

System kontroli wersji Git jest zwinnym następcą takich tworów, jak Concurrent Versions System (CVS) czy Subversion (SVN). Od wspomnianych różni się przede wszystkim tym, że jest systemem rozproszonym i korzysta z migawek oraz kryptograficznie poświadczanego łańcucha zatwierdzeń.
Git jest nowoczesnym, zdecentralizowanym systemem kontroli wersji (ang. version control system). Systemy kontroli wersji to narzędzia, które pozwalają rozróżniać następujące po sobie wydania dokumentów (w szczególności tekstowych, zawierających kod źródłowy programów komputerowych), a efektywnie pamiętać i śledzić dokonywane w nich zmiany.
Dzięki systemom kontroli wersji wiemy dokładnie kiedy doszło do modyfikacji konkretnych plików, kto tego dokonał, a także jakie są różnice w stosunku do bieżącej lub zapamiętanej wcześniej wersji. Kronika zmian pozwala przywracać historyczne wersje dokumentów, jak również kategoryzować ich wydania, z użyciem odpowiednich znaczników, rozgałęzień itp.
Systemów kontroli wersji używa się z jeszcze jednego, istotnego powodu: pozwalają na współpracę nad projektem przez wiele osób. Poza pamiętaniem historii zmian wyposażone są w mechanizmy, które umożliwiają jednoczesną modyfikację zawartości jednego lub większej liczby dokumentów.
Warto podkreślić, że nie mamy tu na myśli chmurowych systemów edycyjnych, które bazują na synchronizacji zmian w czasie rzeczywistym na poziomie edytora bądź procesora tekstu, lecz możliwość scalania zmian w plikach, które były wcześniej edytowane w trybie offline. W przypadku modyfikacji tych samych obszarów przez różne osoby wymagana będzie ręczna interwencja – programista, który chce przesłać zmiany później, niż zrobił to ktoś inny, dokona usunięcia konfliktów, zanim jego wersja zostanie przyjęta.
Historia
Dawniej niemal wszystkie systemy kontroli wersji miały mocno scentralizowaną architekturę. W ramach projektu istniał pewien serwer, na którym działała usługa zajmująca się utrzymywaniem historii zmian, a odpowiednie oprogramowanie klienckie programistów łączyło się do niej i porównywało bieżące wersje plików z zachowanymi na serwerze.

Scentralizowana architektura systemów kontroli wersji minionej epoki: oprogramowanie klienckie łączy się do serwera i synchronizuje zmiany w plikach objętych śledzeniem
Problem pojawiał się, gdy wykrywany był konflikt (zmiany poczynione w obszarach plików już przez kogoś zmodyfikowanych od ostatniej synchronizacji). Użytkownik musiał dokonać ręcznego złączenia zmian i ponowić operację. Dopóki tego nie zrobił jego wydanie pliku nie było pamiętane w systemie kontroli wersji, a tylko w lokalnym katalogu ze źródłami. W niektórych systemach kontroli wersji dochodziło wtedy do automatycznego założenia blokady na czas dokonywania tej operacji, a w jej trakcie nikt inny nie był w stanie synchronizować zmian w odniesieniu do danego zbioru.
Warto również zaznaczyć, że w sporej części systemów synchronizowane zestawy zmian w wielu plikach jednocześnie nie były atomowe, tzn. gdy występowały problemy z jednym zbiorem, reszta była pomyślnie przesyłana i aktualizowana. Prowadziło to do zamieszania i kłopotów ze sprawną współpracą.
Git, jako jeden z pierwszych pakietów oprogramowania wydawanego na wolnych licencjach, zaproponował nieco inne podejście. Zamiast centralnej bazy danych systemu kontroli wersji, wprowadza koncepcję lokalnego repozytorium, które towarzyszy plikom i katalogom projektu. Synchronizacja zmian polega na odbieraniu i wysyłaniu historii zmian między lokalnym a zdalnym repozytorium. To ostatnie może znajdować się na innym systemie, ale też w innym katalogu na tej samej maszynie.
