

Clojure jest językiem o solidnych fundamentach teoretycznych. W tej części zajmiemy się podstawami koncepcyjnymi tego dialektu Lispu, a dokładniej definicjami stanu, tożsamości, powiązania i wartości. Pozwoli nam to oswoić się z paradygmatem funkcyjnym i zrozumieć dlaczego niektóre oczywiste czynności wymagają przeprowadzania operacji niestosowanych w innych językach programowania.
Stan, tożsamość i zmiana
Postrzegany przez nas świat jest pełen zmiennych stanów, które trwają w czasie. Możemy zauważyć, jak mijają pory roku, jak z dnia na dzień zmienia się liczba środków na naszych rachunkach bankowych i jak z biegiem lat nasi znajomi inaczej wyglądają i zachowują się. Mimo to potrafimy wskazać, co się zmieniło bądź kto się zmienił, ponieważ są takie części obrazu świata, które wydają się niezmienne i jednostajne. Pozwalają nam one identyfikować elementy płynnej rzeczywistości, a także nadawać im nazwy. Te konstrukty to stałe tożsamości, które utrzymywane są w naszych osobistych systemach interpretacyjnych, czyli umysłach.
W języku polskim słowo „tożsamość” nacechowane jest osobiście. Kojarzy się często z czymś subiektywnym, wewnętrznym, z pewnego rodzaju rdzenną charakterystyką osoby bądź grupy osób. Angielski jest pod tym względem trochę bardziej neutralny i tamtejsze „identity” wiąże się ze wskazywaniem bądź wyróżnianiem, lecz nie ma tak internalizującego brzmienia. Myśląc o pojęciu tożsamości w kontekście technologii informacyjnych warto pamiętać o tej różnicy i próbować kojarzyć słowo „tożsamość” z abstraktem, który pozwala wskazywać (nazywać, identyfikować) zjawiska zewnętrzne i (rzadziej) wewnętrzne.
Programy komputerowe modelują rzeczywistość i operując na przyjętych modelach pomagają nam rozwiązywać rzeczywiste problemy. Te odzwierciedlenia mogą być jednak wyrażane na różne sposoby, które charakteryzowało będzie odmienne podejście do kwestii stanu, tożsamości i zmiany. Ów sposób patrzenia na te fundamentalne sprawy nazywamy paradygmatem (ang. paradigm), który dla programisty ma istotne konsekwencje techniczne.
Tożsamość
Kiedy coś, czemu nadaliśmy tożsamość (ang. identity), ulega zmianie, wciąż możemy to rozpoznawać, ponieważ w przestrzeniach naszej pamięci dokonujemy aktualizacji abstrakcyjnej koncepcji z powiązanym z nią obiektem o zmiennych cechach. Odbywa się to dzięki dwóm kompetencjom poznawczym: umiejętności wyodrębniania przedmiotu z tła i zdolności rozpoznawania jego istotnych atrybutów. Te ostatnie możemy nazwać składnikami tożsamości, ponieważ mają wpływ na uznanie przedmiotu za wyjątkowy.
W świecie ludzkiej percepcji tożsamość jest więc umysłowym konstruktem, który pozwala wyodrębniać pewne fragmenty świata, mimo że ich właściwości się zmieniają. Działa tu mechanizm abstrahowania przez redukcję: pewne cechy są ignorowane, a na bazie tych, które zostały, tworzona jest koncepcja jednolitego bytu.
W procesie interakcji ze światem nie potrzebujemy świadomie odnajdywać wielu charakterystycznych cech stanowiących o danej tożsamości, ponieważ nasz umysł będzie automatycznie, ze wszystkich sił, próbował podłączyć do aktualnego doświadczenia bazę wspomnień związanych z konkretną osobą czy przedmiotem, aby zachować w miarę trwały układ odniesienia. Pozwala to na korzystanie z wcześniejszych doświadczeń w dalszych interakcjach z wyróżnionym elementem otoczenia, zamiast od nowa wykształcać z nim relację. W ten sposób redukujemy napięcie, wiedząc czego można się spodziewać, a tym samym wybieramy mniej energochłonną i bardziej komfortową opcję.
Słowo „tożsamość” pochodzi z łacińskiego określenia idem, które oznacza „tak samo” (rdzeniem jest tu łacińskie id oznaczające „to”, „ta” lub „ten”, a uźródłowione w praindoeuropejskim i). Mamy do czynienia z pojęciem, które wyraża podobieństwo obiektów, a na poziomie procesu zdolność rozróżniania obiektów o wspólnych właściwościach (zarówno ich grupowania, jak i wyodrębniania).
To, jakie konkretnie składniki będą określały tożsamość, zależy od przyjętych założeń. Możemy polegać na atrybutach związanych na przykład z kształtem, kolorem, wagą bądź inną cechą, ale też z rolą bądź przeznaczeniem postrzeganego elementu w obrębie danego systemu interpretacyjnego. Tożsamość może, ale nie musi, zależeć od jakościowych bądź ilościowych właściwości przedmiotu, do którego się odnosi; może też, ale nie musi, wskazywać wielu elementów (nazwiemy ją wtedy tożsamością grupową).
Opisaną wyżej tożsamość sklasyfikujemy jako ekstensjonalną (ang. extensional), ponieważ składają się na nią zewnętrzne cechy zakorzenione w otoczeniu. Mając w przestrzeniach naszej pamięci obraz przedmiotu o pewnych kluczowych właściwościach konstytuujących jego tożsamość, możemy rozpoznawać go jako unikatowy obiekt o charakterystycznym znaczeniu. Gdy widzimy nasz ulubiony kubek do kawy, który ma pewne specyficzne cechy wyróżniające go spośród innych, możemy zidentyfikować go pojęciem „nasz kubek” i użyć, bez analizowania jego wszystkich cech.
Istnieje też inny rodzaj tożsamości, którą możemy określić mianem intensjonalnej (ang. intensional). Będzie ona zależała od stworzonych przez nas, abstrakcyjnych właściwości, niezależnych od cech wskazywanego przedmiotu bądź osoby. Przykładem może być tu nazwa stanowiska w zakładzie pracy, np. główny księgowy. Osoby piastujące tę funkcję na przestrzeni czasu mogą się zmieniać, lecz w wewnętrznych procedurach i procesach komunikacji (np. obiegu firmowych dokumentów) wzmiankowana będzie właśnie ta rola, a nie konkretny pracownik.
W przypadku języków programowania tożsamość ma podobną funkcję: służy do nazywania danych, żeby można było w pewnych kontekstach rozpoznawać je i odwoływać się do nich. Owe nazwy będziemy określali ogólnym terminem identyfikatory. W świecie komputerowych programów spotkamy się zarówno z tożsamościami ekstensjonalnymi, jak i intensjonalnymi.
W przypadku tożsamości intensjonalnych będziemy mieli do czynienia
z identyfikatorami, które powiązano ze zmiennym obszarem. Na przykład Suma_Środków
może być odniesieniem, które wskazuje liczbę całkowitą 123, aby za chwilę odwoływać
się do wartości 456, a jeszcze później do ∞.
Możemy zauważyć, że modelując tożsamość intensjonalną będziemy starali się uniezależniać ją od kolejnych wartości, a nawet rodzajów danych, do których się odnosi, aby była jak najbardziej „pojemna” i uniwersalna (mogła określać dane o różnej charakterystyce). Będzie wyrażała intencję programisty odnośnie roli i przeznaczenia danego abstrakcyjnego bytu w systemie interpretacyjnym.
W przypadku tożsamości ekstensjonalnej również będziemy mieli do czynienia
z identyfikatorem, lecz nie będzie on wyznaczał przeznaczenia danych, ale komunikował
wartość, która nie ulega zmianom. Na przykład x nazywający liczbę całkowitą 5.
Podsumowując: tożsamością w programowaniu nazwiemy abstrakcyjny, ustalony byt służący do identyfikowania zmieniających się bądź ustalonych wartości, które mają wspólne znaczenie w kontekście przyjętej logiki programu. Znaczeniem tym może być wartość (pojedyncza lub złożona) bądź rola serii wartości zmieniających się w czasie.
Aspekty tożsamości
Rozpatrując tożsamość w kontekście programowania komputerów, możemy wyróżnić jej kilka istotnych aspektów, których poprawna implementacja jest kluczowa:
Aspekt identyfikacyjny

Aspekt identyfikacyjny tożsamości pozwala używać jej do wskazywania danych z użyciem czytelnego identyfikatora i odwoływać się do wyrażanych na przestrzeni czasu wartości o wspólnych cechach w kontekście przyjętej w programie logiki. Dzięki niemu możemy rozpoznawać tożsamości w kodzie źródłowym i korzystać z nich w celu dostępu do wartości bieżących.
Aspekt abstrakcyjny
Aspekt abstrakcyjny pozwala korzystać z tożsamości w odniesieniu do danych o różnej charakterystyce (niezależnie od ich budowy czy wyrażanej wartości). Dzięki niemu możemy też traktować tożsamości jako samodzielne byty, na których da się wykonywać pewne operacje. Ta właściwość oznacza, że tożsamość ma wyższy poziom abstrakcji, niż wskazywane nią wartości.
