.
22,ssh;
- ipv4_addr – adres IPv4, np.
-
protokolarne:
- inet_proto – protokół internetowy warstwy transportowej, np.
tcp; - nf_proto – protokół warstwy sieciowej;
- pkt_type – typ pakietu;
- inet_proto – protokół internetowy warstwy transportowej, np.
-
specyficzne dla TCP:
- tcp_flag – flaga TCP, np.
syn;
- tcp_flag – flaga TCP, np.
-
specyficzne dla ICMP:
- icmp_code – kod komunikatu ICMP, np.
net-unreach; - icmp_type – typ komunikatu ICMP, np.
echo-request; - icmpx_code – generyczny kod komunikatu ICMP, np.
no-route;
- icmp_code – kod komunikatu ICMP, np.
-
specyficzne dla Ethernetu:
- ether_type – typ protokołu (lub rozmiar, gdy <= 1500);
- ether_addr – adres MAC, np.
10:aa:be:ce:de:ef;
-
specyficzne dla śledzenia połączeń:
- ct_dir – kierunek połączenia;
- ct_label – etykieta połączenia;
- ct_state – stan połączenia;
- ct_status – status połączenia;
-
specyficzne dla trasowania:
- realm – dziedzina trasowania (32‑bitowa liczba lub nazwa z
/etc/iproute2/rt_realms);
- realm – dziedzina trasowania (32‑bitowa liczba lub nazwa z
-
specyficzne dla podsystemu Traffic Control:
- tc_handle – uchwyt podsystemu kontroli przepływu;
-
decyzyjne:
- verdict – decyzja, np.
jump;
- verdict – decyzja, np.
-
specyficzne dla IPv6:
- icmpv6_type – typ komunikatu ICMP dla IPv6, np.
packet-too-big; - mh_type – typ nagłówka mobilnościowego;
- icmpv6_type – typ komunikatu ICMP dla IPv6, np.
-
specyficzne dla interfejsów sieciowych:
- iface_index – numer kolejny interfejsu (liczba 32‑bitowa lub nazwa);
- iface_type – typ interfejsu (16‑bitowa liczba);
- ifname – nazwa interfejsu (16‑bajtowy łańcuch tekstowy);
- devgroup – grupa urządzeń;
-
specyficzne dla ARP:
- arphrd – znacznik typu urządzenia ARP;
- arp_op – typ operacji ARP;
-
systemowe:
- uid – identyfikator użytkownika (32‑bitowa liczba lub nazwa);
- gid – identyfikator grupy (32‑bitowa liczba lub nazwa);
-
specyficzne dla DCCP:
- dccp_pkttype – typ pakietu DCCP.
Typy można też podzielić ze względu na obszary, w których znajdują zastosowanie (w nawiasach podano nazwę pliku z kodem źródłowym, w którym znajdują się definicje):
-
ogólny (
datatype.c):
invalid,verdict,nf_proto,bitmask,integer,string,ll_addr,ipv4_addr,ipv6_addr,inet_proto,inet_service,mark,icmp_code,icmpv6_code,icmpx_code,time; -
obsługa śledzenia połączeń (
ct.c):
ct_state,ct_dir,ct_status,ct_label; -
metadane (
meta.c):
realm,tc_handle,iface_index,iface_type,uid,gid,pkt_type,devgroup; -
obsługa protokołów (
proto.c):
icmp_type,tcp_flag,dccp_pkttype,icmpv6_type,arp_op,ether_addr,ether_type; -
obsługa nagłówków rozszerzeń (
exthdr.c):
mh_type.
Typy złożone
Nftables wyposażono w wydajne struktury służące do przechowywania danych: słowniki, zbiory i mapy danych. Są to typy złożone, w których strukturach przechowywać można dane innych typów. Podczas ich tworzenia konieczne jest określanie elementy jakich konkretnie typów danych będą wchodziły w ich skład.
Zbiory
Zbiory (ang. sets) to kolekcje elementów, które pozwalają przechowywać i wyszukiwać informacje, na przykład adresy, numery portów, nazwy interfejsów i inne dane znanych typów. Danych tych można następnie używać jako kryteriów dopasowania lub parametrów akcji.
