

Analiza i sprawdzanie poprawności numerów telefonicznych nie są zadaniami trywialnymi, a samodzielne utrzymywanie setek reguł uwzględniających zmieniające się sposoby numeracji w różnych regionach świata byłoby syzyfową pracą. Istnieją jednak projekty wolnego oprogramowania, które zawierają odpowiednie funkcje i na bieżąco aktualizowane zestawy reguł. Jedno z takich wolnodostępnych narzędzi postanowiłem włączyć do ekosystemu Clojure, a tu spróbuję przy okazji scharakteryzować również sam język na przykładzie opisów ważniejszych części tworzonej biblioteki.
W połowie roku 2020 w jednym z eksperymentalnych projektów tworzonych w języku Clojure chciałem sprawdzić poprawność podawanego przez użytkownika numeru telefonicznego. W trakcie poszukiwań odpowiedniej biblioteki programistycznej trafiałem zazwyczaj na kod bazujący na wyrażeniach regularnych. To całkiem oczywiste, regexpy są powszechnie używane tam, gdzie trzeba szybko sprawdzić dane wejściowe i nie przejmować się znikomymi wyjątkami od reguły.
Problem polega jednak na tym, że numeracja telefoniczna zależy od regionów, krajów, a nawet miejsc, z których nawiązywane są połączenia. Mi z kolei zależało na uniwersalnym mechanizmie. Nawet jeżeli zasady numeracji uznalibyśmy za język regularny, odpowiednie wyrażenie składałoby się z setek, jeżeli nie tysięcy mniejszych reguł. Kiedy to, które wpada nam w ręce, takim nie jest, możemy mieć podejrzenie graniczące z pewnością, że nie działa zbyt dokładnie. Efektów nie trzeba szukać daleko: widać je w mechanizmach walidacji obecnych na różnych stronach WWW, gdzie pewne numery po prostu „nie wchodzą”, mimo że są całkiem poprawne. Zazwyczaj witryna skrojona jest na miarę statystycznego odbiorcy i gdy np. mamy polski serwis webowy, będzie on w miarę dobrze sprawdzał polskie numery, ale z zagranicznymi może już mieć kłopot. Przeciwna spotykana strategia polega na rozluźnieniu rygoru walidacji i dopuszczeniu numerów niepoprawnych. Zależy to od konkretnego przypadku użycia.
Moja motywacja w kwestii znalezienia precyzyjnego walidatora była najprawdopodobniej uźródłowiona w doświadczeniach pracy z mechanizmami takimi jak clojure.spec, Schema i Malli, w których z pojedynczych komponentów charakteryzujących dane (począwszy od określania cech niepodzielnych i najprostszych wartości) buduje się coraz bardziej złożone. Następnie można używać tak opisanych schematów do sprawdzania wejściowych, a nawet generowania przykładowych danych. W gruncie rzeczy narzędzia te pozwalają na tworzenie czegoś na wzór tekstowych wyrażeń regularnych, lecz w postaciach bardziej otwartych, przejrzystych i właśnie możliwych do łączenia ze sobą w większe systemy.
Clojure.spec czy pokrewne nie wymagają, aby precyzyjnie określać dane, ale można zastosować je również w ten sposób. Co więcej, specyfikacje mogą sięgać do istniejących funkcji programu i delegować procesy walidacji, jeżeli są one na tyle skomplikowane, że przedstawianie ich wyłącznie z użyciem wbudowanych predykatów i reguł mijałoby się z celem.
Idealnym scenariuszem byłby taki, w którym udaje się znaleźć coś już zintegrowanego z wyżej wymienionymi mechanizmami. W ostateczności mogę po prostu to dopisać.
Ważna rzecz. Potrzebuję jakoś nazwać projekt.
Phone-number
Szczerze powiedziawszy nie rozmyślałem zbyt długo nad nazwą. Nie zauważyłem, żeby już
istniała popularna biblioteka phone-number, więc postanowiłem ochrzcić ją właśnie
takim mianem.
Żeby mieć gdzie zapamiętywać zmiany, założyłem repozytorium Gita w serwisie GitHub:
Szkielet aplikacji pożyczyłem od chłopaków z JUXT-a, a po lekkim przerobieniu struktura katalogowa wyglądała mniej więcej tak:
├── Makefile
├── aliases
│ ├── codox
│ │ └── phone_number
│ │ └── codox
│ │ └── main.clj
│ ├── nrepl
│ │ └── nrepl.clj
│ └── rebel
│ └── phone_number
│ └── rebel
│ └── main.clj
├── bin
│ ├── docs
│ ├── repl
│ └── test
├── deps.edn
├── dev
│ ├── resources
│ └── src
│ ├── infra.clj
│ ├── phone_number
│ └── user.clj
├── doc
├── pom.xml
├── resources
├── src
│ ├── phone_number
│ │ ├── core.clj
│ │ ├── spec.clj
│ │ └── util.clj
│ └── phone_number.clj
├── target
└── test
└── phone_number
└── core_test.clj
├── Makefile
├── aliases
│ ├── codox
│ │ └── phone_number
│ │ └── codox
│ │ └── main.clj
│ ├── nrepl
│ │ └── nrepl.clj
│ └── rebel
│ └── phone_number
│ └── rebel
│ └── main.clj
├── bin
│ ├── docs
│ ├── repl
│ └── test
├── deps.edn
├── dev
│ ├── resources
│ └── src
│ ├── infra.clj
│ ├── phone_number
│ └── user.clj
├── doc
├── pom.xml
├── resources
├── src
│ ├── phone_number
│ │ ├── core.clj
│ │ ├── spec.clj
│ │ └── util.clj
│ └── phone_number.clj
├── target
└── test
└── phone_number
└── core_test.clj
Najważniejsze pliki:
-
Makefile– opisuje jak realizować najczęstsze zadania (wydawanie wersji, generowanie dokumentacji, uruchamianie testów itp.); -
pom.xml– opisuje właściwości potencjalnego pakietu Mavena (przy publikowaniu wersji w serwisie Clojars); -
deps.edn–opisuje zależności od innych pakietów oprogramowania podzielone na środowiska (rozwojowe, produkcyjne itd.).
Najważniejsze katalogi:
-
bin– zawiera skrypty powłokowe (np. do uruchamiania REPL-a); -
aliases– zawiera w podkatalogach kod Clojure definiujący funkcje główne używane w pewnych sytuacjach (np. uruchomienie interaktywnego REPL-a programisty bądź sieciowego REPL-a dla edytora Emacs, generowanie dokumentacji); -
dev– zawiera pomocniczy kod potrzebny w procesie rozwijania oprogramowania; -
src– zawiera właściwe pliki z kodem źródłowym oprogramowania; -
test– zawiera pliki testów.
W pliku
src/phone_number/core.clj
zamierzałem umieszczac główne funkcje biblioteki, a w pliku
scr/phone_number/util.clj
funkcje dodatkowe, niekoniecznie mieszczące się w definicji API. Plik
spec.clj
to z kolei miejsce dla specyfikacji, o których jeszcze opowiem.
Libphonenumber
Ponieważ wzorcowa implementacja języka Clojure działa pod kontrolą JVM, do dyspozycji mamy nie tylko natywne biblioteki stworzone z myślą o Clojure, ale również oprogramowanie napisane w Javie.
W przepastnych repozytoriach GitHuba natknąłem się na długo rozwijaną bibliotekę Libphonenumber, która jest wolnym oprogramowaniem. Poza sprawdzaniem poprawności numerów telefonicznych zawiera też metody pozwalające uzyskiwać informacje o operatorach linii, regionach i innych właściwościach, które mogą przydać się na przykład podczas automagicznego ustawiania języka interfejsu bądź kraju użytkownika, kiedy ten rejestruje się w usłudze.