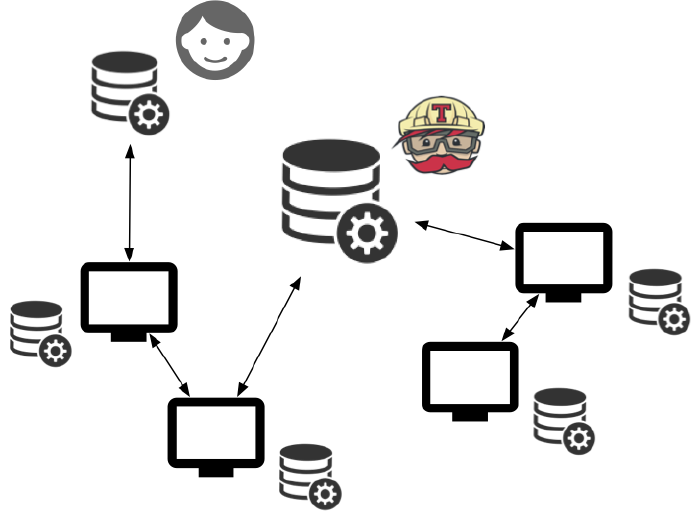
Rozproszona architektura systemów kontroli wersji pozwala delegować kompetencje, a każdy ma pełną kopię historii zmian i może dzielić się zawartością repozytorium z innymi
Jeżeli ktoś ma doświadczenie z systemami CVS lub SVN, zaznajomienie się z Gitem będzie łatwiejsze – wystarczy spojrzeć na niego tak, jakby istniało wiele serwerów służących do utrzymywania rejestru wprowadzanych zmian. Należy mieć jednak na względzie, że Git doskonale sobie radzi bez protokołu sieciowego, który służy do prowadzenia dialogu między klientem a serwerem – wystarczy mu widoczność systemu plikowego zdalnej maszyny. Oczywiście, jeżeli udostępnianie plików i katalogów (np. jako udziałów sieciowych) nie jest możliwe, Git może działać z użyciem własnego protokołu transportującego, SSH, a nawet HTTP.
Git a społeczności programistów
Istnieje społecznościowy efekt uboczny pracy z użyciem systemu Git, który objawia się większym pluralizmem wprowadzania zmian i poprawek, szczególnie w projektach wolnego i otwartego oprogramowania. Zjawisko to można uznać za ciekawy przykład kształtowania postaw społecznych przez nowoczesne technologie.
W czasach dawnych systemów kontroli wersji, które wymuszały centralizację, każdy projekt musiał mieć osobę dbającą o jego repozytorium. Do jej obowiązków, poza utrzymaniem technicznym, należało również rozstrzyganie sporów dotyczących wprowadzanych zmian. Często osoba taka łączyła funkcję lidera i głównego programisty projektu z rolą administratora. Miała ona swobodny dostęp do repozytorium i od niej zależało, kto może wprowadzać zmiany, jak szybko będą wprowadzane, a także jak długo należy poczekać, zanim usunie się blokadę pozostawioną przez kogoś, kto o niej zapomniał.
W rezultacie niektóre projekty, mimo że miały naprawdę kompetentnych liderów, cierpiały z powodów logistycznych i międzyludzkich. Naczelny programista nie zawsze miał czas na zarządzanie konfliktami w systemie kontroli wersji, rzadziej na zarządzanie konfliktami między innymi programistami, a częstokroć opieszale wprowadzał istotne, proponowane poprawki. Mógł sobie na to pozwolić m.in. dlatego, że kontrolował źródłowe repozytorium. Był to jeden z filarów jego scentralizowanej, administracyjnej władzy. Jeżeli trafiliśmy dodatkowo na osobę o nieco autystycznym usposobieniu i przypadkiem lub celowo naraziliśmy się jej, to oprogramowanie, któremu chcieliśmy pomóc wzrastać, mogło być w opałach z powodów zupełnie innych, niż merytoryczne.
Jeżeli naprawdę lubicie używać CVS-u, nie powinno was tu być.
Powinniście być w jakimś szpitalu psychiatrycznym, gdzieś indziej1.— Linus Torvalds
Wraz z upowszechnieniem się Gita zachowanie szefów projektów wolnego i otwartego oprogramowania musiało dostosować się do nowych realiów. Selekcja naturalna, z którą mamy do czynienia w tego typu przedsięwzięciach, wzmocniła się. Nie nastąpiła jakaś wielka rewolucja – projekty nadal mają hierarchiczną strukturę zarządzania, jednak znacznie łatwiejsze stało się tworzenie alternatywnych wersji całego kodu źródłowego; wersji zawierających kompletną historię zmian. Mieliśmy do czynienia z pewnego rodzaju udrożnieniem mechanizmu dzielenia się. Niedługo potem powstały serwisy, takie jak GitHub czy GitLab, gdzie skopiowanie całego drzewa źródeł w inne miejsce zajmuje mniej czasu, niż znalezienie odpowiedzi na popularny problem w serwisie Stack Overflow.
Jeżeli opiekun projektu ociąga się z wprowadzaniem potrzebnych poprawek czy usprawnień, albo z innych przyczyn opóźnia włączenie zaproponowanych zmian, mimo że użytkownikom są one potrzebne, szybko znajdzie się ktoś, kto przejmie dotychczasową bazę kodu i zacznie wydawać satysfakcjonujące społeczność wersje.