W zależności od rodzaju danych zbiory mogą wewnętrznie korzystać z drzew czerwono-czarnych (ang. red-black trees) lub tablic mieszających (ang. hash tables), żeby zapewniać szybki dostęp do elementów i dokonywać automatycznej kompresji większych zestawów. Gdy na przykład przechowywane i dopasowywane mają być informacje dotyczące przestrzeni adresowych z uwzględnieniem zakresów, można wykorzystać strukturę drzewiastą, a gdy między elementami nie ma hierarchicznej relacji, tablicę mieszającą.
Istnieją zbiory anonimowe (ang. anonymous sets) oraz zbiory nazwane (ang. named sets). Te pierwsze są osadzone w regułach, a drugie mogą być w nich użytkowane, lecz są zdefiniowane osobno i identyfikowane podaną nazwą.
Jeżeli usuwana jest reguła, w której osadzono anonimowy zbiór, to przestaje on istnieć. Poza tym nie można zmieniać zawartości takich zbiorów po ich utworzeniu, chociaż można się do nich odwoływać z użyciem przydzielonych przez kernel identyfikatorów.
Przykład nazwanego zbioru używanego do dopasowywania:
set zbior {
type ipv4_address
elements = { 127.0.0.1, 172.0.0.1 }
}
set zbior {
type ipv4_address
elements = { 127.0.0.1, 172.0.0.1 }
}
Obsługiwane typy elementów, które mogą wchodzić w skład zbiorów to:
ipv4_addr– adresy IPv4;ipv6_addr– adresy IPv6;ether_addr– adresy ethernetowe;inet_proto– rodzaje protokołów internetowych;inet_service– usługi internetowe (np. numery portów);mark– znaczniki pakietowe.
Mapy
Mapy (ang. maps) – zwane też mapami danych (ang. data maps), gdy nie zawierają danych decyzyjnych, służą się do przechowywania wartości (ang. values) przyporządkowanych do podanych kluczy (ang. keys). Mapy wewnętrznie korzystają ze zbiorów, a programiści obiektowi mogą wyobrażać sobie mapę jako klasę pochodną zbioru. Mapy, podobnie jak zbiory, mogą być mapami anonimowymi (ang. anonymous maps) lub mapami nazwanymi (ang. named maps).
Przykład mapy pomocnej w wyrażeniu sposobu translacji adresów z przekierowaniem portów:
map kierownik {
type inet_service : ipv4_addr;
80 : 192.168.0.2,
8888 : 172.30.1.8
}
map kierownik {
type inet_service : ipv4_addr;
80 : 192.168.0.2,
8888 : 172.30.1.8
}
Możemy zauważyć, że deklaracja typu zawiera dwie nazwy oddzielone dwukropkiem. Pierwsza określa typ kluczy, a druga typ kojarzonych z nimi wartości.
Słowniki
Słowniki (ang. dictionaries), zwane w nftables również mapami decyzyjnymi (ang. verdict maps, skr. vmaps), pozwalają przyporządkowywać akcje do kluczy. Wewnętrznie słowniki korzystają ze zbiorów do strukturalizowania danych i są specyficznym rodzajem map. Programiści obiektowi mogą wyobrażać sobie słownik jako egzemplarz mapy, w którym typem wartości jest verdict (decyzja). Słowniki mogą być słownikami anonimowymi (ang. anonymous dictionaries) lub słownikami nazwanymi (ang. named dictionaries).
Przykład anonimowego słownika używanego do warunkowania podjęcia akcji:
map {
type inet_proto : verdict;
elements = { tcp : jump obsluga-tcp, udp : jump obsluga-udp }
}
map {
type inet_proto : verdict;
elements = { tcp : jump obsluga-tcp, udp : jump obsluga-udp }
}
Mapy decyzyjne a mapy danych
Mapa decyzyjna (słownik) jest również mapą, jednak przedstawiona została jako osobna
struktura z tej przyczyny, że bywa często stosowana do wyrażenia pewnych decyzji
przez użycie specyfikatora vmap umieszczanego w wyrażeniach. Zamiast osobnej
(w sensie składniowym) deklaracji mamy wtedy do czynienia z decyzjami zawartymi
bezpośrednio w mapie.
Interwały (zakresy)
Interwały (ang. intervals) pozwalają określać zakresy (ang. ranges), czyli
zbiory wartości z pewnych przedziałów. Wyrażane są zapisem: wartość-wartość i mogą
pojawiać się zarówno w miejscach, gdy oczekiwane jest podanie pewnych danych, jak
i jako elementy zbiorów czy map. Najczęstszym ich zastosowaniem jest używanie ich do
oznaczania zakresów adresacji i numerów portów.
