

Nick Craver opisuje przeprowadzoną w roku 2017 operację wdrożenia domyślnego korzystania z protokołu HTTPS w popularnym serwisie Stack Overflow. Dowiemy się jak wiele punktów infrastruktury i komponentów oprogramowania usługowego trzeba było przygotować na tę pamiętną noc.
Wdrożyliśmy dziś HTTPS jako wymóg w Stack Overflow. Cały
ruch jest teraz przekierowywany do https://, a odnośniki Google’a zmienią się
w ciągu kilku najbliższych tygodni. Aktywacja polegała dosłownie na pstryknięciu
przełącznikiem (zmianie flagi funkcji), lecz aby dotrzeć do tego punktu potrzebne
były lata pracy. Od teraz HTTPS jest domyślnym protokołem we wszystkich witrynach Q&A
[z pytaniami i odpowiedziami – przyp. tłum.].
Wdrożenie w obrębie sieci Stack Exchange zajęło ostatnie 2 miesiące. Stack Overflow jest ostatnią witryną i zdecydowanie największą. To dla nas ogromny kamień milowy, ale bynajmniej nie koniec. Jest więcej do zrobienia, do czego jeszcze dojdziemy, jednak koniec jest wreszcie na horyzoncie, hura!
Uczciwe ostrzeżenie: to historia długiej podróży. Bardzo długiej. Wskazuje na to bardzo mały rozmiar paska przewijania twojej przeglądarki. Podczas gdy pod względem napotkanych w trakcie tej wyprawy problemów serwisy Stack Exchange/Overflow nie okazały się specjalnie wyjątkowe, kombinacje owych problemów były dość rzadkie. Mam nadzieję, że niektóre szczegóły naszych prób, zmagań, pomyłek, zwycięstw, a nawet pewnych projektów typu open source, które wyłoniły się po drodze, okażą się pomocne. Trudno jest ułożyć tak zawiły łańcuch zależności w chronologiczny wpis, więc podzielę go tematycznie: infrastruktura, kod aplikacji, pomyłki itp.
Myślę, że warto przedstawić najpierw listę problemów, które sprawiają, że nasza sytuacja jest nieco wyjątkowa:
-
Mamy setki domen (wiele witryn i innych usług):
-
wiele domen drugiego poziomu
(stackoverflow.com,stackexchange.com,askubuntu.comitd.); -
wiele domen czwartego poziomu
(np.meta.gaming.stackexchange.com).
-
-
Pozwalamy na zawartość przesyłaną i osadzaną przez użytkowników
(np. obrazy i filmy z YouTube’a we wpisach). -
Świadczymy usługi z jednego centrum danych
(latencja ograniczona do jednego źródła). -
Mamy reklamy (i sieci reklamowe).
-
Używamy WebSockets z więcej niż 500 000 aktywnych połączeń
w dowolnym momencie. -
Jesteśmy DDoS-owani (proxy).
-
Mamy wiele witryn i aplikacji komunikujących się z użyciem API po HTTP (proxy).
-
Mamy obsesję na punkcie wydajności (może trochę za bardzo).
Ponieważ ten wpis jest nieco szalony, odnośniki do jego poszczególnych sekcji znajdziesz w spisie treści.
Początek
Zaczęliśmy rozmyślać o wdrożeniu HTTPS-u w Stack Overflow jeszcze w roku 2013. Nasuwa się więc oczywista kwestia: Jest rok 2017. Co u licha zajęło 4 lata? Były to te same 2 powody, które sprawiają, że opóźnia się każdy projekt IT: zależności i priorytety. Bądźmy szczerzy, informacje na Stack Overflow nie są aż tak cenne (aby je zabezpieczać), jak większość innych danych. Nie jesteśmy bankiem, nie jesteśmy szpitalem, nie obsługujemy płatności kartami kredytowymi, a raz na kwartał publikujemy nawet większość naszych baz danych z użyciem zarówno HTTP, jak i wykorzystując torrenty. Oznacza to, że z punktu widzenia bezpieczeństwa nie ma tutaj tak wysokiego priorytetu, jak w innych sytuacjach. Mieliśmy również o wiele więcej zależności, niż większość, co jest raczej unikatową kombinacją pewnych przestrzeni kilku potężnych obszarów problemowych podczas wdrażania HTTPS-u. Jak zdążysz przekonać się w dalszej części, niektóre problemy z domenami pozostają też niezmienne.
Największymi obszarami, które sprawiły nam problemy, były:
- zawartość użytkowników (mogą przesyłać zdjęcia lub podawać URL-e);
- sieci reklamowe (umowy i pomoc techniczna);
- hosting z jednego centrum danych (latencja);
- setki domen różnych poziomów (certyfikaty).
Okej, dlaczego więc chcemy mieć HTTPS na naszych stronach? Cóż, dane nie są jedyną rzeczą, która potrzebuje bezpieczeństwa. Mamy moderatorów, twórców oprogramowania, a także pracowników z różnymi poziomami dostępu odbywającego się przez sieć web. Chcemy zabezpieczyć ich komunikację z witryną. Chcemy zabezpieczyć historię przeglądania każdego użytkownika. Niektórzy ludzie każdego dnia żyją w strachu, wiedząc że ktoś może dowiedzieć się, iż w sekrecie lubią monady. Również Google faworyzuje strony zabezpieczone przez HTTPS w swym rankingu (chociaż nie mamy pojęcia jak).
Och, i wydajność. Kochamy wydajność. Ja kocham wydajność. Ty kochasz wydajność. Mój pies kocha wydajność. Wykonajmy wydajnościowy uścisk. To było bardzo miłe. Dziękuję. Ładnie pachniesz.
Szybkie specyfikacje
Niektórzy ludzie chcą po prostu specyfikacji, więc mamy wykonane naprędce Q&A (kochamy pytania i odpowiedzi):
Jakie protokoły obsługujecie?
TLS 1.0, 1.1, 1.2 (uwaga: Fastly ma w planach wycofanie TLS-u 1.0 i 1.1).
Nadchodzi obsługa TLS-u 1.3.
Czy obsługujecie SSL-a v2, v3?
Nie, są to uszkodzone, niebezpieczne protokoły.
Każdy powinien natychmiast je wyłączyć.
Jakie szyfry obsługujecie?
Na CDN-ie używamy domyślnego zestawu z Fastly’ego.
Na naszym systemie równoważenia obciążenia używamy zestawu
zgodnego z konfiguracją Modern od Mozilli.
Czy Fastly łączy się do serwerów początkowych przez HTTPS?
Tak, jeżeli żądanie CDN-u używa HTTPS-u, początkowe żądanie też wykorzysta HTTPS.
Czy obsługujecie utajnianie z wyprzedzeniem?
[ang. Forward Secrecy –przyp. tłum.]
Tak.
Czy obsługujecie HSTS?
Tak, obecnie intensyfikujemy jego wykorzystanie na stronach Q&A.
Gdy skończymy, przeniesiemy na serwery brzegowe.
Czy obsługujecie HPKP?
Nie i prawdopodobnie nie będziemy.
Czy obsługujecie SNI?
Nie, mamy certyfikat wieloznaczny z uwagi na wydajność HTTP/2 (szczegóły poniżej).
Skąd bierzecie certyfikaty?
Używamy DigiCertu, były świetne.
Czy obsługujecie IE 6?
To posunięcie w końcu całkowicie z tym kończy. IE 6 nie obsługuje TLS-u (domyślnie – chociaż można włączyć 1.0), a my nie obsługujemy SSL-a. Z obecnymi przekierowaniami 301 większość użytkowników IE 6 nie ma już dostępu do Stack Overflowa. Gdy TLS 1.0 zostanie wyeliminowany, żaden z nich nie będzie mógł.
Jakiego systemu równoważenia obciążenia używacie?
HAProxy (wewnętrznie korzysta z OpenSSL-a).
Jaka motywacja przyświecała wdrożeniu HTTPS-u?
Ludzie ciągle atakowali nasze ścieżki administracyjne,
takie jak stackoverflow.com/admin.php.
Infrastruktura
Certyfikaty
Pomówmy o certyfikatach, ponieważ pojawia w tym względzie wiele błędnych informacji. Straciłem rachubę w kwestii liczby osób, które mówią, że wystarczy zainstalować certyfikat i można już obsługiwać HTTPS. Rzuć okiem na malutki rozmiar paska przewijania i zgadnij, czy się z tym zgadzam. W celu odgadywania preferujemy metodę SWAG.
Najczęstsze zadawane nam pytanie brzmi: „Dlaczego nie użyć Let’s Encrypt?”.
Odpowiedź: ponieważ u nas to nie zadziała. Let’s Encrypt robi świetną rzecz. Mam nadzieję, że przy tym pozostaną. Gdy korzystasz z jednej domeny lub najwyżej kilku domen, są naprawdę dobrą opcją dla szerokiego wachlarza scenariuszy. My zwyczajnie nie jesteśmy w takiej pozycji. Stack Exchange ma setki domen. Let’s Encrypt nie ma w ofercie certyfikatów wieloznacznych. Te dwie rzeczy wzajemnie się wykluczają. Musielibyśmy uzyskiwać certyfikat (lub dwa) za każdym razem, gdy wdrażana byłaby nowa strona Q&A (bądź dowolny inny serwis). Znacznie komplikuje to proces wdrażania i albo a.) powoduje odrzucanie klientów SNI (obecnie około 2% ruchu), albo b.) wymaga znacznie większych niż nasze przestrzeni adresowych IP.
Innym powodem, dla którego chcemy mieć kontrolę nad certyfikatem, jest to, że potrzebujemy instalować dokładnie takie same certyfikaty zarówno w lokalnych modułach równoważenia obciążenia, jak i w systemach dostarczających CDN/proxy. Dopóki tego nie zrobimy, nie możemy we wszystkich przypadkach awaryjnie przełączać ruchu (z dala od proxy). Każdy, kogo certyfikat przypisano do serwera z użyciem HPKP (HTTP Public Key Pinning), nie przejdzie walidacji. Oceniamy, czy wdrożyć HPKP1, ale jesteśmy przygotowani na zrobienie tego później.
Zauważyłem wiele zmarszczonych brwi u tych, którzy widzieli nasz główny certyfikat, zawierający wszystkie domeny podstawowe i symbole wieloznaczne. Oto jak wygląda:
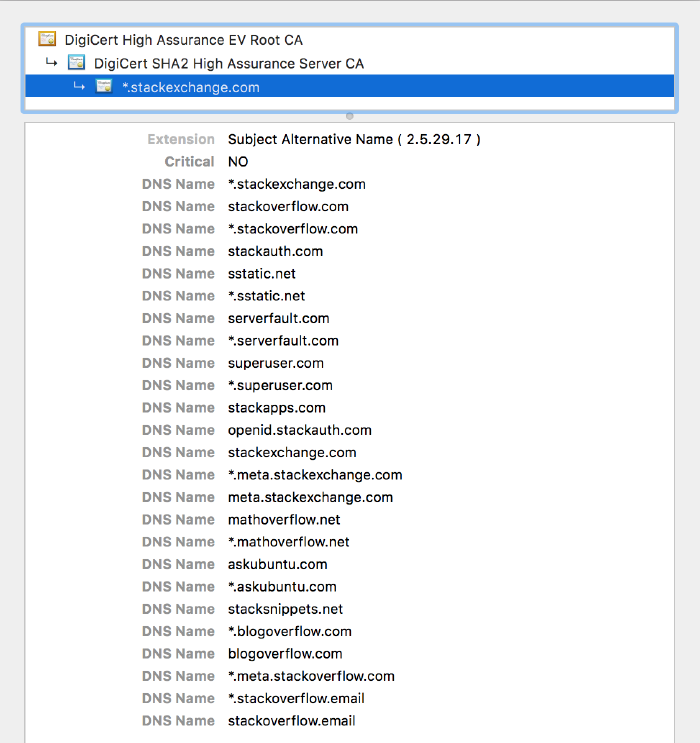
Po co to robić? Cóż, prawdę mówiąc, DigiCert zajmuje się tym na nasze zlecenie. Po co przechodzić przez kłopot związany z ręcznym łączeniem certyfikatu przy każdej zmianie? Po pierwsze dlatego, że chcieliśmy obsługiwać jak najwięcej ludzi. Włączając w to klientów, którzy nie obsługują SNI (na przykład gdy zaczynaliśmy, sporym wydarzeniem był Android 2.3). Również z powodu HTTP/2 i realizmu. Za chwilę się tym zajmiemy.
Podrzędne mety (meta.*.stackexchange.com)
Jedną z zasad sieci Stack Exchange jest to, że musi istnieć miejsce, w którym można
rozmawiać o każdej stronie Q&A. Nazywamy to „drugim
miejscem”. Na
przykład meta.gaming.stackexchange.com istnieje po to, aby rozmawiać
o gaming.stackexchange.com. Dlaczego tak bardzo się to liczy? Cóż, nie
bardzo. W tym przypadku interesuje nas tylko domena. Ma 4 poziomy głębokości.
Omówiłem to już
wcześniej,
lecz na czym skończyliśmy? Pierwszy problem: *.stackexchange.com pokrywa
gaming.stackexchange.com (i setki innych stron), lecz nie pokrywa
meta.gaming.stackexchange.com. RFC 6125 (sekcja
6.4.3) stwierdza:
Klient NIE POWINIEN próbować dopasować przedstawionego identyfikatora, w którym symbol wieloznaczny zawarty jest w etykiecie inaczej, niż na najbardziej lewostronnej pozycji (np. nie powinien dopasować
bar.*.example.net).
Oznacza to, że nie możemy mieć symbolu wieloznacznego
meta.*.stackexchange.com. Cóż, cholera jasna. Co więc robimy?
-
Opcja 1: wdrożenie certyfikatów SAN.
-
Potrzebowalibyśmy 3 (limit wynosi ~100 domen na jeden), potrzebowalibyśmy przeznaczyć 3 adresy IP, a także skomplikować proces odpalania nowych witryn (dopóki nie zmieni się schemat, co już się stało).
-
Musielibyśmy przez cały czas opłacać 3 niestandardowe certyfikaty na CDN-ie/proxy.