Aspekt wyróżniający

Aspekt wyróżniający pozwala odróżniać wytworzone tożsamości i porównywać je ze sobą. Dzięki temu aspektowi możemy badać, czy mamy do czynienia z tą samą tożsamością, nawet gdyby została powiązana z różnymi wartościami na przestrzeni czasu. Warto zaznaczyć, że nie chodzi tu o porównywanie wartości bieżących, ale właśnie samych tożsamościowych konstruktów.
Aspekt kontrolny

Aspekt kontrolny (hermetyzujący) wprowadza do tożsamości mechanizmy kontroli dostępu (odczytywania i ustawiania) wartości bieżących, zapobiegając bezpośrednim zmianom wskazywanych struktur danych. Dodatkowo zapewnia sterowanie zasięgiem identyfikatorów i widocznością powiązanych z nimi wartości. Dzięki zarządzaniu dostępem możemy mieć pewność, że nie dojdzie do zmian danych inaczej, niż przez odwołanie się do tożsamości. Ten aspekt będzie istotny w przypadku tożsamości intensjonalnych.
Imperator z amnezją
W imperatywnym paradygmacie programowania (i podejściach pochodnych) świat programu komputerowego składa się z cyfrowych bytów przypisanych do pamięciowych lokalizacji. Oznacza to, że podstawowym sposobem na to, aby identyfikować serię zmieniających się stanów (np. liczbę środków na rachunku bankowym) jest poleganie na stałym umiejscowieniu ich w pamięci operacyjnej. Wydaje się to intuicyjne i łatwe do zrealizowania, ponieważ komputer wyposażony jest w RAM, a programy mogą tam przechowywać dane, korzystając z rozkazów procesora. Nazywamy to architekturą von Neumanna.
Historycznie rzecz ujmując, istnieje wiekowa linia języków programowania, których rodowód sięga języka Algol 58. Znajdziemy tam BCPL-a, B, C (i jego następcę ANSI C), Pascala, Delphi, Modulę, a nawet ich (i nie tylko ich) późniejsze kombinacje, czyli C++, Javę, Pythona i Ruby’ego. Wszystkie one dziedziczą istotną właściwość: bazują na mniej lub bardziej wyrafinowanym sposobie realizacji rozkazów zakorzenionym we wspomnianej wyżej architekturze. Aby to osiągnąć, wprowadzają koncepcję zmiennej (ang. variable), czyli konstrukcji, która pozwala odwoływać się z użyciem wybranej nazwy do określonego miejsca w pamięci i operować na zawartych tam danych.
W kodzie źródłowym tych języków wspomniany model świata będzie wyrażany z użyciem
konstrukcji reprezentujących struktury, których zawartość możemy zmieniać. Każda
operacja na danych będzie w istocie operacją na pamięciowych adresach, pod którymi
spodziewamy się je znaleźć. Gdybyśmy chcieli odzwierciedlić na przykład zbiór liści
na drzewie, utworzymy strukturę Drzewo zawierającą struktury typu
Liść. Oczywiście na poziomie implementacji będą to dane odpowiednich typów: albo
wbudowanych, albo stworzonych przez programistę na bazie obiektowego systemu typów –
zależnie od konkretnego języka.
Kiedy w uniwersum naszego programu nastanie abstrakcyjna jesień, zmienimy stan
obiektu Drzewo, usuwając liście bądź modyfikując ich kolor. Istotne jest jednak, że
dzięki nazwom i ustalonym lokalizacjom, możemy odwoływać się do pamięciowych struktur
identyfikowanych etykietami Drzewo i Liść.
W opisanym procesie na pierwszy rzut oka nie ma nic niespotykanego i wydaje się on całkiem naturalny, dopóki nie staniemy się dociekliwi i nie zaczniemy badać kilku istotnych kwestii: tożsamości, wspomnianego stanu i czasu.
Tożsamość imperatywna
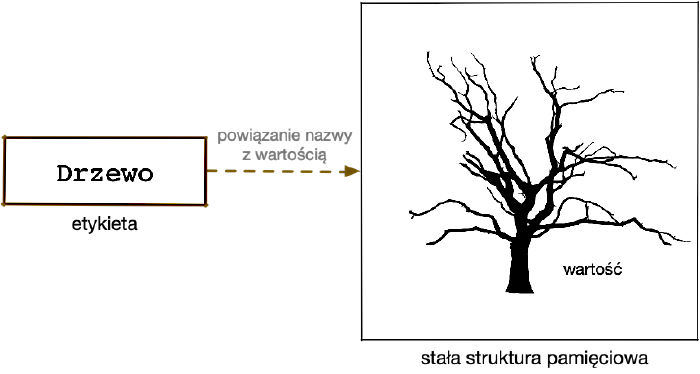
Zauważyliśmy, że w paradygmacie imperatywnym istotnym składnikiem tożsamości jest umiejscowienie identyfikowanego obiektu w konkretnym obszarze pamięci. Wyrazem tego jest zmienna, czyli wskazanie lokalizacji struktury powiązane z nadaną przez programistę nazwą. Zawartość ulega zmianom, lecz dzięki temu, że istnieje stała lokalizacja, możemy traktować pamięciowy obiekt jako byt o ustalonej tożsamości.

Składniki imperatywnej tożsamości: etykieta i obszar pamięciowy o zmiennej zawartości
Odnosząc się do przykładu z obiektem Drzewo: może ono mieć zmienną liczbę liści,
zmienną wysokość i zmienny kształt, ale wciąż będzie można je zidentyfikować,
ponieważ rezyduje w stałym obszarze lub odniesienie do niego znajduje się w stałym
miejscu. Etykieta Drzewo jest nazwą tego obszaru i wraz z nim pomaga stwarzać
tożsamość obiektu.
Hermetyzujący aspekt tożsamości jest w tym podejściu ograniczony niemal do zera. Możliwość modyfikacji danych identyfikowanych zmiennymi, do których dostęp uzyskano, nie jest ograniczona. Może być to o tyle problematyczne, że programy operujące bezpośrednio na zawartościach pamięci i polegające na znajdowanych tam danych są w stanie zmieniać ich kształt bez pośrednictwa tożsamościowych konstruktów, których użyto do identyfikacji. W efekcie znika element, który izolowałby pojedynczą lub zespoloną wartość na czas potrzebny do bezpiecznego przeprowadzenia istotnych operacji wymagających utrzymania spójności danych. Nie chodzi tu nawet o jednoczesny dostęp do zawartości zmiennych w pewnym czasie, ale o ich bezpośrednie modyfikacje prowadzone z różnych obszarów programu, np. z wnętrza funkcji, do której przekazano wskaźnik lub referencję. Utrudnia to diagnozowanie usterek, tworzenie zautomatyzowanych testów i wprowadza tzw. uboczny, współdzielony stan, o którym wspomnimy w dalszej części.
Z perspektywy paradygmatycznej tożsamość imperatywna nie jest w stu procentach intensjonalna, jak chcielibyśmy, ponieważ zależy od zewnętrznie przydanej cechy: ustalonego miejsca w pamięci operacyjnej, które od tożsamości nie zależy i można do niego uzyskać dostęp.
Dla zaznajomionych z programowaniem w języku C: Tożsamość imperatywną można skojarzyć ze znaną z operacji przypisania L-wartością (ang. L-value). Mamy tam do czynienia z pewną stałą nazwą, do której przypisywany jest jakiś adres w pamięci, aby móc odwoływać się do umieszczonych pod nim danych. Chociaż etykieta jest stała i adres jest stały, sama funkcja przypisania wartości nie jest operacją matematyczną, ponieważ aplikując taką samą nazwę (zmiennej) możemy otrzymywać różne wartości na przestrzeni czasu. Wynika to z mutowalnej natury danych umieszczanych pamięci. Tego typu tożsamość nacechowana więc będzie intensjonalnie: stała nazwa identyfikująca zmienne dane.
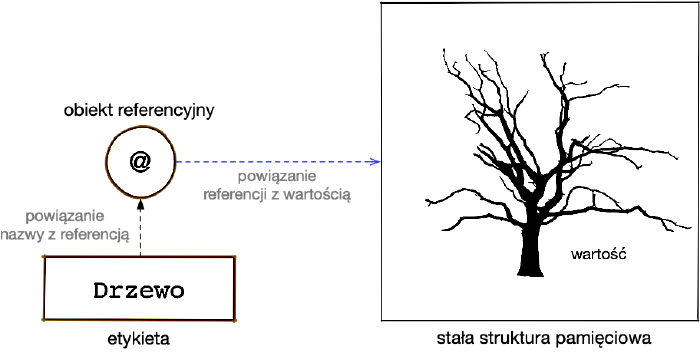
Tożsamość referencyjna
Ciekawym zjawiskiem jest tożsamość w językach zorientowanych obiektowo i nowoczesnych językach wieloparadygmatowych. Możemy ją nazwać tożsamością referencyjną, ponieważ bazuje na dodatkowych konstruktach stanowiących odniesienia do pamięciowych lokalizacji przechowujących obiekty.