Postanowiłem, że zaadaptuję tę bibliotekę do wykorzystania w Clojure, ale najpierw upewnię się, czy ktoś już tego nie zrobił. Trafiłem na parę Gistów i repozytoriów, gdzie faktycznie poczyniono takie kroki, ale zawierały one zazwyczaj tylko funkcje służące do tego, co komuś akurat było potrzebne, na przykład wyłącznie sprawdzanie poprawności bądź tylko wyświetlanie pewnych właściwości numeru, które autor uznał za najważniejsze. Czekała mnie więc ciekawa przygoda i zmiana rytmu dobowego.
Czy na pewno potrzebne jest tworzenie nowej biblioteki, tylko po to, żeby była interfejsem dla istniejącej? Nie ma nic złego w bezpośrednim sięganiu do obiektów i metod Javy z poziomu języka Clojure. W przypadku biblioteki Libphonenumber można to zrobić np. w taki sposób:
(.getRegionCodeForNumber
(PhoneNumberUtil/getInstance)
(.parse
(PhoneNumberUtil/getInstance)
"+48 601 100 601" ""))
; => "PL"
(.getRegionCodeForNumber
(PhoneNumberUtil/getInstance)
(.parse
(PhoneNumberUtil/getInstance)
"+48 601 100 601" ""))
; => "PL"
To samo w Javie wyglądałoby tak:
PhoneNumberUtil phoneUtil = PhoneNumberUtil.getInstance();
PhoneNumber phoneNumber = phoneUtil.parse("+48 601 100 601", "");
phoneUtil.getRegionCodeForNumber(phoneNumber);
PhoneNumberUtil phoneUtil = PhoneNumberUtil.getInstance();
PhoneNumber phoneNumber = phoneUtil.parse("+48 601 100 601", "");
phoneUtil.getRegionCodeForNumber(phoneNumber);
Odwołując się bezpośrednio do metod Javy rezygnujemy jednak z paru rzeczy: możliwości abstrahowania typowego dla Clojure, korzystania z idiomów tego języka i funkcyjnego komponowania wywołań. Ponadto nurkujemy w gnijących resztkach paradygmatów programowania, które zapoczątkowały obecne w wielu językach podejście, że tożsamość powinna zależeć od miejsca w pamięci. W takich przypadkach struktury danych są z reguły mutowalne, ponieważ sposobem na zmianę stanu czegoś, co musi zajmować stałe miejsce, będzie właśnie mutacja.
Ktoś powie, że mamy tu przecież do czynienia z OOP (programowaniem zorientowanym obiektowo), a to właśnie w nim wprowadzono koncepcję tożsamości obiektu, która identyfikuje go niezależnie od przyjmowanego stanu. To prawda, jednak gdy przyjrzymy się wewnętrznym sposobom używanym przez mechanizmy języka, aby odwoływać się do obiektów, odkryjemy, że każdy z nich ma też drugą, ekstensjonalną tożsamość, związaną z umiejscowieniem w pamięci, a z kolei jej źródłem jest koncepcja zmiennej. Aspekt identyfikacyjny obiektowej tożsamości jest obecny, jednak hermetyzacja pozostaje złudzeniem – szczególnie, gdy w grę wchodzi wiele wątków przyczepionych do jednej struktury danych. Da się to opanować, choćby stosując dobre praktyki, blokady dostępu do obiektów i umiejętnie sterując zasięgiem oraz widocznością, ale fundamentalnie coś z tym jest nie tak.
Ale referencja! Ona również, z powodu zależności od pamięciowych lokalizacji danych, będzie trudna do opanowania. Raz zapamiętane odniesienie do wartości sprawi, że będzie można ją zmieniać w zupełnie niepozornych miejscach, modyfikując stan całego programu. „Nie ma takiego dereferencjonowania. Koniec imprezy”.
Gdy spojrzymy na rodowody dzisiejszych tzw. języków obiektowo zorientowanych, zauważymy, że mają one całkiem proceduralne korzenie. Wspominał o tym Alan Kay, który tak odżegnał się od C++:
Wymyśliłem pojęcie „zorientowany obiektowo”
i mogę powiedzieć, że C++ nie jest tym, co miałem na myśli.
W zbliżony sposób pan Kay wypowiada się na temat Javy.
Koniec dygresji o nurkowaniu w odpadkach. Gdyby kogoś interesowały kwestie tożsamości i stanu w programowaniu, polecam publikację „Out of the Tar Pit”.
Wracając do biblioteki Libphonenumber. Jej sercem są dwie klasy: PhoneNumberUtil
i PhoneNumber. Pierwsza jest fabryką obiektów typu PhoneNumber i parserem, druga
strukturą do przechowywania właściwości konkretnych numerów. Dodatkowo,
PhoneNumberUtil wyposażono też w pewne metody, których można użyć na obiektach
PhoneNumber, aby wyciągnąć więcej dodatkowych informacji.
Zacząłem więc zastanawiać się jaką ścieżkę adaptacji obrać, patrząc jak radzili sobie z tym inni…
Struktury danych
Istnieje pewien szybki i kuszący sposób przysposobienia biblioteki Javy do użytku
w Clojure. Polega on na rozszerzaniu istniejących klas Javy i/lub
zastosowaniu konstrukcji proxy, która pozwala na tworzenie anonimowych
klas i ich egzemplarzy na bazie klas pochodzących np. z biblioteki
programistycznej. W ciele makra proxy możemy też definiować funkcje, których
wywołania będą przekierowywane do odpowiadających im metod obiektu.
Powyższe znajduje zastosowanie tam, gdzie mamy do czynienia z dużą liczbą specyficznych klas obecnych w bibliotece, a większość należy instancjonować. Towarzyszy mu jednak pewien istotny mankament. W Clojure bardzo lubimy znane typy i struktury danych, ponieważ w ten sposób możemy ponownie wykorzystywać raz napisane funkcje, które na nich operują. Spłaszcza to również krzywą uczenia się i upraszcza programy.
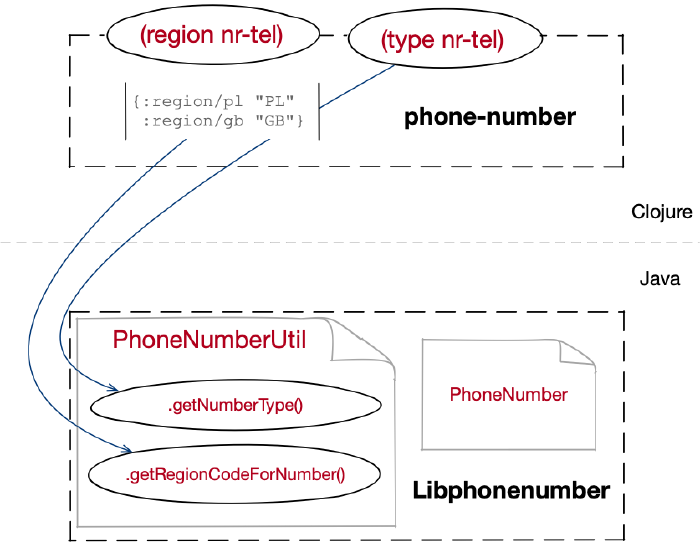
Szkic sposobu działania: phone-number ma udostępniać funkcje, odwołując się do metod Javy z biblioteki Libphonenumber i dokonywać transformacji struktur danych
Jeżeli mamy do czynienia z biblioteką Javy, która do poprawnej pracy wymaga tylko kilku niestandardowych obiektów, a ich przeznaczeniem nie są daleko idące optymalizacje w zakresie wydajności przetwarzania, wtedy warto rozważyć zwyczajne instancjonowanie klas, wywoływanie potrzebnych metod i konwersję rezultatów do znanych struktur języka Clojure. W odniesieniu do tego procesu używa się często slangowego terminu „owrapować”. Kiedy na wyjściu metod bibliotecznych mamy do czynienia z kolekcją, gdzie istotny jest porządek, można użyć konwersji do list, a gdy rezultaty mają być identyfikowane, lecz ich kolejność nie jest ważna, skorzystać z map. Możemy też pójść o krok dalej i nie tracić czasu na konwersje struktur…
Alan Perlis powiedział kiedyś:
Lepiej mieć 100 funkcji operujących na jednej strukturze danych,
niż 10 funkcji operujących na 10 strukturach.