-
Musielibyśmy mieć wpisy DNS-owe dla każdej podrzędnej strony meta zgodnie ze schematem
meta.*- Z uwagi na zasady działania DNS-u musielibyśmy tak naprawdę dodawać wpis w DNS-ie dla każdej osobnej strony, komplikując odpalenia stron i ich utrzymywanie.
-
-
Opcja 2: przenieść wszystkie domeny do
*.meta.stackexchange.com?-
Mielibyśmy bolesne przenosiny, ale jednorazowo, i uprościłoby to cały proces utrzymania oraz certyfikaty.
-
Musielibyśmy zbudować globalny system logowania (tu szczegóły).
-
Rozwiązanie to powoduje dodatkowo problem z
includeSubDomainspodczas obsługi HSTS-owego zaocznego ładowania [ang. HSTS preload lists – przyp. tłum.] (tu szczegóły).
-
-
Opcja 3: Udało nam się, zamykamy kram.
- To najłatwiejsze wyjście, ale nie zostało zaakceptowane.
Zbudowaliśmy globalny system logowania się użytkowników,
a później przenieśliśmy podrzędne domeny meta (używając 301-ek) – są już teraz
w swoich nowych domach; przykładem może być
https://gaming.meta.stackexchange.com/. Po
tej operacji zdaliśmy sobie sprawę, jakim problemem będą listy zaocznego ładowania
z tego prostego powodu, że domeny te kiedykolwiek istniały. Omówię to pod
koniec, bo jeszcze nad tym pracujemy. Zwróć uwagę, że te problemy
są odzwierciedlane w naszej drodze ku takim rzeczom jak meta.pt.stackoverflow.com,
ale były bardziej ograniczone w skali, gdyż istnieją jedynie 4 nieanglojęzyczne
wersje Stack Overflowa.
Och, samo w sobie spowodowało to kolejny problem. Przenosząc ciasteczka do domeny
najwyższego poziomu i polegając na ich dziedziczeniu w obrębie domen podrzędnych,
musieliśmy teraz przenieść domeny. Na przykład używamy SendGrida do wysyłania e-maili
we (wdrażanym właśnie) nowym systemie. Powód, dla którego wysyła on pocztę
ze stackoverflow.email z odnośnikami kierującymi do sg-links.stackoverflow.email
(wskazywanymi przez rekord CNAME),
jest taki, żeby twoja przeglądarka nie wysyłała żadnych wrażliwych plików
cookie. Gdyby nazwą była sg-links.stackoverflow.com (lub cokolwiek pod
stackoverflow.com), wtedy twoja przeglądarka wysłałaby nasze ciasteczka do nich. To
konkretny przykład nowych rzeczy, ale w obrębie naszego DNS-u istniały również inne
usługi, nieświadczone przez nas. Każda z tych poddomen musiała być przeniesiona lub
wycofana z użycia, aby wydostać się spod naszych domen uwierzytelnionych… albo
wysyłalibyśmy pliki cookie do nieswoich serwerów. Szkoda byłoby wykonywać całą tę
pracę tylko po to, żeby na koniec mieć cookies, które wyciekają do innych serwerów.
Przez chwilę próbowaliśmy to obejść na jednej z instancji przez wprowadzenie serwera pośredniczącego, który przekazywał właściwości Hubspota, usuwając w trakcie pliki cookie. Niestety Hubspot korzysta z dostawcy Akamai, który zaczął traktować naszą instancję HAProxy jak bota i zaczął ją blokować, każdego tygodnia z użyciem innego, jakże zabawnego sposobu. Pierwsze 3 razy były nawet śmieszne. Tak czy inaczej, to naprawdę nie zadziałało. Poszło tak źle, że nigdy więcej tego nie powtórzymy.
Ciekawiło cię dlaczego Stack Overflow Blog znajduje się adresem
https://stackoverflow.blog/? Dokładnie,
bezpieczeństwo. Jest hostowany w zewnętrznej usłudze i dzięki temu zespół marketingu
i inni mogą szybciej iterować. Aby to umożliwić, musieliśmy wyodrębnić go poza domeny
z ciasteczkami.
Powyższe kwestie z domenami podrzędnymi meta wprowadziły również powiązane problemy
z HSTS-em, zaocznym
ładowaniem i dyrektywą includeSubdomains. Później zobaczymy
dlaczego stało się to punktem spornym.
Wydajność: HTTP/2
Dawno temu zwyczajowa mądrość głosiła, że HTTPS był protokołem wolniejszym. I był. Jednak czasy się zmieniły. Nie mówimy już o HTTPS-ie. Mówimy o HTTPS-ie z HTTP/2. Podczas gdy HTTP/2 nie wymaga szyfrowania, w praktyce wymaga. Wynika to z tego, że główne przeglądarki żądają bezpiecznego połączenia, aby umożliwić korzystanie z większości jego funkcji. Możemy cały dzień spierać się o specyfikacje i reguły, ale przeglądarki stanowią rzeczywistość, w której wszyscy żyjemy. Chciałbym, żeby nazwali to po prostu HTTPS/2 i zaoszczędzili każdemu sporo czasu. Drodzy wytwórcy przeglądarek, nie jest za późno. Proszę, usłuchajcie rozsądku, jesteście naszą jedyną nadzieją!
HTTP/2 ma wiele korzyści wydajnościowych, zwłaszcza gdy idzie o wysyłanie zasobów do użytkownika, zanim o nie poprosi, gdy nadarzy się taka okazja. Nie będę szczegółowo pisał o tych zaletach, Ilya Grigorik już wykonał fantastyczną robotę w tym zakresie. Krótko mówiąc, największe optymalizacje (dla nas) obejmują:
- zwielokrotnianie żądań/odpowiedzi,
- wykorzystanie technologii Server Push,
- kompresowanie nagłówków,
- priorytetyzację strumieni,
- zmniejszenie liczby połączeń do źródła.
Hej, moment, a co z tym głupim certyfikatem?
Mniej znaną cechą HTTP/2 jest możliwość wysyłania zawartości z różnych domen, dopóki spełnione są pewne kryteria:
- Nazwy serwerów źródłowych wskazują na ten sam adres IP serwera.
- Serwery źródłowe posługują się tym samym certyfikatem TLS (bingo!).
Rzućmy więc okiem na nasz obecny DNS:
λ dig stackoverflow.com +noall +answer
; <<>> DiG 9.10.2-P3 <<>> stackoverflow.com +noall +answer
;; global options: +cmd
stackoverflow.com. 201 IN A 151.101.1.69
stackoverflow.com. 201 IN A 151.101.65.69
stackoverflow.com. 201 IN A 151.101.129.69
stackoverflow.com. 201 IN A 151.101.193.69
λ dig cdn.sstatic.net +noall +answer
; <<>> DiG 9.10.2-P3 <<>> cdn.sstatic.net +noall +answer
;; global options: +cmd
cdn.sstatic.net. 724 IN A 151.101.193.69
cdn.sstatic.net. 724 IN A 151.101.1.69
cdn.sstatic.net. 724 IN A 151.101.65.69
cdn.sstatic.net. 724 IN A 151.101.129.69
λ dig stackoverflow.com +noall +answer
; <<>> DiG 9.10.2-P3 <<>> stackoverflow.com +noall +answer
;; global options: +cmd
stackoverflow.com. 201 IN A 151.101.1.69
stackoverflow.com. 201 IN A 151.101.65.69
stackoverflow.com. 201 IN A 151.101.129.69
stackoverflow.com. 201 IN A 151.101.193.69
λ dig cdn.sstatic.net +noall +answer
; <<>> DiG 9.10.2-P3 <<>> cdn.sstatic.net +noall +answer
;; global options: +cmd
cdn.sstatic.net. 724 IN A 151.101.193.69
cdn.sstatic.net. 724 IN A 151.101.1.69
cdn.sstatic.net. 724 IN A 151.101.65.69
cdn.sstatic.net. 724 IN A 151.101.129.69
Heeeeej, te adresy IP są zgodne i mają ten sam certyfikat! Oznacza to, że możemy mieć
wszystkie zalety związane z wysyłaniem danych przez serwer HTTP/2 bez szkody dla
użytkowników HTTP/1.1. HTTP/2 ma obsługę push, a HTTP/1.1 dzielenie
domen (przez
sstatic.net). Nie wdrożyliśmy jeszcze serwera push, ale to wszystko jest
przygotowywane.
Jeżeli więc chodzi o wydajność, HTTPS jest tylko środkiem do celu. I nie przeszkadza mi to. Mogę powiedzieć, że naszym głównym dążeniem jest wydajność, a nie bezpieczeństwo. Chcemy bezpieczeństwa, lecz samo bezpieczeństwo w naszej sytuacji nie jest wystarczającym uzasadnieniem dla czasu potrzebnego na wdrożenie HTTPS-u w naszej sieci. Gdy jednak połączysz wszystkie powyższe czynniki, możemy usprawiedliwić ogromną ilość czasu i wysiłku, które są potrzebne, aby to zrobić. W roku 2013 HTTP/2 nie był czymś wielkim, ale zmieniło się to wraz z upowszechnieniem się obsługi i ostatecznie pomogło nam jako czynnik, który pozwolił zainwestować czas w HTTPS.
Warto też zauważyć, że krajobraz HTTP/2 zmienił się nieco podczas wdrożenia. Sieć przeszła ze SPDY do HTTP/2 i z NPN-a do ALPN-a. Nie omówię tego wszystkiego, ponieważ nic w tej przestrzeni nie zrobiliśmy. Obserwowaliśmy i odnosiliśmy korzyści, lecz napędzali to sieciowi giganci. Jeżeli jednak cię to ciekawi, Cloudflare ma dobre sprawozdanie z tych posunięć.
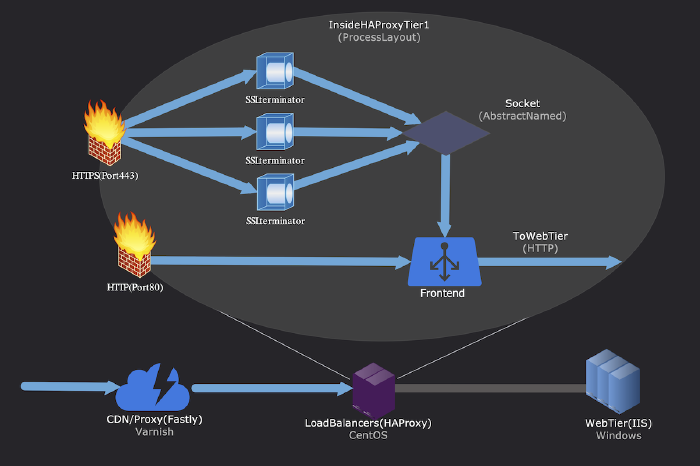
HAProxy: obsługa HTTPS-u
Podstawową obsługę HTTPS-u wdrożyliśmy w HAProxy w roku 2013. Dlaczego HAProxy? Ponieważ już z niego korzystaliśmy, a obsługa została dodana jeszcze w 2013 (jako GA w 2014) wraz z wersją 1.5. Przez jakiś czas mieliśmy serwer nginx umieszczony przed HAProxy (jak można zauważyć w ostatnim wpisie w blogu). Jednak proste rzeczy okazują się często lepsze, zaś wyeliminowanie wielu problemów związanych z połączeniami, wdrażaniem i ogólną złożonością zwykle bywa dobrym pomysłem.
Nie będę tu opisywał wielu szczegółów, bo zwyczajnie nie ma tu zbyt wiele do omówienia. HAProxy fabrycznie obsługuje HTTPS z użyciem OpenSSL-a od wersji 1.5, a konfiguracja jest prosta. Najważniejsze cechy naszej konfiguracji to:
-
Działanie w oparciu o 4 procesy:
- 1 przeznaczony do obsługi HTTP/front-endu,
- 2–4 przeznaczone do ustanawiania połączeń HTTPS.
-
HTTPS-owe front-endy są połączone z HTTPS-owymi back-endami przez abstrakcyjne gniazdo nazwane (znacznie obniża to ogólny narzut wydajnościowy).
-
Każdemu front-endowi lub „poziomowi” (mamy 4: Primary, Secondary, Websockets i dev) odpowiada proces nasłuchu
:443. -
Dołączamy nagłówki żądań (i usuwamy te, które chcesz wysłać – niezła próba) podczas przekazywania do poziomu webowego, aby wskazać skąd pochodziło połączenie.
-
Używamy zestawu szyfrów Modern rekomendowanego przez Mozillę. Uwaga: nie jest to ten sam zestaw, który działa na naszej CDN.
Pierwszym i względnie prostym krokiem była obsługa końcówki :443 przez HAProxy
z wykorzystaniem ważnych certyfikatów SSL-owych. Z perspektywy czasu była to tylko
mała próbka wymaganego wysiłku.
Oto logiczny układ tego, co opisałem wyżej… potem omówimy tę małą chmurę z przodu:
CDN/proxy: przeciwdziałanie latencji
Jedną z rzeczy w Stack Overflow, z których jestem najbardziej dumny, jest wydajność naszego stosu. Niezłe, prawda? Prowadzisz dużą witrynę internetową na małym zestawie serwerów w pojedynczym centrum danych? Nie. Nie do końca. Nie tym razem. Chociaż czymś świetnym jest bycie wydajnym w pewnych przypadkach, to gdy chodzi o opóźnienia, nagle staje się to czymś problematycznym. Nigdy nie potrzebowaliśmy wielu serwerów. Nigdy nie musieliśmy rozbudowywać się do wielu lokalizacji (chociaż tak, mamy inną dla DR [zapasowego centrum danych – przyp. tłum.]). Tym razem to jest problem. Nie możemy (jeszcze!) Rozwiązać fundamentalnych problemów z latencją ze względu na prędkość światła. Powiedziano nam, że pracuje nad tym ktoś inny, lecz doszło do drobnego niepowodzenia, z którym wiązały się łzy w czasoprzestrzennej tkance i utrata myszoskoczków.