Źródłem iluzji niezależności tożsamości referencyjnej są wskazywane obszary pamięci, co sprawia, że mamy do czynienia z pewnego rodzaju imitacją wartości. Powstaje wtedy swoista dwuskładnikowa tożsamość: jedna wytworzona referencyjnie, a druga związana z pamięciowym adresem. Oczywiście wieloskładnikowość nie jest niczym złym, jednak w tym wariancie wprowadza ona mechanizm dostępu do danych, który sprawia wrażenie bezpiecznego, chociaż takim nie jest.
Zależnie od języka programowania z referencyjną tożsamością mogą wiązać się dwa problemy. Pierwszym będzie bezpośrednia osiągalność zmiennych struktur wskazywanych referencją (gdy język nie hermetyzuje ich z użyciem odpowiednich metod kontrolnych przypisanych do obiektu), a drugim mutowalność samej referencji, którą można kojarzyć z etykietą w taki sam sposób, w jaki ustawiamy zawartości zmiennych. W efekcie mamy tu podatność na podobne komplikacje, jak w tożsamości typowo imperatywnej, bazującej na zmiennych.
Tożsamość referencyjna może być dobrym sposobem obsługi tzw. niezbędnych stanów współdzielonych, jednak jej składnikiem nie może być zmienny element bezpośrednio dostępny z wielu miejsc programu. Zwrócimy na to uwagę w dalszej części, przy okazji omawiania tożsamości funkcyjnej.
Tożsamość obiektowa
W językach zorientowanych obiektowo istnieje określona paradygmatem koncepcja tożsamości, którą definiujemy jako jedną z właściwości każdego obiektu, pozwalającą odróżnić go od innych niezależnie od tego, z jakich składa się danych. Dzięki niej programista jest w stanie sprawdzać, czy różnie nazwane referencje nie odnoszą się do tego samego obszaru. Najczęściej tożsamość ta będzie polegała na unikatowym identyfikatorze obiektu.
Możemy zauważyć, że taka tożsamość dobrze implementuje aspekt identyfikacyjny i rozróżniający, jednak brakuje jej aspektu hermetyzującego. Tu z pomocą przychodzą obiektowe mechanizmy, w których każdy obiekt może izolować własne zmienne składowe i dawać do nich dostęp tylko z użyciem odpowiednich metod (tzw. akcesorów). Problemem pozostaje jednak jakość owej hermetyzacji, ponieważ poszczególne pola struktury wchodzące w skład obiektu również mogą być obiektami, które ulegają zmianom bez jego pośrednictwa czy kontroli. Podobna cecha uwidoczni się również na poziomie referencji wskazującej obiekt, która – jak wspomnieliśmy wcześniej – efektywnie jest zmienną.
Wartości a zmienne
Wartości z natury są niezmienne. Parafrazując Richa Hickey’a, twórcę języka
Clojure: liczba 1 będzie zawsze liczbą 1, a wtorek nie stanie się środą. Istnieją
jednak dane takich typów, które mimo, że znaczeniowo pełnią rolę niezmiennych
wartości, są w praktyce mutowalnymi obiektami. Na przykład wyrażony w programie
komputerowym kolor żółty (reprezentowany pamięciowym obiektem Żółty) może zacząć
tak naprawdę odzwierciedlać kolor zielony, gdy dokonamy zmiany w jego wewnętrznej
strukturze i przedefiniujemy numerycznie wyrażoną barwę. Problem zaczyna się wtedy,
gdy zmiana taka może pochodzić z różnych miejsc lub zachodzić równolegle.
Język programowania zakorzeniony imperatywnie jest w stanie ukrywać fakt, że obiekty mogą ulegać mutacjom, tworząc stosowne interfejsy, które będą wprowadzały kontrolę zmian. Jest to popularną praktyką szczególnie w językach zorientowanych obiektowo. Możemy jednak zauważyć tu pewną niekonsekwencję na poziomie samej reguły, ponieważ fundamentalnie i tak większość danych będzie przechowywana w zmiennych strukturach, do których można uzyskać dostęp z pominięciem obiektów referencyjnych bądź opakowujących. Wystarczy jeden taki obiekt, jedno niezabezpieczone przed bezpośrednim dostępem pole, aby nie można było polegać na działaniu całego programu. W efekcie na programistę przeniesiony zostaje obowiązek odróżniania struktur o zmiennej strukturze od tych, które są typowymi (niezmiennymi) wartościami. W stosunku do tych pierwszych wymienionych będzie musiał korzystać z odpowiednich akcesorów w dostępie do danych, aby nie naruszyć referencyjnego powiązania, które zapewnia, że mamy do czynienia ze stałą tożsamością.
Zauważmy, że w wielu popularnych językach programowania sposoby obsługi zarówno
zmiennych struktur (np. obiektu Drzewo), jak i zasadniczo niezmiennych wartości
(np. liczby 1), są takie same. Zarówno Drzewo jak i wartość numeryczna 1 będą
związane z jakąś nazwą zmiennej (bądź nazwą obiektu referencyjnego). Brak jest
jednoznacznie wyrażonej i konsekwentnie stosowanej zasady rządzącej ważnymi cechami
wszystkich obsługiwanych danych.
Dane mutowalne są nadużywane, choć z powodzeniem wiele z nich można by traktować właśnie jak wartości, których nie trzeba nigdy modyfikować. W takich językach programowania przezorniej jest oczywiście zakładać, że każdy obiekt może ulegać zmianom. Podejście przeciwne, polegające na wprowadzeniu niemutowalnych wartości, byłoby możliwe, jednak wcześniej należałoby w jakiś sposób uniezależnić tożsamość od miejsca. Gdy tożsamość zależy od lokalizacji obiektu w pamięci, zmiana stanu będzie oznaczała jego mutację. Gdy uda się to zrealizować, należy dodatkowo zadbać o to, aby nie można było jej w prosty sposób obejść, pozwalając na dostęp do wartości bieżących wyłącznie z jej pośrednictwem.
Stan
Doprecyzujmy naszą wiedzę dotyczącą stanu (ang. state), uwzględniając wcześniej podane informacje. Nazwiemy nim kondycję pewnej tożsamości w danym punkcie czasu, na którą składają się cechy wyrażone jej wartością bieżącą. Ta ostatnia może być pojedyncza lub składać się z innych wartości.
Warto zaznaczyć, że przez zmianę stanu rozumiemy pojawienie się innego stanu zamiast bieżącego, a nie jakąś jego transformację. Z definicji stan uznajemy za element abstrakcyjny, wiążący konkretne wartości z konkretnym czasem w ramach pewnej tożsamości, chociaż często spotkamy się z użyciem określenia „stan” na nazwanie konkretnej konstrukcji, np. zmiennej widocznej w wielu miejscach programu.
Zauważmy, że tożsamość intensjonalna jest niezależna od wskazywanych nią wartości
bieżących, więc możemy używać jej do śledzenia i wyrażania zmieniających się,
niezbędnych dla działania programu stanów. W jednej chwili nasze hipotetyczne
Drzewo (tożsamość) może być obiektem typu Brzoza, w innym typu Topola,
a w jeszcze innym mieć wartość nieustaloną (nil).
W modelu imperatywnym stanem danej tożsamości będzie zawartość zmiennej reprezentującej ją w danym momencie.
Powiemy więc, że w programie imperatywnym stan zmienił się (w inny), gdy nastąpi zmiana danych rezydujących w pewnych obszarach pamięci identyfikowanych nazwą zmiennej; na przykład, gdy na modelowanym drzewie ubędzie liści bądź zyskają one inny kolor z powodu wywołania jakiejś procedury. Dojdzie wtedy do przekształcenia pamięciowych obiektów w miejscu (ang. in-place) ich rezydowania. Przyjęcie nowego stanu jest w tym modelu związane z „zapomnieniem” stanu poprzedniego przez wymazanie ostatnich wartości.
Globalny stan
Z punktu widzenia realizowania programu komputerowego najmniej pożądany będzie stan współdzielony między jednostkami strukturalnymi programu. Wyróżnimy go wtedy, gdy dany podprogram (np. procedura bądź funkcja) podczas obliczeń odwołuje się do zewnętrznej tożsamości (np. zmiennej) i używa wskazywanej nią wartości, która nie została mu jawnie przekazana (np. przez argumenty wywołania). W efekcie utrudnione jest testowanie i śledzenie błędów, ponieważ zachowanie takiej jednostki uruchomieniowej i zwracana przez nią wartość (dane wyjściowe) nie są w pełni determinowane przez jej formalną specyfikację (zawierającą dane wejściowe i sposób ich przetwarzania), lecz w sposób ukryty zależą od otoczenia. W rezultacie wszystkie elementy programu, które polegają na tej funkcji również stają się zależne od zewnętrznego, współdzielonego stanu.