Zastosowanie Gita nie oznacza anarchii. Oznacza, że ważne jest przetrwanie i rozwój oprogramowania, a nie pozycji programisty. Podejście takie może wydawać się nieco zdehumanizowane, jednak finalnie korzystają użytkownicy. Poza tym dzięki rozproszonym repozytoriom można prowadzić projekty w oparciu o wielopoziomowe hierarchie. Tak wygląda dziś na przykład opracowywanie zmian w Linuksie. Istnieją szefowie poszczególnych podsystemów, którzy mają swych zaufanych programistów, a sami odpowiadają przed osobami odpowiedzialnymi za ogólny kierunek prac. Gdy ktoś spoza tych kręgów proponuje zmianę, trafia ona najpierw do jednego z programistów, a jeżeli uzna on ją za odpowiednią (i może nieco poprawi), wysyła do któregoś z utrzymujących konkretny fragment źródeł. W proces ten wpisana jest naturalna kontrola jakości.
Twórcą Gita jest Linus Torvalds, autor kernela Linux, znany z pragmatycznego podejścia. Motywacją dla stworzenia takiej akurat architektury Gita nie były więc wyłącznie ideały pluralistycznego tworzenia oprogramowania z pomniejszonym nadzorem, ale konkretne powody logistyczne.
Okazuje się, że najbardziej efektywnym sposobem rozwiązywania konfliktów w kodzie, czy włączania do kodu zewnętrznych zmian, nie jest wyposażenie projektu w jednego opiekuna i centralnego administratora, lecz skorzystanie z sieci społecznej, w której mamy do czynienia z delegowanymi kompetencjami. W efekcie programiści zachęcają zaufanych współpracowników do tego, aby pobrali od nich jakiś fragment i jeżeli im się spodoba, włączyli go do swojej gałęzi kodu. W systemie Git rozgałęzień może być wiele, ale przyjęty model zarządzania czyni operacje ich łączenia nieskomplikowanymi.
Podstawowe terminy
Zacznijmy od rzeczy najbardziej podstawowych, a jednocześnie wymagających skupienia. Jeżeli zrozumiemy wewnętrzne mechanizmy, których używa Git do zarządzania naszymi danymi, szybko zauważymy, że jest to pewna skończona wiedza i nie zareagujemy frustracją na kłopoty z obsługą bardziej skomplikowanych operacji.
Repozytorium
Sercem systemu kontroli wersji Git jest baza danych zwana repozytorium (ang. repository, skr. repo), w której zapisywane są tzw. migawki zawartości projektu objętego kontrolą wersji, jak również obiekty zawierające metadane związane z dokonywanymi zmianami. Użytkownik może wybrać, które z plików obecnych w drzewie katalogowym będą należały do repozytorium, tzn. będzie w odniesieniu do nich prowadzone śledzenie zmian.
Lokalne repozytorium Gita, towarzyszące każdemu projektowi, znajdziemy w podkatalogu
.git.
Repozytorium systemu kontroli wersji Git możemy wyobrażać sobie jako specyficzny system plikowy z obsługą migawek, historii zmian i rozgałęzień. Wewnętrznie każdy przechowywany w nim rekord informacji reprezentowany jest tzw. obiektem, czyli pojedynczym plikiem. Nazwa ścieżkowa tego pliku jest rezultatem wywołania kryptograficznej funkcji skrótu na zawartości obiektu. W związku z tym Git bywa nazywany systemem plikowym adresowanym zawartością (ang. content-addressable filesystem).
Korzystając z odpowiednich poleceń możemy w bazie Gita zapisywać dowolne dane (np. napisy tekstowe), a potem wyszukiwać je i dokonywać ich odczytu. Przeznaczeniem pozostaje jednak kontrola wersji i właśnie związane z tym zadaniem informacje będą umieszczane w repozytorium.
Obiekty Gita
Git przechowuje informacje o zmianach we wspomnianej już bazie
obiektów. Z systemowego punktu widzenia jest to struktura katalogowa wewnątrz
podkatalogu .git, w którym rezydują zasoby identyfikowane rezultatami wywołania
kryptograficznej funkcji skrótu SHA-1 (z ang. Secure Hash Alghoritm). Te zasoby
to zawartości plików objętych kontrolą wersji, informacje o dokonywanych zmianach,
dane dotyczące struktury katalogów itd. – wszystko, co Git musi zapamiętywać.
Kryptograficzne funkcje skrótu, zwane też kryptograficznymi funkcjami mieszającymi (ang. cryptographic hash functions), to funkcje zbudowane na bazie algorytmów, które dla podanych danych wejściowych zwracają stałej długości liczbę (sumę kontrolną), przy czym zmiana w jednym bicie danych wejściowych powinna powodować zmianę przynajmniej połowy bitów zwracanego rezultatu. Funkcje mieszające używane w kryptografii powinny również cechować się bezkolizyjnością lub niską kolizyjnością, tzn. powinno być niemożliwe lub bardzo trudne spreparowanie podobnych danych wejściowych, które dadzą w efekcie ten sam skrót.
Kryptograficznie użytecznych funkcji skrótu używa się m.in. do generowania podpisów cyfrowych bądź sum kontrolnych plików, których integralność musi być poświadczana.