Jeżeli chodzi o opóźnienia, spójrzmy na liczby. Wokół równika jest niemal dokładnie 40 000 km (najgorszy przypadek dla prędkości światła w obie strony). Prędkość światła to 299 792 458 m/sekundę w próżni. Niestety, sporo osób posługuje się tą liczną, ale większość światłowodów nie znajduje się w próżni. Realistycznie wiele z nich jest 30–31% wolniejsza. Mamy więc do czynienia z:
40 075 000 m ÷ (299 792 458 m/s × 0,70) = 0,191 sekundy (lub 191 ms)
na podróż w dwie strony, w najgorszym przypadku, prawda?
Cóż… nie, niezupełnie. Dodatkowo zakłada się optymalną ścieżkę, lecz przejście między dwoma miejscami docelowymi w Internecie bardzo rzadko jest linią prostą. Istnieją routery, przełączniki, bufory, kolejki procesorów i wszelkiego rodzaju dodatkowe, małe opóźnienia po drodze. Sumują się do wymiernego opóźnienia. Nie wspominajmy nawet o Marsie, jeszcze.
Dlaczego więc ma to znaczenie dla Stack Overflowa? To obszar, w którym wygrywa chmura. Jest bardzo prawdopodobne, że serwer dostawcy chmury, na który trafiasz, jest umiejscowiony stosunkowo blisko. U nas tak nie jest. Z powodu bezpośredniego połączenia im dalej oddalasz się od naszych centrów danych w Nowym Jorku lub w Denver (w zależności od tego, które z nich jest aktywne), tym większe staje się wrażenie spowolnienia. Gdy chodzi o HTTPS, mamy do czynienia z dodatkową drogą w obie strony, żeby negocjować połączenie przed wysłaniem jakichkolwiek danych. To w najlepszych okolicznościach (chociaż sytuacja poprawia się w przypadku TLS-u 1.3 i 0-RTT). Ilya Grigorik ma tutaj obszerne podsumowanie tego tematu.
Dochodzimy do Cloudflare’a i Fastly’ego. HTTPS nie był projektem wdrożonym w silosie; czytając dalej, zobaczysz, że po drodze krzyżuje się kilka innych projektów. W przypadku lokalnego punktu końcowego HTTPS-u dla użytkownika (aby zminimalizować wspomniany czas podróży w dwie strony) szukaliśmy paru głównych kryteriów:
- lokalne zakańczanie HTTPS-u,
- ochrona przed DDoS-em,
- funkcja CDN-u,
- wydajność taka sama lub większa niż przy bezpośrednim podłączaniu do nas.
Przygotowanie: chronometraż klientów
Przed przejściem na serwer pośredniczący należało przeprowadzić testy
wydajnościowe. Aby to zrobić, skonfigurowaliśmy pełną sekwencję pomiarów czasowych,
żeby uzyskać metryki wydajności z przeglądarek. Od lat przeglądarki zawierają
mechanizm mierzenia czasów działania osiągalny z użyciem JavaScriptu przez
window.performance. Śmiało, otwórz
inspektora i wypróbuj! Chcemy być bardzo transparentni w tej kwestii, dlatego
szczegóły są udostępnione na
teststackoverflow.com od pierwszego dnia naszego
działania. Nie są przesyłane żadne poufne dane, tylko identyfikatory URI zasobów
ładowanych bezpośrednio przez stronę wraz z czasami. Dla każdego zarejestrowanego
wczytywania strony otrzymujemy czasy, które wyglądają następująco:
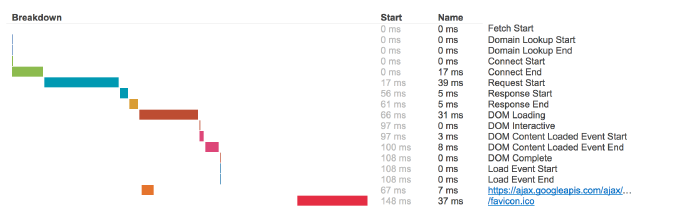
Obecnie próbujemy rejestrować wydajność czasową dla 5% ruchu. Proces nie jest skomplikowany, ale musiały zostać zbudowane wszystkie kawałki:
- Przekształć czasy do JSON-a.
- Przesłać czasy po zakończeniu ładowania strony.
- Przekazać czasy do naszej wewnętrznej usługi Traffic Processing Service
(która ma raporty). - Przechowywać czasy w klastrowanym magazynie kolumn SQL Servera.
- Przekaźnik agreguje czasy do Bosuna (przez BosunReporter.NET-a).
W rezultacie mamy teraz świetny wykaz faktycznej wydajności użytkowników z całego świata w czasie rzeczywistym, który możemy łatwo przeglądać, używać do generowania ostrzeżeń i wykorzystywać do oceny wpływu dowolnych zmian. Oto widok napływających pomiarów czasowych:
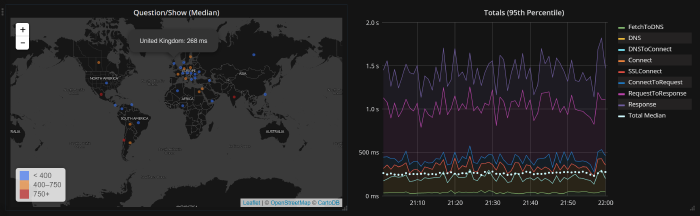
Na szczęście mamy wystarczająco dużo stałego ruchu, aby uzyskać przydatne dane. W tym momencie jesteśmy w posiadaniu danych złożonych z ponad 5 miliardów pomiarów (i liczba ta ciągle rośnie), które pomagają nam podejmować decyzje. Oto ich krótki przegląd:

Okej, mamy więc teraz bazowe dane. Czas przetestować kandydatów do konfiguracji CDN-u/proxy.
Cloudflare
Oceniliśmy wielu dostawców proxy z funkcją CDN/DDoS. Wybraliśmy Cloudflare’a na podstawie ich infrastruktury, szybkości reakcji i obietnicy Railguna. Jak więc możemy sprawdzić w jaki sposób mogłoby wyglądać życie za Cloudflare’em na całym świecie? Ile serwerów musielibyśmy skonfigurować, żeby uzbierać wystarczającą liczbę pomiarów? Żadnego!
Stack Overflow ma w tym miejscu doskonałe źródło: miliardy odwiedzin
miesięcznie. Pamiętasz pomiary czasów dla klientów, o których właśnie rozmawialiśmy?
Mamy już dziesiątki milionów użytkowników, którzy odwiedzają nas każdego dnia, więc
dlaczego ich nie zapytać? Możemy to zrobić, osadzając <iframe> na stronach Stack
Overflowa. Cloudflare był już wcześniej naszym hostem dla
cdn.sstatic.net (współdzielona, statyczna domena dla
treści bez plików cookie), ale było to wykonane z użyciem DNS-owego rekordu
CNAME (my obsługiwaliśmy DNS, który
wskazywał na ich DNS). Jednak aby używać Cloudflare’a jako serwera proxy,
potrzebowaliśmy z ich użyciem obsługiwać nasz własny DNS. Więc najpierw musieliśmy
przetestować wydajność ich DNS-u.
Praktycznie rzecz ujmując, aby przetestować wydajność, musieliśmy wydelegować im
domenę drugiego poziomu, lecz nie something.stackoverflow.com, która mogłaby mieć
różne rekordy typu glue i czasami
nie być obsługiwana w ten sam sposób (powodując 2 wyszukiwania). Wyjaśniając: domeny
najwyższego poziomu
(ang. Top-Level Domains, skr. TLD) to takie rzeczy jak .com, .net, .org,
.dance, .duck, .fail, .gripe, .here, .horse, .ing, .kim, .lol,
.ninja, .pink, .red, .vodka i .wtf. Nie, nie
żartuję (a tu jest
pełna lista). Domeny drugiego
poziomu (ang. Second-Level
Domains, skr. SLD) są o jeden poziom niżej, co dla większości stron wyglądałoby:
stackoverflow.com, superuser.com itd. To jest to, czego potrzebujemy, żeby
przetestować zachowanie i wydajność. Tym sposobem narodził się
teststackoverflow.com. Dzięki tej nowej domenie mogliśmy przetestować wydajność
DNS-u w obrębie całego świata. Osadzając <iframe> dla pewnego odsetka
odwiedzających (włączaliśmy i wyłączaliśmy go przy każdym teście), mogliśmy łatwo
uzyskać dane z każdej konfiguracji DNS-u i hostingu.
Pamiętaj, że ważne jest, aby testować co najmniej przez ~24 godziny. Zachowanie internetu zmienia się w ciągu dnia, kiedy ludzie nie śpią bądź przesyłają strumieniowo treści z serwisu Netflix na całym świecie, przechodząc przez strefy czasowe. Aby zmierzyć jeden kraj, naprawdę potrzebujesz całego dnia. Najlepiej robić to w dni powszednie (np. nie w połowie soboty). Pamiętaj też, sraczka się zdarza. To przytrafia się cały czas. Wydajność internetu nie jest stabilna; mamy dane, aby tego dowieść.
Nasze początkowe założenia określały, że stracimy część wydajności ładowania strony przechodząc przez Cloudflare’a (dodatkowy przeskok niemal zawsze zwiększa opóźnienie), ale nadrobilibyśmy to wzrostem wydajności DNS-u. Od strony DNS-u opłaciło nam się to. Cloudflare miał serwery DNS o wiele bardziej lokalne dla użytkowników niż my w pojedynczym centrum danych. Wydajność była tam o wiele lepsza. Mam nadzieję, że wkrótce znajdziemy czas na opublikowanie tych danych. To po prostu wiele do przetworzenia (i obsługi), a czas nie jest czymś, czego mam teraz pod dostatkiem.
Potem zaczęliśmy testować wydajność ładowania strony, korzystając z proxy
teststackoverflow.com przez Cloudflare’a, ponownie w <iframe>. Widzieliśmy, że
Stany Zjednoczone i Kanada są nieco wolniejsze (z powodu dodatkowego przeskoku), ale
reszta świata wypadała na równi lub lepiej. Było to zgodne z ogólnymi oczekiwaniami
i kontynuowaliśmy działanie za siecią Cloudflare’a. Kilka ataków DDoS po drodze nieco
przyspieszyło tę migrację, ale to już inna historia. Dlaczego zaakceptowaliśmy trochę
powolniejsze wyniki w Stanach Zjednoczonych i Kanadzie? Cóż, w przypadku większości
stron ładowanie to ~200–300 ms, co dalej jest cholernie szybkie; ale nie lubimy
przegrywać. Pomyśleliśmy, że w odzyskaniu tej wydajności pomoże nam
Railgun.
Po zakończeniu wszystkich testów musieliśmy poskładać klocki odpowiedzialne za ochronę przed atakami DDoS. Wymagało to zainstalowania się dodatkowych, wyspecjalizowanych dostawców usług internetowych w naszym centrum danych, aby można było łączyć się z CDN-em/proxy. Poza tym ochrona przed DDoS-ami z użyciem proxy nie jest zbyt skuteczna, jeżeli możesz ją zwyczajnie obejść. Oznaczało to, że serwowaliśmy dane z użyciem 4 dostawców usług internetowych na centrum danych, z 2 zestawami routerów, z których wszystkie obsługują protokół BGP z pełnymi tabelami. Oznaczało to również 2 nowe moduły równoważenia obciążenia, przeznaczone dla ruchu obsługiwanego przez CDN/proxy.
Railgun
W owym czasie wspomniana konfiguracja oznaczała również 2 dodatkowe „pudełka” tylko dla Railguna. Sposób działania Railguna polega na buforowaniu ostatniego rezultatu dla danego URL-a w memcached: lokalnie i po stronie Cloudflare’a. Gdy Railgun jest włączony, każda strona (poniżej pewnego progu rozmiaru) jest na wyjściu buforowana. Przy kolejnym żądaniu, jeżeli w brzegowej pamięci podręcznej Cloudflare’a i naszej pamięci podręcznej znaleziony zostanie rekord (kluczowany URL-em), nadal żądamy jej od serwera WWW, lecz zamiast wysyłać całą stronę z powrotem do Cloudflare’a, wysyłamy tylko różnicę. Ta różnica jest nakładana na zawartość z ich pamięci podręcznej i przesyłana z powrotem do klienta. Z powodu charakteru użytego kanału komunikacji oznaczało to również przeniesienie kompresji gzip związanej z transmisją z 9 serwerów WWW obsługujących Stack Overflowa do 1 aktywnej „skrzynki” z Railgunem. Musiała to być więc całkiem wydajna maszyna. Zwracam na to uwagę, bo na naszej drodze to wszystko musiało być ocenione, zakupione i wdrożone.
Pomyśl na przykład o 2 użytkownikach wyświetlających witrynę z pytaniem. Zrób zdjęcie każdej przeglądarce. To prawie taka sama strona, więc różnica jest niewielka. To ogromna optymalizacja, jeżeli jesteśmy w stanie przesyłać jedynie tę różnicę przez większą część drogi do użytkownika.
Ogólnie rzecz ujmując, celem jest tu zmniejszenie ilości przesyłanych danych w nadziei na poprawę wydajności. Kiedy to zadziałało, faktycznie taki był tego efekt. Railgun miał również inną, ogromną zaletę: żądania nie były nowymi połączeniami. Inną konsekwencją latencji jest czas trwania i prędkość „rozkręcania się” powolnego startu [ang. slow-start – przyp. tłum.] w protokole TCP, będącego częścią mechanizmu kontrolowania przeciążeń, który pomaga utrzymywać Internet w ruchu. Railgun podtrzymuje stałe połączenie z serwerami brzegowymi Cloudflare’a i zwielokrotnia żądania użytkowników tak, że wszystkie przechodzą przez połączenie przygotowane wcześniej, które nie jest mocno opóźniane powolnym startem. Mniejsze różnice zmniejszyły też ogólną potrzebę rozruchu.
Niestety, nigdy nie sprawiliśmy, aby Railgun bezproblemowo działał na dłuższą metę. O ile mi wiadomo prowadziliśmy (w tamtym czasie) największe wdrożenie tej technologii i eksploatowaliśmy bardziej niż kiedykolwiek wcześniej. Chociaż przez ponad rok próbowaliśmy rozwiązać ten problem, ostatecznie poddaliśmy się i poszliśmy dalej. Po prostu nie przynosiło nam to więcej, niż ostatecznie nas kosztowało. Minęło już jednak kilka lat. Gdy rozważasz użycie Railguna, warto ocenić aktualną wersję, z wprowadzonymi w niej ulepszeniami, i zdecydować samodzielnie.