Spotkamy się czasami z określeniem „globalny stan” (ang. global state). Oznacza on taki stan, który wyrażany jest konstruktami dostępnymi właśnie z dowolnej części programu. Flagowym przykładem stanu globalnego jest zmienna globalna (ang. global variable) o zasięgu nieograniczonym, która jest współdzielona między wszystkimi wątkami i dostępna z każdego obszaru kodu źródłowego.
Zestaw wszystkich pamięciowych obiektów wspomnianego rodzaju nazwiemy globalnym stanem programu komputerowego, ponieważ ich zawartości bezpośrednio wpływają na sposób jego działania, a podczas ich użytkowania nie obserwujemy konieczności wywoływania jakiejś funkcji w celu dostępu do zawartości.
Rich Hickey porównuje czasem stan do atramentu wpuszczanego do wody. Jeżeli części programu polegają na obiektach reprezentujących globalny stan, szybko dochodzi do uzależnienia rezultatów działania całej aplikacji od tych niezależnych ognisk zmian. Gdy programu nie wyposażono w precyzyjne sposoby sterowania globalnym stanem, lecz jest on po prostu wyrażany zmiennymi strukturami przypisanymi do stałych miejsc, jego działanie może być nieprzewidywalne, a programista będzie miał utrudnione zadanie podczas lokalizowania przyczyn i obszarów występowania usterek. Te same wyrażenia kodu źródłowego będą w różnych momentach przeliczane do różnych wartości (czasem powodując też różne efekty uboczne). W językach zakorzenionych imperatywnie próbuje się przed tym zabezpieczać odpowiednio kontrolując widoczność, lecz mechanizmy te są łatwe do przypadkowego lub celowego obejścia; na przykład możemy zapamiętać referencję do zmiennej lub wskaźnik do jej pamięciowego adresu i nadal modyfikować zawartość, mimo że identyfikator został przesłonięty bądź oznaczony jako niewidoczny.
Stan niezbędny i uboczny
Źródłem zmian stanów będą nie tylko rezultaty obliczeń umieszczane w zmiennych strukturach, ale też np. operacje wejścia/wyjścia bądź rezultaty zdarzeń mających źródło w podprogramach obsługi interfejsu użytkownika. Stany mające źródło we wprowadzanych, zmieniających się danych zewnętrznych będą stanami niezbędnymi (ang. essential), ponieważ ich obsługa wymagana jest do poprawnego działania programu i nie możemy ich zignorować czy uniknąć.
W pewnych przypadkach źródła zmiennych stanów będą obecne w samej konstrukcji programu. Mogą one być przypadkowe lub wynikać z przemyślanej decyzji programisty, aby w przejrzystszy, łatwiejszy bądź bardziej wydajny sposób zarządzać informacjami wykorzystywanymi w różnych obszarach kodu. Przykładami mogą być tu globalne lub ograniczone leksykalnie liczniki, kolejki komunikatów wykorzystywane do przetwarzania danych itp. Tego typu stany nazwiemy przypadkowymi lub ubocznymi (ang. accidental).
Problemem nie jest sama konieczność obsługi niezbędnych bądź przypadkowych stanów, lecz jakość mechanizmów służących do wyrażania ich i zarządzania nimi (w tym mechanizmów utrzymywania tożsamości).
Stan a tożsamość
Niezmienna tożsamość pozwalająca śledzić następujące po sobie szeregi danych o wspólnym przeznaczeniu (np. rezultaty kalkulacji, zdarzenia pochodzące z interfejsu użytkownika czy strumienie multimedialne) jest sposobem na to, aby móc nawiązywać z nimi relacje i posługiwać się nimi. Wiemy wtedy gdzie szukać źródeł informacji, które mają znaczenie w kontekście przyjętej logiki aplikacji, a dokładniej jakie operacje możemy wykonywać i jakich rodzajów cech oczekiwać. Drzewo ma liście, rachunek bankowy ma środki, gra ma punkty oraz pozycje graczy itd.
W modelu imperatywnym w przypadku zmiany stanu zmiennego obiektu dochodzi do jego mutacji, ponieważ modyfikacja wartości musi zachodzić w jego strukturze, w jego „tkance”. To istotna różnica między tym, jak funkcjonuje komputer, a system interpretacyjny człowieka, która sprawia, że programowanie jest czasami mniej intuicyjne, niż chcielibyśmy.
Na poziomie najmniejszych części imperatywnego modelu nie ma innej możliwości zmiany stanu, ponieważ miejsce nie może się zmienić, aby tożsamość nie została utracona. Możemy temu zaradzić, wprowadzając mechanizmy referencyjne, jednak będą one wyjątkami od reguły i pewnego rodzaju obejściem problemu, nawet jeżeli programista nie będzie musiał ich implementować, lecz będą wbudowane w język.
Czas
Przyjrzyjmy się przez chwilę koncepcji czasu (ang. time). Jako ludzie możemy go nazwać, ponieważ mamy pamięć i zauważamy zmieniające się stany lokalnego świata, bazując na różnicach tego, co odzwierciedlone w pamięci z tym, co ostatnio uświadomione dzięki zewnętrznemu i wewnętrznemu doświadczeniu. Przypomina to sekwencję obrazów ułożonych od najstarszego do najnowszego, które możemy porównywać i na tej podstawie uzyskiwać dodatkową wiedzę o kształcie lokalnego świata w różnych momentach. Stosowanie porównań między kolejnymi obrazami (i ich fragmentami) jest możliwe dzięki wrażeniu kontynuacji generowanemu przy udziale tożsamości rejestrowanych elementów rzeczywistości.
W przypadku imperatywnego podejścia do programowania, w którym reprezentujemy rzeczywistość z użyciem zmiennych, informacja o czasie zostaje efektywnie zagubiona. Na poziomie wątku zadania imperatywny język programowania cierpi na swoistą amnezję, ponieważ dokonuje nadpisywania struktur pamięciowych, aby wyrażać zmieniające się stany. Przypomina to trochę pracę roztargnionego artysty malarza, który poprawia tworzony obraz, zmywając pewne części i przykrywając je znów farbą, aby za chwilę zapomnieć, co wcześniej widniało na płótnie.
Zmienna struktura jest abstrakcyjną szufladką, w której różne wątki programu mogą na przestrzeni czasu umieszczać dane. Faktycznie podlega więc ona upływowi czasu, chociaż właściwość ta nie jest obsługiwana. A gdy dojdzie do tego, że jakiś wątek nie zakończy użytkowania zawartości struktury, a inny już ją zmieni? Pojawią się kłopoty.
Zauważmy, że mówiąc „na przestrzeni czasu” analizujemy proces z punktu widzenia człowieka, który obserwuje uruchomiony program. Ten ostatni w tym modelu podstawowo nie jest „świadomy” czasu. Wczytywane instrukcje pobierają dane z pamięci, a po przeliczeniu umieszczają w niej rezultaty, nadpisując zastaną zawartość. Nie istnieje pamięć zmian, więc nie można szczerze powiedzieć, że mamy do czynienia z obsługą czasu, mimo iż program wykonuje się w (postrzeganym przez nas) czasie.
Nic nie przeszkadza programiście wprowadzać w konkretnych sytuacjach konstrukty wyrażające czas, aby chronić pamięciowe obiekty przed zapomnieniem. Na poziomie implementacji możemy zastosować mechanizmy, które zabezpieczą pewne obszary pamięci przed jednoczesnym dostępem bądź stworzą strukturę, w której uwzględniamy historię zmian. Od lat w językach bazujących na paradygmacie imperatywnym stosuje się przecież odpowiednie dzienniki, blokady zapisu, a także zamrażanie i klonowanie obiektów. Możemy użyć takich sposobów, uwzględniając czas i zmienność pamięciowych struktur, lecz nie jest to inherentną zasadą imperatywnej rzeczywistości. Zasadniczo nie ma pod tym względem rygoru ze strony paradygmatu.
Kiedy wątek wykonywania się programu zostaje wybudzony kolejnym cyklem procesora, „spodziewa się”, że zastanie cały wirtualny świat dokładnie takim, jakim go pozostawił. Stąd tak klinicznie brzmiący tytuł sekcji: mamy niemałe kłopoty, jeżeli okaże się, że w praktyce modelowana rzeczywistość jest na tyle zmienna i wielowątkowa, że dużą część programu stanowią procedury obsługi chroniące go przed więcej niż jednym architektem (rdzeniem procesora realizującym równoległą czynność na tych samych danych).
Światy równoległe
Zastanówmy się nad hipotetyczną sytuacją, w której rzeczywistość imperatywna jest stwarzana i kontrolowana przez więcej niż jednego demiurga. Mamy tu na myśli programy wielowątkowe (ang. multithreaded) i współbieżne (ang. concurrent). Współdzielona jest w nich dostępna aplikacji pamięć, a jeden uruchomiony wątek może „popsuć” zapamiętaną rzeczywistość innemu. Jeżeli program nie będzie pisany z uwzględnieniem tego zagrożenia, jego działanie może być wadliwe.