Przykłady zakresów:
192.168.0.1-192.168.0.1001-1024.
Przykład zakresu w mapie decyzyjnej:
map {
type ipv4_addr : verdict;
elements = {
192.168.0.1-192.168.0.100 : jump serwery,
192.168.0.101-192.168.0.255 : drop
}
}
map {
type ipv4_addr : verdict;
elements = {
192.168.0.1-192.168.0.100 : jump serwery,
192.168.0.101-192.168.0.255 : drop
}
}
Uwaga: Gdy interwały o nakładających się zakresach są kluczami mapy, to podczas przeszukiwania wybrany zostanie ten element, którego zakres jest bardziej precyzyjny (węższy). Jeżeli oba nakładające się zakresy są takiej samej długości, a przypisane akcje różnią się, zwrócony zostanie błąd.
Reguły
Reguły (ang. rules) w nftables składają się z wyrażeń i deklaracji. Jeżeli badany pakiet charakteryzuje się właściwościami pasującymi do przedstawionych wyrażeniem kryteriów, to zostaje wykonana zadeklarowana akcja lub akcje. Deklaracja jest elementem składniowo‑gramatycznym, natomiast akcja czynnością, która zostanie powzięta.
Wyrażenia
Wyrażenia (ang. expressions), jak sama nazwa wskazuje, pozwalają wyrażać pewne wartości. Wartości te mogą być stałe (np. adresy sieciowe czy numery portów), albo wyliczone (np. dane powstałe wcześniej w toku badania zawartości pakietu bądź informacje kernela dotyczące trasowania lub śledzenia połączeń). Każda stała wartość wyrażenia ma jakiś znany typ danych, podobnie jak każda wartość wyrażenia, które zostało już obliczone.
Wyrażeń używa się przede wszystkim w regułach, aby konstruować kryteria dopasowywania (ang. match criteria) pakietów, jednak znajdują one również zastosowanie w dookreślaniu akcji reguł, np. podczas parametryzowania translacji adresów.
Wyrażenia mogą składać się z innych wyrażeń, a ich spoiwem są wtedy odpowiednie operatory. Powstają wtedy wyrażenia złożone (ang. combined expressions).
Możemy wyróżnić kilka rodzajów wyrażeń:
-
wyrażenia podstawowe (ang. primary expressions):
- wyrażenia stałe (ang. constant expressions);
- wyrażenia niestałe (ang. non‑constant expressions):
- wyrażenia metadanowe (ang. meta data expressions);
- wyrażenia ładunkowe (ang. payload expressions);
- wyrażenia śledzenia połączeń (ang. conntrack expressions);
-
wyrażenia złożone (ang. combined expressions):
- wyrażenia bitowe (ang. bitwise expressions);
- wyrażenia przedrostkowe (ang. prefix expressions);
- wyrażenia listowe (ang. list expressions);
- wyrażenia zakresowe (ang. range expressions);
- wyrażenia złączeniowe (ang. concat expressions);
- wyrażenia wieloznaczne (ang. wildcard expressions);
-
wyrażenia relacyjne (ang. relational expressions),
- podstawowe wyrażenia relacyjne (ang. basic relational expressions);
- porównania flag (ang. flag comparisons).
Wyrażenia podstawowe
Wyrażenia podstawowe to takie wyrażenia, które opisują pojedynczą porcję danych. Mogą być stałe lub dynamiczne (niestałe). Te pierwsze są podawane na etapie konstruowania wyrażeń, a drugie pozyskiwane w trakcie pracy.
Wyrażenia stałe
Wyrażenia stałe to przedstawione z użyciem typów danych niezmienne wartości, np. wyrażone numerycznie adresy IP czy flagi TCP. Wyrażenia tego typu są obliczane w przestrzeni użytkownika (w oprogramowaniu odpowiedzialnym za przetwarzanie i kompilację reguł).