Dzięki identyfikowaniu każdego obiektu skrótem, który jest pochodną jego zawartości, bardzo szybko można sprawdzić, czy dodawany zasób istnieje w bazie (np. czy bieżąca wersja pliku nie rezyduje już w repozytorium). Poza tym Git gwarantuje w ten sposób integralność zmian i do pewnego stopnia niezaprzeczalność ich autorstwa, gdy w skład sumy kontrolnej niektórych obiektów wchodzi również informacja o autorze zatwierdzającym zmianę.
Gdybyśmy na przykład chcieli sprawdzić, jaki byłby skrót dla przykładowego napisu „test”, możemy w powłoce wykonać polecenie:
echo "test" | git hash-object --stdin
echo "test" | git hash-object --stdin
Rezultatem powinna być przedstawiona heksadecymalnie wartość skrótu:
9daeafb9864cf43055ae93beb0afd6c7d144bfa4
Jeżeli podany przez nas napis miałby być przechowywany w bazie Gita w formie obiektu,
to zostałby umieszczony w katalogu .git/objects, podkatalogu 9d i pliku
aeafb9864cf43055ae93beb0afd6c7d144bfa4. Podkatalog 9d jest tworzony ze względów
wydajnościowych.
Sprytni czytelnicy mogą porównać wyjście polecenia git hash-object z sha1sum
i stwierdzić, że mamy do czynienia z inną niż SHA-1 funkcją mieszającą. Wyjaśnienie
jest prozaiczne: git-hash nie tworzy sumy kontrolnej z samej zawartości, lecz używa
złączenia:
- typu obiektu wyrażonego łańcuchem znakowym (np. blob),
- znaku spacji,
- długości obiektu wyrażonej w bajtach przedstawionych dziesiętnie,
- znaku o kodzie 0,
- podanej zawartości.
Czym jest wspomniany wyżej typ obiektu? Obecne w katalogu .git/objects obiekty mogą
należeć do różnych rodzajów:
-
obiekty blob (ang. blob objects)
służące do przechowywania zawartości plików, -
obiekty zatwierdzeniowe (ang. commit objects)
opisujące wprowadzane zmiany, -
obiekty drzew (ang. tree obiects)
zawierające informacje o rozmieszczeniu plików w katalogach, -
obiekty znaczników opatrzonych komentarzem (ang. annotated tag objects)
używane do dodatkowego oznaczania wybranych wersji.
Wszystkie wymienione obiekty będą identyfikowane z użyciem rezultatów funkcji skrótu (dwa pierwsze znaki jako nazwa katalogu, reszta jako nazwa pliku). Często spotkamy się też z praktyką wyrażania relacji między obiektami Gita w ten sposób, że jeden obiekt będzie zawierał wewnątrz sumę SHA-1, która odnosi się do innego. Na przykład obiekt typu commit wyrażający zmianę będzie przechowywał wewnątrz odwołanie do obiektu typu tree.
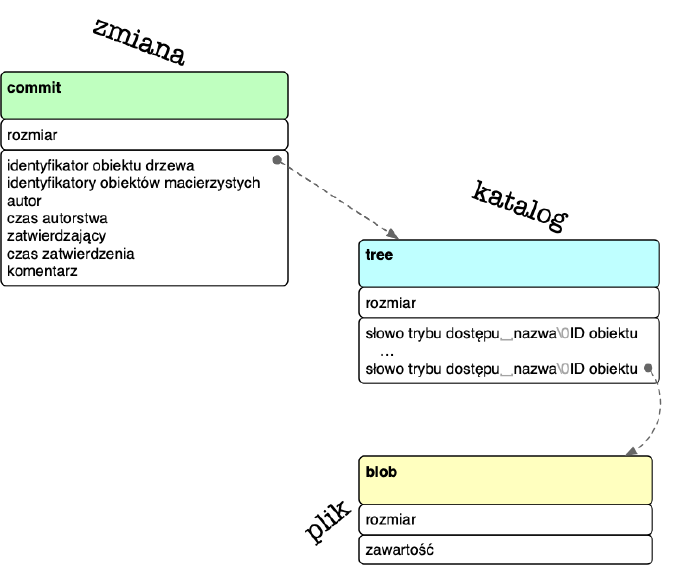
Wewnętrzna struktura najczęściej używanych obiektów Gita i relacje między nimi: commit wyraża zmianę, tree strukturę katalogu w chwili wprowadzania zmiany, a blob zapamiętaną zawartość pliku wchodzącego w skład katalogu w momencie zatwierdzania zmiany
Migawka
Migawka (ang. snapshot) to stan projektu w danym punkcie czasu. Na stan składają się nazwy, zawartości i niektóre atrybuty wszystkich plików oraz katalogów, które zostały objęte kontrolą wersji. Termin nawiązuje do migawek znanych ze świata fotografii i animacji, a w IT oznacza zrzut danych o wartości historycznej.