Fastly
Przejście na Fastly’ego odbyło się stosunkowo niedawno, ale ponieważ zajmujemy się tematem CDN-u/proxy, omówię go teraz. Same przenosiny nie były strasznie ciekawe, ponieważ większość elementów potrzebnych do współpracy z dowolnym serwerem proxy wykonano już w epoce Cloudflare’a (p. wyżej). Jednak oczywiście każdy zapyta: dlaczego się na to przenieśliśmy? Chociaż Cloudflare był bardzo atrakcyjny pod wieloma względami - głównie: wiele centrów danych, stabilne ceny za przesył i obecny DNS – nie był dla nas najlepszą opcją. Potrzebowaliśmy kilku dopasowanych do nas rzeczy, które Fastly po prostu zrobił: większa elastyczność na serwerach brzegowych, szybsza propagacja zmian i możliwość pełnej automatyzacji w rozsyłaniu konfiguracji. Nie oznacza to, że Cloudflare jest zły, po prostu nie pasował już do Stack Overflowa.
Ponieważ czyny mówią więcej, niż słowa: gdybym nie cenił wysoko Cloudflare’a, mój osobisty blog nie byłby teraz umieszczony za ich systemami. Hejka! Czytasz go.
Główną cechą Fastly’ego, która była dla nas tak interesująca, był Varnish i VCL. To sprawia, że system brzegowy jest wysoce konfigurowalny, więc funkcje, których Cloudflare nie mógł łatwo wdrożyć (ponieważ mogą mieć wpływ na wszystkich klientów), mogliśmy definiować sami. Jest to po prostu inna koncepcja architektoniczna w sposobie działania tych dwóch firm, a wysoce konfigurowalne podejście z użyciem kodu bardzo nam odpowiada. Podobało nam się również, jak bardzo byli otwarci na szczegóły infrastruktury na konferencjach, czatach itp.
Oto przykład, w którym VCL jest bardzo przydatny. Niedawno wdrożyliśmy .NET-a 4.6.2, który zawierał bardzo paskudny błąd ustawiający maksymalną ważność odpowiedzi w pamięci podręcznej na ponad 2 000 lat. Najszybszym sposobem zapobieżenia temu problemowi we wszystkich naszych usługach, których dotyczył, była podmiana nagłówka pochodzącego z pamięci podręcznej na serwerze brzegowym, w sytuacjach, w których było to wymagane. Kiedy to piszę, aktywny jest następujący VCL:
sub vcl_fetch {
if (beresp.http.Cache-Control) {
if (req.url.path ~ "^/users/flair/") {
set beresp.http.Cache-Control = "public, max-age=180";
} else {
set beresp.http.Cache-Control = "private";
}
}
}
sub vcl_fetch {
if (beresp.http.Cache-Control) {
if (req.url.path ~ "^/users/flair/") {
set beresp.http.Cache-Control = "public, max-age=180";
} else {
set beresp.http.Cache-Control = "private";
}
}
}
Pozwala nam to buforować flarę użytkownika przez 3 minuty (ponieważ jest to sowita liczba bajtów) i pominąć wszystko inne. To łatwe do wdrożenia, globalne rozwiązanie pozwalające obejść palący problem zatruwania pamięci podręcznej we wszystkich aplikacjach. Jesteśmy bardzo, bardzo zadowoleni ze wszystkiego, czego możemy teraz dokonać na serwerach brzegowych. Na szczęście mamy Jasona Harveya, który zebrał kawałki VCL i napisał zautomatyzowanego dystrybutora naszej konfiguracji. Musieliśmy ulepszyć istniejące biblioteki w Go, sprawdź więc fastlyctl – kolejny open source’owy fragment, który z tego wyszedł.
Innym ważnym aspektem Fastly’ego (który występował też w usłudze Cloudflare’a, ale nigdy nie wykorzystaliśmy go z uwagi na koszty) jest możliwość korzystania z własnego certyfikatu. Jak wspomnieliśmy wcześniej, używamy go już na etapie przygotowania wysyłki HTTP/2. Jednak Fastly nie robi czegoś, co robi Cloudflare: DNS-u. Musimy więc to teraz rozwiązać. Czy ten łańcuch zależności nie jest zabawny?
Globalny DNS
Przechodząc z Cloudflare’a do Fastly’ego, musieliśmy ocenić i wdrożyć użycie nowych (dla nas), globalnych dostawców DNS-u. Jest to osobno opisane w zupełnie innym wpisie, autorstwa Marka Hendersona. W trakcie kontrolowaliśmy też:
- nasze własne serwery DNS-u (nadal działające jako rozwiązanie awaryjne),
- serwery Name.com (dla przekierowań niewymagających HTTPS-u),
- DNS-y Cloudflare’a,
- DNS-y Route 53,
- DNS-y Google’a,
- DNS-y Azure’a,
- … i kilka innych (do testów).
To był sam w sobie odrębny projekt. Musieliśmy wymyślić sposoby, aby zrobić to
skutecznie, i tak narodził się
DNSControl. Jest
to teraz projekt typu open source,
dostępny na GitHubie, napisany
w Go. W skrócie: wprowadzamy zmianę w konfiguracji JavaScriptu
do Gita i jest ona wdrażana na całym świecie w niecałą minutę. Oto przykładowa
konfiguracja na jednej z naszych witryn z uproszczonym DNS-em,
askubuntu.com:
D('askubuntu.com', REG_NAMECOM,
DnsProvider(R53,2),
DnsProvider(GOOGLECLOUD,2),
SPF,
TXT('@', 'google-site-verification=PgJa[…]2fbQhES7-Q9cv8'), // webmasters
A('@', ADDRESS24, FASTLY_ON),
CNAME('www', '@'),
CNAME('chat', 'chat.stackexchange.com.'),
A('meta', ADDRESS24, FASTLY_ON),
END)
D('askubuntu.com', REG_NAMECOM,
DnsProvider(R53,2),
DnsProvider(GOOGLECLOUD,2),
SPF,
TXT('@', 'google-site-verification=PgJa[…]2fbQhES7-Q9cv8'), // webmasters
A('@', ADDRESS24, FASTLY_ON),
CNAME('www', '@'),
CNAME('chat', 'chat.stackexchange.com.'),
A('meta', ADDRESS24, FASTLY_ON),
END)
Okej, świetnie, jak chcecie przetestować czy to wszystko działa? Pomiary czasów klienckich! Te, które omawialiśmy wyżej, pomogą nam przetestować całe to DNS-owe wdrożenie z użyciem faktycznych danych pochodzących ze świata, a nie z symulacji. Oczywiście potrzebujemy też sprawdzić, czy wszystko po prostu działa.
Testowanie
Przy testowaniu wydajności w trakcie wdrażania bardzo pomocne były pomiary czasów klienckich. Jednak to nie było dobre wyjście, gdy chodzi o testowanie konfiguracji. Koniec końców pomiary czasów klienta są świetną sprawą, gdy chcemy oglądać ich wyniki, ale większość błędów konfiguracji skutkuje brakiem ładowania strony, a zatem brakiem jakichkolwiek czasów. Musieliśmy więc zbudować httpUnit (tak, zespół przekonał się później o konflikcie nazw…). Jest to obecnie kolejny open source’owy projekt napisany w Go. Przykładowa konfiguracja dla teststackoverflow.com:
[[plan]]
label = "teststackoverflow_com"
url = "http://teststackoverflow.com"
ips = ["28i"]
text = "<title>Test Stack Overflow Domain</title>"
tags = ["so"]
[[plan]]
label = "tls_teststackoverflow_com"
url = "https://teststackoverflow.com"
ips = ["28"]
text = "<title>Test Stack Overflow Domain</title>"
tags = ["so"]
[[plan]]
label = "teststackoverflow_com"
url = "http://teststackoverflow.com"
ips = ["28i"]
text = "<title>Test Stack Overflow Domain</title>"
tags = ["so"]
[[plan]]
label = "tls_teststackoverflow_com"
url = "https://teststackoverflow.com"
ips = ["28"]
text = "<title>Test Stack Overflow Domain</title>"
tags = ["so"]
Testowanie było ważne, ponieważ po drodze wymienialiśmy zapory sieciowe, certyfikaty, powiązania, przekierowania itp. W trakcie musieliśmy upewniać się, że każda zmiana była dobra, zanim aktywowaliśmy ją dla użytkowników (wdrażając najpierw na naszych dodatkowych modułach równoważenia obciążenia). Dzięki httpUnitowi mogliśmy to zrobić i uruchomić zestaw testów integracyjnych, żeby upewnić się, iż nie wystąpiły usterki regresywne.
Istnieje kolejne narzędzie, które opracowaliśmy wewnętrznie (przez naszego uroczego
Toma Limoncelliego), aby łatwiej zarządzać grupami
wirtualnych adresów IP
[ang. Virtual IP Addresses – przyp. tłum.] w modułach równoważenia
obciążenia. Testujemy je na nieaktywnym module za pośrednictwem dodatkowego zakresu,
a następnie przenosimy cały ruch, pozostawiając poprzedniego mastera w znanym, dobrym
stanie. Gdy coś pójdzie nie tak, cofamy się. Gdy wszystko pójdzie dobrze (jej!),
wprowadzamy zmiany również do tego modułu równoważenia obciążenia. Narzędzie nazywa
się keepctl (skrót od keepalived control) – wypatruj, gdy otwarty zostanie jego kod
źródłowy, jeżeli tylko pozwoli na to czas.
Aplikacje / kod
Przygotowywanie aplikacji
Niemal wszystko opisane wyżej związane było z pracami infrastrukturalnymi. Zajmuje się tym zwykle zespół kilku innych inżynierów ds. niezawodności witryny w Stack Overflow, a moim zadaniem jest porządkowanie tego wszystkiego. Wiele więcej trzeba było też zrobić w samych aplikacjach. To długa lista. Napiłbym się kawy i zjadł Snickersa.
Jedną z ważnych rzeczy, na które należy zwrócić uwagę, jest fakt, że architektura
stron z pytaniami i odpowiedziami typu Stack Overflow i Stack
Exchange,
jest wielo-dzierżawiona. Oznacza to, że
jeżeli trafisz na stackoverflow.com lub superuser.com, albo
bicycles.stackexchange.com, trafisz dokładnie w to samo miejsce. Wchodzisz
do tego samego procesu w3wp.exe na dokładnie tym samym serwerze. Na podstawie
nagłówka Host
wysyłanego przez przeglądarkę zmieniamy kontekst żądania. Parę z poniższych elementów
stanie się bardziej zrozumiałymi, jeżeli zrozumiesz, że Current.Site w naszym
kodzie to strona z żądania. Rzeczy takie jak Current.Site.Url()
i Current.Site.Paths.FaviconUrl są wywodzone z tego głównego konceptu.
Inny sposób wyjaśnienia tej koncepcji/konfiguracji: możemy uruchomić całą sieć Q&A na pojedynczym procesie jednego serwera, a wy byście się o tym nie dowiedzieli. Dziś na każdym z 9 serwerów uruchamiamy pojedynczy proces, głównie po to, aby zyskać redundancję i możliwość regularnej przebudowy zasobów.
Globalne logowanie
Całkiem sporo z prowadzonych projektów samych w sobie wydawało się dobrymi pomysłami (i takimi były), lecz stanowiły część większego obrazu HTTPS-u. Login był jednym z takich projektów. Omawiam go najpierw, ponieważ został wprowadzony znacznie wcześniej niż pozostałe zmiany opisywane dalej.
Przez pierwsze 5–6 lat istniał Stack Overflow (i Stack Exchange), logowaliście się do
określonej witryny. Na przykład każda witryna stackoverflow.com,
stackexchange.com i gaming.stackexchange.com miała własne, przypisanej do niej
pliki cookie. Warto w tym miejscu zaznaczyć: logowanie
do meta.gaming.stackexchange.com zależało od pliku cookie napływającego z poddomeny
gaming.stackexchange.com. To strony „meta”, o których rozmawialiśmy wcześniej, przy
okazji omawiania certyfikatów. Ich mechanizmy logowania się użytkowników były
powiązane, zawsze następowało logowanie przez domenę nadrzędną. Technicznie nie miało
to większego znaczenia, ale z punktu widzenia użytkownika było do niczego. Trzeba
było zalogować się do każdej witryny. „Naprawiliśmy”
to z użyciem
mechanizmu „global auth”, który był elementem <iframe> na stronie, na której
wszyscy się logowali przez stackauth.com, jeżeli byli zalogowani gdzie indziej. Lub
też próbowali. Doświadczenie użytkownika było przyzwoite, ale wyskakujący pasek
z poleceniem kliknięcia, żeby przeładować stronę i zalogować się, nie był zbyt
wspaniały. Moglibyśmy zrobić to lepiej. Aha, i zapytaj Kevina
Montrose’a o tryb prywatny mobilnego
Safari. Wyzywam cię.
Witamy w Universal Login. Skąd nazwa „Universal”? Ponieważ „Global” była już
zajęta. Jesteśmy prostymi ludźmi. Na szczęście ciasteczka też są całkiem proste. Plik
cookie obecny w domenie nadrzędnej (np. stackexchange.com) Zostanie wysłany przez
twoją przeglądarkę do wszystkich poddomen (np. gaming.stackexchange.com). Gdy
patrzysz na naszą sieć z szerszej perspektywy, mamy raptem kilka domen drugiego
poziomu:
askubuntu.com,mathoverflow.net,serverfault.com,stackapps.com,stackexchange.com,stackoverflow.com,superuser.com.
Tak, mamy inne domeny, które do przekierowują do tych,
np. askdifferent.com, ale są to tylko przekierowania
i nie mają przypisanych plików cookie ani zalogowanych użytkowników.
Jest dużo pracy back-endowej, którą tu omawiam (wyrazy uznania dla Geoffa
Dalgasa i Adama
Leara), lecz jej ogólny sens jest taki, że gdy się
logujesz, ustawiamy plik cookie przypisany do tych domen. Robimy to za pośrednictwem
pochodzących ze stron trzecich ciasteczek i okazjonalnych
wartości [ang. nonces –
przyp. tłum.]. Kiedy logujesz się do którejkolwiek z powyższych domen, 6 plików
cookie jest wysyłanych do innych domen za pośrednictwem znaczników <img>
umieszczonych na stronie docelowej, skutecznie cię logując. Nie działa to wszędzie
(w szczególności dziwna jest mobilna wersja Safari), ale stanowi olbrzymią poprawę
w stosunku do tego, co było.
Kod klienta nie jest skomplikowany, wygląda tak:
$.post('/users/login/universal/request', function (data, text, req) {
$.each(data, function (arrayId, group) {
var url = '//' + group.Host +
'/users/login/universal.gif?authToken=' +
encodeURIComponent(group.Token) +
'&nonce=' +
encodeURIComponent(group.Nonce);
$(function () {
$('#footer').append('<img style="display:none" src="' +
url +
'"></img>');
});
});
}, 'json');
$.post('/users/login/universal/request', function (data, text, req) {
$.each(data, function (arrayId, group) {
var url = '//' + group.Host +
'/users/login/universal.gif?authToken=' +
encodeURIComponent(group.Token) +
'&nonce=' +
encodeURIComponent(group.Nonce);
$(function () {
$('#footer').append('<img style="display:none" src="' +
url +
'"></img>');
});
});
}, 'json');
Jednak aby tego wszystkiego dokonać, musimy przejść do uwierzytelniania na poziomie konta (wcześniej było na poziomie użytkownika), zmienić sposób przeglądania plików cookie i sposób, w jaki działa logowanie się do podrzędnych stron meta, jak również zapewnić integrację tych nowych kawałków z innymi aplikacjami. Na przykład Careers (obecnie Talent and Jobs) ma inną bazę kodu. Musieliśmy sprawić, żeby aplikacje te przeglądały pliki cookie i wywoływały aplikację Q&A za pośrednictwem API, aby uzyskać dostęp do konta. Wdrażamy to za pośrednictwem biblioteki NuGet, aby zminimalizować powtarzający się kod. Konkluzja: logujesz się raz i jesteś zalogowany do wszystkich domen. Żadnych komunikatów, żadnych przeładowań strony.
Z technicznego punktu widzenia nie musimy teraz martwić się o to, gdzie znajdują się
domeny *.*.stackexchange.com. Dopóki są pod stackexchange.com, jest
dobrze. Podczas gdy zewnętrznie nie miało to nic wspólnego z HTTPS-em, pozwoliło nam
przenieść rzeczy takie jak meta.gaming.stackexchange.com na
gaming.meta.stackexchange.com bez przerw doświadczanych przez użytkowników. Jest to
jedna wielka, naprawdę brzydka łamigłówka.
Rozwijanie lokalnego HTTPS-u
Żeby poczynić jakiekolwiek postępy w miejscu, w którym się znaleźliśmy, lokalne środowiska muszą jak najbardziej odpowiadać środowiskom dev i production. Na szczęście korzystamy z IIS-a, który sprawia, że jest to całkiem proste w realizacji. Istnieje narzędzie, którego używamy do konfigurowania środowisk rozwojowych, zwane „dev local setup”, ponieważ – raz jeszcze – jesteśmy prostymi ludźmi. Instaluje ono zestaw narzędziowy (Visual Studio, Gita, SSMS-a, itd.), usługi (SQL Servera, Redisa, Elasticsearcha), repozytoria, bazy danych, strony webowe, a także kilka innych części. Podstawową konfigurację narzędziową już mieliśmy, potrzebne nam były tylko certyfikaty SSL-owe/TLS-owe. Skrócona konfiguracja dla Core’a wygląda jak poniżej:
Websites = @(
@{
Directory = "StackOverflow";
Site = "local.mse.com";
Aliases = "discuss.local.area51.lse.com", "local.sstatic.net";
Databases = "Sites.Database", "Local.StackExchange.Meta",
"Local.Area51", "Local.Area51.Meta";
Certificate = $true;
},
@{
Directory = "StackExchange.Website";
Site = "local.lse.com";
Databases = "Sites.Database", "Local.StackExchange",
"Local.StackExchange.Meta", "Local.Area51.Meta";
Certificate = $true;
}
)
Websites = @(
@{
Directory = "StackOverflow";
Site = "local.mse.com";
Aliases = "discuss.local.area51.lse.com", "local.sstatic.net";
Databases = "Sites.Database", "Local.StackExchange.Meta",
"Local.Area51", "Local.Area51.Meta";
Certificate = $true;
},
@{
Directory = "StackExchange.Website";
Site = "local.lse.com";
Databases = "Sites.Database", "Local.StackExchange",
"Local.StackExchange.Meta", "Local.Area51.Meta";
Certificate = $true;
}
)
Kod, który korzysta z powyższego, umieściłem w tym Giście:
Register-Websites.psm1.
Konfigurujemy nasze strony internetowe z użyciem nagłówków Host (dodając je
w aliasach); jeżeli zostało to zlecone, nadajemy im certyfikaty (hmmm, teraz
powinniśmy domyślnie korzystać z $true…); a także przyznajemy tym kontom AppPool
dostęp do baz danych. Okej, teraz możemy więc lokalnie rozwijać oprogramowanie
wykorzystujące https://. Tak, wiem – naprawdę powinniśmy otworzyć źródła tej
konfiguracji, ale musimy w jakiś sposób usunąć niektóre specyficzne dla nas
fragmenty z rozgałęzienia [systemu kontroli wersji –przyp. tłum.]. Pewnego dnia.
Dlaczego jest to ważne? Wcześniej ładowaliśmy statyczną zawartość z /content,
nie z innej domeny. Było to wygodne, ale ukrywało też problemy, takie jak
między-źródłowe żądania (ang. Cross-Origin Requests) związane z między-źródłowym
współdzieleniem
zasobów
(ang. Cross-Origin Resource Sharing, skr. CORS). To, co ładuje się dobrze w obrębie
tej samej domeny i tego samego protokołu, może łatwo zawieść podczas tworzenia
oprogramowania i na produkcji. „U mnie
działa”.
Dzięki skonfigurowaniu CDN-u i domen aplikacyjnych z użyciem tych samych protokołów
i takim układem, który mamy na produkcji, znajdujemy i poprawiamy o wiele więcej
problemów jeszcze zanim opuszczą maszynę programisty. Czy wiesz na przykład, że gdy
dochodzi do przejścia ze strony https:// do http://, przeglądarka nie wysyła
nagłówka
Referer? To
kwestia związana z bezpieczeństwem; w URL-u mogłyby być wrażliwe fragmenty, które
zostałyby wysłane w jawnej postaci tego nagłówka.
„To bzdury, Nick, mamy referery Google’a!”. No tak. Macie. Jednak dlatego, że oni
wyraźnie się na to zgodzili. Gdy spojrzysz na stronę wyszukiwarki Google,
odnajdziesz taką dyrektywę <meta>:
<meta content="origin" id="mref" name="referrer">
<meta content="origin" id="mref" name="referrer">
…i dlatego je od nich dostajesz.
Okej, jesteśmy przygotowani do budowania jakichś rzeczy. Dokąd stąd wyruszymy?
Zawartość mieszana
Od ciebie
Ta prosta nazwa mocno implikuje, że chodzi o stronę zawierającą treści przesyłane przez użytkowników. Jakiego rodzaju problemy z mieszaną zawartości mogły nagromadzić się przez lata? Niestety całkiem sporo. Oto lista rodzajów zawartości przesyłanych przez użytkowników, z którymi musieliśmy się uporać:
http://obrazy w pytaniach, odpowiedziach, tagach, wiki itp.
(wszystkie typy wpisów),http://awatary,http://awatary na czacie (pojawiające się na pasku bocznym strony),http://zdjęcia w profilowych sekcjach „o mnie”,http://obrazy w artykułach centrum pomocy,http://filmy z YouTube’a (włączone np. nagaming.stackexchange.com),http://obrazy w opisach uprawnień,http://obrazy w opowieściach programistów,http://zdjęcia w opisach stanowisk,http://obrazy na stronach firmowych,http://źródła we wstawkach JavaScriptu.
Z każdym wiązały się problemy, ale będę się tu trzymać ciekawszych fragmentów. Uwaga: każde z rozwiązań, o których wspominam, musi być skalowalne, aby działało w setkach witryn i baz danych, biorąc pod uwagę naszą architekturę.
Dla każdego z wymienionych wyżej przypadków (z wyjątkiem fragmentów kodu) istniał
wspólny pierwszy krok do wyeliminowania treści mieszanych. Wyeliminować nowe
mieszane treści. W przeciwnym razie wszystkie porządki będą kontynuowane
w nieskończoność. Zatkaj otwór, a dopiero wtedy opróżnij statek z wody. W tym celu
zaczęliśmy wymuszać osadzanie obrazów wyłącznie z użyciem
https://. Po wykonaniu tej
czynności i zatkaniu dziur mogliśmy zabrać się do sprzątania.
W przypadku obrazów w pytaniach, odpowiedziach i innych typach wpisów musieliśmy
przeprowadzić sporo analiz i zobaczyć, jaką ścieżkę wybrać. Po pierwsze, możemy zająć
się znanym przypadkiem, występującym w więcej niż 90%: stack.imgur.com. Stack
Overflow ma własną hostowaną instancję Imgura, pamiętającą jeszcze czasy przed
moimi. Gdy przesyłasz obraz z użyciem naszego edytora, trafia on tam. Zdecydowana
większość wpisów stosuje to podejście i lata temu dodano odpowiednią obsługę
HTTPS-u. Była to prosta przebudowa całej witryny na zasadzie znajdowania
i zastępowania (nazywamy to ponownym przetwarzaniem Markdowna dla wpisów).
Następnie przeanalizowaliśmy wszystkie pozostałe ścieżki obrazów z użyciem indeksu Elasticsearch dla całej zawartości. Mówiąc my, mam na myśli Samo. Włożył mnóstwo pracy w mieszaną zawartość. Po ujrzeniu, że wiele z najczęściej powtarzających się domen faktycznie obsługuje HTTPS, zdecydowaliśmy się:
-
Wypróbować każde źródło
<img>zhttps://.
Jeżeli to zadziałało, podmienić odnośnik we wpisie. -
Jeżeli źródło nie obsługuje
https://, skonwertować znacznik do odnośnika.
Oczywiście to nie działało po prostu. Okazało się, że wyrażenie regularne używane, aby dopasowywać URL-e nie od lat było popsute i nikt tego nie zauważył… Więc naprawiliśmy je i ponownie wszystko zindeksowaliśmy. Ups.
Zapytano nas: „dlaczego po prostu nie użyć proxy?” Cóż, to szara strefa prawna
i etyczna dla większości naszych treści. Na przykład na
photo.stackexchange.com mamy fotografów, którzy
specjalnie nie używają Imgura, aby zachować wszelkie prawa autorskie. Całkowicie
zrozumiałe. Jeżeli zaczniemy używać proxy i buforować pełen obraz, to w najlepszym
przypadku stanie się to bardzo trudne z prawnego punktu widzenia. Okazuje się, że
z milionów obrazów umieszczonych w Sieci jedynie kilka tysięcy zarówno nie obsługuje
https://, jak i nie są dla nich wysyłane komunikaty 404. Wobec tego zdecydowaliśmy
się nie tworzyć skomplikowanej konfiguracji proxy. Odsetki (znacznie mniej niż 1%)
zwyczajnie nie były w stanie usprawiedliwić takiego działania.
Zbadaliśmy jednak temat budowania proxy. Ile by to kosztowało? Jak wiele miejsca będziemy potrzebować? Czy mamy wystarczającą przepustowość? Znaleźliśmy szacunkowe odpowiedzi na wszystkie te pytania, przy czym niektóre miały różniące się odpowiedzi. Na przykład, czy używać ochrony witryny świadczonej przez Fastly’ego, czy może przejąć ciężar przepustowości pasma z wykorzystaniem łącz dostawcy? Która opcja jest szybsza? Która jest tańsza? Która skalowalna? Naprawdę, to temat na kolejny, odrębny wpis w blogu, ale jeżeli masz konkretne pytania, zadaj je w komentarzach, a ja spróbuję odpowiedzieć.
Na szczęście po drodze balpha przerobił osadzanie
materiałów z YouTube’a, aby naprawić parę rzeczy związanych z HTML-em 5. Zmiana ta
w efekcie ubocznym wymusiła korzystanie przez wszystkich z https://, jej! Wszystko
gotowe.
Z resztą obszarów treści historia była podobna: ubić nową zawartość mieszaną i podmienić istniejącą. Wymagało to zmian w następujących obszarach kodu:
- wpisy,
- profile,
- opowieści programistów,
- centrum pomocy,
- praca / talent,
- strony firmowe.
Zastrzeżenie: fragmenty kodu JavaScript pozostają kwestią nierozwiązaną. Nie jest to takie proste, ponieważ:
-
Żądany zasób może być niedostępny z użyciem
https://(np. biblioteka). -
Ponieważ to JavaScript, możesz po prostu skonstruować dowolny URL. Jest to w zasadzie niemożliwe do wykrycia.
- Jeżeli masz jakiś sprytny sposób, aby to zrobić, powiedz nam proszę. W tym przypadku utknęliśmy w kwestii użyteczność vs bezpieczeństwo.
Od nas
Problemy nie kończą się na zawartości dostarczanej przez użytkownika. Mamy całkiem
sporo bagażu http://. Podczas gdy przenosiny takich rzeczy nie są szczególnie
ciekawe, gwoli „czemu to tyle zajęło?” warto je wyliczyć:
- serwer reklam (Calculon);
- serwer reklam (Adzerk);
- sponsoringi tagów;
- założenia odnośnie JavaScriptu;
- Strefa 51 (dosłownie cała przeklęta strona - to prehistoryczna baza kodu);
- trackery do analityki (Quantcast, GA);
- wstawki JavaScriptu per strona (plug-iny społeczności);
- wszystko pod
/jobsna Stack Overflow (to naprawdę proxy, niespodzianka!); - flara użytkownika;
- …i niemal wszędzie indziej, gdzie w kodzie pojawia się
http://.
JavaScript i odnośniki były nieco bolesne, więc omówię je trochę bardziej szczegółowo.