Niektóre ze stałych wyrażeń mają symboliczne odpowiedniki, aby możliwe było bardziej przejrzyste reprezentowanie pewnych ustalonych wartości, np. usług internetowych z użyciem nazw a nie znanych numerów portów. Poniższa tabela przedstawia stałe symboliczne wyrażenia z podziałem na rodziny zastosowań:
| Protokół / sekcja | Typ danych | Symbole stałych |
|---|---|---|
| ARP | arp_op | request,
reply, rrequest, rreply,
inrequest, inreply, nak |
iface_type | ether, ppp
, ipip, ipip6, loopback, sit,
ipgre | |
| DCCP | dccp_pkttype | request,
response, data, ack, dataack,
closereq, close, reset, sync,
syncack |
| Ethernet | ether_type | ip,
arp, ip6, vlan |
| CT | ct_dir | original,
reply |
ct_state | invalid,
new, established, related,
untracked | |
ct_status | expected,
seen-reply, assured, confirmed,
snat, dnat, dying | |
| ICMPv4 | icmp_type | echo_reply,
destination-unreachable, source-quench,
redirect, echo-request, time-exceeded,
parameter-problem, timestamp-request,
timestamp-reply, info-request, info-reply,
address-mask-request, address-mask-reply |
icmp_code | net-unreachable,
host-unreachable, prot-unreachable,
port-unreachable, net-prohibited,
host-prohibited, admin-prohibited | |
| ICMPv6 | no-route,
admin-prohibited, addr-unreachable,
port-unreachable | |
icmpv6_type | destination-unreachable,
packet-too-big, time-exceeded, param-problem,
echo-request, echo-reply, mld-listener-query,
mld-listener-report, mld-listener-reduction,
nd-router-solicit, nd-router-advert,
nd-neighbor-solicit, nd-neighbor-advert,
nd-redirect, router-renumbering | |
| ICMP | icmpx_type | port-unreachable,
admin-prohibited, no-route,
host-unreachable |
| IP | nf_proto | ipv4,
ipv6 |
pkt_type | unicast,
broadcast, multicast, ipgre | |
| IPv6 | mh_type | binding-refresh-request,
home-test-init, careof-test-init, home-test,
careof-test, binding-update,
binding-acknowledgement, binding-error,
fast-binding-update, fast-binding-acknowledgement,
fast-binding-advertisement, experimental-mobility-header,
home-agent-switch-message |
| TCP | tcp_flag | fin,
syn, rst, psh, ack,
urg, ecn, cwr |
Wyrażenia niestałe
Wyrażenia metadanowe
Wyrażenia metadanowe pozwalają odczytywać metadane badanego pakietu. Informacje te nie pochodzą bezpośrednio z datagramu, ale mogą być pochodną zawartych tam danych.
Każde wyrażenie metadanowe składa się ze słowa kluczowego meta, po którym następuje
słowo kluczowe (ang. keyword) określające konkretny parametr.
| Parametr | Typ danych | Opis |
|---|---|---|
length | integer
(32 bity) | długość pakietu |
priority | priorytet | |
protocol | ether_type | przenoszony protokół |
mark | mark | znacznik pakietowy |
iif | iface_index | numer kolejny interfejsu wejściowego |
iiftype | iface_type | sprzętowy typ interfejsu wejściowego |
oif | iface_index | numer kolejny interfejsu wyjściowego |
oifname | string | nazwa interfejsu wyjściowego |
oiftype | iface_type | sprzętowy typ interfejsu wyjściowego |
skuid | uid | systemowy identyfikator użytkownika dla gniazda |
skgid | gid | systemowy identyfikator grupy dla gniazda |
rtclassid | realm | dziedzina trasowania |
Wyrażenia metadanowe mogą być doprecyzowane (ang. qualified) lub
niedoprecyzowane (ang. unqualified). Te pierwsze korzystają ze składni
zawierającej słowo kluczowe meta, a w przypadku tych drugich narzędzie nft
dedukuje, że chodzi o takie wyrażenie, jeżeli podano po prostu należący do niego
unikatowy klucz.
Wyrażenia ładunkowe
Dzięki wyrażeniom ładunkowym możemy dokonywać testów zawartości danych transmitowanych w pakiecie. Warto zauważyć, że powszechną definicją ładunku (ang. payload) pakietu jest ta jego część, w której transmitowane są właściwe dane (z pominięciem metadanych czy danych nagłówkowych). Terminologia zastosowana przez autorów nftables na pierwszy rzut oka różni się od powszechnie przyjętej, bo w wyrażeniach widzimy odniesienia właśnie do danych w nagłówkach. Warto jednak pamiętać, że w przypadku generycznych metod pozyskiwania danych z pakietów i ramek mamy do czynienia z operowaniem na najniższym poziomie i dostępem do ładunków, którymi mogą być całe pakiety protokołów wyższych warstw (włączając ich nagłówki).