Wewnętrznie migawka reprezentowana jest zestawem obiektów rezydujących w repozytorium, które przechowują informacje pozwalające odtworzyć strukturę katalogową, atrybuty i zawartości plików z chwili wprowadzania zmiany. Będą to więc obiekty typu blob (zawartości plików) i obiekty drzew (zawartości katalogów).
Warto zaznaczyć, że termin „migawka” jest pewnego rodzaju abstrakcją, która ma znaczenia dla użytkownika. Architektonicznie rzecz ujmując, Git nie zawiera jakiejś specjalnej przestrzeni zwanej migawką, ani nie ma jednolitego obiektu, który takową by reprezentował.
Kopia robocza
Lokalne pliki i katalogi, dla których działa kontrola wersji, nazywamy kopią roboczą (ang. working copy) lub drzewem roboczym (ang. working tree). Od chwili zainicjowania lokalnego repozytorium mogą one wyrażać nie tylko aktualny stan projektu, ale również dowolny inny: z jednego z wcześniejszych momentów, lub też z innej, alternatywnej ścieżki zmian (jeżeli istnieje). Użytkownik może przełączać się między różnymi wersjami i dochodzi wtedy do podmiany plików oraz katalogów w drzewie na ich historyczne wersje.
Roboczość oznacza tu, że po wprowadzeniu kontroli wersji katalog z naszym projektem przestaje być zbiorem plików, których zawartość zależy tylko od dokonywanych przez nas edycji. Strażnikiem integralności staje się repozytorium, natomiast kopia robocza wyraża bieżącą lub inną wybraną przez nas migawkę.
Jeżeli zdarzy się, że zmodyfikujemy jakiś plik, a w następnej chwili przypadkiem zechcemy przywrócić jego wcześniejszą wersję, Git odmówi wykonania tej operacji z uwagi na możliwość zaprzepaszczenia wprowadzonych zmian, które jeszcze nie zostały zachowane w repozytorium.
Istnieją również tzw. repozytoria czyste (ang. bare repositories), którym nie towarzyszą robocze drzewa katalogowe. Korzysta się z nich do współdzielenia historii zmian między wieloma węzłami w modelu klient-serwer. Są wtedy zdalnymi repozytoriami, z którymi synchronizowane są lokalne repozytoria programistów. Często wykorzystuje się tego typu architekturę do automatycznego wdrażania (ang. deployment) lub wydawania (ang. release) wybranych wersji oprogramowania.
Poczekalnia
Jednym ze składników Gita jest dodatkowa baza zwana indeksem (ang. index), której główną rolą jest pełnienie funkcji poczekalni, czyli obszaru przejściowego (ang. staging area). Jest to przestrzeń, w której umieszczane są obiekty reprezentujące informacje o plikach z drzewa roboczego zanim Git zapamięta je w repozytorium i powiąże z informacjami o wersji.
Zmiany dokonywane w drzewie roboczym nie mogą być śledzone, jeżeli najpierw nie
dodamy do indeksu wybranych plików (służy do tego omówione dalej polecenie git add). Operacja ta sprawia, że tworzona jest tymczasowa migawka kopii roboczej, która
reprezentuje wszystkie pliki i katalogi, lecz tylko te wprowadzone do indeksu pojawią
się w nowych wersjach.
Zawartość każdego dodawanego do indeksu dokumentu reprezentowana jest obiektem typu
blob w repozytorium, natomiast informacje o metadanych oczekujących plików
(m.in. o ich typach i atrybutach), a także o lokalizacjach wewnątrz struktury
katalogowej projektu przechowywane są w specjalnym obiekcie o nazwie index,
zlokalizowanym w podkatalogu .git.
Wpisy w indeksie odnoszące się do umieszczonych w poczekalni plików z katalogu roboczego zawierają również identyfikatory wspomnianych obiektów typu blob (reprezentujących zawartości z chwili dodawania).
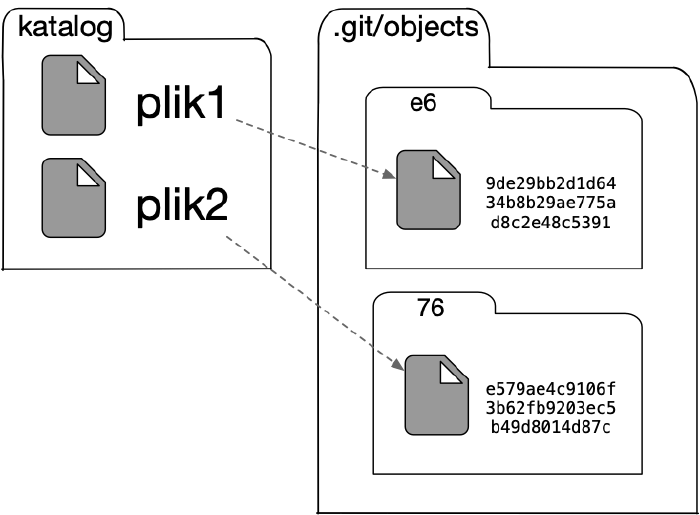
Po dodaniu plików do indeksu w bazie gita powstają dwa zbiory identyfikowane sumą SHA-1, które reprezentują obiekty typu blob przechowujące zawartości tych plików z chwili dodawania
Zbiory rezydujące w indeksie nazywamy oczekującymi (ang. staged). Na co? Na decyzję o zatwierdzeniu, czyli wprowadzeniu ich do systemu kontroli wersji jako kolejnych wydań.