JavaScript to obszar, o którym niektórzy ludzie zapominają, ale on oczywiście
istnieje. Mieliśmy kilka założeń odnośnie http:// w JavaScripcie, gdzie jedynie
podawaliśmy dalej nazwę hosta. Było też wiele wypracowanych już założeń odnośnie
meta. jako przedrostków dla stron meta. Bardzo wiele. Och, jak wiele. Przyślijcie
pomoc. Jednak teraz ich już nie ma, a serwer renderuje domenowo dookreślone katalogi
główne witryny w naszym obiekcie opcji na górze strony. Wygląda to mniej więcej tak
(w skrócie):
StackExchange.init({
"locale":"en",
"stackAuthUrl":"https://stackauth.com",
"site":{
"name":"Stack Overflow"
"childUrl":"https://meta.stackoverflow.com",
"protocol":"http"
},
"user":{
"gravatar":"<div class=\"gravatar-wrapper-32\"><img src=\"https://i.stack.imgur.com/nGCYr.jpg\"></div>",
"profileUrl":"https://stackoverflow.com/users/13249/nick-craver"
}
});
StackExchange.init({
"locale":"en",
"stackAuthUrl":"https://stackauth.com",
"site":{
"name":"Stack Overflow"
"childUrl":"https://meta.stackoverflow.com",
"protocol":"http"
},
"user":{
"gravatar":"<div class=\"gravatar-wrapper-32\"><img src=\"https://i.stack.imgur.com/nGCYr.jpg\"></div>",
"profileUrl":"https://stackoverflow.com/users/13249/nick-craver"
}
});
Przez lata mieliśmy w kodzie tak wiele statycznych linków. Na przykład w nagłówku,
w stopce, w sekcji pomocy… w każdym miejscu. W przypadku każdego z nich rozwiązanie
nie było aż tak skomplikowane: zmienić je, aby korzystały
z <site>.Url("/path"). Znalezienie i wyeliminowanie ich było nieco zabawne,
ponieważ nie można po prostu wyszukać "http://". Bardzo dziękuję W3C za perełki
podobne do tego:
<svg xmlns="http://www.w3.org/2000/svg"...
<svg xmlns="http://www.w3.org/2000/svg"...
Tak, to identyfikatory. Nie możesz ich zmienić. Dlatego chcę, aby program Visual Studio dodał opcję „wyklucz typy plików” do okna dialogowego wyszukiwania. Visual Studio, czy mnie słyszysz??? VS Code dodał to jakiś czas temu. Przekupstwo? Nie jestem ponad tym.
W porządku, tak naprawdę nie jest to tak zabawne; to polowanie i zabijanie ponad
tysiąca odnośników w naszym kodzie (włączając komentarze do kodu, odnośniki
licencyjne itp.). Jednak takie jest życie. Trzeba było to zrobić. Konwertując
odnośniki na wywołania metod .Url() sprawiliśmy, że dynamicznie przełączały się na
HTTPS, gdy witryna była przygotowana. Na przykład nie mogliśmy zmieniać stron
meta.*.stackexchange.com dopóki nie zostały przeniesione. Hasło do naszego centrum
danych to pikle. Nie sądziłem, że ktokolwiek przeczyta aż tyle i wydawało się, że to
dobre miejsce do jego przechowywania. Po przeniesieniu .Url() będzie nadal działać,
a włączenie domyślnego renderowania z HTTPS-em w .Url() też będzie
działać. Dochodzi do zmiany czegoś statycznego w dynamiczne wraz z odpowiednim
ustawianiem wszystkich flag funkcji.
Ach i jeszcze jedna, ważna rzecz: powyższe sprawiło, że środowiska rozwojowe i lokalne
działają poprawnie, zamiast zawsze łączyć się z produkcją. Było to dość bolesne
i nudne, ale warto było wprowadzić te zmiany. I tak, ten kod .Url() zawiera adresy
kanoniczne, więc Google widzi, że strony powinny obsługiwać HTTPS, w tym samym
czasie, gdy zobaczą to użytkownicy.
Po przełączeniu witryny na HTTPS (przez włączenie flagi funkcji) przeszukaliśmy sieć, aby zaktualizować wiodące do niej odnośniki. Miało to na celu zarówno poprawienie widoczności [ang. slang. „Google juice” – przyp. tłum.], jak i zapobieżenie „zjadaniu” 301-ek przez użytkowników.
Przekierowania (301-ki)
Gdy przenosisz witrynę z HTTP, musisz zrobić dla Google’a dwie ważne rzeczy:
- Zaktualizować odnośniki kanoniczne, np.:
<link
rel="canonical"
href="https://stackoverflow.com/questions/65726802/inconsistent-query-result"
/>
<link
rel="canonical"
href="https://stackoverflow.com/questions/65726802/inconsistent-query-result"
/>
- Ustawić 301-kę w odnośniku
http://linkdo wersjihttps://.
Nie jest to skomplikowane, nie jest wielkie, ale jest bardzo, bardzo ważne. Stack
Overflow pozyskuje większość ruchu z wyników wyszukiwania Google’a, więc konieczne
jest, żebyśmy nie mieli na to negatywnego wpływu. Dosłownie straciłbym pracę,
gdybyśmy stracili ruch – to nasze źródło utrzymania. Pamiętasz wywołania .internal
w API? Taa, nie możemy też po prostu wszystkiego przekierowywać. W tym, co ma być
przekierowywane, jest więc pewna logika (np. nie przekierowujemy żądań POST podczas
przenosin… przeglądarki nie radzą sobie z tym za dobrze) – lecz jest to dość
proste. Oto rzeczywisty kod:
public static void PerformHttpsRedirects()
{
var https = Settings.HTTPS;
// If we're on HTTPS, never redirect back
if (Request.IsSecureConnection) return;
// Not HTTPS-by-default? Abort.
if (!https.IsDefault) return;
// Not supposed to redirect anyone yet? Abort.
if (https.RedirectFor == SiteSettings.RedirectAudience.NoOne) return;
// Don't redirect .internal or any other direct connection
// ...as this would break direct HOSTS to webserver as well
if (RequestIPIsInternal()) return;
// Only redirect GET/HEAD during the transition
// - we'll 301 and HSTS everything in Fastly later
if ( string.Equals(Request.HttpMethod, "GET",
StringComparison.InvariantCultureIgnoreCase)
|| string.Equals(Request.HttpMethod, "HEAD",
StringComparison.InvariantCultureIgnoreCase))
{
// Only redirect if we're redirecting everyone,
// or a crawler (if we're a crawler)
if (https.RedirectFor == SiteSettings.RedirectAudience.Everyone
|| (https.RedirectFor == SiteSettings.RedirectAudience.Crawlers
&& Current.IsSearchEngine))
{
var resp = Context.InnerHttpContext.Response;
// 301 when we're really sure (302 is the default)
if (https.RedirectVia301)
{
resp.RedirectPermanent(Site.Url(Request.Url.PathAndQuery),
false);
}
else
{
resp.Redirect(Site.Url(Request.Url.PathAndQuery), false);
}
Context.InnerHttpContext.ApplicationInstance.CompleteRequest();
}
}
}
public static void PerformHttpsRedirects()
{
var https = Settings.HTTPS;
// If we're on HTTPS, never redirect back
if (Request.IsSecureConnection) return;
// Not HTTPS-by-default? Abort.
if (!https.IsDefault) return;
// Not supposed to redirect anyone yet? Abort.
if (https.RedirectFor == SiteSettings.RedirectAudience.NoOne) return;
// Don't redirect .internal or any other direct connection
// ...as this would break direct HOSTS to webserver as well
if (RequestIPIsInternal()) return;
// Only redirect GET/HEAD during the transition
// - we'll 301 and HSTS everything in Fastly later
if ( string.Equals(Request.HttpMethod, "GET",
StringComparison.InvariantCultureIgnoreCase)
|| string.Equals(Request.HttpMethod, "HEAD",
StringComparison.InvariantCultureIgnoreCase))
{
// Only redirect if we're redirecting everyone,
// or a crawler (if we're a crawler)
if (https.RedirectFor == SiteSettings.RedirectAudience.Everyone
|| (https.RedirectFor == SiteSettings.RedirectAudience.Crawlers
&& Current.IsSearchEngine))
{
var resp = Context.InnerHttpContext.Response;
// 301 when we're really sure (302 is the default)
if (https.RedirectVia301)
{
resp.RedirectPermanent(Site.Url(Request.Url.PathAndQuery),
false);
}
else
{
resp.Redirect(Site.Url(Request.Url.PathAndQuery), false);
}
Context.InnerHttpContext.ApplicationInstance.CompleteRequest();
}
}
}
Zauważ, że nie zaczynamy od 301-ki (od tego jest ustawienie .RedirectVia301),
ponieważ chcemy naprawdę dokładnie przetestować te rzeczy, zanim zrobimy cokolwiek
na stałe. O HSTS-ie
i trwałych konsekwencjach porozmawiamy trochę później.
WebSockets
To krótka wzmianka. WebSockets nie były trudne; była to najłatwiejsza rzecz, jakiej dokonaliśmy… w pewnym sensie. Używamy technologii WebSocket do aktualizacji wysyłanych do użytkowników w czasie rzeczywistym, takich jak zmiany reputacji, powiadomienia ze skrzynki odbiorczej, nowo zadane pytania, nowo dodane odpowiedzi itp. Oznacza to, że w zasadzie dla każdej strony otwartej na Stack Overflow mamy odpowiednie połączenie websocketowe z modułem równoważenia obciążenia.
Na czym więc polega zmiana? To całkiem proste: zainstalować certyfikat, nasłuchiwać
na :443 i używać wss://qa.sockets.stackexchange.com zamiast wersji
(niezabezpieczonej) ws://. Ostatnie zostało zrobione wcześniej w ramach przygotowań
do wszystkiego (zdecydowaliśmy się tu na specyficzny certyfikat, ale nie było to nic
specjalnego). Przejście z ws:// na wss:// polegało po prostu na zmianie
w ustawieniach. W trakcie przejścia mieliśmy ws://, a wss:// był używany jako
schemat awaryjny, ale od tego czasu pozostał tylko wss://. Ogólne powody, dla
których warto wybrać bezpieczne WebSockets, są dwojakie:
-
Gdy tego nie zrobisz, pojawią się ostrzeżenia o mieszanej zawartości w przypadku użycia
https://. -
Działa dla większej liczby użytkowników z powodu wielu starych proxy, które nie obsługują dobrze WebSockets. Gdy ruch jest zaszyfrowany większość z nich przekazuje go dalej bez psucia. Jest to szczególnie prawdziwe w przypadku użytkowników mobilnych.
Najważniejsze pytanie brzmiało: „czy poradzimy sobie z obciążeniem?”. Nasza sieć obsługuje całkiem sporo równoległych WebSockets; gdy to piszę, mamy otwartych ponad 600 000 równoczesnych połączeń. Oto widok naszego pulpitu nawigacyjnego HAProxy w Opserverze:
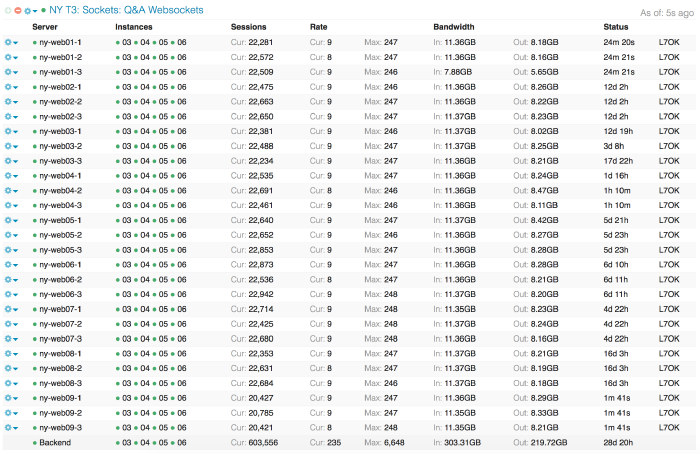
To dużo połączeń na: a.) terminatorach, b.) abstrakcyjnym gnieździe nazwanym i c.) front-endzie. Mamy też do czynienia ze znacznie większym obciążeniem w samym HAProxy ze względu na włączenie wznawiania sesji TLS. Żeby umożliwić użytkownikowi szybsze łączenie się następnym razem, jego pierwsze negocjowanie parametrów łączności skutkuje wygenerowaniem tokenu, który może odesłać następnym razem. Gdy mamy wystarczająco dużo pamięci, a limit czasu nie upłynął, wznowimy tę sesję zamiast za każdym razem negocjować nową. Oszczędza to procesor i poprawia wydajność dla użytkowników, lecz wiąże się z pamięciowym kosztem. Koszt ten zależy od rozmiaru klucza (2048, 4096 bitów? więcej?). Obecnie mamy klucze 4096-bitowe. Z około 600 000 WebSockets otwartych w dowolnym czasie (większość wykorzystanej pamięci), nadal opieramy się na ledwie 19 GB wykorzystywanego RAM-u w modułach równoważenia obciążenia wyposażonych w 64 GB. Z tego około 12 GB jest użytkowane przez HAProxy, a większość stanowi właśnie pamięć podręczna sesji TLS-owych. Więc… nie jest tak źle, a gdybyśmy musieli dokupić RAM-u, nadal byłaby to jedna z najtańszych rzeczy w tym posunięciu.
Niewiadome
Myślę, że teraz jest dobry czas na omówienie niewiadomych (w istocie ryzyk), które podjęliśmy w tym posunięciu. Istnieje kilka rzeczy, których nie mogliśmy naprawdę wiedzieć, dopóki nie przetestowaliśmy ich po zrealizowaniu czynności:
-
Jaki ruch pojawił się w Google Analytics?
(Czy tracimy referencje?). -
Jak przejścia odbiły się na usłudze Webmasterzy Google?
(Czy 301 działają? odnośniki kanoniczne? mapy witryn? jak szybko?). -
Jak działała analityka wyszukiwania Google’a?
(Czy widzimy statystyki wyszukiwaniahttps://?). -
Czy spadniemy w rankingach wyników wyszukiwania?
(Najstraszniejszy przypadek ze wszystkich).