Wyrażenia ładunkowe różnią się ze względu na rodzaj obsługiwanego protokołu wyższej warstwy i konstruując je należy podać dwa słowa kluczowe – pierwsze określające protokół przenoszonych danych, a drugie nazwę konkretnego parametru, którego wartość ma być pobrana.
| Protokół | Parametr | Typ danych | Opis |
|---|---|---|---|
arp(ARP) | htype | integer
(16 bitów) | typ sprzętu |
ptype | ether_type | typ protokołu | |
hlen | integer
(8 bitów) | długość adresu sprzętowego | |
plen | integer
(8 bitów) | długość adresu protokolarnego | |
op | arp_op | operacja | |
dccp(DCCP) | sport | inet_service | port źródłowy |
dport | port docelowy | ||
ether(Ethernet) | saddr | ether_addr | adres źródłowy |
daddr | adres docelowy | ||
type | ether_type | typ przenoszonego protokołu | |
ip(IPv4) | version | integer
(4 bity) | wersja nagłówka IP |
hdrlength | integer
(16 bitów) | długość nagłówka IP | |
length | całkowita długość pakietu | ||
id | identyfikator pakietu IP | ||
frag-off | przesunięcie fragmentu | ||
checksum | suma kontrolna nagłówka IP | ||
ttl | integer
(8 bitów) | czas trwania pakietu (ang. Time to live, skr. TTL) | |
tos | integer (6 bitów) | pole typu usługi (ang. Type of Service, skr. ToS) | |
protocol | inet_proto | protokół wyższej warstwy | |
saddr | ipv4_addr | adres źródłowy | |
daddr | adres docelowy | ||
ip6(IPv6) | version | integer (4 bity) | wersja nagłówka IP |
priority | priorytet | ||
flowlabel | integer
(20 bitów) | etykieta przepływu | |
length | integer
(16 bitów) | długość ładunku | |
nexthdr | inet_proto | protokół następnego nagłówka (zwykle kapsułkowanego pakietu) | |
hoplimit | integer
(8 bitów) | maksymalna liczba przeskoków | |
saddr | ipv6_addr | adres źródłowy | |
daddr | adres docelowy | ||
ah(AH) | nexthdr | inet_proto | protokół następnego nagłówka (zwykle kapsułkowanego pakietu) |
hdrlength | integer
(8 bitów) | długość nagłówka AH | |
reserved | integer
(16 bitów) | przestrzeń zarezerwowana | |
spi | integer
(32 bity) | indeks parametrów bezpieczeństwa (ang. Security Parameter Index, skr. SPI) | |
sequence | numer sekwencyjny | ||
esp(ESP) | spi | integer (32 bity) | indeks parametrów bezpieczeństwa (ang. Security Parameter Index, skr. SPI) |
sequence | numer sekwencyjny | ||
ipcomp(IPcomp) | nexthdr | inet_proto | protokół następnego nagłówka (zwykle kapsułkowanego pakietu) |
flags | integer
(8 bitów) | flagi | |
cfi | integer
(16 bitów) | indeks parametrów kompresji (ang. Compression Parameter Index, skr. CFI) | |
tcp(TCP) | sport | inet_service | port źródłowy |
dport | port docelowy | ||
sequence | integer
(32 bity) | numer sekwencyjny | |
ackseq | numeru potwierdzenia | ||
doff | integer
(4 bity) | przesunięcie danych | |
reserved | integer
(6 bitów) | przestrzeń zarezerwowana | |
flags | tcp_flags | flagi | |
window | integer
(16 bitów) | szerokość okna | |
checksum | suma kontrolna | ||
urgptr | wskaźnik danych priorytetowych | ||
sctp(SCTP) | sport | inet_service | port źródłowy |
dport | port docelowy | ||
vtag | integer
(32 bity) | znacznik weryfikacyjny | |
checksum | suma kontrolna | ||
udp(UDP) | sport | inet_service | port źródłowy |
dport | port docelowy | ||
length | integer
(16 bitów) | długość całkowita pakietu | |
checksum | suma kontrolna | ||
udplite(UDP‑lite) | sport | inet_service | port źródłowy |
dport | port docelowy | ||
cscov | integer
(16 bitów) | pokrycie sumy kontrolnej | |
checksum | suma kontrolna | ||
vlan(VLAN) | id | integer
(12 bitów) | identyfikator (VID) |
cfi | integer
(1 bit) | wskaźnik formatu kanonicznego (ang. Canonical Format Indicator, skr. CFI) | |
pcp | integer (3 bity) | punkt kodowy priorytetu (ang. Priority Code Point, skr. PCP) | |
type | ether_type | typ przenoszonego protokołu |
Wyrażenia śledzenia połączeń
Wyrażenia związane z podsystemem śledzenia połączeń pozwalają na dostęp do
metadanych, dzięki którym można określić stany pakietów w kontekście ich
przyporządkowania do sesji komunikacyjnych. Składają się ze słowa kluczowego ct
i kolejnego słowa kluczowego, które określa konkretny parametr.