Zatwierdzanie zmian
Umieszczona w poczekalni migawka kopii roboczej może zostać zatwierdzona (ang. commited). Stanie się wtedy kolejną wersją w historii zmian przechowywanych w repozytorium. Każda zatwierdzona zmiana zawiera w sobie odniesienie do zmiany zatwierdzonej wcześniej, stając się częścią acyklicznego, skierowanego grafu historii zmian.
Zatwierdzenia zmian, a więc utworzenia nowej wersji, dokonuje się używając
odpowiedniego polecenia (git commit), które zapisuje w repozytorium tzw. obiekt
zatwierdzeniowy, zwany też obiektem zestawu zmian. Poza nim do odnotowania
zmiany wykorzystywane są też obiekty drzew i obiekty typu blob, które tworzą migawkę.
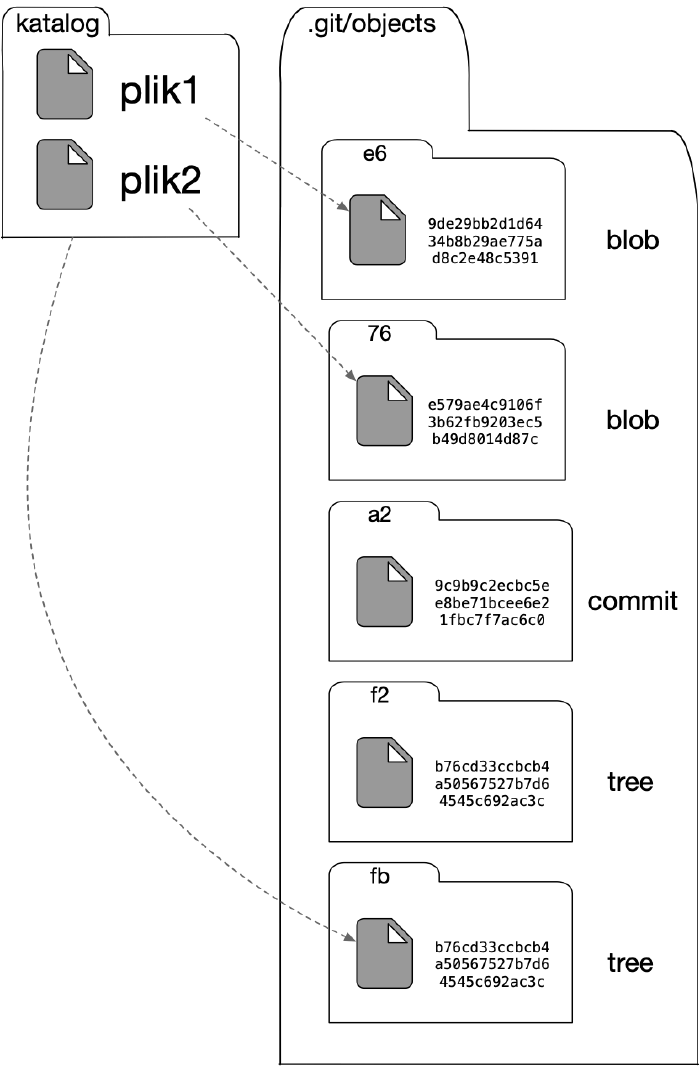
Po zatwierdzeniu zmian w bazie gita powstają dodatkowe zbiory identyfikowane sumami SHA-1: dwa reprezentujące zawartości katalogów i jeden będący obiektem zatwierdzeniowym
Obiekt zatwierdzeniowy przechowywany jest w bazie danych Gita wraz z innymi obiektami i również jest plikiem identyfikowanym własnym skrótem. Wewnętrznie jest skompresowanym zestawem następujących składników:
- łańcucha znakowego
commit; - znaku spacji;
- długości obiektu wyrażonej w bajtach przedstawionych dziesiętnie;
- znaku o kodzie 0;
- identyfikatora obiektu drzewa, który reprezentuje strukturę katalogową w momencie zatwierdzania zmian;
- identyfikatorów macierzystych obiektów zatwierdzeniowych (ang. parent commit objects);
- autora zmiany;
- czasu zmiany;
- zatwierdzającego zmianę;
- czasu zatwierdzenia zmiany;
- komentarza;
- kryptograficznego skrótu powyższych danych, który stanie się nazwą katalogu i pliku podczas zapisywania obiektu.