Po wielu latach Rich Hickey, twórca języka Clojure, nieco przeformułował tę myśl:
Lepiej mieć 100 funkcji operujących na jednej abstrakcji danych,
niż 10 funkcji operujących na 10 strukturach.
Przez abstrakcję rozumiemy tu ujednolicony interfejs dostępu do danych o zbliżonej charakterystyce. Przykładem może być sekwencja, której można użyć, aby uzyskiwać dostęp do kolejnych elementów różnorakich kolekcji: list, zbiorów, elementów łańcuchów znakowych, a nawet map czy rezultatów wywołań funkcji. Używanie sekwencji polega na korzystaniu ze związanych z nimi operacji (tak naprawdę trzech: pobranie pierwszego elementu, pobranie reszty elementów, dodanie elementu na początku) bez względu na to, jaka struktura danych faktycznie magazynuje informacje.
Tym sposobem uogólniamy mechanizmy dostępu do danych, aby móc stosować te same funkcje niezależnie od ich ukształtowania. Co zyskujemy? Łatwość wdrożenia się (znajome struktury, znajome interfejsy) i możliwość korzystania z bazy rozwijanych przez społeczność i przetestowanych w warunkach bojowych funkcji.
Na marginesie: ciekawym przykładem abstrakcji są również specyficzne dla Clojure funkcje wyższego rzędu zwane transduktorami. Można je funkcyjnie komponować, a następnie przekazywać jako operatory do funkcji redukujących.
Pomysł jest więc taki, żeby tam, gdzie to możliwe „przystroić” dane zwracane przez metody pierwotnej biblioteki funkcyjnymi wrapperami, a tam, gdzie nie da się tego dokonać, spróbować konwersji. Podobnie z argumentami: warto będzie sprowadzić je do jakichś znanych typów i struktur.
Singleton PhoneNumberUtil
W bibliotece Libphonenumber głównym obiektem, którego metod używa się do walidacji
i analizy numerów telefonicznych, jest singleton klasy
PhoneNumberUtil
z pakietu com.google.i18n.phonenumbers.
Singleton to taki zwinny twór wykorzystywany m.in. w sytuacjach, w których powstawałoby wiele egzemplarzy tej samej klasy, a każdy z nich po krótkim użyciu i wywołaniu odpowiednich metod nie byłby już potrzebny. Tego rodzaju nadwerężanie obiektowego systemu typów byłoby stratą zasobów (pamięci i czasu procesora), więc ktoś wpadł kiedyś na pomysł, że być może wystarczyłaby tylko jedna instancja danej klasy w roli „narcystycznej maszynki do mięsa”, z której cały program mógłby korzystać – bez niepotrzebnego namnażania obiektów wyłącznie po to, aby wywołać parę metod.
Singleton w programowaniu zorientowanym obiektowo to po prostu jedna, globalna instancja danej klasy, której używa się najczęściej do:
-
wielokrotnego przetwarzania danych w modelu przelicz-i-zapomnij,
-
śledzenia współdzielonego, globalnego stanu
(np. bieżącej kondycji postaci w grze, współpracy z UI, obsługi logów itp.), -
dynamicznego tworzenia obiektów po wstępnym określeniu ich typu i początkowych właściwości (rola tzw. fabryki),
-
kontenera na globalnie widoczne metody w językach, którym brak przestrzeni nazw.
Tworząc singletony w językach programowania o imperatywnym rodowodzie – czy ogólnie
rzecz ujmując, utożsamiających dane z miejscem w pamięci – warto zatroszczyć się
o ich odpowiednią izolację w bieżącym wątku, ew. w mechanizmy międzywątkowej kontroli
współdzielonych danych (np. buforów używanych podczas prowadzenia obliczeń). W Javie
można zacząć od użycia słowa kluczowego
synchronized.
Klasy singletonowe w większości obiektowo zorientowanych języków wyposażone będą
w odpowiednie klasowe metody (zwane tu i ówdzie statycznymi) służące do ich
instancjonowania, czyli powoływania do życia obiektów (a właściwie pojedynczego
obiektu). W naszym przypadku taką metodą jest getInstance(), która przy pierwszym
wywołaniu utworzy i zwróci obiekt typu PhoneNumberUtil, a przy wywołaniach
kolejnych nie zainicjuje nowych egzemplarzy, lecz skorzysta z wcześniej
wykreowanego i to on zostanie zwrócony.
Obiekt PhoneNumber
No dobrze, mamy singleton PhoneNumberUtil i – jak podaje
dokumentacja
biblioteki Libphonenumber – w jego obiekcie znajdziemy wytwórczą metodę
parse(),
która przyjmuje numer telefoniczny w postaci łańcucha znakowego i zwraca nowy obiekt
typu
PhoneNumber.
Po przejściu przez parse() podany numer telefonu zmienia się w obiekt, którego
właściwości jesteśmy w stanie odczytywać, korzystając z odpowiednich metod. Na
przykład getCountryCode() poda nam numerycznie wyrażony kod kraju,
a getNationalNumber() zwróci lokalną część numeru w formie długiej liczby
całkowitej.
Czyli wystarczy napisać w Clojure funkcję, która pobierze wymagane argumenty, wywoła metody odpowiednich obiektów Javy i przekaże nam zwracaną wartość? Coś takiego jak poniżej?
(defn region
([phone-number]
(region phone-number nil))
([phone-number region-code]
(.getRegionCodeForNumber
(PhoneNumberUtil/getInstance)
(.parse (PhoneNumberUtil/getInstance)
phone-number
region-code))))
(defn region
([phone-number]
(region phone-number nil))
([phone-number region-code]
(.getRegionCodeForNumber
(PhoneNumberUtil/getInstance)
(.parse (PhoneNumberUtil/getInstance)
phone-number
region-code))))
Mamy tu funkcję wieloczłonową, czyli taką, która ma więcej niż jedną
argumentowość (arność). W Clojure nie przeciążamy funkcji, przeciążamy ich
argumentowości. W wariancie jednoargumentowym pobierany jest tylko numer telefoniczny
i wywoływany jest wariant dwuargumentowy z przekazaniem w miejscu kodu regionu
wartości nieustalonej nil. Zostanie ona potraktowana przez metody jak znakowy
łańcuch pusty, a kod regionu będzie musiał być zawarty w podanym numerze
(np. w postaci kodu kraju po znaku plusa).
Jest prawie dobrze, ale może warto utworzyć osobną funkcję dla pobierania instancji?
Nie musi być eksponowana publicznie, jako część interfejsu programisty, ale pozwoli
uniknąć powtórzeń w wielu innych funkcjach. Z tego samego powodu mogłaby też istnieć
wewnętrzna funkcja, która zmienia tekstowy numer w egzemplarz klasy PhoneNumber.
Zanim przejdę dalej, jeszcze raz przypomnę: w Clojure nie chcemy pamiętać dziesiątek nazw metod i klas Javy. Wolimy sprawdzone typy podstawowe i generyczne funkcje, które mogą na tych pierwszych operować. Nie mamy nic przeciwko danym o zagnieżdżonej, skomplikowanej strukturze i wielu etykietach, jeżeli taka jest ich natura. Zauważamy jednak problem z łączeniem ich kształtu i rodzajów wartości ze składnią bądź systemem typów języka programowania.
Program powinien przetwarzać dane,
nie upodobniać się
do nich.
Bez urazy – z doświadczenia wiem, że powyższe dobrze działa w książkach uczących
programowania na przykładach. Mamy klasę bazową Ssak i klasę potomną Niedźwiadek,
a w nich metody do obsługi ssaków i niedźwiadków. Pewną epifanią jest, gdy pierwszy
raz rozpoznamy, że obsługa niedźwiadka może skorzystać z już przygotowanych metod
obsługujących ssaka. Wow! I raz na jakiś czas, chyba na fali tego zachwytu, ktoś
wpada na wspaniały pomysł zaaplikowania takiej strategii do zarządzania magazynem
z tysiącami produktów. Naprawdę!
Wielu z czytających pewnie śmieje się teraz pod nosem w poczuciu wyższości, bo
przecież dobrze wiedzą, że warto oddzielać implementację od operacji na
danych. Abstrakcje są w modzie. W takim razie inny przykład: klasa Dokument
i podklasa Paragraf. Oczywiście to tylko namiastka, pierwszy tydzień nowego
projektu w hipotetycznym, zmęczonym biurowcu wypluwającym z siebie zlecenia dla
administracji publicznej. W ciągu roku klas będzie kilkadziesiąt, a metod
kilkaset. Potrzeba do tego dużo białych tablic, pakietów biurowych i producentów
kodu: sztygarów dziedziczenia, inżynierów testów i koderów robiących na przodku. Kto
chce zamykać polskie kopalnie, niech pierwszy rzuci cyfrowy brykiet!
W związku z powyższym pomysł z automatycznym mostkowaniem metod z klasy PhoneNumber
odpadł w przedbiegach. Zamiast tego postanowiłem, że będę pobierał uzyskane
właściwości numerów i konwertował je do form wyrażanych popularnymi typami
i strukturami danych spotykanymi w Clojure, a tam gdzie to możliwe
abstrakcjami. Zero waste!
Dobrze, zacznijmy od prostej rzeczy, czyli wrappera dla klasy singletonowej:
(defn instance [] (PhoneNumberUtil/getInstance))
(defn instance [] (PhoneNumberUtil/getInstance))
Mamy tu funkcję, która zwraca obiekt będący instancją PhoneNumberUtil. Będzie to
nasza najpopularniejsza funkcja, gwiazda wieczoru; z jej pomocą możliwe staną się
wszystkie inne operacje.
Teraz kod pobierający region będzie wyglądał następująco:
(defn region
([phone-number]
(region number nil))
([phone-number region-code]
(.getRegionCodeForNumber
(phone-number.util/instance)
(.parse (phone-number.util/instance)
phone-number
region-code))))
(defn region
([phone-number]
(region number nil))
([phone-number region-code]
(.getRegionCodeForNumber
(phone-number.util/instance)
(.parse (phone-number.util/instance)
phone-number
region-code))))
W powyższym phone-number.util jest przestrzenią nazw z pliku
util.clj. Możemy
tam zauważyć nieco inną postać definicji, bo zawierającą pewne rzeczy w nawiasach
klamrowych:
(defn instance
{:tag PhoneNumberUtil, :added "8.12.4-0"}
[]
(PhoneNumberUtil/getInstance))
(defn instance
{:tag PhoneNumberUtil, :added "8.12.4-0"}
[]
(PhoneNumberUtil/getInstance))
Takie nawiasy w kodzie Clojure oznaczają mapowe S-wyrażenie (literalną formę
asocjacyjnej mapy), a umieszczone w tym miejscu definicji funkcji mapowe wyrażenie
metadanowe. Jest to sposób adnotowania niektórych struktur, dzięki
któremu możemy sterować przebiegiem kompilacji, zasięgiem i innymi implementacyjnymi
aspektami programu. W tym przypadku mamy metadaną o kluczu :added, która będzie
wykorzystana w procesie generowania dokumentacji, a także metadaną :tag sugerującą
kompilatorowi zwracany przez funkcję typ danych. Nie jest to wymagane, ale pomaga
unikać mechanizmów refleksji i zwiększa wydajność.
Zastanawiał mnie jednak region. Zarówno jako podpowiedź przekazywana w drugim, opcjonalnym argumencie, jak i jako zwracana przez funkcję wartość. To łańcuch znakowy służący do klasyfikacji, a możliwa liczba takich łańcuchów jest skończona (tak jak liczba regionów). Może więc zamienić go w coś prostszego?
Zanim zabiorę się do konwersji tekstowych identyfikatorów regionów, poszukam innych parametrów wykorzystywanych w źródłowej bibliotece, które mają podobną charakterystykę – są elementami zbiorów o skończonych rozmiarach – i zobaczę w jaki sposób zostały obsłużone.
Wyliczenia
Patrząc na klasę PhoneNumber można zauważyć, że czegoś tam brakuje. W dokumentacji
nie ma wzmianki na przykład o rodzaju numeru telefonicznego, chociaż biblioteka
potrafi dokonać takiej klasyfikacji. Chodzi m.in. o rozróżnienie linii naziemnych,
pagerów i numerów przynależących do sieci telefonii komórkowej.
Okazuje się, że niektóre właściwości obsługiwane są bezpośrednio przez instancję
wspomnianej na początku, singletonowej klasy PhoneNumberUtil (u nas
phone-number.util/instance), a w tym przypadku przez jej metodę
getNumberType(). Z taką samą sytuacją mieliśmy już do czynienia podczas próby
odczytania regionu.
Wartością zwracaną przez wspomnianą wyżej metodę będzie jedna z możliwych stałych
typu wyliczeniowego PhoneNumberType z tej samej klasy, a oczekiwanym argumentem
obiekt typu PhoneNumber (czyli numer już po parsowaniu).
Typ wyliczeniowy (ang. enumerated type) to konstrukcja w niektórych językach programowania, która służy do wyrażania danych mogących przyjmować wyłącznie wartości z podanego zbioru. Co więcej, zbiór ten będzie odzwierciedlony w postaci etykiet tekstowych widocznych bezpośrednio w kodzie źródłowym.
W naszym przypadku będziemy mieli takie możliwe typy numerów telefonicznych:
FIXED_LINE,FIXED_LINE_OR_MOBILE,MOBILE,PAGER,PERSONAL_NUMBER,PREMIUM_RATE,SHARED_COST,TOLL_FREE,UAN,UNKNOWN,VOICEMAIL,VOIP.
Adaptacja
Spróbujmy wyeliminować przyszłe roboczogodziny z naszego projektu przez przekształcenie wspomnianych wcześniej wartości typów wyliczeniowych do słów kluczowych. Dzięki temu do walidacji DANYCH będziemy mogli użyć zwykłych zbiorów. Poza tym w przypadku zmian w bibliotece, do której dojdzie na drugim krańcu wszechświata i w zupełnie innym oprogramowaniu, nie trzeba będzie silić się na rozwiązanie problemu wyrazu przez jakieś domieszkowanie (nawet nie wiem czy w Javie jest możliwe w odniesieniu do typów enumerowanych) bądź definiowanie nowego typu wyliczeniowego.
Ochronę przed błędami programisty (i wiele więcej) zapewnią nam specyfikacje (ang. specifications, skr. specs) wejścia, wyjścia i ew. zachowania funkcji, a nie system typów. W ten sposób język nie będzie musiał „znać” kształtu danych i możliwych wartości w możliwych miejscach. Do tego posłużą odrębne struktury danych i odpowiednie konstrukcje pomagające nimi zarządzać – powitajmy mechanizm clojure.spec.
Klucze
Wracając do kluczy, zwanych też słowami kluczowymi (ang. keywords). Nazwa ta może być trochę myląca, ponieważ w większości języków programowania są to identyfikatory wbudowanych konstrukcji (odpowiedniki symboli z Lispów). W Clojure słowa kluczowe to typowo użytkowy typ danych, któremu najbliżej chyba do znanych języka Ruby symboli (tak, to nie pomyłka).
Z tożsamościowego punktu widzenia klucze są wartościami własnymi (singletonami). Gdy pierwszy raz skorzystamy z klucza o podanej nazwie, powstanie odpowiadający mu pamięciowy obiekt, a przy każdym kolejnym użyciu identycznie nazwanego klucza, kompilator wykorzysta odwołanie do już istniejącego. W efekcie słowa kluczowe cechuje duża szybkość porównywania, dlatego często używa się ich jako kluczy w asocjacyjnych strukturach danych (np. mapach).
Dwa tak samo nazwane słowa kluczowe wewnętrznie, na poziomie JVM, są referencjami do tego samego miejsca w pamięci, a więc na jeszcze niższym poziomie pamięciowymi adresami. Z kolei adresy to coś, co procesory lubią przetwarzać najbardziej i bardzo dobrze im idzie również ich porównywanie. Nie muszą wtedy skakać do podprogramu, który zdekoduje zawartość bądź odczyta specjalnie wyliczoną, unikatową sumę kontrolną każdego z obiektów w celu ustalenia, czy może są one takie same. W przypadku kluczy, porównuje po prostu, czy wskazują na ten sam adres. Mówi się na to równość referencyjna (ang. referential equality) w przeciwieństwie na przykład do równości strukturalnej (ang. structural equality), gdzie porównywana jest zawartość.
Klucz może być literalnie wyrażany w kodzie (np. :w-ten-sposób), ale może też być
utworzony na podstawie łańcucha znakowego (np. (keyword "w-ten-sposób")).
Żeby szybko zamieniać słowa kluczowe na typy numerów, dodałem taką mapę:
(def all
#::{
:fixed-line PhoneNumberUtil$PhoneNumberType/FIXED_LINE
:mobile PhoneNumberUtil$PhoneNumberType/MOBILE
:fixed-line-or-mobile PhoneNumberUtil$PhoneNumberType/FIXED_LINE_OR_MOBILE
:toll-free PhoneNumberUtil$PhoneNumberType/TOLL_FREE
:premium-rate PhoneNumberUtil$PhoneNumberType/PREMIUM_RATE
:shared-cost PhoneNumberUtil$PhoneNumberType/SHARED_COST
:voip PhoneNumberUtil$PhoneNumberType/VOIP
:personal PhoneNumberUtil$PhoneNumberType/PERSONAL_NUMBER
:pager PhoneNumberUtil$PhoneNumberType/PAGER
:uan PhoneNumberUtil$PhoneNumberType/UAN
:voicemail PhoneNumberUtil$PhoneNumberType/VOICEMAIL
:unknown PhoneNumberUtil$PhoneNumberType/UNKNOWN})
(def all
#::{
:fixed-line PhoneNumberUtil$PhoneNumberType/FIXED_LINE
:mobile PhoneNumberUtil$PhoneNumberType/MOBILE
:fixed-line-or-mobile PhoneNumberUtil$PhoneNumberType/FIXED_LINE_OR_MOBILE
:toll-free PhoneNumberUtil$PhoneNumberType/TOLL_FREE
:premium-rate PhoneNumberUtil$PhoneNumberType/PREMIUM_RATE
:shared-cost PhoneNumberUtil$PhoneNumberType/SHARED_COST
:voip PhoneNumberUtil$PhoneNumberType/VOIP
:personal PhoneNumberUtil$PhoneNumberType/PERSONAL_NUMBER
:pager PhoneNumberUtil$PhoneNumberType/PAGER
:uan PhoneNumberUtil$PhoneNumberType/UAN
:voicemail PhoneNumberUtil$PhoneNumberType/VOICEMAIL
:unknown PhoneNumberUtil$PhoneNumberType/UNKNOWN})
Mapa odwrotna przyda się do zamiany typów na klucze:
(def by-val
(clojure.set/map-invert all))
(def by-val
(clojure.set/map-invert all))
Symbole all i by-val nazywają te dwie mapy. Dzieje się to w ten sposób,
że w specjalnej, asocjacyjnej strukturze języka zwanej przestrzenią nazw
w wyniku użycia def dodawane jest przyporządkowanie każdego z nich do obiektu typu
Var, który z kolei wskazuje na odpowiednią strukturę danych w pamięci. W tym
przypadku przestrzeń nazw z tymi odwzorowaniami nazywa się phone-number.type
i określona jest w pliku
type.clj.
Symbol kratki z dwoma dwukropkami to ułatwienie, które oznacza, że każdy klucz
budowanej mapy będzie miał też dookreśloną przestrzeń nazw, ustawioną na podstawie
bieżącej przestrzeni z aktualnego fragmentu kodu źródłowego (tu
phone-number.type).
Klucz nie jest umieszczany w globalnym obiekcie przestrzeni nazw, tak jak to było
z all i by-val, ponieważ tam lądują globalne nazwy funkcji, klas Javy i ustawień
(zmiennych). Gdy podamy przestrzeń, klucz będzie po prostu wewnętrznie zbudowany
zarówno z nazwy przestrzeni i nazwy własnej, np. phone-number.type/mobile.
Użyta forma definiowania mapy jest więc zwięzłym sposobem zapisu, analogicznym do poniższego:
(def all
#{
:phone-number.type/fixed-line PhoneNumberUtil$PhoneNumberType/FIXED_LINE
:phone-number.type/mobile PhoneNumberUtil$PhoneNumberType/MOBILE})
(def all
#{
:phone-number.type/fixed-line PhoneNumberUtil$PhoneNumberType/FIXED_LINE
:phone-number.type/mobile PhoneNumberUtil$PhoneNumberType/MOBILE})
Po co w kluczach dodatkowe miejsce na przestrzeń nazw? Na przykład w przypadku, gdyby
programista przechowywał typ numeru telefonicznego w strukturze zawierającej również
inne właściwości (nawet niekoniecznie pochodzące z tej samej biblioteki). Będzie mógł
wtedy jednoznacznie rozpoznać, że ma do czynienia z rodzajem numeru
(:phone-number.type/mobile), a nie np. z mobilnym rodzajem niedźwiadka (:mobile).
I jeszcze jedna fajna sprawa. W Clojure klucz też jest funkcją, mapa też jest funkcją. To tzw. formy przeszukiwania kolekcji:
(:phone-number.type/mobile all)
; => PhoneNumberUtil$PhoneNumberType/MOBILE
(all :phone-number.type/mobile)
; => PhoneNumberUtil$PhoneNumberType/MOBILE
(:phone-number.type/mobile all)
; => PhoneNumberUtil$PhoneNumberType/MOBILE
(all :phone-number.type/mobile)
; => PhoneNumberUtil$PhoneNumberType/MOBILE
Tekstowe regiony
Z typem wyliczeniowym sytuacja jest jednoznaczna, a jak wyglądałaby konwersja
regionów (wyrażonych obiektami typu String) do słów kluczowych i vice versa?
Obiecałem, że wrócę do funkcji region:
(defn region
([phone-number]
(region phone-number nil))
([phone-number region-code]
(.getRegionCodeForNumber
(phone-number.util/instance)
(.parse (phone-number.util/instance)
phone-number
region-code))))
(defn region
([phone-number]
(region phone-number nil))
([phone-number region-code]
(.getRegionCodeForNumber
(phone-number.util/instance)
(.parse (phone-number.util/instance)
phone-number
region-code))))
Zarówno przyjmowany, jak i zwracany przez metody Javy kod regionu, ma postać tekstową
(np. "PL"). Trzeba więc pozyskać wszystkie możliwe wartości i zbudować słownik,
który w Clojure nazywamy mapą. W pliku
region.clj
zdefiniowałem następującą zmienną globalną:
(def all
(let [tns (str (ns-name *ns*))]
(into #::{}
(map
(juxt #(keyword tns (clojure.string/lower-case %)) identity)
(.getSupportedRegions (phone-number.util/instance))))))
(def all
(let [tns (str (ns-name *ns*))]
(into #::{}
(map
(juxt #(keyword tns (clojure.string/lower-case %)) identity)
(.getSupportedRegions (phone-number.util/instance))))))
Co się tu dzieje? Kod w Lispie czytamy od środka:
-
Wywoływana jest metoda
.getSupportedRegionsz singletonuPhoneNumberUtili uzyskujemy zbiór łańcuchów znakowych. -
Przekształcamy każdy z elementów, traktując funkcją
map, w taki sposób, że:-
Dla każdego tekstowego regionu tworzone są 2 nowe wartości w formie dwuelementowego wektora (efekt działania
juxt):-
słowo kluczowe (
keyword) o nazwie takiej jak nazwa regionu przekształcona do małych liter (lower-case) i z ustawioną przestrzenią nazwphone-number.region(z odczytu leksykalnego powiązaniatns, gdzie przypisano wartość bieżącej przestrzeni ustawionej w nagłówku pliku); -
zastany łańcuch znakowy (
identity).
-
-
-
Uzyskana sekwencja wektorów (wyjście z
juxt) jest używana przezinto, żeby wprowadzić ją do pustej mapy, w której kluczami będą pierwsze, a przypisanymi do nich wartościami drugie elementy wektorów. -
Rezultat będzie przypisany do zmiennej globalnej
phone-number.region/all.
Nasza mapa regionów będzie więc wyglądała w ten sposób:
{:phone-number.region/pl "PL",
:phone-number.region/ta "TA",
:phone-number.region/ao "AO",
:phone-number.region/cf "CF",
:phone-number.region/is "IS"}
{:phone-number.region/pl "PL",
:phone-number.region/ta "TA",
:phone-number.region/ao "AO",
:phone-number.region/cf "CF",
:phone-number.region/is "IS"}
Na bazie tej struktury mogę stworzyć mapę dla argumentów i mapę dla wartości
zwracanych. Ta druga będzie dokładnie taka sama, ale do pierwszej dodam region
"ZZ", który identyfikowany jest kluczem :phone-number.region/unknown. Będzie on
oznaczał region nieustalony, który może się zdarzyć (nie wszystkie numery
telefoniczne są geograficzne).
W efekcie poszukiwania regionu możemy więc czasem uzyskać wartość
:phone-number.region/unknown, lecz wprowadzanie jej jako parametru przetwarzania
do funkcji operujących na numerach telefonicznych nie ma sensu. Dzięki osobno
określonym mapom dla wejścia i wyjścia mogę później łatwo testować program i dodawać
odpowiednie mechanizmy walidacji.
Po dodaniu jeszcze paru zmiennych i transformacji plik region.clj będzie zawierał
następujące globalne wartości:
phone-number.region/all– mapa regionów na ich tekstowe odpowiedniki,phone-number.region/by-val– mapa nazw regionów na słowa kluczowe,phone-number.region/all-arg–mapa regionów bez klucza:unknown,phone-number.region/by-val-arg–mapa nazw regionów bez klucza"ZZ",phone-number.region/unknown– klucz:phone-number.region/unknown,phone-number.region/unknown-val– tekst"ZZ",phone-number.region/default– identyfikator domyślnego regionu (nil),phone-number.region/default– wartość domyślna regionu (nil),phone-number.region/all-vec– wektor regionów (do generowania próbek),phone-number.region/all-arg-vec– wektor nazw regionów (jw.),phone-number.region/by-val-vec– jw. dla nazw regionów,phone-number.region/by-val-arg-vec– jw. dla nazw w roli argumentów,
I następujące globalne funkcje:
phone-number.region/valid?– sprawdzająca czy region jest poprawny,phone-number.region/valid-arg?– jw. dla argumentów metod,phone-number.region/parse– przygotowująca wartość argumentu dla metod.
Ktoś mógłby zapytać, dlaczego wcześniej pojawia się słowo „zmienna”, w dodatku „globalna”? Czy ta cała niemutowalność jest jakąś ściemą? A co z imperatywną tożsamością, która zależy od miejsca?
W Clojure istnieje konstrukcja, która przypomina konwencjonalne zmienne. Wynika to
z tego, że – podobnie jak inne Lispy – jest to język wieloparadygmatowy, a nie czysto
funkcyjny. Jednak zmienna w Clojure to w istocie referencja (typu Var) do stałej
wartości (ew. innej referencji), która w dodatku podlega rygorowi odpowiedniego
zarządzania dostępem w obrębie wielu wątków. Zmiennych globalnych nie używa się
do wyrażania często zmieniających się stanów, ale głównie do nazywania operacji
i ustawień.
Teraz funkcja region będzie prezentowała się następująco:
(defn region
([phone-number]
(region phone-number nil))
([phone-number region-code]
(phone-number.region/by-val
(.getRegionCodeForNumber
(phone-number.util/instance)
(.parse
(phone-number.util/instance)
phone-number
(phone-number.region/parse region-code))))))
(defn region
([phone-number]
(region phone-number nil))
([phone-number region-code]
(phone-number.region/by-val
(.getRegionCodeForNumber
(phone-number.util/instance)
(.parse
(phone-number.util/instance)
phone-number
(phone-number.region/parse region-code))))))
Widzimy, że opcjonalnie podawany region jest przekształcany przez funkcję
phone-number.region/parse, a zwracana wartość przez phone-number.region/by-val
(mapę w formie przeszukującej). Brakuje jeszcze wyabstrahowania operacji
przetwarzania samego numeru telefonicznego, ale jeszcze do tego wrócę.
Inne mapy i parsery
Opisaną wyżej taktykę odwzorowywania przyjąłem też w odniesieniu do:
- międzynarodowych kodów wywoławczych
(
net_code.clj), w tym:- kodów krajów
(
country_code.clj); - globalnych kodów sieci
(
net_code.clj),
- kodów krajów
(
- typów numerów
(
type.clj), - rodzajów kosztów dla numerów skróconych
(
cost.clj), - formatów zapisu
(
format.clj), - formatów stref czasowych
(
tz_format.clj), - rodzajów dopasowania podczas porównywania numerów
(
match.clj), - poziomów pobłażliwości podczas wyszukiwania w tekście
(
leniency.clj).
Podejście zbliżone zastosowałem również w mechanizmie obsługi ustawień językowych
(locale.clj),
ale polegam tam nie tylko na słowach kluczowych, lecz również na obiektach innych
typów. Dzięki temu dopuszczone są m.in. łańcuchy znakowe czy instancje
klasy java.util.Locale. Pomagają w tym funkcje z biblioteki
trptr.java-wrapper.locale.
Wyjątkowe potraktowanie tych parametrów wynika z tego, że w praktyce możemy mieć do czynienia z wieloma źródłami ustawień językowych w programach i nie zdziwiłbym się, gdyby najczęstszym były obiekty Javy. Buduję bibliotekę programistyczną, a nie samodzielną aplikację, więc tam, gdzie to możliwe, muszę dostosować się do konwencji stosowanych przez innych programistów.
Inferencja przestrzeni nazw
Dookreślanie przestrzeni nazw w kluczach ma sens w przypadku struktur wynikowych, np. gdy funkcja region zwraca wartość, ale można zastanawiać się nad ich rolą, kiedy słowa kluczowe w literalnych postaciach podawane są jako argumenty specyficznych dla biblioteki funkcji.
Oczywiście będą zdarzały się sytuacje, w których łatwiej obsłużyć dane pochodzące np. z bazy i mające dookreśloną przestrzeń nazw, zwyczajnie je przekazując. Mniejsza wtedy szansa pomyłki i wieloznaczności. Jednak gdy przychodzi do kodu źródłowego programu, warto szanować palce i jakoś to skrócić.
W phone-number istnieje na przykład funkcja
format,
która przyjmuje jako argument klucz określający sposób formatowania numeru i zwraca
odpowiednio ukształtowany łańcuch znakowy. Możliwe wartości to:
:phone-number.format/e164,:phone-number.format/international,:phone-number.format/national,:phone-number.format/rfc3966,:phone-number.format/raw-input.
(Oryginalnie raw-input nie istnieje jako format w Libphonenumber, ale to inna
historia).
Wywołać funkcję możemy z kolei tak:
(phone-number.core/format "+44 29 2018 3133" :gb :rfc3966)
(phone-number.core/format "+44 29 2018 3133" :gb :rfc3966)
Gdy spojrzymy na kod źródłowy odpowiedzialny za parsowanie formatu, zauważymy w nim taki fragment:
(let [k (util/ns-infer "phone-number.format" k use-infer)] […])
(let [k (util/ns-infer "phone-number.format" k use-infer)] […])
Wywoływana jest tu wewnętrzna funkcja
ns-infer
z pliku util.clj, której zadaniem jest przekształcenie podanego słowa kluczowego
w klucz z przestrzenią nazw określoną wartością drugiego argumentu (tu
phone-number.format), gdy takiej przestrzeni jeszcze w nim nie ustawiono, zaś flaga
use-infer jest ustawiona.
W uproszczeniu jej definicja wygląda tak:
(defn ns-infer
([ns-name k]
(if (simple-keyword? k)
(keyword ns-name (name k))
k))
([ns-name Keyword k use-infer]
(if use-infer (ns-infer ns-name k) k)))
(defn ns-infer
([ns-name k]
(if (simple-keyword? k)
(keyword ns-name (name k))
k))
([ns-name Keyword k use-infer]
(if use-infer (ns-infer ns-name k) k)))
Iteratory
Gdy zerkniemy na typy wartości zwracanych przez metody
PhoneNumberUtil,
zauważymy że dwie z nich są obiektami typu
java.lang.Iterable<PhoneNumberMatch>. W Javie istnieje interfejs
Iterable, który klasy mogą implementować. Składają wtedy obietnicę, że znajdziemy
w nich konkretne metody zadeklarowane w danym interfejsie. W przypadku Iterable
obietnica ta dotyczy wyposażenia obiektów w tzw. iteratory, dzięki którym możliwe
jest przesuwanie się po elementach kolekcji.
Wspomniane metody biblioteki Libphonenumber (dokładnie findNumbers i jej
przeciążona wersja) umożliwiają wyszukiwanie numerów telefonicznych w tekście,
a rezultaty wywołań są kolekcjami wyposażonymi w iteratory. Czy w Clojure możemy
z tego skorzystać?
Bezpośrednio jest to możliwe, ale niezalecane, ponieważ iteratory zawierają mutowalny
element związany z ich bieżącą pozycją. Zamiast tego stworzymy w pełni funkcyjny
interfejs dostępu do nich bezujący na leniwych sekwencji. Pomysł na
zrobienie tego porządnie podrzucił w serwisie Stack
Overflow nasz rodak (lub ktoś
o polskich korzeniach), Grzegorz Łuczywo. Materializacja tej idei w kodzie
phone-number wygląda następująco:
(defn lazy-iterator-seq
([coll]
(lazy-iterator-seq coll (.iterator coll)))
([coll iter]
(lazy-seq
(when (.hasNext iter)
(cons (.next iter) (lazy-iterator-seq coll iter))))))
(defn lazy-iterator-seq
([coll]
(lazy-iterator-seq coll (.iterator coll)))
([coll iter]
(lazy-seq
(when (.hasNext iter)
(cons (.next iter) (lazy-iterator-seq coll iter))))))
Polimorfizm
Wyobraźmy sobie, że ktoś nie korzysta z phone-number do incydentalnego
przetwarzania pojedynczych numerów telefonicznych, na przykład w celu prostego
sprawdzenia poprawności, lecz ma dużą bazę danych i chce użyć biblioteki do pomocy
w tworzeniu statystyk dotyczących operatorów i regionów. Gdyby użył „krzykliwej”
funkcji
phone-number.core/info,
uzyskałby potrzebne dane, lecz dodatkowo doszłoby do zbędnych wywołań dodatkowych
funkcji. Mógłby więc spróbować użyć tylko tych operacji, które są potrzebne, aby
uzyskać potrzebne właściwości (np. phone-number.core/carrier
i phone-number.core/region).
Gdyby posłużyć się wymienionymi funkcjami w odniesieniu do numerów wyrażonych jako
łańcuchy znakowe, wtedy oczywiście uzyskamy rezultaty, lecz w międzyczasie za każdym
razem numer będzie poddawany analizie (parsowany) i pojawiał się będzie tymczasowy
obiekt klasy PhoneNumber. Dobrze byłoby, gdyby ze względów wydajnościowych udało
się przekazać nie tylko tekstowy zapis numeru, ale przygotowany na początku, już
poddany analizie obiekt. Z tego powodu zdecydowałem się na zmianę standardowych
funkcji w ich polimorficzne odpowiedniki.
Polimorfizm (ang. polymorphism) to ogólne określenie na mechanizmy pozwalające używać tych samych konstrukcji programu w odniesieniu do różnych danych. Dziedziczenie znane z OOP będzie polimorfizmem, przeciążanie funkcji będzie polimorfizmem, a nawet rzutowanie typów może być uznane za mechanizm polimorficzny.
W przypadku phone-number największy zysk z polimorfizmu osiągniemy na wejściu,
podczas przekazywania numeru telefonicznego, który może być:
- łańcuchem znakowym (np.
+48 601 100 601), - liczbą całkowitą uzupełnioną oznaczeniem regionu (np.
601100601,:pl), - obiektem
PhoneNumber.
Na początku korciło mnie, aby ukrywać jakiekolwiek obiekty pochodzące z biblioteki Libphonenumber i udostępniać interfejs bazujący wyłącznie na znanych z Clojure strukturach i typach danych. Zmieniłem zdanie, gdy zaobserwowałem, że wcale nierzadką praktyką jest wywoływanie kodu Clojure z poziomu Javy, a także, że świat nie kończy się na prostej walidacji danych wejściowych pochodzących z formularzy na stronach sieci web.
Aby umożliwić obsługę już przeanalizowanych danych w formie obiektów typu
PhoneNumber, musiałem przekształcić większość już napisanych funkcji w takie, które
byłyby w stanie pracować z argumentami różnych rodzajów. Po chwili przyjąłem jednak
taktykę polegającą na zbudowaniu tylko kilku punktów przekształcania danych
do obiektów PhoneNumber, aby następnie móc użyć tego rezultatu tam, gdzie trzeba.
Gdy w Clojure potrzebujemy szybkiego mechanizmu dyspozycyjnego bazującego na typie wartości przekazywanej jako pierwszy argument funkcji, używamy protokołów. Jest to bazujący na klasach mechanizm rozdzielania wywołań na podstawie pojedynczego argumentu (ang. class-based single dispatch on an argument). Brzmi to poważnie, ale polega na:
- wykrywaniu typu wartości przekazanej jako pierwszy argument wywołania,
- wywoływaniu funkcji stworzonej specjalnie do obsługi tego typu.
W praktyce będziemy mieli więc wiele wariantów tej samej funkcji, z których każdy w nieco inny sposób poradzi sobie z pierwszym argumentem.
Protokół (ang. protocol) przypomina znany z Javy interfejs i jest kontraktem opisującym jakie operacje będzie można wykonać w odniesieniu do konkretnego typu danych (obiektów konkretnej klasy). Gdy protokół zostanie opisany, możemy następnie oznaczać nim istniejące lub dopiero tworzone typy danych (klasy). Wiąże się to jednak z wymogiem zdefiniowania w nich wszystkich metod określonych protokołem (w Clojure wyrażonych w postaci funkcji).
W pliku
core.clj
mamy definicję prototkołu Phoneable, której skrócona wersja wygląda tak:
(defprotocol Phoneable
(valid-input? [phone-number])
(number [phone-number] [phone-number region-code])
(number-noraw [phone-number] [phone-number region-code])
(raw-input [phone-number] [phone-number region-code])
(valid? [phone-number] [phone-number region-code]
[phone-number region-code dialing-region]))
(defprotocol Phoneable
(valid-input? [phone-number])
(number [phone-number] [phone-number region-code])
(number-noraw [phone-number] [phone-number region-code])
(raw-input [phone-number] [phone-number region-code])
(valid? [phone-number] [phone-number region-code]
[phone-number region-code dialing-region]))
Widzimy tu 5 deklaracji funkcji, które będą musiały być zdefiniowane dla każdego
typu danych, którego wartości chcemy przekazywać jako ich pierwsze
argumenty. Najistotniejszą jest funkcja number. Przyjmuje ona numer telefonu
w jakiejś postaci i zwraca instancję klasy PhoneNumber.
Dalej w tym samym
pliku
mamy implementację protokołu Phoneable dla konkretnych typów. W przypadku obiektów
PhoneNumber funkcja number zwyczajnie zwraca otrzymaną jako argumet wartość, ale
gdy przejdziemy do typu
String,
zauważymy następującą definicję:
(number
([phone-number]
(number phone-number nil))
([phone-number
^clojure.lang.Keyword region-code]
(assert (valid-input? phone-number)
"Phone number string should begin with at least 3 digits")
(when (some? phone-number)
(.parseAndKeepRawInput
(util/instance)
phone-number
(region/parse region-code *inferred-namespaces*)))))
(number
([phone-number]
(number phone-number nil))
([phone-number
^clojure.lang.Keyword region-code]
(assert (valid-input? phone-number)
"Phone number string should begin with at least 3 digits")
(when (some? phone-number)
(.parseAndKeepRawInput
(util/instance)
phone-number
(region/parse region-code *inferred-namespaces*)))))
Widzimy tu dwie argumentowości. Pierwsza obsługuje numer bez podanego regionu
i wywołuje drugą, przekazując w tym miejscu wartość nieustaloną nil. Logika
działania znajduje się w wydaniu z dwoma argumentami. Na początku mamy prosty test,
czy podany numer nie jest zbyt krótki, a następnie warunkowe wywołanie metody
parseAndKeepRawInput() na singletonie PhoneNumberUtil (uzyskanym przez wywołanie
util/instance).
Kolejnym krokiem było użycie phone-number.core/number we wszystkich funkcjach,
które dostarczają informacji o charakterystycznych cechach numeru
telefonicznego. Dzięki temu mogą one obsługiwać różne typy danych.
Oto przykład znanej nam już funkcji phone-number.core/region, która od teraz
korzysta z phone-number.core/number do parsowania numerów:
(defn region
([phone-number]
(region phone-number nil))
([phone-number region-code]
(phone-number.region/by-val
(.getRegionCodeForNumber
(phone-number.util/instance)
(number phone-number region-code)))))
(defn region
([phone-number]
(region phone-number nil))
([phone-number region-code]
(phone-number.region/by-val
(.getRegionCodeForNumber
(phone-number.util/instance)
(number phone-number region-code)))))
Z kolei hipotetyczny programista korzystający z biblioteki będzie mógł napisać coś w stylu:
(require '[phone-number.core :as phone])
(let [numer (phone/number "+44 29 2018 3133")
nr-rfc (phone/format numer nil :rfc3966)
region (phone/region numer)
operator (phone/carrier numer)]
(dodaj-do-bazy konektor nr-rfc region operator))
(require '[phone-number.core :as phone])
(let [numer (phone/number "+44 29 2018 3133")
nr-rfc (phone/format numer nil :rfc3966)
region (phone/region numer)
operator (phone/carrier numer)]
(dodaj-do-bazy konektor nr-rfc region operator))
Lub też prościej:
(require '[phone-number.core :as phone])
(let [numer (phone/number "+44 29 2018 3133")
nr-rfc (phone/format numer :rfc3966)
region (phone/region numer)
operator (phone/carrier numer)]
(dodaj-do-bazy konektor nr-rfc region operator))
(require '[phone-number.core :as phone])
(let [numer (phone/number "+44 29 2018 3133")
nr-rfc (phone/format numer :rfc3966)
region (phone/region numer)
operator (phone/carrier numer)]
(dodaj-do-bazy konektor nr-rfc region operator))
TODO
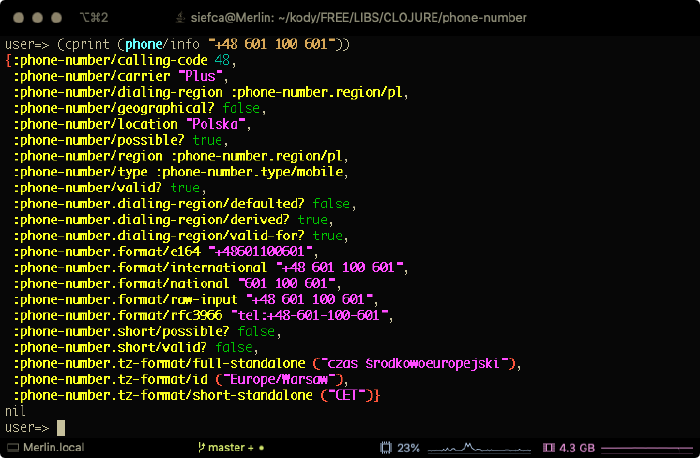
Warto wspomnieć, skoro było to wzmiankowane, że pierwsza wersja biblioteki
phone-number została uzupełniona o funkcję phone-number.core/info, która
prezentuje wszystkie ważniejsze właściwości numeru telefonicznego w postaci mapy
o unikatowych kluczach. Przykładowy rezultat jej wywołania wygląda tak:
Do opracowania zostały na pewno testy i specyfikacje, a właściwie ich rozszerzenie w taki sposób, aby pokrywały wszystkie funkcje.
W przypadku ręcznych (możemy je na wyrost nazwać behawioralnymi) testów, korzystam
z Midje, natomiast do specyfikacji używam
mechanizmu clojure.spec wzbogaconego biblioteką
Orchestra, która służy do instrumentalizacji
wywołań w środowisku rozwojowym. Testowanie automatyzowane jest narzędziem
Kaocha, które uruchamia testy napisane
ręcznie, jak również testy generatywne na bazie specyfikacji funkcji (argumentów,
zwracanych wartości i wyrażonej w uproszczony sposób relacji między nimi).
Poza zautomatyzowanym testowaniem i instrumentalizacją specyfikacje pełnią jeszcze
jedną funkcję: są dostępnym z zewnątrz mechanizmem walidacji. Jeżeli więc ktoś
poszukiwałby biblioteki, która zintegruje się z jego specami, może skorzystać
z phone-number.
Największym problemem jaki napotkałem podczas tworzenia specyfikacji były generatory, które nie mogły być automatycznie utworzone w wyniku złożenia mniejszych specyfikacji (wyposażonych we własne generatory) z oczywistego względu: nie istniały wbudowane reguły dla numerów telefonicznych, a dodane przeze mnie polegały na rezultatach pracy zewnętrznej biblioteki.
Mogłem wybrać łatwiejszą drogę i stworzyć generator liczb całkowitych, z którego co któraś byłaby poprawnym numerem. Takie podejście również się stosuje i działa ono. Chciałem jednak uzyskać pewną granulację sterowania samym samplerem, aby nie dochodziło do błędów braku poprawnych próbek przy kilkudziesięciu wywołaniach. Zbudowałem więc najpierw osobny generator, którego parametrami można sterować (podając np. cechy numerów, tj. regiony, typy itp.). Jest on w stanie zmieniać strategię skracania produkowanych numerów, jeżeli wykryje, że dla danych parametrów zaczyna pojawiać się zbyt wiele błędnych próbek.
Może napiszę kiedyś więcej na temat samych specyfikacji i testów, albo uzupełnię ten wpis, a tymczasem dziękuję za dotrwanie do końca i mam nadzieję, że biblioteka okaże się przydatna, a jeżeli nie, to może sama historia jej powstania rozjaśni pewne kwestie związane z programowaniem w Clojure.
Zobacz także
-
phone-number, kod źródłowy w serwisie GitHub
-
Phone-number, dokumentacja dla programistów