| Parametr | Typ danych | Opis |
|---|---|---|
state | ct_state | stan połączenia |
direction | ct_dir | kierunek połączenia |
status | ct_status | status połączenia |
mark | mark | znacznik pakietowy |
expiration | time | czas ważności połączenia |
helper | string | pomocniczy moduł obsługi połączenia |
l3proto | nf_proto | protokół warstwy sieciowej |
saddr | ipv4_addripv6_addr | adres źródłowy |
daddr | adres docelowy | |
protocol | inet_proto | protokół warstwy transportowej |
proto-src | inet_service | identyfikacja źródła warstwy transportowej |
proto-dst | identyfikacja celu warstwy transportowej |
Wyrażenia złożone
Wyrażenia złożone, jak sama nazwa mówi, składają się z innych wyrażeń i operacji, które nadają im sens obliczeniowy.
Wyrażenia operacji bitowych
Wyrażenia operacji bitowych pozwalają przeprowadzać działania na pojedynczych bitach wartości podanych wyrażeń. Składają się z operatora i dwóch operandów, które powinny być wartościami o typach numerycznych:
| Operator | Znaczenie |
|---|---|
& | koniunkcja
bitowa (iloczyn logiczny, operacja AND) |
| | | alternatywa bitowa (suma logiczna, operacja OR) |
^ | bitowa różnica
symetryczna (logiczna alternatywa wykluczająca, operacja XOR) |
Wyrażenia przedrostkowe
Dzięki wyrażeniom przedrostkowym można zapisywać na przykład prefiksy sieci. Składają
się z dwóch argumentów oddzielonych znakiem ukośnika (/). Wartość pierwszego
argumentu powinna być adresem lub typem numerycznym, a drugiego liczbą całkowitą
określającą liczbę bitów pierwszego, które są istotne (np. powinny być pozostawione
podczas wyliczania części adresu IP wskazującego na sieć).
Wyrażenia zakresowe
Wyrażenia zakresowe obsługiwane są przez interwały omówione przy okazji
przedstawiania typów złożonych. Składają się z dwóch argumentów typu numerycznego
(wyrażeń wartościowanych do typu numerycznego) oddzielonych dywizem (-).
Wyrażenia listowe
Wyrażenia listowe, zwane także listami wyrażeń są listami kolejnych wyrażeń
oddzielonych znakami przecinka (,). Używane są na przykład do zakomunikowania wielu
flag, które muszą być jednocześnie ustawione (w tzw. dopasowaniach flag, które
opiszemy w dalszej części).
Wyrażenia złączeniowe
Dzięki wyrażeniom złączeniowym możliwe jest tworzenie wyrażeń, których wartości zostaną połączone w jeden łańcuch. Może być to przydatne na przykład podczas tworzenia kluczy dla zbiorów odzwierciedlających wielowymiarowe struktury lub podczas dopasowywania sąsiadujących pól nagłówków.
Wyrażenie złączeniowe można tworzyć na bazie dwóch lub więcej wyrażeń, między którymi
znajduje się znak kropki (.).
Wyrażenia wieloznaczne
Wyrażenia wieloznaczne pozwalają określać dane domyślne podczas korzystania ze
słowników. Używa się w nich symbolu gwiazdki (*), który oznacza, że dany rekord
pasuje do dowolnych danych wejściowych (jeżeli żaden inny nie został odnaleziony
w strukturze).