Warto wyjaśnić znaczenie identyfikatora obiektu macierzystego. Jest to utworzone na bazie SHA-1 odwołanie do innego obiektu zatwierdzeniowego, dzięki któremu utrzymywana jest linia historii zmian. Obiekt nadrzędny może być nieustawiony – będzie to oznaczało, że mamy do czynienia z pierwszą zmianą; może zawierać odwołanie do jednego obiektu macierzystego – mamy wtedy do czynienia z kolejnym zestawem zmian następującym po istniejącym; może w końcu zawierać więcej niż dwa odwołania – będzie to efektem tzw. złączenia rozgałęzień, czyli równoległych linii zmian.
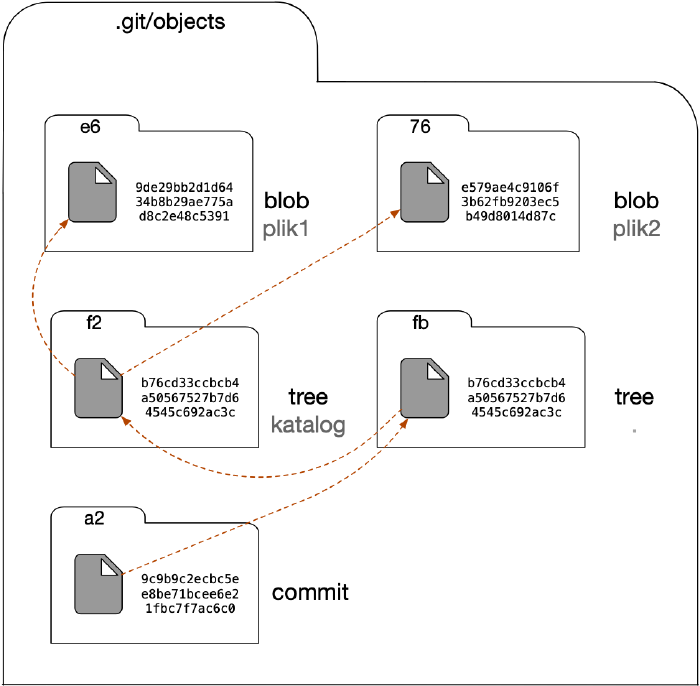
Obiekt zatwierdzeniowy zawiera odwołanie do obiektu drzewa reprezentującego katalog główny projektu, a ten z kolei odwołuje się do obiektu drzewa odzwierciedlającego strukturę katalogu katalog, w którym znajdziemy odwołania do obiektów blob odpowiadających zawartościom plików w danym momencie
Rozgałęzienia
Poza wersjami, które wyrażają historię następujących po sobie zmian, możemy też tworzyć tzw. rozgałęzienia (ang. branches). Rozgałęzienie sprawia, że powstaje kolejna, alternatywna linia zmian projektu, zwana gałęzią.
Rozgałęzienia przydają się na przykład wtedy, gdy potrzebujemy więcej czasu na opracowanie poprawki bądź dodanie nowej funkcji do programu i nie chcemy, aby wprowadzane przez nas modyfikacje utrudniały innym testowanie aplikacji i nanoszenie drobniejszych zmian.
W Gicie wytwarzanie rozgałęzień jest operacją „tanią”, tzn. nie wymaga kopiowania całego drzewa roboczego do innego katalogu. Wynika to z referencyjnego charakteru repozytorium – wystarczy dodać różniące się wydania plików, utworzyć nowy obiekt zatwierdzeniowy i… już!

Aby zrozumieć, w jaki sposób wewnętrznie działają rozgałęzienia, musimy przyswoić jeszcze jeden istotny termin: HEAD. Jest to odniesienie do bieżącej gałęzi lub obiektu zatwierdzającego, które informuje oprogramowanie o aktualnej linii zmian.
W praktyce działa to tak, że istnieje plik HEAD w podkatalogu .git, wewnątrz
którego możemy znaleźć nazwę gałęzi bądź identyfikator obiektu
zatwierdzającego. Warto zauważyć, że nowo utworzone repozytorium zawiera zawsze
jedną, domyślną gałąź zmian o nazwie master.
Żeby Git mógł pomagać użytkownikowi w nawigacji między różnymi momentami historii zmian, musi być w stanie odnajdywać odpowiadające tym momentom obiekty zatwierdzające, a właściwie ich identyfikatory. W gruncie rzeczy potrzebny będzie tylko ostatni, najbardziej aktualny obiekt typu commit, ponieważ wewnątrz znajdziemy odwołanie do jego poprzednika (obiektu macierzystego). Gdzie więc należy szukać informacji o tym ostatnim wierzchołku grafu reprezentującego historię?
W podkatalogu .git istnieje katalog refs/heads, który przechowuje pliki nadające
gałęziom nazwy. Zawartości tych plików to identyfikatory obiektów typu commit,
które powinny opisywać ostatnie zmiany w swoich liniach historii zmian.
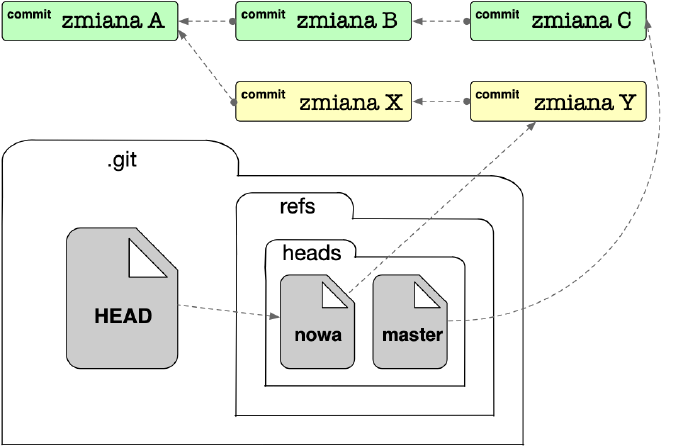
Wskaźnik HEAD i pliki referencyjne nazywające gałęzie zmian, które zawierają identyfikatory ostatnich zatwierdzeń
Do tworzenia rozgałęzień służy, omówione w kolejnych częściach, polecenie git branch, a także polecenie git checkout z opcją -b.
Przełączanie wersji
W sekcji dotyczącej rozgałęzień mogliśmy zapoznać się z mechanizmem ustawiania
wskaźnika HEAD, który używany jest przez rozmaite operacje Gita, aby określić
bieżącą gałąź, na której chce operować użytkownik.
Gdy podejrzymy zawartość pliku .git/HEAD, znajdziemy w nim zapis podobny
do poniższego:
ref: refs/heads/master
ref: refs/heads/master
Oznacza on, że wersją bieżącą jest ta określona odwołaniem (ref:) zapisanym
w pliku refs/heads/master. Kiedy wypiszemy jego zawartość, zobaczymy sumę SHA-1,
która identyfikuje zmianę, czyli obiekt typu commit.
Warto zaznaczyć, że plik HEAD może zawierać nie tylko nazwę gałęzi (w naszym
przypadku refs/heads/master), ale również identyfikator zmiany w postaci skrótu
SHA-1. W takim przypadku mówimy o tzw. oderwanym HEAD (ang. detached HEAD),
tzn. wskazaniu na konkretny obiekt typu commit zamiast na ostatni z gałęzi o podanej
nazwie.
Wskaźnika HEAD nie ustawiamy modyfikując zawartość pliku .git/HEAD, lecz z użyciem
polecenia git checkout. Służy ono do przełączania bieżącej wersji. Jako pierwszy
parametr przekazujemy nazwę gałęzi lub identyfikator obiektu typu commit, a polecenie
dokona odpowiednich operacji, na które składają się:
-
odszukanie obiektu typu commit na podstawie podanej nazwy gałęzi lub identyfikatora;
-
aktualizacja zawartości plików i katalogów drzewa roboczego na podstawie obiektów typu tree i blob skojarzonych ze zmianą opisaną obiektem commit;
-
aktualizacja wskaźnika HEAD, aby odwoływał się do podanej gałęzi lub konkretnego obiektu typu zatwierdzeniowego.
Jeżeli zamiast dookreślonej nazwy gałęzi podamy nazwę skróconą (np. master
w miejsce refs/heads/master), to aby usunąć niejednoznaczności i znaleźć plik
z identyfikatorem obiektu zatwierdzeniowego, będą przeszukane następujące
lokalizacje:
.git/<nazwa>.git/refs/<nazwa>.git/refs/tags/<nazwa>.git/refs/heads/<nazwa>.git/refs/remotes/<nazwa>.git/refs/remotes/<nazwa>/HEAD
Uwaga: Ustawiając HEAD na wartość konkretnego obiektu typu commit, zamiast na gałąź, sprawiamy że Git nie będzie mógł automatycznie przesunąć tego wskaźnika po dokonaniu zatwierdzenia zmian. Powstanie więc obiekt zatwierdzeniowy, który nie należy do żadnej nazwanej gałęzi. Może to prowadzić do zagubienia konkretnego wydania, ponieważ odwoływać się do niego będzie można tylko z użyciem identyfikatora w postaci sumy SHA-1.
-
L. Torvalds, „Tech Talk: Linus Torvalds on Git” [online], Mountain View, aktualizacja 14.05.2007 [dostęp 22.01.2019], https://youtu.be/4XpnKHJAok8?t=510 ↩︎