Powyżej wspomniany problem łatwo zobrazować sytuacją z pamiętnikiem prowadzonym jednocześnie przez kilka osób. Jedna z nich chce go czytać, druga zamierza dopisać jakąś historię, a trzecia pragnie dodać ilustrację na jednej ze stron. Mamy trzy wątki wykonywania i jedną przestrzeń z danymi. Aby nie pojawiały się konflikty, można na przykład umówić się, że osoba, która operuje na pewnym fragmencie pamiętnika, otrzyma egzemplarz na wyłączność. W tym czasie pozostałe muszą zaczekać. Ten sposób nazywa się blokowaniem (ang. locking) i jest często wykorzystywany podczas dostępu do zasobów w imperatywnych programach wielowątkowych. Problemem w nim bywa kiepska wydajność (polegająca na przykład na konieczności cyklicznego sprawdzania, czy blokada została już zdjęta) i sytuacje tzw. zakleszczeń (ang. deadlocks).
W analogii z pamiętnikiem zakleszczenie mogłoby polegać na tym, że pierwsza osoba zakłada blokadę na wyłączność wprowadzania zmian w pamiętniku, druga czeka na nią, trzecia czeka na drugą, a pierwsza nie zauważa, że ma wyłączność i również zaczyna oczekiwać, ale na trzecią – mamy wtedy impas. Wszystko to spowodowane zostało pierwotnie tym, że każdy z wątków miał absolutną i bezpośrednią władzę nad mutowalnymi obiektami znajdującymi się w pamięci. Sam więc, powodowany intencją programisty, musiał ją ograniczać, aby nie tworzyć sytuacji konfliktowych.
Innym sposobem na przedstawienie omawianego tu problemu może być użycie terminologii bazodanowej. Powiemy wtedy, że w modelu imperatywnym występuje zespolenie dwóch ważnych funkcji związanych z przetwarzaniem zbioru danych: postrzeżeniowej i operacyjnej. Gdy w systemie przetwarzania te dwie role nie są odpowiednio odseparowane (na poziomie mechanizmów rządzących dostępem do struktur danych), uzyskanie spójności w obrębie logicznie powiązanych wartości staje się utrudnione. Dzieje się tak dlatego, że występuje konieczność gwarantowania, iż odpowiedzialny za wprowadzanie zmian operator nie będzie aktywny w momentach odczytu danych przez postrzegającego. Praktycznym przykładem tego zjawiska jest konieczność zakładania blokad na tabele baz relacyjnych na czas wprowadzania w nich zmian, a także tworzenie kopii biznesowych baz, aby gwarantować dostępność podczas trwającego dłużej przeliczania większości danych (np. w procesach zamknięcia dnia).
Konsekwentny operator
Clojure proponuje bardziej funkcyjne podejście do kwestii tożsamości i zmieniających się w czasie stanów. Domyślnie mamy do czynienia z niezmiennymi wartościami, które reprezentowane są danymi niemutowalnymi (ang. immutable). Pamięciowe struktury używane do ich wyrażania nie ulegają modyfikacjom, a więc wartość raz wpisana do konkretnego obszaru pamięci pozostaje w nim do momentu usunięcia przez Garbage Collectora lub zakończenia pracy programu.
Niektóre wbudowane, złożone struktury danych mogą okazjonalnie zawierać zmienne fragmenty, aby po wykonaniu na nich pewnych operacji (np. dodania jednego elementu do wektora zawierającego ich milion) współdzielić niezmienione części z nową instancją. Motywacją jest tu oszczędność pamięci i czasu potrzebnego na wykonanie pełnej kopii. Fakt ten jest jednak skutecznie ukrywany i izolowany, a nowa struktura będzie z punktu widzenia działającego programu widziana jako niezależna od bazowej. W praktyce więc tego typu obiekty również są niezmienne.
W programowaniu zorientowanym funkcyjnie zamiast imperatora realizującego kolejne rozkazy, mamy do czynienia z operatorem lokalnej rzeczywistości. On również ma na nią wpływ i może dokonywać zmian, ale czyni to w sposób mniej inwazyjny. Nie modyfikuje pamięciowych przestrzeni bezpośrednio, używając ich jak buforów akumulujących zmienne dane, lecz wytwarza kolejne „włókna” rezultatów. Taki sposób działania wynika z konstrukcji całego modelu rzeczywistości.
Podobnie jak w podejściu imperatywnym wartości będą zlokalizowane w jakichś pamięciowych przestrzeniach, ponieważ mamy do czynienia z pewną z góry określoną architekturą sprzętową. Różnica polega jednak na tym, że nie jest istotne w jakich, ponieważ nie ma do nich bezpośredniego dostępu – tożsamości w Clojure są wyabstrahowane i fundamentalnie niezależne od umiejscowienia. Operacja zmiany wartości w efekcie wykonania obliczeń nie nadpisuje zawartości przestrzeni pamięciowej, lecz stwarza nową wartość, tzn. na podstawie operatora i podanych operandów uzyskujemy wynik. Konsekwencją tego jest zupełnie inny mechanizm utrzymywania stałych tożsamości – nie można już z dobrodziejstwem sprzętowego inwentarza wiązać ich z umiejscowieniem.
Dane niemutowalne
Jeżeli, podążając za wcześniejszym przykładem, postanowimy w Clojure przyjrzeć się
strukturze elementu Drzewo, to w funkcyjnym świecie będzie ona wyrażana niezmienną
wartością, a nie mutowalną zawartością (zmienną). Wartość będzie przypominała
obraz utrwalony na fotograficznej błonie, który reprezentuje Drzewo w pewnym
momencie istnienia, wyrażając jego aktualny stan.
Pamięć w tym modelu przypomina pamięć człowieka: gdy obserwujemy zmianę właściwości jakiegoś elementu rzeczywistości, nie sprawia ona, że nasze wspomnienia związane z tą utrwaloną tożsamością są natychmiastowo zastępowane, lecz powstają nowe, bardziej aktualne, odnoszące się do strumienia zdarzeń o wspólnym rodowodzie.
Programistów przyzwyczajonych do konwencjonalnych zmiennych zastanawiać może, w jaki sposób opracowywać dane bez nadpisywania pamięciowych struktur. Czy tylko przez tworzenie kaskad zawartych w sobie wywołań funkcji, albo przez marnotrawienie miejsca na coraz to nowe rezultaty? Żeby to wyjaśnić musimy bliżej przyjrzeć się temu, jak w rzeczywistości funkcyjnej wygląda proces zmiany.
Migawki stanów
Świat rzeczywistości funkcyjnej przypomina migawki następujących po sobie stanów, gdzie jeden jest logiczną kontynuacją drugiego, zaś powodami wykształcania nowych wartości są operacje przeprowadzane na wartościach istniejących. Wynika to ze sposobu przechowywania rezultatów obliczeń: zamiast nadpisywać określoną strukturę w pamięci tworzone są serie rezultatów, którym w zależności od potrzeb możemy nadawać stałe tożsamości, aby śledzić zachodzące zmiany; możemy również polegać tylko na ostatecznym wyniku wszystkich zagnieżdżonych operacji – będziemy wtedy mieli do czynienia z wyrafinowanym kalkulatorem.
W przedstawionej wcześniej analogii z roztargnionym malarzem będzie to zmiana sposobu pracy z zamalowywania poprzednich obrazów na tworzenie coraz to nowych i ulepszonych szkiców na osobnych płótnach. Malarz jest w tym przykładzie funkcją, obraz ustaloną tożsamością, zaś kolejne pomalowane płótna wartościami, które sprawiają, że mamy do czynienia z różnymi stanami.
Stanem nazwiemy więc tu wartość bieżącą (w danym punkcie czasu) konkretnej, ustalonej tożsamości.
Funkcyjna tożsamość
Wiemy, że tożsamość pozwala identyfikować takie elementy modelu świata, które mogą przyjmować zmienne stany. W programach imperatywnych używamy w tym celu zmiennych, które przypisane są do konkretnych, pamięciowych lokalizacji. W przypadku danych niemutowalnych zastosowanie tego schematu byłoby problematyczne, ponieważ zakładając stałą lokalizację i umieszczoną w niej stałą zawartość tracimy zdolność wyrażania zmian. Będziemy więc mieli do czynienia z nieco innym podejściem.
Zauważmy, że to, co naprawdę łączy jedną wartość z drugą (powstałą na bazie tej pierwszej), to operacja, zwykle wyrażana funkcją. Tożsamość w funkcyjnym świecie nie będzie więc bazowała na umiejscowieniu danych w pamięci, ale na konstrukcji zdolnej do śledzenia łańcucha dowolnych wartości następujących po sobie w czasie i rezydujących w różnych miejscach. Nie możemy już polegać na tożsamości będącej pochodną architektury sprzętowej komputera, musimy więc samodzielnie stwarzać i utrzymywać ów konstrukt.