Wyrażenia relacyjne
Wyrażenia relacyjne, zwane też wyrażeniami dopasowującymi (ang. match expressions), pozwalają na sprawdzanie zależności i związków między wartościami. Dzięki nim możliwe jest warunkowanie wykonywanie pewnych czynności, np. jeżeli badany pakiet spełni określone kryteria.
Istnieją dwa rodzaje wyrażeń dopasowujących:
- proste wyrażenia relacyjne (ang. basic relational expressions) i
- porównania flag (ang. flag comparisons).
Proste wyrażenia relacyjne
Proste wyrażenia relacyjne polegają na użyciu operatora (ang. operator) komunikującego relację między wyrażeniami umieszczonymi po jego lewej i prawej stronie:
| Operator | Znaczenie |
|---|---|
== | równe |
!= | różne |
< | mniejsze |
<= | mniejsze lub równe |
> | większe |
>= | większe lub równe |
Jeżeli nie podano operatora, domniemywa się, że chodzi
o ==.
W przypadku, gdy wyrażeniem po prawej stronie jest zbiór, dokonywane jest jego przeszukanie pod kątem zawierania określonego elementu, podobnie w przypadku gdy jest to zakres (interwał).
Dopasowania flag
Drugim rodzajem wyrażeń dopasowujących są dopasowania flag. Flagi to jednobitowe elementy, które mogą wyrażać logiczną prawdę lub fałsz. W strukturach pakietów i ramek rozmaite flagi łączy się w jedno– lub nawet wielobajtowe łańcuchy. Powstają wtedy struktury, które chociaż dają się reprezentować numerycznie (jako liczby całkowite), są w istocie zestawami parametrów, a znaczenie każdego z nich zależy od umiejscowienia w sekwencji.
Aby zbadać czy dane flagi z wyrażonego numerycznie zestawu są ustawione, należy wykonać operację iloczynu bitowego wartości i przygotowanego wcześniej wzorca z zapalonymi bitami w spodziewanych miejscach. Jeżeli w rezultacie otrzymamy taką samą wartość jak wzorzec, oznaczało to będzie, że wszystkie testowane flagi są aktywne.
Żeby nie trzeba było korzystać z bitowej arytmetyki, można użyć właśnie wyrażeń
dopasowujących flagi, a zamiast podawać liczby użyć reprezentujących konkretne flagi
wyrażeń stałych (np. established zamiast 0x00000002 przy określaniu oczekiwanego
stanu połączenia).
Wyrażenie dopasowujące flagi składa się z podanego na początku innego wyrażenia (np. wyrażenia ładunkowego pobierającego z nagłówka pakietu zestaw flag) i listy oddzielonych przecinkami wyrażeń stałych typu bitmask.
Deklaracje i akcje
Dzięki temu, że zamiast z regułami o ustalonej strukturze mamy do czynienia z małymi pseudoprogramami, możemy bez tworzenia dodatkowych łańcuchów czy osobnych reguł sprawiać, aby w stosunku do pakietu spełniającego określone kryteria była podejmowana więcej niż jedna akcja (ang. action) na podstawie podanej deklaracji (ang. statement).
Akcjami mogą być różnorakie operacje, włączając w to analizy polegające np. na wczytaniu ładunku z pakietu w celu porównania pewnego fragmentu z wzorcem. Tak naprawdę znika wyraźny podział na kryteria i cele. Znane z iptables cele, będące efektem pracy reguły, stały się właśnie akcjami.
Niektóre z zadeklarowanych akcji decydują o losie pakietu – nazywamy je wtedy decyzjami lub werdyktami (ang. verdicts), a wyrażające je konstrukcje deklaracjami decyzyjnymi (ang. verdict statements).