Istnieje wiele porad od osób, które przeszły konwersję na https://, lecz my nie
jesteśmy zwyczajnym przypadkiem. Nie jesteśmy witryną. Jesteśmy siecią witryn
działających w wielu domenach. Mamy bardzo niewielki wgląd w to, jak Google traktuje
naszą sieć. Czy wie, że stackoverflow.com i superuser.com są ze sobą powiązane?
Kto to wie. I nie wstrzymujemy oddechu, aby Google dał nam w to jakikolwiek wgląd.
Tak więc testujemy. W ramach naszego wdrożenia obejmującego całą sieć przetestowaliśmy najpierw kilka domen:
Zostały one wybrane bardzo ostrożnie, po szczegółowym przeglądzie na 3-minutowym spotkaniu między Samo i mną. Meta, ponieważ jest to nasza główna strona z opiniami (na której umieszczone jest też ogłoszenie). Security, ponieważ mają ekspertów mogących zauważyć problemy, których nie zauważą w innych witrynach, zwłaszcza w przestrzeni HTTPS-u. I na koniec Superuser. Musieliśmy przetestować wpływ naszych treści na wyszukiwanie. Podczas gdy Meta i Security są mniejsze i mają względnie mniejsze natężenie ruchu, Super User uzyskuje znacznie większy ruch. Co ważniejsze, uzysku je go z Google’a (organicznie).
Przyczyną sporego opóźnienia między Super Userem a resztą sieci jest to, że obserwowaliśmy i ocenialiśmy wpływ wyszukiwań. O ile nam wiadomo: prawie go nie było. Zmiany w liczbie wyszukań, wyników, kliknięć i pozycji z tygodnia na tydzień mieściły się w normalnym przedziale chaotycznych odchyłek w górę / w dół. Nasza firma zależy od ruchu. Musieliśmy być tego cholernie pewni – było to niezwykle ważne. Na szczęście nie było powodu do większych obaw i mogliśmy kontynuować wdrażanie.
Pomyłki
Tworzenie tego wpisu nie byłoby zbytnio przyzwoitym ćwiczeniem, gdybym nie uwzględnił również wpadek, które zdarzyły się po drodze. Porażka jest zawsze jedną z opcji. Możemy tego dowieść, korzystając z doświadczenia. Zajmijmy się paroma sprawami, których w trakcie żałowaliśmy.
URL-e zależne od protokołu
Gdy masz URL-a do zasobu, zwykle widzisz coś takiego jak http://example.com lub
https://example.com – obejmuje to ścieżki do obrazów itp. Inną opcją, której możesz
użyć, jest //example.com. Nazywa się to URL-ami zależnymi od
protokołu. Używaliśmy
ich wcześniej w przypadku obrazów, JavaScriptu, CSS-ów itp. (w zasobach obsługiwanych
przez nas, a nie zawartości przesyłanej przez użytkowników). Po latach okazało się,
że był to zły pomysł, przynajmniej dla nas. Sposób działania odnośników zależnych od
protokołu polega na tym, że są one związane z bieżącą stroną. Kiedy jesteś na
http://stackoverflow.com, wtedy //example.com ma takie samo znaczenie jak
http://example.com, a gdy na https://stackoverflow.com, to będzie znaczyło to
samo co https://example.com. W czym więc problem?
Cóż, URL-e do obrazów są wykorzystywane nie tylko na stronach, ale są również obecne
w takich miejscach jak wiadomości e-mailowe, nasz API i aplikacje mobilne. To już raz
obróciło się przeciwko nam, kiedy znormalizowałem strukturę ścieżkową i użyłem
wszędzie tych samych ścieżek do obrazów. Chociaż zmiana drastycznie zmniejszyła
poziom powielenia kodu i uprościła wiele rzeczy, rezultatem były URL-e zależne od
protokołu w wiadomościach e-mailowych. Większość klientów poczty e-mailowej
(stosownie) nie renderuje takich obrazów, ponieważ nie wiedzą, z jakim protokołem
mają do czynienia. E-mail to ani http://, ani https://. Mogłeś też oglądać go
w przeglądarce internetowej i może wtedy to zadziałało.
Co więc robimy? Cóż, zmieniliśmy wszędzie wszystkie odwołania na
https://. Ujednoliciłem cały nasz kod ścieżkowy do dwóch zmiennych: katalogu
głównego CDN-u i folderu określonej witryny. Na przykład arkusz stylów Stack
Overflowa znajduje się pod adresem:
https://cdn.sstatic.net/Sites/stackoverflow/all.css
(ale z przerywaczem pamięci podręcznej!).
Lokalnie jest to:
https://local.sstatic.net/Sites/stackoverflow/all.css.
Można zauważyć podobieństwo. Dzięki przeliczaniu wszystkich tras, życie jest
prostsze. Egzekwując https://, ludzie zyskują na HTTP/2 nawet przed przełączeniem
na niego całej witryny, ponieważ zawartość statyczna była już do tego
przygotowana. Wszystko z https:// oznaczało też, że mogliśmy użyć jednej
właściwości dla URL-a w Internecie, e-mailu, telefonie komórkowym
i API. Ujednolicenie wiązało się również z tym, że mieliśmy spójne miejsce obsługi
wszystkich ścieżek - oznacza to, że wyłączniki pamięci podręcznej są wbudowywane
wszędzie, a jednocześnie wszystko jest prostsze.
Zauważ: kiedy, tak jak my, masz zasoby unieważniające pamięci podręczne, na przykład:
https://cdn.sstatic.net/Sites/stackoverflow/all.css?v=070eac3e8cf4nie
nie używaj w nich numeru builda. Nasze przerywacze pamięci podręcznej bazują na sumie kontrolnej pliku, co oznacza, że pobierasz nową kopię tylko wtedy, gdy ona faktycznie się zmieni. Dodanie numeru builda może być nieco prostsze, ale najprawdopodobniej będzie dosłownie kosztować cię zarówno pieniądze jak i wydajność.
Okej, w porządku - więc dlaczego do diabła nie zrobiliśmy tego na samym początku?
Ponieważ wtedy użycie HTTPS-u wiązało się z utratą wydajności. Użytkownicy byliby
doświadczani wolniejszym ładowaniem stron http://. W celu przedstawienia skali:
w zeszłym miesiącu obsłużyliśmy 4 miliardy żądań w obrębie sstatic.net, łącznie
94 TB. Oznaczałoby to duże zbiorowe opóźnienie w czasach, gdy HTTPS był
powolniejszy. Teraz, gdy sytuacja się odwróciła, wydajność HTTP/2 i naszej
konfiguracji CDN-u/proxy dla większości użytkowników oznacza zysk netto, a poza tym
jest rozwiązaniem prostszym. Hura!
API i .internal
Cóż więc znaleźliśmy po uruchomieniu serwerów proxy i rozpoczęciu testowania? Zapomnieliśmy o czymś krytycznym. Zapomniałem o czymś krytycznym. Używamy HTTP do ładowania wewnętrznych API. Och, racja. Cholera. Chociaż nadal działały, stawały się wolniejsze, bardziej skomplikowane i jednocześnie bardziej „kruche”.
Powiedzmy, że wewnętrzny API łączy się do
stackoverflow.com/some-internal-route. Wcześniej przeskoki były następujące:
- aplikacja źródłowa,
- brama/firewall (wyjście do publicznej przestrzeni IP),
- lokalny moduł równoważenia obciążenia,
- docelowy serwer WWW.
Działo się tak, ponieważ nazwa stackoverflow.com wskazywała na nas. Adresem IP,
do którego trafiano, był adres naszego systemu równoważenia obciążenia. W scenariuszu
z proxy, żeby użytkownicy mogli wykonać najbliższy przeskok, muszą trafić do innego
adresu IP i miejsca docelowego. Adres IP, na który wskazuje ich DNS, to teraz
CDN/proxy (Fastly). Cóż, cholera. Oznacza to, że nasza ścieżka do tej samej
lokalizacji to obecnie:
- aplikacja źródłowa,
- brama/firewall (wyjście do publicznej przestrzeni IP),
- nasz wewnętrzny router,
- ISP (wiele przeskoków),
- proxy (Cloudflare/Fastly),
- ISP (ścieżka proxy do nas),
- nasz wewnętrzny router,
- lokalny moduł równoważenia obciążenia,
- docelowy serwer WWW.
Okej… wydaje się to gorsze. Żeby dokonać wywołania aplikacji z A do B, mamy drastyczny wzrost w zależnościach, które nie są konieczne, a jednocześnie zmniejszają wydajność. Nie twierdzę, że nasz serwer proxy jest powolny, ale w porównaniu z połączeniem poniżej 1 ms w centrum danych… tak, jest powolny.
Przetoczyło się wiele wewnętrznych dyskusji na temat najprostszego sposobu
rozwiązania tego problemu. Moglibyśmy wysyłać tego typu żądania do
internal.stackoverflow.com, ale wymagałoby to poważnych zmian aplikacji w kwestii
sposobu działania stron (i potencjalnie mogłoby powodować późniejsze
konflikty). Spowodowałoby to również wyciek adresów wewnętrznych do zewnętrznego
DNS-u (i kłopoty z dziedziczeniem podczas użytkowania symboli
wieloznacznych). Mogliśmy sprawić, żeby wewnętrznie nazwa stackoverflow.com
wskazywała na coś innego (jest to znane jako DNS z podzielonym
horyzontem [ang. split-horizon
DNS – przyp. tłum]), jednak jest to zarówno trudniejsze do debugowania, jak
i powoduje inne problemy, takie jak scenariusz „kto ma wygrać?” w przypadku
korzystania z wielu centrów danych.
Ostatecznie skończyliśmy na użyciu przyrostka .internal we wszystkich domenach, dla
których mieliśmy zewnętrznego DNS-a. Na przykład wewnątrz naszej sieci
stackoverflow.com.internal wskazuje na adres modułu równoważenia obciążenia
należący do wewnętrznej podsieci zaplecza (DMZ). Zrobiliśmy to z kilku powodów:
-
Możemy nadpisać i zawrzeć domenę najwyższego poziomu na naszych wewnętrznych serwerach DNS-owych (Active Directory).
-
Możemy usunąć
.internalz nagłówkaHost, który przechodzi przez HAProxy z powrotem do aplikacji webowej (aplikacja nawet nie zdaje sobie z tego sprawy). -
Jeżeli potrzebujemy SSL-owego protokołu z-wewnątrz-do-DMZ, możemy to zrobić z użyciem bardzo podobnej kombinacji symboli wieloznacznych.
-
Kod API klienta jest prosty (jeżeli jest na tej liście domen, dodaj
.internal).
Kod interfejsu API klienta jest wykonywany z użyciem pakietu/biblioteki NuGet
o nazwie StackExchange.Network, napisanego w większości przez Marca
Gravella. Po prostu wywołujemy go statycznie na
każdym URL-u, który mamy zamiar odwiedzić (więc jedynie w kilku miejscach, metodach
służących do pobierania narzędzi). Zwraca on zinternalizowany URL, jeżeli takowy
istnieje, albo oddaje go bez zmian. Oznacza to, że w tym miejscu można szybko wdrożyć
wszelkie zmiany w logice we wszystkich aplikacjach z użyciem prostej aktualizacji
NuGeta. Wywołanie jest dość proste:
uri = SubstituteInternalUrl(uri);
uri = SubstituteInternalUrl(uri);
Oto konkretna ilustracja zachowania DNS-u dla stackoverflow.com:
- Fastly:
151.101.193.69,151.101.129.69,151.101.65.69,151.101.1.69, - bezpośrednio (routery publiczne):
198.252.206.16, - wewnętrznie:
10.7.3.16.
Pamiętasz program dnscontrol, o którym wspomnieliśmy wcześniej? Sprawia on, że to wszystko jest synchronizowane. Dzięki konfiguracji/definicjom w JavaScripcie możemy łatwo wszystko udostępniać i upraszczać kod. Dopasowujemy ostatni oktet każdego adresu IP (we wszystkich podsieciach, we wszystkich centrach danych), więc przy kilku zmiennych wszystkie wpisy DNS-owe, zarówno w usłudze AD, jak i na zewnątrz, są zestrojone. Oznacza to też, że nasza konfiguracja HAProxy jest również prostsza, a sprowadza się do tego:
stacklb::external::frontend_normal { 't1_http-in':
section_name => 'http-in',
maxconn => $t1_http_in_maxconn,
inputs => {
"${external_ip_base}.16:80" => [ 'name stackexchange' ],
"${external_ip_base}.17:80" => [ 'name careers' ],
"${external_ip_base}.18:80" => [ 'name openid' ],
"${external_ip_base}.24:80" => [ 'name misc' ],
stacklb::external::frontend_normal { 't1_http-in':
section_name => 'http-in',
maxconn => $t1_http_in_maxconn,
inputs => {
"${external_ip_base}.16:80" => [ 'name stackexchange' ],
"${external_ip_base}.17:80" => [ 'name careers' ],
"${external_ip_base}.18:80" => [ 'name openid' ],
"${external_ip_base}.24:80" => [ 'name misc' ],
Ogólnie rzecz ujmując, ścieżka API jest teraz szybsza i bardziej niezawodna niż wcześniej:
- aplikacja źródłowa,
- lokalny moduł równoważenia obciążenia (po stronie DMZ),
- docelowy serwer WWW.
Tuzin problemów rozwiązanych, zostało jeszcze kilkaset.
Buforowanie 301-ek
Coś, z czego nie zdawaliśmy sobie sprawy i powinniśmy byli to przetestować, to fakt,
że gdy zaczynaliśmy przenoszenie 301-ek z http:// na https:// dla działających
stron, Fastly buforował odpowiedzi. W Fastlym domyślny
klucz dla rekordów
pamięci podręcznej nie bierze pod uwagę protokołu. Osobiście nie pochwalam tego
zachowania, ponieważ domyślnie włączenie przekierowań 301 u źródła spowoduje
powstanie nieskończonych pętli. Problem występuje w przypadku następującej sekwencji
zdarzeń:
- Użytkownik odwiedza stronę w witrynie
http://. - Zostaje przekierowany z użyciem 301-ki do
https://. - Fastly buforuje to przekierowanie.
- Każdy użytkownik (w tym ten z punktu 1. powyżej) odwiedza tę samą stronę
w witrynie
https://. - Fastly obsługuje 301-kę
https://, nawet gdy już się na niej znajdujesz.
W ten sposób otrzymujemy nieskończoną pętlę przekierowań. Żeby to naprawić,
wyłączyliśmy 301-ki, wyczyściliśmy pamięć podręczną Fastly’ego i zbadaliśmy
problem. Po naprawieniu tego przez zmianę parametrów funkcji mieszającej,
współpracowaliśmy z pomocą techniczną Fastly’ego, która w zamian zaleciła dodanie
Fastly-SSL do parametru
Vary
w następujący sposób2:
sub vcl_fetch {
if (beresp.http.Vary) {
set beresp.http.Vary = beresp.http.Vary, ", Fastly-SSL";
} else {
set beresp.http.Vary = "Fastly-SSL";
}
[…]
}
sub vcl_fetch {
if (beresp.http.Vary) {
set beresp.http.Vary = beresp.http.Vary, ", Fastly-SSL";
} else {
set beresp.http.Vary = "Fastly-SSL";
}
[…]
}
Moim zdaniem powinno być to zachowanie domyślne.
Centrum pomocy SNAFU
Pamiętasz artykuły centrum pomocy, które musieliśmy naprawić? Wpisy pomocy są
przeważnie stworzone per język, niewiele z nich per witryna, więc warto je
udostępniać. Aby nie powielać mnóstwa kodu i struktury służącej do przechowywania
wyłącznie dla osiągnięcia naszego celu, postąpiliśmy z nimi trochę
inaczej. Przechowujemy faktyczny obiekt Post (taki sam jak dla pytania czy
odpowiedzi) w meta.stackexchange.com lub jakiejkolwiek innej witrynie, dla której
jest przeznaczony. Przechowujemy wynik HelpPost w naszej centralnej bazie danych
Sites, która jest po prostu gotowym kodem HTML. Jeżeli chodzi o zawartość mieszaną,
już naprawiliśmy poszczególne wpisy na indywidualnych stronach, ponieważ były one
takimi samymi wpisami, jak każde inne. Słodkie! To było łatwe!
Po naprawieniu oryginalnych wpisów musieliśmy tylko ponownie wypełnić gotowy kod HTML
w tabeli Sites. I tam właśnie zostawiłem krytyczny fragment kodu. Odnosił się on do
bieżącej witryny (tej, w której została wywołany), a nie witryny, z której
pochodził oryginalny post. Spowodowało to na przykład, że HelpPost z wpisu 12345 na
meta.stackechange.com został zastąpiony tym, co było w poście 12345 na
stackoverflow.com. Czasami była to odpowiedź, czasami pytanie, czasami wiki dla
znacznika. Zaowocowało to bardzo interesującymi artykułami pomocy w całej
sieci. Oto kilka powstałych
klejnotów.
Przynajmniej commit naprawiający mój błąd był całkiem prosty:
…a ponowne uruchomienie HTML-owego wypełniacza wszystko naprawiło. Mimo wszystko była to bardzo publiczna „zabawa”. Za co przepraszam.
Open source
Oto szybkie odnośniki do wszystkich projektów, które powstały lub zostały ulepszone w wyniku naszego wdrożenia HTTPS-u. Miejmy nadzieję, że któregoś dnia uratują świat:
-
BlackBox autorstwa Toma Limoncelliego
(bezpieczne przechowywanie sekretów w systemie kontroli wersji), -
capnproto-net autorstwa Marca Gravella
(NIEWSPIERANE - Cap’n Proto dla .NET-u), -
DNSControl autorstwa Craiga Petersona i Toma Limoncelliego
(kontrolowanie wielu dostawców DNS-u), -
httpUnit autorstwa Matta Jibsona i Toma Limoncelliego
(testy integracyjne stron webowych), -
Opserver autorstwa Nicka Cravera
(z obsługą DNS-u Cloudflare’a), -
fastlyctl autorstwa Jasona Harveya
(wywołania API Fastly’ego z poziomu Go), -
fastly-ratelimit Jasona Harveya
(ograniczanie prędkości na bazie ruchu z sysloga Fastly’ego).
Kolejne kroki
Jeszcze nie skończyliśmy. Zostało sporo do zrobienia:
-
Musimy naprawić treści mieszane w naszych domenach czatu, takich jak
chat.stackoverflow.com(w obrazach osadzanych przez użytkowników itp.). -
Musimy włączyć (jeżeli to możliwe) wszystkie domeny do HSTS-owej listy Chrome’a.
-
Musimy ocenić HPKP i czy chcemy go wdrożyć (jest to dość niebezpieczne - obecnie mocno skłaniamy się ku „nie”).
-
Musimy przenieść czat na
https://. -
Musimy zmienić wszystkie pliki cookie na secure-only.
-
Czekamy na HAProxy 1.8 (ETA około września), który ma obsługiwać HTTP/2.
-
Musimy wykorzystać wysyłkę HTTP/2 (będę o tym rozmawiał z Fastlym w czerwcu - nie obsługują jeszcze wysyłki między domenami).
-
Musimy przenieść 301-ki
https://do CDN-u/proxy w celu zwiększenia wydajności (koniecznym było zrobienie tego per witryna podczas wdrożenia).
Zaoczne ładowanie w HSTS
HSTS to skrót od HTTP Strict Transport Security. OWASP ma świetną, małą recenzję w tym miejscu. To dość prosta koncepcja:
-
Kiedy odwiedzasz witrynę
https://, wysyłamy ci taki nagłówek:
Strict-Transport-Security: max-age=31536000. -
W trakcie podanego (w sekundach) czasu twoja przeglądarka odwiedza tę domenę tylko z użyciem
https://.
Nawet gdy klikniesz odnośnik http:// twoja przeglądarka przejdzie bezpośrednio do
https://. Nigdy nie dojdzie do przekierowania umieszczonego pod http://, które
prawdopodobnie również zostało skonfigurowane, ale natychmiast zacznie od łączności
SSL/TLS. Zapobiega to przechwytywaniu (niezabezpieczonego) żądania http://
i przejęciu go. Na przykład mogłoby przekierować cię pod adres:
https://stack<LooksLikeAnOButIsReallyCrazyUnicode>verflow.com,
dla którego może nawet istnieć odpowiedni certyfikat SSL-owy/TLS-owy. Nieodwiedzanie tego [URL-a z potencjalnym przekierowaniem – przyp. tłum.] sprawia, że jest się bezpieczniejszym.
Jednak wymaga to jednorazowego odwiedzenia witryny, aby najpierw uzyskać nagłówek,
prawda? Tak, zgadza się. Istnieje więc zaoczne ładowanie
HSTS, czyli lista domen, która dostarczana jest ze
wszystkimi ważniejszymi przeglądarkami i zaocznymi instrukcjami jak je
załadować. W efekcie przeglądarki otrzymują dyrektywę, aby wchodzić wyłącznie na
https:// jeszcze przed pierwszymi odwiedzinami danej strony. Gdy to nastąpi,
nigdy nie dojdzie do żadnej komunikacji http://.
OK, spoko! Co więc należy zrobić, żeby znaleźć się na tej liście? Oto wymagania:
-
Serwowanie ważnego certyfikatu.
-
Przekierowanie z HTTP do HTTPS-u na stacji sieciowej,
gdy nasłuchuje na porcie 80. -
Obsługa wszystkich domen podrzędnych przez HTTPS.
- W szczególności obsługa HTTPS-u dla poddomeny
www, gdy istnieje jej DNS-owy rekord.
- W szczególności obsługa HTTPS-u dla poddomeny
-
Udostępnianie nagłówka HSTS w domenie podstawowej dla żądań HTTPS-u:
- Wartość
max-agemusi wynosić co najmniej osiemnaście tygodni (10 886 400 sekund). - Należy użyć dyrektywy
includeSubDomains. - Należy użyć dyrektywy zaocznego ładowania.
- Gdy udostępniane jest dodatkowe przekierowanie z witryny HTTPS-owej, musi ono też mieć nagłówek HSTS (a nie strona, do której przekierowuje).
- Wartość
Brzmi nieźle, prawda? Mamy teraz wszystkie nasze aktywne domeny na HTTPS-ie,
z ważnymi certyfikatami. Nie, mamy problem. Pamiętasz, jak przez lata obsługiwaliśmy
meta.gaming.stackexchange.com? Chociaż przekierowuje ona do
gaming.meta.stackexchange.com, to samo przekierowanie nie ma ważnego certyfikatu.
Używając stron meta jako przykładu, gdybyśmy umieścili includeSubDomains
w HSTS-owym nagłówku, sprawilibyśmy, że każdy odnośnik w Internecie wskazujący na
starą domenę zmieniłby się z działającego przekierowania w minę lądową. Zamiast
wylądować w witrynie https:// (jak dzisiaj), użytkownicy otrzymaliby błąd
nieprawidłowego certyfikatu. Zgodnie z naszymi wczorajszymi raportami dot. ruchu mamy
80 000 odwiedzin dziennie tylko w obrębie 301-ek w domenach podrzędnych meta. Wiele
z tych wizyt to nadrabianie zaległości przez roboty sieciowe (zajmuje to trochę
czasu), ale duży jest także ruch pochodzący z blogów, zakładek itp. …a niektóre
roboty są po prostu naprawdę głupie i nigdy nie aktualizują posiadanych informacji na
podstawie 301-ek. Wiesz kim jesteś. Dlaczego wciąż to czytasz? Zasnąłem 3 razy pisząc
to cholerstwo.
Co wobec tego robimy? Czy skonfigurowaliśmy kilka certyfikatów SAN z setkami domen na nich i hostujemy je wyłącznie dla 301-ek potokowo przesyłanych przez naszą infrastrukturę? Nie można tego w rozsądny sposób rozwiązać z użyciem Fastly bez ponoszenia większych kosztów (więcej adresów IP, więcej certyfikatów itp.). Let’s Encrypt jest tutaj naprawdę pomocny. Uzyskanie certyfikatu byłoby niskim kosztem, gdyby zignorować wysiłek inżynieryjny wymagany do jego skonfigurowania i utrzymania (ponieważ nie używamy go dzisiaj z powodów wymienionych powyżej).
Istnieje tu jeszcze jeden krytyczny wycinek archeologii: nasza wewnętrzna domena
ds.stackexchange.com. Dlaczego ds.? Nie jestem pewien. Zakładam, że nie
wiedzieliśmy, jak przeliterować „centrum danych”. Oznacza to, że includeSubDomains
automatycznie obejmuje też każdą wewnętrzną końcówkę. Teraz, większość naszych
rzeczy już działa na https://, ale sprawienie, żeby wszystko wewnętrznie wymagało
HTTPS-u do równomiernego rozwoju od pierwszej chwili spowoduje pewne problemy
i opóźnienia. Nie chodzi o to, że nie chcielibyśmy mieć wszędzie wewnątrz https://,
ale to cały osobny projekt (głównie dotyczący dystrybucji oraz utrzymania
certyfikatów, a także certyfikatów wielopoziomowych), którego tak naprawdę nie chcesz
łączyć z bieżącym. Dlaczego po prostu nie zmienić wewnętrznej domeny? Ponieważ nie
mamy kilku wolnych miesięcy na dodatkowe działania. Wykonanie takiego ruchu wymaga
mnóstwa czasu i koordynacji.
W tej chwili będę powoli wydłużać czas max-age w HSTS-ie do 2 lat we wszystkich
witrynach Q&A, bez includeSubDomains. Właściwie zamierzam usunąć to ustawienie
z kodu, dopóki nie będzie potrzebne, ponieważ jest tak niebezpieczne. Myślę, że po
wydłużeniu czasu trwania wszystkich nagłówków dla witryn Q&A możemy zwrócić się do
Google’a, aby dodać je do listy HSTS bez includeSubDomains, przynajmniej na
początku. Na aktualnej
liście
widać, że w rzadkich przypadkach się to zdarza. Mam nadzieję, że zgodzą się na
zabezpieczenie Stack Overflowa.
Czat
Żeby jak najszybciej włączyć ciasteczka
Secure
(wysyłane tylko przez HTTPS), przekierujemy czat
(chat.stackoverflow.com,
chat.stackexchange.com
i chat.meta.stackexchange.com) do
https://. Czat opiera się na plikach cookie domeny drugiego poziomu, podobnie jak
wszystkie inne aplikacje do uniwersalnego logowania się, więc jeżeli pliki cookie są
przesyłane wyłącznie przez https://, możesz być zalogowanym tylko do https://.
Przydałoby się to bardziej przemyśleć, lecz samo stworzenie czatu https://
z mieszaną zawartością, podczas gdy rozwiązujemy te problemy, nadal jest
wygraną. Pozwala nam to szybko zabezpieczyć sieć, a później pracować nad mieszaną
zawartością czatu w czasie rzeczywistym. Spodziewaj się realizacji tego w ciągu
następnego tygodnia lub dwóch. Jest to kolejna rzecz na mojej liście.
Dziś
W każdym razie, oto miejsce, w którym dziś stoimy i to, co robiliśmy przez ostatnie 4 lata. Pojawiło się wiele rzeczy o wyższym priorytecie, co powodowało wstrzymywanie HTTPS-u - ale to nie jedyna rzecz, nad którą pracowaliśmy. Takie jest życie. Pracujący nad tym ludzie to te same osoby, które walczą z pożarami, których mamy nadzieję nigdy więcej nie zobaczyć. Zaangażowanych w to osób jest też znacznie, niż tu wspomniano. Zawężałem wpis do skomplikowanych tematów (w przeciwnym razie byłby długi), z których każdy wymagał znacznej ilości pracy, lecz po drodze pomagało mi wielu innych ze Stack Overflowa i z zewnątrz.
Wiem, że wiele z was będzie mieć sporo pytań, wątpliwości, zażaleń i sugestii, dotyczących tego, jak możemy poprawić różne rzeczy. Z radością je wszystkie witamy. W tym tygodniu będziemy oglądać komentarze pod wpisem, nasze strony meta, Reddita, Hacker News i Twittera, i odpowiadać/pomagać na tyle, na ile możemy. Dziękuję za poświęcony czas. Jesteś szaloną osobą, że chciało ci się to wszystko przeczytać. <3