W funkcyjnym paradygmacie programowania tożsamość to po prostu tworzony od podstaw stały abstrakt – cyfrowy byt, który w kolejnych punktach czasu może identyfikować różne wartości. Poza tym będzie on w kodzie programu rozpoznawany z użyciem jakiejś czytelnej etykiety, aby można było wygodnie się nim posługiwać.
W Clojure istnieją dwa mechanizmy służące do budowania tożsamości. Pierwszego użyjemy do identyfikowania wartości, których nie musimy współdzielić z innymi wątkami wykonywania się programu, a drugiego do śledzenia zmieniających się w czasie, współdzielonych stanów.
Powiązania nazw
Pierwszym sposobem identyfikacji danych będą powiązania (ang. bindings) nazw z wartościami, czyli konstrukcje, które pozwalają na nadawanie tym ostatnim czytelnych identyfikatorów. Jeżeli wykonujemy jakąś operację i chcemy w pewnym obszarze programu zapamiętać jej rezultat, możemy skorzystać z odpowiedniej formy, która powiąże wynik z symboliczną nazwą. W obrębie bieżącego wątku wykonywania jesteśmy również w stanie dokonywać zmiany istniejącego powiązania przez skojarzenie już używanego identyfikatora z inną wartością.
Tego rodzaju tożsamości umożliwiają wyrażanie zmiennych stanów, lecz w zakresie
ograniczonym zarówno leksykalnie (powiązanie istnieje w obrębie wyrażeń wchodzących
w skład ciała odpowiedniej konstrukcji, np. let), jak i współbieżnie
(powiązanie dostępne jest tylko w obrębie lokalnego wątku wykonywania).
Możemy zauważyć, że tego typu tożsamościowy konstrukt eliminuje problemy z równoczesnym modyfikowaniem tych samych obszarów pamięci, lecz jest to osiągane przez pozbawienie go możliwości operowania na stanach, do których dostęp ma wiele wątków. Powiązań nazw z wartościami użyjemy więc raczej do zapamiętywania rezultatów obliczeń w obrębie wybranych fragmentów programu.
Składniki funkcyjnej tożsamości na bazie powiązania: etykieta i odwołanie do wartości
Gdyby do powiązań zastosować wcześniejszą analogię z pamiętnikiem, mielibyśmy do czynienia z czynnością uzupełniania go o nowe wpisy, jednak tylko przez wyznaczoną w danej chwili osobę i tylko przez dodawanie tekstu w jeszcze niezapisanych miejscach. Powiązaniem byłaby rola pisarza, którą mogłaby piastować w danym czasie jedna z osób znajdujących się przy stoliku.
Referencje
W celu identyfikowania zmiennych stanów, które są współdzielone między wątkami, skorzystamy z tożsamości o nieco bardziej finezyjnej konstrukcji. Przypomnijmy: potrzebujemy mechanizmu, który umożliwiałby identyfikację zmieniających się w czasie, logicznie powiązanych wartości, przy założeniu, że w tym samym momencie kilka wątków programu może mieć dostęp do wartości bieżącej i próbować ją odczytywać bądź modyfikować.
Współdzielonych stanów nie da się zupełnie uniknąć, szczególnie gdy aplikacja ma pracować z danymi, które pochodzą z zewnątrz. Strumienie tekstowe i multimedialne, działania użytkownika, komunikacja sieciowa, a nawet różniące się zawartości plików – są to źródła danych, których przetwarzanie o wiele przejrzyściej i łatwiej zaimplementować, gdy dopuścimy pamięciowe konstrukty reprezentujące zmienne stany.
Gdyby powyższe założenie próbować wprowadzić w życie z wykorzystaniem konwencjonalnych, imperatywnych zmiennych, implementacja byłaby mało efektywna, ponieważ pojawiłyby się wspomniane wcześniej problemy z nadpisywaniem danych przez inne wątki, koniecznością stosowania blokad implikujących podatność na zakleszczenia itd. Nie możemy również zastosować omówionych wcześniej powiązań, gdyż nie są one widoczne we wszystkich wątkach wykonywania się programu. Nawet gdybyśmy w jakiś sposób zmusili je do tego, ich aktualizacje nie byłyby bezpieczne w kontekście przetwarzania współbieżnego i moglibyśmy na nich polegać wyłącznie przy wielowątkowym identyfikowaniu wartości, które nie ulegają zmianom.
Kwestia podążania za łańcuchami zmian tworzącymi chwilowe wartości nie jest nowa, a rozwiązać ją można przez zaaplikowanie dwóch procesów: śledzenia (ang. tracking) wartości bieżącej i identyfikowania (ang. identifying) konstruktu śledzącego.
Aby sprostać omawianemu zadaniu Clojure wprowadza tzw. typy referencyjne, czyli takie rodzaje danych, które służą do wytwarzania specyficznych powiązań obiektów referencyjnych z wartościami przy odpowiednim sterowaniu dostępem. Tak wytworzona tożsamość zawiera pojedynczy, mutowalny element reprezentujący zmienny stan, przy czym nie służy on do przechowywania wartości, lecz odniesienia do już istniejącej. Odniesienie to, jak łatwo się domyślić, można zmieniać.
Żeby zaktualizować stan obiektu referencyjnego i powiązać go z nową wartością, należy posłużyć się odpowiednią funkcją. Jej zadaniem będzie obsługa procesu wprowadzania zmiany w taki sposób, aby był on współbieżnie bezpieczny. Oznacza to na przykład, że gdy w jakimś wątku następuje właśnie odczyt wartości, funkcja poczeka, aż zakończy się ta operacja i dopiero wtedy ustawi odwołanie do nowej wartości dla wszystkich wątków.
Z użyciem referencyjnego konstruktu śledzona będzie wartość bieżąca wyrażająca aktualny stan tożsamości. Sam obiekt referencyjny będzie można identyfikować w programie z użyciem nadanej mu z użyciem standardowego powiązania symbolicznej nazwy.
Składniki funkcyjnej tożsamości na bazie referencji: etykieta i odwołanie do referencji
W analogii do sytuacji z pamiętnikiem obiektem referencyjnym będzie osoba wyznaczona do koordynowania procesu umieszczania nowych wpisów. Każdy z autorów otrzyma od niej kopię wszystkich kartek, do których będzie mógł dopisywać własne historie. Warunkiem wprowadzenia zmian będzie jednak przekazanie brudnopisu do redaktora, aby dołączył nowe teksty do oficjalnego wydania. Pamiętnik jest tu tożsamością, ale sposobem dostępu do jego aktualnej wersji (bieżącego stanu) jest skorzystanie z pośrednictwa osoby redagującej. Odpowiada ona za łączenie otrzymanych w tym samym czasie aktualizacji w spójną całość, a także za uaktualnianie brudnopisów tym, którzy chcą jeszcze coś dodać.
W Clojure zależnie od zapotrzebowania użyjemy jednego z kilku obecnych typów referencyjnych:
-
Var– gdy zechcemy globalnie nazwać jakąś wartość, funkcję bądź inny obiekt referencyjny; -
Atom– kiedy potrzebujemy konstruować liczniki, w których zmian może dokonywać tylko jeden wątek w danym kwancie czasu, a gdy to się dzieje, pozostałe, chcące również wprowadzać zmiany, muszą oczekiwać; -
Agent– w przypadkach dużej liczby aktualizacji bez międzywątkowego blokowania zapisu, lecz z oczekiwaniem na odzwierciedlenie zbuforowanych operacji, które może nastąpić po jakimś czasie; -
Ref– jeżeli zależy nam na koordynowanych transakcjach, w których wiele zależnych od siebie wartości bieżących wybranych tożsamości musi zostać uaktualnionych jednocześnie.
Poza tym istnieją jeszcze typy Future, Promise, Delay i Volatile, o których
można przeczytać w rozdziale poświęconym współbieżności.
Łatwo zauważyć, że opisywana tu funkcyjna tożsamość bazująca na referencjach do złudzenia przypomina tożsamość referencyjną z języków zorientowanych obiektowo. To dobra obserwacja, szczególnie w użytym określeniu poziomu podobieństwa (sic!). Zasada pozostaje ta sama: mamy specjalny obiekt, który odnosi się do innego i w ten sposób może dokonywać śledzenia zmiennych stanów bez względu na umiejscowienie czy charakter danych. W przypadku obiektowo zorientowanych języków zakorzenionych imperatywnie mamy jednak do czynienia ze zmiennymi strukturami, które podatne są na zaburzenia zawartości przez równolegle wykonywane operacje. Winną takiego stanu rzeczy nie jest oczywiście referencyjnie skonstruowana tożsamość, lecz to, że w praktyce mamy do czynienia z kolejną, ukrytą tożsamością, jednak bazującą na umiejscowieniu struktury, do której referencyjna tożsamość się odnosi. Przyczyną tego problemu są dane mutowalne używane zamiast wartości jako elementy wyrażające zmieniające się stany. Narzędzie jest więc dobre, lecz używane w odniesieniu do złych materiałów.