Oto możliwe akcje, które mogą być podjęte, gdy kryteria dopasowywania reguły zostaną spełnione:
-
decyzje (werdykty):
- accept – przyjęcie pakietu;
- reject – odrzucenie pakietu z poinformowaniem nadawcy;
- drop – zablokowanie pakietu;
- return – zwrócenie pakietu do łańcucha nadrzędnego;
- jump – skok do podanego łańcucha;
- goto – bezpowrotny skok do podanego łańcucha;
-
translacje adresów:
- snat – translacja adresu źródłowego pakietu (SNAT);
- dnat – translacja adresu docelowego pakietu (DNAT);
-
modyfikacje:
- meta mark – ustawianie znacznika pakietu;
- meta priority – ustawianie priorytetu (klasyfikacja QoS);
- meta nftrace – włączanie śledzenia ścieżki w obrębie nf_tables;
-
ograniczanie prędkości:
- limit rate – wykonywanie akcji tylko dla podanej liczby pakietów w czasie;
-
raportowanie:
- log – zgłoszenie pakietu do podsystemu raportowania zdarzeń;
-
zliczanie:
- counter – zliczanie pakietów (w nftables opcjonalne).
Akcje mogą decydować o losie pakietu, ale mogą też dokonywać dalszej analizy. Życiowym przykładem może tu być konieczność raportowania i jednoczesnego oznaczania pakietów – w nftables robi się to z użyciem jednego polecenia.
Niektóre akcje reguł nftables można parametryzować, a parametry mogą być ustalane dynamicznie, na podstawie danych uzyskanych w toku analizy pakietu lub przez odczyt struktur utrzymywanych przez jądro (np. tabel śledzenia połączeń). W praktyce pozwala to na zarządzanie ruchem sieciowym w sposób niezwykle elastyczny.
Podsumowanie
Przykłady
Poniżej znajdziemy kilka przykładów stanowiących wstęp do zainteresowania się nftables w formie prostego scenariusza.
Tworzenie tabeli i łańcucha reguł
Tworzenie tabeli nasza (rodzina IPv4), a w niej łańcucha reguł wejscie, do
którego trafiały będą pakiety kierowane do lokalnej stacji sieciowej:
nft add table ip nasza
nft add chain ip nasza wejscie { type filter hook input priority 0 \; }
nft add table ip nasza
nft add chain ip nasza wejscie { type filter hook input priority 0 \; }
Tworzenie zbioru adresów
Dodanie do tabeli nasza zbioru dobre-adresy zawierającego zaufane adresy IP:
nft add set ip nasza dobre-adresy { type ipv4_addr \; }
nft add element ip nasza dobre-adresy { 192.168.0.1 , 172.30.0.5 }
nft add set ip nasza dobre-adresy { type ipv4_addr \; }
nft add element ip nasza dobre-adresy { 192.168.0.1 , 172.30.0.5 }
Dodawanie reguł
Dodanie do łańcucha reguł wejscie (z tabeli nasza) reguły, która dla każdego
z adresów innych niż podany zakres dokonuje zliczania nawiązywanych sesji:
nft add rule ip nasza wejscie ct state new \
ip saddr != 192.168.0.1-192.168.0.254 \
counter
nft add rule ip nasza wejscie ct state new \
ip saddr != 192.168.0.1-192.168.0.254 \
counter
Dodanie reguły, która dla każdego „dobrego” adresu oznacza pakiet markerem 31337:
nft add rule ip nasza wejscie ip saddr @dobre-adresy mark 31337
nft add rule ip nasza wejscie ip saddr @dobre-adresy mark 31337
Wyświetlanie tabeli
Wyświetlenie tabeli z zawartością:
nft list table ip nasza
nft list table ip nasza
Rezultat wykonania powyższej komendy:
table ip nasza {
set dobre-adresy {
type ipv4_addr
elements = { 192.168.0.1, 172.30.0.5 }
}
chain wejscie {
type filter hook input priority 0; policy accept;
ct state new ip saddr < 192.168.0.1 ip saddr > 192.168.0.254 counter
packets 0 bytes 0
ip saddr @dobre-adresy mark 0x00007a69
}
}
Zobacz także
- „The netfilter.org nftables project”, strona projektu
- „Nftables HOWTO”, HOWTO projektu
- „Blokowanie niepożądanej komunikacji z nftables na linux”, Morfitronik
- „Nftables quick howto”, podręcznik autorstwa Érica Leblonda
- „Why you will love nftables”, wpis w blogu Érica Leblonda
- „nftables”, podręcznik nftables dystrybucji Arch Linux
- „Nftables”, podręcznik nftables dystrybucji Gentoo Linux
- "[ANNOUNCE]: First release of nftables”, ogłoszenie na Netfilter Development
- „Netfilter – index : nftables”, kod źródłowy
- „gnftables”, narzędzie do graficznego zarządzania regułami (wersja rozwojowa)