Przykład z życia
Aby zobrazować abstrakcyjny byt tożsamościowy, który może identyfikować zmieniające się stany, możemy posłużyć się przykładem. Wyobraźmy sobie, że mamy do wydania określoną sumę pieniędzy w postaci środków na rachunku bankowym. Żeby nie przemęczać umysłu każdorazowym myśleniem o ich dokładnej liczbie, pochodzeniu każdej kwoty i numerze konta, możemy naszym prywatnym zasobom finansowym nadać nazwę, na przykład kasa. Będzie ona identyfikowała konstrukt myślowy, który jest pewnym znaczeniem rezydującym w naszej pamięci.
Korzystając z informacji pochodzących z otoczenia, będziemy mogli wspomnianą przestrzeń pamięciową aktualizować. Dokonamy tego w momentach, w których zajdzie taka potrzeba, czyli na przykład, gdy dostaniemy wypłatę lub będziemy mieli większy wydatek – wtedy, gdy postanowimy sprawdzić stan konta. Z pojęcia kasa skorzystamy też wybierając się na zakupy.
Wyobraźmy sobie więc, że udajemy się do sklepu spożywczego, ale sprzedawca nie przyjmuje płatności kartą. Musimy wobec tego odwiedzić bankomat. Podejmując decyzję o wypłacie gotówki również pomyślimy o kasie, ponieważ pod tym terminem kryje się zestaw skojarzeń związanych z naszymi pieniędzmi. Istotnym elementem procesu zakupu towaru w sklepie będzie też skorzystanie z naszej kasy.
Zauważmy, że kasa najpierw znajdowała się w systemie komputerowym banku, potem w bankomacie, następnie w portfelu, aż w końcu mogliśmy jej użyć, żeby dokonać zakupu. Czy środki na rachunku można nazwać kasą? Tak. Czy jest nią także gotówka w dłoni? Owszem!
Kasa jest nazwą abstraktu o ustalonej tożsamości. Na przestrzeni czasu może być on kojarzony z różnymi wartościami, które same w sobie są stałe. Leżący na stole banknot o nominale 100 PLN nie stanie się dwustuzłotowym, a liczba wyrażająca stan środków w bazie danych banku nie zmieni numerycznego znaczenia.
Gdy ktoś zapyta ile mamy kasy, będziemy mogli odpowiedzieć ostatnią (aktualną) wartością. Skojarzenie właśnie z nią zostanie podmienione na inne w momencie, gdy dokonana będzie kolejna operacja zmieniająca stan kasy (czyli aktualizująca skojarzenie z konkretną wielkością), na przykład przez spoglądnięcie na rachunek ze sklepu, a wcześniej na wydruk z bankomatu.
Czy fakt, że kasa jest abstraktem czyni ją mniej namacalną? W pewnym sensie tak. Nie można bezpośrednio pokazać kasy, można jedynie pokazać jej aktualny stan, reprezentowany bieżącą wartością (np. liczbą banknotów o danych nominałach czy liczbową reprezentacją środków na rachunku).
Czy będąc abstraktem, kasa nie istnieje naprawdę? Nie istnieje materialnie, ale sam fakt, że możemy ją wyróżnić, czyni ją istotną, chociaż nieprzynależną do świata zmysłów. Najważniejsze jednak jest to, że można jej używać, czyli przeprowadzać na niej operacje. Będą to działania na niezmiennych wartościach, polegające na ich wczytywaniu i stwarzaniu nowych. Sklepikarz nie odetnie połowy banknotu, tylko wyda nam resztę, której wartość zsumujemy z wartością posiadanej kasy i zmienimy jej bieżący stan na inny.
Zaletą istnienia stałych, wyodrębnionych tożsamości, które mogą przyjmować różne stany, jest brak potrzeby rezygnowania ze stałych wartości w celu przeprowadzania operacji. Na co dzień bardzo często posługujemy się wartościami ustalonymi, których znaczenia się nie zmieniają – np. używamy ich we wzajemnej komunikacji do wyrażania wielkości, które mają uniwersalne znaczenie. Korzystamy też z abstraktów, ale nie przyszłoby nam nigdy do głowy, aby na stałe wiązać je z konkretnymi wartościami. Gdy dostajemy wypłatę, nie zapominamy o tym, że wcześniej zarabialiśmy mniej; gdy w sklepie otrzymujemy paragon, nie szukamy poprzedniego rachunku z tego samego miejsca, aby go zastąpić; a kiedy składamy zeznanie podatkowe, nie palimy wysłanych rok wcześniej kopii dokumentów, bo straciły na aktualności. Większość procesów zarządzania informacją bazuje na aktualizacji (podmianie) wartości bieżącej, a nie na modyfikacji poprzednich danych. Możemy więc zaryzykować stwierdzenie, że funkcyjna tożsamość jest bliższa modelowi świata, którym sami się posługujemy.
Przykład użycia
Spróbujmy bardziej konkretnych przykładów tworzenia tożsamości, czyli podwińmy rękawy i posłużmy się typami referencyjnymi języka Clojure.
Poniższa forma najpierw wytwarza obiekt referencyjny (w tym przypadku typu Var),
a następnie przypisuje ten obiekt do symbolicznej nazwy kasa. W ten sposób powstaje
zmienna globalna:
1(def kasa 5)
(def kasa 5)
Stworzyliśmy tożsamość o nazwa kasa z użyciem zmiennej globalnej, której obiekt
referencyjny wskazuje na wartość 5. W istocie mamy tu do czynienia z dwoma
powiązaniami:
- symbolu
kasaz obiektem referencyjnym (w przestrzeni nazw), - obiektu referencyjnego z wartością 5 (w jego strukturze).
A tak może wyglądać przyjęcie nowego stanu przez tożsamość określaną symbolem
kasa:
;; łatwo
(def kasa 100000)
;; bezpiecznie
(alter-var-root #'kasa (constantly 100000))
Pierwsze operacja przypisze nową wartość, lecz nie będzie to czynność synchronizowana między wątkami. Jeżeli przeprowadzilibyśmy ją wielokrotnie i współbieżnie, niektóre wątki korzystałyby z różnych wartości – szczególnie wtedy, gdy polegalibyśmy na wartości poprzedniej, aby wyliczyć nową.
Operacja druga uwzględnia przetwarzanie współbieżne i dokonuje zmiany wewnętrznego powiązania obiektu referencyjnego w taki sposób, że w trakcie uaktualniania wartości pozostałe wątki, w których pojawiłaby się również operacja aktualizacji tego stanu, będą oczekiwały, aż czynność prowadzona w bieżącym wątku się zakończy.
Zmienne globalne są specyficznymi tożsamościami, ponieważ zaprojektowano je z myślą o aspekcie identyfikującym. Użyjemy ich na przykład do nazywania funkcji, ustawień konfiguracyjnych czy globalnie dostępnych tożsamości referencyjnych, które powinny być dostępne w całym programie.
Spójrzmy na inny przykład, korzystający z najbardziej zaawansowanego typu
referencyjnego, czyli Ref. W jego przypadku wykorzystywana jest programowa
pamięć transakcyjna, dzięki której zmiany w wielu zależnych od siebie wartościach
bieżących wybranych, współdzielonych tożsamości są wprowadzane w sposób
koordynowany:
1;; Tożsamości referencyjne.
2(def gotówka (ref 0))
3(def rachunek (ref 0))
4(def skarbonka (ref 0))
5
6;; Tożsamość główna identyfikująca funkcję
7;; zwracającą stan kasy w postaci mapy.
8(defn kasa []
9 (dosync
10 {:gotówka @gotówka
11 :rachunek @rachunek
12 :skarbonka @skarbonka
13 :suma (+ @gotówka @rachunek @skarbonka)}))
14
15;; Otrzymywanie gotówki.
16(dosync (alter gotówka + 100))
17
18;; Otrzymywanie przelewu.
19(dosync (alter rachunek + 10000))
20
21;; Sprawdzanie stanu kasy.
22(kasa)
23; => {:gotówka 100, :rachunek 10000, :skarbonka 0, :suma 10100}
24
25;; Wypłata połowy środków z rachunku w gotówce
26;; i włożenie 100 zł do skarbonki.
27(dosync
28 (alter gotówka + (alter rachunek / 2))
29 (alter gotówka - 100)
30 (alter skarbonka + 100))
31
32;; Sprawdzanie stanu kasy.
33(kasa)
34; => {:gotówka 5000, :rachunek 5000, :skarbonka 100, :suma 10100}
;; Tożsamości referencyjne.
(def gotówka (ref 0))
(def rachunek (ref 0))
(def skarbonka (ref 0))
;; Tożsamość główna identyfikująca funkcję
;; zwracającą stan kasy w postaci mapy.
(defn kasa []
(dosync
{:gotówka @gotówka
:rachunek @rachunek
:skarbonka @skarbonka
:suma (+ @gotówka @rachunek @skarbonka)}))
;; Otrzymywanie gotówki.
(dosync (alter gotówka + 100))
;; Otrzymywanie przelewu.
(dosync (alter rachunek + 10000))
;; Sprawdzanie stanu kasy.
(kasa)
; => {:gotówka 100, :rachunek 10000, :skarbonka 0, :suma 10100}
;; Wypłata połowy środków z rachunku w gotówce
;; i włożenie 100 zł do skarbonki.
(dosync
(alter gotówka + (alter rachunek / 2))
(alter gotówka - 100)
(alter skarbonka + 100))
;; Sprawdzanie stanu kasy.
(kasa)
; => {:gotówka 5000, :rachunek 5000, :skarbonka 100, :suma 10100}
W powyższym przykładzie korzystamy z makra dosync, które realizuje obliczenia
wewnątrz transakcji. Każda tożsamość, która reprezentowana jest obiektem typu
Ref, będzie aktualizowana z użyciem odpowiednich mechanizmów międzywątkowej
koordynacji. Użyta w kodzie funkcja alter służy do zmiany stanu wybranej
tożsamości. Przyjmuje ona jej symboliczną nazwę, operator używany do dokonania
obliczeń i argumenty, które będą przekazane do operatora wraz z wartością
bieżącą. Funkcje realizujące operacje (tu +, / i -) będą wywoływane na migawce
wartości bieżących wszystkich aktualizowanych tożsamości. Migawka ta zawiera stany
tych tożsamości z momentu rozpoczęcia transakcji. Dopiero, gdy wszystkie wartości
zostaną przeliczone i przygotowane do aktualizacji, transakcja będzie zatwierdzona,
a gotówka, skarbonka i rachunek zyskają nowe, współdzielone wartości bieżące.
Więcej o wykorzystaniu typu Ref i programowej pamięci transakcyjnej można
przeczytać w odcinku 18. podręcznika.
Tożsamość imperatywna a funkcyjna
W paradygmacie imperatywnym mamy tożsamość bazującą na umiejscowieniu (konkretnych struktur danych), a w funkcyjnym bazującą na śledzeniu stanów (następujących po sobie wartości). Ta pierwsza jest bardziej konkretna i prostsza w konstrukcji, chociaż wskazuje na zmienne dane, z kolei druga wymaga skomplikowanych sposobów obsługi i świadomego uaktualniania powiązań z wartościami, lecz możemy jej użyć do śledzenia serii niemutowalnych danych (wartości) bez względu na ich pamięciowe umiejscowienie.
Funkcyjna tożsamość jest pierwotnie pusta, a więc samoistna – nie musi identyfikować żadnego obiektu, ani nie zależy od charakterystyki danych, do których się odnosi. Można ją nazwać abstrakcyjnym bytem wyższego rzędu, ponieważ wyraża relacje między innymi bytami (niezmiennymi wartościami znajdującymi się w pamięci).
W modelu imperatywnym tożsamość jest powiązana z pamięciową lokalizacją, a więc nie jest w pełni samoistna. Wyjątkiem będzie imperatywna tożsamość referencyjna, w której usunięto bezpośrednie powiązanie etykiety z miejscem, lecz wciąż nie ma tam wbudowanej kontroli nad procesem wprowadzania zmian w docelowym obiekcie. Ten hermetyzujący aspekt tożsamości jest zminimalizowany: tożsamościowy konstrukt nadaje się do identyfikowania danych, jednak nie pośredniczy w aktualizacjach, pozostawiając umiejętnościom programisty implementację w tym zakresie.
Powyższe świadczy o tym, że w paradygmacie imperatywnym tożsamość jest naturalnym efektem sposobu, w jaki funkcjonuje komputer. Jest obligatoryjna i zawsze obecna, co implikowane jest faktem, że zmienne struktury danych zajmują stałe miejsca. Programy, które chcą zabezpieczać się przed nadpisywaniem ważnych danych czy negatywnym wpływem globalnych stanów, muszą wprowadzać dodatkowe mechanizmy zarządzania dostępem do zmiennych i ukrywać możliwość bezpośredniego dostępu do nich przed programistą w mniej lub bardziej udany sposób. Na barki twórcy oprogramowania spada też obowiązek zadbania o to, aby właściwie aktualizować zmienne struktury w przypadkach globalnych stanów i wielu aktywnych wątków. Oznacza to, że twórca oprogramowania musi w jakiś sposób implementować tożsamościowe konstrukcje na własną rękę – oczywiście, jeżeli zależy mu na pełnej hermetyzacji i prawdziwym abstrahowaniu szeregów wartości.
W paradygmacie funkcyjnym tożsamość jest opcjonalna – wartości przyjmowane i zwracane przez funkcje doskonale radzą sobie bez niej. W tym modelu tożsamość możemy wytwarzać, gdy zachodzi potrzeba identyfikowania zmiennych stanów wyrażanych na przestrzeni czasu seriami powiązanych logicznie wartości. W Clojure również mamy do czynienia ze współdzielonymi stanami, nawet globalnymi, jednak już na poziomie mechanizmów języka są one odpowiednio izolowane i wyposażane w mechanizmy kontroli – właśnie dzięki przemyślanej implementacji tożsamości.
RAM
Można słusznie zauważyć, że programy korzystające z funkcyjnej tożsamości będą potrzebowały większej ilości pamięci, ponieważ każde powiązanie i każdy obiekt referencyjny są dodatkowymi strukturami danych, które trzeba utrzymywać. Jest to cena jaką płacimy za modelowanie bytu wyższego rzędu: musi on być niezależny od pozostałych obiektów oraz ich właściwości, żeby móc je wskazywać i identyfikować.
Znane z modelu imperatywnego poleganie na pamięciowej lokalizacji do określania tożsamości ma kilka wad, ale jedną istotną zaletę: oszczędność RAM-u. Również same mutacje struktur mogą być postrzegane jako zaleta, ponieważ nadpisywanie danych jest oszczędnością pamięci dostępnej programowi. Nie potrzebujemy też wtedy często interweniującego Garbage Collectora usuwającego zapamiętane rezultaty, które nie będą już programowi potrzebne.
Zysk pamięciowy to tylko jeden z czynników, który należy brać pod uwagę. Jeżeli aplikacja zamiast 1 megabajta danych będzie potrzebowała 2 czy nawet 10 megabajtów, a koszt 1000 megabajtów to minuta pracy firmy korzystającej z oprogramowania, wybór podyktowany wyłącznie oszczędnością RAM-u będzie zwyczajnie nieracjonalny; szczególnie, gdy weźmiemy pod uwagę zysk polegający na zwiększeniu produktywności związanej z usuwaniem usterek i testowaniem programu podczas jego rozwijania.
CPU
Dobra obsługa współbieżności, która cechuje Clojure z racji minimalnej liczby zmiennych obiektów pamięciowych, jest właściwością przybierającą na znaczeniu. Dzieje się tak ze względu na fizyczne granice skalowalności sprzętu elektronicznego, a konkretnie z powodu nieuchronnie nadchodzącego momentu, w którym nie będzie już można zagęszczać elementów półprzewodnikowych. Ograniczeniem jest tu po prostu budowa materii – miniaturyzacja kończy się na pojedynczym atomie.
Obejściem powyższego problemu jest budowanie układów, które nie są skalowane przez zwiększenie liczby elementów na pewnym obszarze, lecz przez złożenie kilku podobnych komponentów, które potrafią równolegle przetwarzać dane. W kontekście programowania mowa tu oczywiście o procesorach.
Architektura wielordzeniowa (ang. multi-core) radzi sobie z problemem skali przez wprowadzanie wielu fizycznych układów obliczeniowych. Jednak same rdzenie CPU nie zdadzą się na wiele, jeżeli nie zostaną odpowiednio obsłużone. Jednym ze sposobów jest zrównoleglanie procesów systemu operacyjnego, ale bardziej istotnym będzie jednoczesne wykonywanie kilku procesów lub wątków danego programu. W przypadku procesów do czynienia mamy z osobnymi przestrzeniami danych, więc konieczna jest gruntowna przebudowa aplikacji i wprowadzenie komunikacji międzyprocesowej. Z kolei przy korzystaniu z wątków (ang. threads) dane są współdzielone, ale pojawiają się problemy związane z wykonywaniem współbieżnym. Te ostatnie można rozwiązać, stosując m.in. wymienione już blokady, semafory czy tzw. model aktora, jednak będą to jedynie obejścia problemu, który leży u podstaw imperatywnego modelu.
W paradygmacie funkcyjnym i języku Clojure miejsca, w których może dochodzić do konfliktów podczas dostępu do współdzielonych danych, są wprost określane przez programistę w drodze wyjątku, z użyciem odpowiednich typów referencyjnych. Musi on więc wybrać, jakiego rodzaju mechanizmu użyje, zależnie od wymagań tworzonego oprogramowania.
Zobacz także: