

Struktury danych to, obok algorytmów wyrażanych operacjami, podstawowy składnik każdego programu komputerowego. Budując aplikacje, wybieramy takie struktury, które będą najlepiej nadawały się do przetwarzania danych w przyjętym przez nas modelu.
Struktury danych
Struktura danych (ang. data structure) to sposób organizowania danych w pamięci operacyjnej dostępnej programowi komputerowemu. W zależności od problemu wybieramy – obok odpowiednich algorytmów – takie struktury, które pozwolą najefektywniej go rozwiązać.
Przykładem struktury danych dopasowanej do potrzeb może być drzewo binarne wykorzystywane w implementacji algorytmu kompresji. Struktury danych są abstrakcyjnymi obiektami o cechach, które mogą być wyrażane z użyciem różnych typów danych.
Typ danych (ang. data type) to z kolei klasa wartości o wspólnych właściwościach, np. możliwych zakresach, wielkościach zajmowanej przestrzeni pamięciowej bądź sposobie reprezentowania informacji. Również w przypadku typów możemy mieć do czynienia z ich doborem odpowiednim do rozwiązywanego problemu. Na przykład obliczenia matematyczne ze względów wydajnościowych lepiej przeprowadzać na typach numerycznych, reprezentowanych w pamięci liczbami całkowitymi, a nie na łańcuchach znakowych przedstawiających liczby alfabetycznie (chociaż jest to możliwe i czasami stosowane, np. w rachunkach operujących na naprawdę wielkich wartościach). Z punktu widzenia kompilatora typ konkretnej wartości jest jej metadaną – adnotacją o tym, jak się z nią obchodzić podczas tłumaczenia kodu źródłowego na maszynowy.
Warto mieć na względzie, że współczesne urządzenia komputerowe potrafią operować wyłącznie na liczbach całkowitych, więc potrzebne są sposoby wyrażania danych o innej charakterystyce (np. napisów, liczb zmiennoprzecinkowych, ułamków czy wartości logicznych) w postaci właśnie tych liczb. W tym przypadku typy danych pomagają oznaczać pewne klasy wartości, aby następnie kompilator lub interpreter mógł dobierać odpowiednie metody ich reprezentowania we wspomnianej postaci numerycznej. Na przykład łańcuch znakowy będzie reprezentowany sekwencją bajtów lub struktur wielobajtowych, a operujące na nim funkcje, gdy zajdzie taka potrzeba, skorzystają z wbudowanych w język mechanizmów przezroczystej konwersji na odpowiadające wartościom symbole alfabetu.
Charakterystyki struktur danych w Clojure
Struktury trwałe
Wbudowane w Clojure struktury danych są trwałe (ang. persistent). Oznacza to, że wprowadzanie w nich zmian zawsze polega na stwarzaniu nowych obiektów przy zachowaniu oryginalnych wersji. Mamy więc do czynienia z pewnego rodzaju historią zmian.
Na poziomie wewnętrznych mechanizmów języka złożone struktury trwałe poddawane są pewnym modyfikacjom, aby wyrażać zachodzące w czasie zmiany. Polega to na tym, że w przypadku wprowadzenia zmiany w trwałej strukturze danych tworzona jest co prawda jej zupełnie nowa wersja, jednak nie dochodzi do kopiowania wszystkich elementów z poprzedniej (co byłoby mało wydajne), lecz w wynikowym obiekcie umieszczane są odwołania do poszczególnych elementów lub obszarów wersji pierwotnej struktury. Technikę tę nazywamy współdzieleniem strukturalnym (ang. structural sharing).
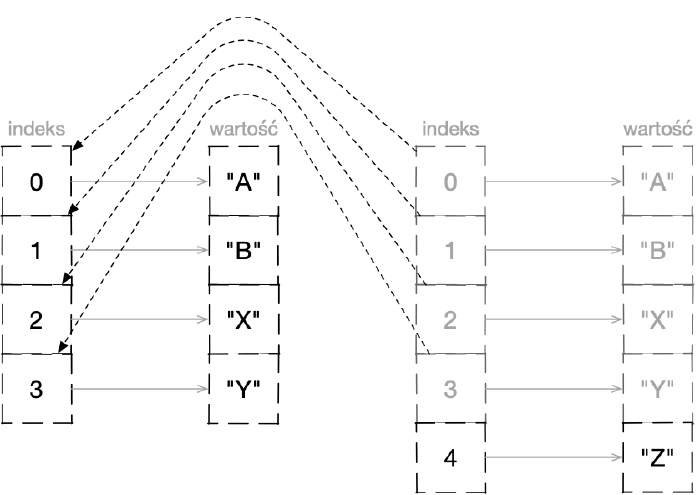
Po dodaniu elementu do wektora tworzony jest nowy obiekt, który współdzieli z poprzednim większość struktury
Złożone, wbudowane struktury języka Clojure bazują na wspomnianym współdzieleniu, które realizowane jest przez implementację drzew o dużej rozpiętości, wyposażonych w indeksy przyspieszające przeszukiwanie.
Dane niemutowalne
Na bazie trwałych struktur możliwa jest obsługa tzw. danych niemutowalnych (ang. immutable data), czyli takich, które nie zmieniają się w miejscu pamięciowego rezydowania. Wykonywanie operacji na wartościach sprawia, że powstają nowe wartości i nie dochodzi do modyfikacji istniejących obszarów pamięciowych. Gdybyśmy mieli do czynienia z językiem mocno imperatywnym, powiedzielibyśmy, że zmiennej, której raz nadano wartość, nie można już później modyfikować.
Chociaż wewnętrznie mamy do czynienia ze współdzieleniem danych w obrębie struktur trwałych i pewnymi modyfikacjami odniesień do zmienianych fragmentów, procesy te są bezpiecznie izolowane i ukrywane przed programistą w implementacji języka.
Z perspektywy twórcy programu operacja wykonywana na strukturze trwałej daje w efekcie całkiem nowy obiekt. Przykładem może być tu duży zbiór, do którego dodajemy jeden element. W wyniku takiej operacji w programie powstanie osobny zestaw elementów, wzbogacony o dodaną wartość, jednak „pod maską” mamy do czynienia ze współdzieleniem części drzewiastej struktury między oryginalnym zbiorem, a strukturą pochodną. Oszczędza to pamięć i czas.
Typy referencyjne
Istotnym wyjątkiem od reguły niezmienności danych są w Clojure tzw. typy referencyjne (ang. reference types). Ich pamięciową zawartość możemy nadpisywać, jednak odbywa się to z użyciem odpowiednich mechanizmów międzywątkowego izolowania i zarządzania sposobem wprowadzania zmian. Co to w praktyce oznacza? Jeżeli istnieje konieczność używania stałej nazwy do reprezentowania zmiennych danych, to istnieją obiekty takich typów, które nam to umożliwią, a dodatkowo zadbają o sytuacje wyjątkowe, np. jednoczesny dostęp do aktualnie wyrażanej wartości przez wiele wątków w tym samym czasie.
Obiekty referencyjne same nie przechowują wartości, lecz – jak wskazuje nazwa – umożliwiają odnoszenie się do innych danych. Można też powiedzieć, że pozwalają na tworzenie stałych tożsamości wyrażających zmieniające się stany. To, co jest aktualizowane, to właśnie referencja. W jednej chwili może wskazywać na daną wartość, a w drugiej na zupełnie inną. Część mutowalna (pamięciowy obszar poddawany modyfikacji) jest ograniczona do minimum, przez co łatwiej zarządzać zmianami.
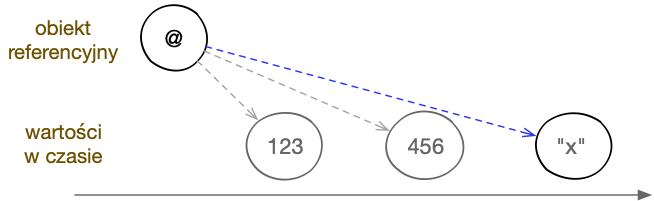
Typy referencyjne pozwalają wskazywać na zmieniające się w czasie wartości
W Clojure dzięki typom referencyjnym jesteśmy w stanie kontrolować zasady wymiany danych między równolegle wykonywanymi czynnościami, a także globalnie (w całym programie) identyfikować wybrane pamięciowe obiekty, np. widoczne w obrębie przestrzeni nazw funkcje bądź ważne ustawienia aplikacji.
Wybór konkretnego typu referencyjnego zależał będzie od sposobu, w jaki chcemy operować na danych w kontekście wielu wątków:
-
W przypadku stanów, które zmieniają się rzadko, skorzystamy z typu
Var, który domyślnie zapewni izolowanie wartości bieżących między wątkami. Obiekty tego typu są poddawane automatycznej dereferencji, tzn. wystarczy odwołanie do ich symbolicznej nazwy, aby poznać wartość bieżącą. -
Do obsługi tożsamości, których stany mogą być zmieniane przez wiele wątków, a zależy nam na tym, aby w danym kwancie czasu tylko jeden wątek mógł dokonać modyfikacji, posłużymy się typem
Atom. -
Jeżeli kolejność aktualizowania współdzielonego stanu nie jest dla nas istotna (np. w przypadku komunikatów obsługi zdarzeń) i nie chcemy, aby operacje aktualizacji były blokujące, wybierzemy typ
Agent. -
Bardziej złożone operacje, które wymagają skoordynowanej obsługi wielu wartości, będą wymagały typu
Ref, który korzysta z programowej pamięci transakcyjnej.
Poza wyżej wspomnianymi znajdziemy w Clojure jeszcze kilka innych typów referencyjnych:
-
Future– służący do realizowania obliczeń w wątku innym, niż bieżący; bieżący wątek jest blokowany dopiero przy próbie odczytu rezultatu (dereferencji); -
Promise– pełniący podobną funkcję doFuture, lecz z możliwością wyboru, w którym wątku przeprowadzone będzie ustawienie bieżącej wartości; -
Delay– wykorzystywany do synchronicznego odkładania w czasie wartościowania, które zostanie przeprowadzone przy pierwszej próbie odczytu; -
Volatile– przypominaAtom, jednak z uwagi na brak gwarancji, że operacje będą atomowe, wykorzystywany do przeprowadzania modyfikacji wartości bieżącej w obrębie pojedynczego wątku.
Zobacz także:
- Typy referencyjne w Clojure, rozdział XV.
Powiązania
Warto zaznaczyć, że w Clojure mamy przede wszystkim do czynienia z operowaniem na powiązaniach (ang. bindings) symbolicznych nazw lub typów referencyjnych z wartościami (ang. values), a nie na zmiennych (ang. variables). Wartości są niezmienne, a sposobem tworzenia nowych jest wykonywanie operacji na istniejących, pobieranie ich z otoczenia lub umieszczanie w kodzie programu w postaci literalnej.
Jeżeli rezultaty operacji przeprowadzanych na danych mają być w jakiś sposób
zapamiętywane i identyfikowane (śledzone), można z użyciem powiązań stwarzać
tożsamości, które będą wyrażały szeregi zmian. Są na to dwa sposoby:
pierwszy polega na powiązaniu symbolicznej nazwy ze wskazaną wartością (np. z użyciem
formy let), a drugi na stworzeniu obiektu referencyjnego i ustawieniu jego
wartości bieżącej, którą będzie można podmieniać przez aktualizowanie odniesienia.
W praktyce bardzo często spotkamy się z sytuacją, w której oba wspomniane wyżej
sposoby będą wykorzystywane równocześnie. Na przykład, aby stworzyć w programie
globalnie widoczną wartość o ustalonej nazwie (odpowiednik zmiennej), użyjemy
symbolicznego identyfikatora. Zostanie on powiązany w przestrzeni
nazw z obiektem referencyjnym typu Var, a dopiero zawarte w nim odniesienie
będzie wskazywało na konkretną wartość.
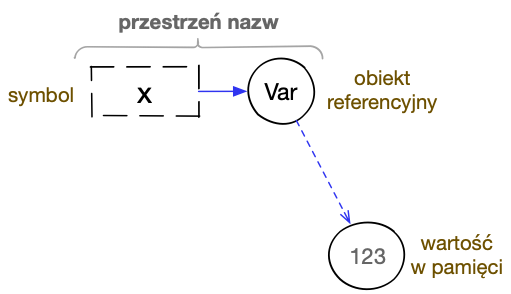
Zmienna globalna w Clojure bazuje na powiązaniu symbolu z obiektem referencyjnym typu Var i powiązaniu tego obiektu z wartością bieżącą
Nasuwają się tu dwa pytania. Po pierwsze: czy nie wystarczyłaby sama przestrzeń nazw i skojarzenie w niej symbolu z wartością w pamięci? Tak, byłoby to możliwe, jednak wtedy wprowadzilibyśmy do języka konwencjonalne zmienne globalne, a więc konstrukcję, która wymaga „uzbrajania” w odpowiednie mechanizmy kontroli i izolacji, gdy program ma działać na wielu wątkach. Dodatkowo, rodzaje tych mechanizmów musiałyby być dopasowane do typów konkretnych zmiennych. Bez tego, lub w przypadku błędnej implementacji współbieżnych wzorców przez programistę, mogłyby się pojawić problemy, z którymi mamy do czynienia w paradygmacie imperatywnym: sytuacje wyścigów, zakleszczenia itd.
Kolejną kwestią jest – wydawać by się mogło – nieco skomplikowane przedstawienie
całej operacji nazywania globalnych wartości. Najpierw symboliczny identyfikator musi
być przypisany do obiektu referencyjnego w przestrzeni nazw, a następnie ustawiona
powinna być wartość bieżąca odniesienia. Na szczęście nie musimy (chociaż możemy) tak
szczegółowo zarządzać tym procesem, ponieważ mamy do dyspozycji odpowiednie makra
i formy specjalne, np. def i defn.
(def x 1)
; => #'user/x
(defn funkcja [] 1)
; => #'user/funkcja
(def x 1)
; => #'user/x
(defn funkcja [] 1)
; => #'user/funkcja
W Clojure mamy również do czynienia z bezpośrednim kojarzeniem identyfikatorów
z wartościami, jednak odbywa się to w ograniczonym zasięgu leksykalnym, a dokładniej
w ciele wspomnianej wcześniej konstrukcji let. W takich przypadkach odwzorowanie
symbolu na wartość jest chwilowo (na czas obliczenia wyrażeń wprowadzonych do tej
formy) przechowywane na specjalnym stosie powiązań utrzymywanym dla danego
wątku. Również tu możemy mieć do czynienia z aktualizacją wartości, która polegać
będzie na nadpisaniu odwzorowania (w tzw. wektorze powiązań formy let), jednak
wydarzać się to będzie w sposób uszeregowany: najpierw pierwsza aktualizacja, potem
następna itd. Powiązanie leksykalne nie wyraża współdzielonego stanu, tak więc nie
musi być specjalnie traktowane w kontekście obsługi wielu wątków.
(let [x 1 ; x powiązany z 1
x (inc x) ; x powiązany z 2, bo (inc x)
x (inc x)] x) ; x powiązany z 3, bo (inc x)
; => 3
(let [x 1 ; x powiązany z 1
x (inc x) ; x powiązany z 2, bo (inc x)
x (inc x)] x) ; x powiązany z 3, bo (inc x)
; => 3
Zobacz także:
- „Powiązania i przestrzenie nazw”, rozdział VI.
Identyfikatory
Identyfikatory to takie typy danych, które służą do nazywania wartości, elementów kolekcji bądź obiektów referencyjnych. W Clojure w roli identyfikatorów stosowane są symbole lub słowa kluczowe. Te pierwsze, jeżeli wyrażone literalnie, mają specjalne znaczenie składniowe, tzn. przeprowadzany jest względem nich proces rozpoznawania nazw (ang. name resolution), zwanego też rozwiązywaniem nazw. Słowa kluczowe nie są automatycznie przekształcane na identyfikowane nimi obiekty, a stosowane są do tworzenia typów wyliczeniowych i indeksowania zawartości struktur asocjacyjnych.
Symbole
Symbol (ang. symbol) to typ danych, który pomaga w identyfikowaniu umieszczonych w pamięci wartości przez nadawanie im symbolicznych nazw. W Clojure symbole mogą mieć specjalne znaczenie, ponieważ są przez język używane do obsługi powiązań. Powiązania, jak mogliśmy przeczytać wcześniej, polegają na kojarzeniu symboli ze stałymi wartościami bądź z obiektami referencyjnymi.
Przypomnijmy: Na poziomie leksykalnym symbol to element języka Clojure, który zaczyna
się znakiem niebędącym liczbą i składa się ze znaków alfanumerycznych. Może również
zawierać znaki *, +, !, -, _, ', ?, <, > oraz =.
Jeżeli w nazwie symbolu wyrażonego literalnie pojawi się znak ukośnika (/), to znak
ten zostanie potraktowany jak separator części określającej przestrzeń nazw i części
stanowiącej właściwą nazwę. Podobne znaczenie ma kropka (.), lecz służy ona
do oddzielania nazw klas Javy lub części przestrzeni nazw pochodzących z pakietów.
Formy symboli
Istnieją trzy podstawowe formy bazujące na symbolach:
-
Symbol niezacytowany umieszczony w kodzie źródłowym będzie tworzył tzw. formę symbolową wyrażającą odwołanie do jakiejś wartości. Taki symbol będzie więc wartościowany, a dalsze obliczenia będą polegały na uzyskanym wyniku. Warunkiem jest oczywiście to, żeby wcześniej symbol o podanej nazwie był z wartością powiązany. Przykłady form symbolowych to:
nazwa,(nazwa inna-nazwa).
-
Symbol zacytowany lub wygenerowany z użyciem funkcji
symbolbędzie tworzył formę stałą reprezentującą sam obiekt symbolu, a nie identyfikowaną nim wartość. Powiemy wtedy o symbolu literalnym. Na przykład:'nazwa,'(nazwa inna-nazwa),(quote nazwa),(symbol "nazwa").
-
W pewnych konstrukcjach (np. w formie specjalnej
let, formie specjalnejdef, makrzedefnbądź wektorze parametrycznym funkcji) niezacytowane symbole będą tworzyły tzw. formy powiązaniowe. Dzięki nim możliwe jest wytwarzanie powiązań z wartościami, czyli nazywanie umieszczonych w pamięci obiektów, np. rezultatów wykonywanych operacji, przyjmowanych argumentów bądź wartości wyrażonych literalnie. Na przykład:let– powiązanie leksykalne:(let [nazwa 5] nazwa),def– powiązanie zmiennej globalnej:(def nazwa 5),defn– powiązanie zmiennej globalnej z funkcją:(defn nazwa []),- wektor parametryczny funkcji:
(fn [nazwa] nazwa).
Warto pamiętać, że w przeciwieństwie do symboli znanych z innych języków programowania (i do typu danych zwanego kluczami) symbole w Clojure nie są automatycznie internalizowane. Oznacza to, że mogą istnieć dwa symbole o takiej samej nazwie, reprezentowane przez dwa różne obiekty pamięciowe. Z tego powodu do indeksowania dużych struktur asocjacyjnych lepiej korzystać z kluczy.
1(identical? 'a 'a) ; czy te dwa symbole są tym samym obiektem?
2; => false ; nie są
3
4(= 'a 'a) ; czy te dwa symbole są równe?
5; => true ; tak, są
(identical? 'a 'a) ; czy te dwa symbole są tym samym obiektem?
; => false ; nie są
(= 'a 'a) ; czy te dwa symbole są równe?
; => true ; tak, są
Budowa symboli
Wewnętrznie symbole są obiektami składającymi się z:
-
etykiety tekstowej (nazwy), wyrażonej łańcuchem znakowym o wspomnianych wcześniej właściwościach;
-
opcjonalnego łańcucha znakowego oznaczającego przestrzeń nazw, do której powinny być przydzielone niektóre identyfikowane symbolami obiekty (jeżeli z przestrzeni nazw korzystają).
Sam symbol nie jest w momencie tworzenia umieszczany w żadnej mapie
reprezentującej przestrzeń nazw, ale można oznaczyć go w taki sposób, żeby
później skorzystały z tej informacji inne konstrukcje języka (np. obiekty typu
Var).
Symbole, które zawierają informację o przestrzeni nazw, nazywamy symbolami z dookreśloną przestrzenią nazw (ang. namespace-qualified symbols), czasem też można spotkać się z żargonowym określeniem symbole w pełni kwalifikowane (ang. fully-qualified symbols).
przestrzeń/nazwa
'inna/inna-nazwa
przestrzeń/nazwa
'inna/inna-nazwa
Symbole same nie przechowują odniesień do wartości, które z ich pomocą są identyfikowane. Ich użyteczność w tym zakresie polega na tym, że formy symbolowe są podczas przeliczania wyrażeń traktowane jak identyfikatory. Dochodzi wtedy do przeszukania różnych (w zależności od kontekstu) obszarów, w których mogą znajdować się odwzorowania symboli na wartości. Symbole w Clojure nie mogą być więc nazwane typem referencyjnym.
Użytkowanie symboli
Dzięki specjalnemu traktowaniu symboli przez czytnik możemy wyrażać je po prostu umieszczając ich nazwy w kodzie. W takiej formie (symbolowej) będą reprezentowały wartości, z którymi wcześniej je skojarzono. Jesteśmy również w stanie posługiwać się symbolami tak, jakby same były wartościami, korzystając z cytowania lub odpowiednich funkcji.
Formy symbolowe
Formy symbolowe powstają, gdy w odpowiednich miejscach kodu źródłowego pojawiają się niezacytowane napisy, które spełniają warunki potrzebne, aby czytnik uznał je za nazwy symboli.
Użycie:
symbol,przestrzeń-nazw/symbol.
Dokładniej rzecz ujmując, formy symbolowe mogą być użyte do identyfikowania:
- klas Javy (rozpoczynają się wtedy znakiem kropki),
- powiązań:
- zmiennych globalnych i dynamicznych (w przestrzeniach nazw);
- leksykalnych (na stosie):
- w forme specjalnej
let, - w parametrach funkcji.
- w forme specjalnej
Gdy tekst kodu źródłowego jest analizowany składniowo przez czytnik, symbole są
wykrywane na podstawie warunków, które muszą spełniać reprezentujące je napisy. Zaraz
po tym są tworzone ich pamięciowe reprezentacje w postaci obiektów typu
clojure.lang.Symbol. To tej postaci będzie dalej używał ewaluator, aby odnaleźć
wskazywane symbolami wartości. Algorytm jest następujący:
-
Jeżeli symbol ma dookreśloną przestrzeń nazw, to następuje próba poznania wartości, na którą wskazuje zmienna globalna powiązana z symbolem o takiej samej nazwie w podanej przestrzeni.
-
Jeżeli symbol zawiera określenie pakietu Javy, następuje próba odwołania się do klasy o nazwie takiej, jak nazwa symbolu.
-
Jeżeli nazwa symbolu jest taka sama, jak nazwa formy specjalnej, to zwracany jest jej obiekt.
-
Jeżeli w bieżącej przestrzeni nazw istnieje przyporządkowanie symbolu do klasy Javy, zwracany jest obiekt tej klasy.
-
Jeżeli mamy do czynienia z zasięgiem leksykalnym (w ciele funkcji lub w konstrukcji
letlub podobnej), przeszukiwany jest przypisany do danego wątku stos powiązań w celu znalezienia tam odwzorowania symbolicznej nazwy na obiekt umieszczony na stercie. -
W końcu dokonywane jest przeszukanie bieżącej przestrzeni nazw w celu znalezienia tam przyporządkowania symbolu o takiej samej nazwie do zmiennej globalnej i poznania aktualnej wartości wskazywanej przez tą zmienną.
Jeżeli po wykonaniu powyższych czynności nadal nie zostanie znalezione powiązanie
żadnego pamięciowego obiektu z symbolem o nazwie tożsamej z nazwą podanego, zgłoszony
zostanie wyjątek java.lang.RuntimeException z komunikatem Unable to resolve symbol.
Formy stałe symboli
Symbole w formach stałych są wartościami własnymi. Możemy z nich korzystać do reprezentowania dowolnych danych mających znaczenie w kontekście logiki przyjętej w aplikacji: nazywania elementów konfiguracji, sterowania przepływem, klasyfikowania innych danych itd.
Użycie:
'symbol,(quote symbol),(symbol nazwa-symbolu),(symbol nazwa-przestrzeni nazwa-symbolu).
Istnieją dwa sposoby tworzenia form stałych symboli: cytowanie i użycie funkcji
symbol.
Cytowanie polega na użyciu formy specjalnej quote lub skorzystaniu z apostrofu
poprzedzającego nazwę symbolu, który jest makrem czytnika rozwijanym do wywołania tej
formy. Pojedynczy, zacytowany z użyciem quote symbol w fazie parsowania stanie się
liściem abstrakcyjnego drzewa składniowego, który zostanie oznaczony jako
nieprzeznaczony do wartościowania. Gdy ewaluator będzie rekurencyjnie obliczał
wartości wyrażeń drzewa, dla takiego fragmentu zwróci po prostu obiekt symbolu bez
prób odnajdywania obiektów, które mogłyby być tym symbolem identyfikowane.
Funkcja symbol pozwala wytwarzać symbole wyrażone podanymi nazwami. Przyjmuje ona
jeden obowiązkowy argument, którym powinna być nazwa symbolu wyrażona łańcuchem
znakowym. Opcjonalnie możemy też przekazać jej jako pierwszy argument
wyrażoną w ten sam sposób nazwę przestrzeni nazw, jeżeli chcemy utworzyć symbol
z dookreśloną przestrzenią. W dwuargumentowej wersji nazwę symbolu musimy wtedy podać
jako drugi argument. Zwracaną wartością jest obiekt symbolu, z którego możemy
w programie korzystać tak, jak z każdej innej wartości.
Efektywnie skorzystanie z funkcji symbol i formy specjalnej quote pozwoli nam
uzyskać obiekt symbolu. Różnica między nimi polega na fazie przetwarzania programu,
w której dojdzie do wytworzenia tego obiektu. W przypadku cytowania obiekt powstanie
już w momencie analizy składniowej, a w przypadku użycia symbol w chwili powrotu
z funkcji.
1(symbol "abc") ; tworzenie symbolu abc
2(symbol "user" "abc") ; tworzenie symbolu abc z przestrzenią user
3(quote abc) ; cytowanie stwarza symbole dla odpwiednich nazw
4'abc ; lukier składniowy dla quote
(symbol "abc") ; tworzenie symbolu abc
(symbol "user" "abc") ; tworzenie symbolu abc z przestrzenią user
(quote abc) ; cytowanie stwarza symbole dla odpwiednich nazw
'abc ; lukier składniowy dla quote
Pamiętajmy, że dookreślenie przestrzeni nazw nie umieszcza symbolu w żadnej przestrzeni, lecz wpisuje weń po prostu odpowiednią informację, z której mogą korzystać potem mechanizmy czyniące użytek z przestrzeni.
Korzystanie z symboli w formach stałych nie różni się od używania innych wartości:
1(list 'chleb 'mleko 'ser) ; lista symboli
2(quote (chleb mleko ser)) ; zacytowana lista symboli
3'(chleb mleko ser) ; zacytowana lista symboli
(list 'chleb 'mleko 'ser) ; lista symboli
(quote (chleb mleko ser)) ; zacytowana lista symboli
'(chleb mleko ser) ; zacytowana lista symboli
Formy powiązaniowe symboli
Niezacytowane symbole znajdują również zastosowanie w wyrażaniu form powiązaniowych, tzn. podczas tworzenia powiązań (np. leksykalnych czy w parametrach funkcji). Mówimy wtedy o wyrażeniach powiązaniowych, do których zaliczamy:
- wektor powiązań – używany do tworzenia powiązań leksykalnych,
- wektor parametryczny – używany do obsługi argumentów funkcji.
Formy powiązaniowe znajdziemy również w definicjach zmiennych globalnych oraz funkcji.
1;; definicje zmiennych globalnych i funkcji:
2
3(def a 5) ; zmienna globalna powiązana z wartością
4(def a (fn [] (+ 2 2))) ; zmienna globalna powiązana z funkcją
5(defn a [] (+ 2 2)) ; zmienna globalna powiązana z funkcją
6
7;; wektory parametryczne:
8
9(fn [a b] (list a b)) ; argumenty funkcji anonimowej
10(defn f [a b] (list a b)) ; argumenty funkcji nazwanej
11
12;; wektory powiązań:
13
14(let [a 5] a) ; powiązanie leksykalne
15(binding [a 5] a) ; powiązanie dynamiczne
16(with-local-vars [a 5] @a) ; zmienna lokalna
;; definicje zmiennych globalnych i funkcji:
(def a 5) ; zmienna globalna powiązana z wartością
(def a (fn [] (+ 2 2))) ; zmienna globalna powiązana z funkcją
(defn a [] (+ 2 2)) ; zmienna globalna powiązana z funkcją
;; wektory parametryczne:
(fn [a b] (list a b)) ; argumenty funkcji anonimowej
(defn f [a b] (list a b)) ; argumenty funkcji nazwanej
;; wektory powiązań:
(let [a 5] a) ; powiązanie leksykalne
(binding [a 5] a) ; powiązanie dynamiczne
(with-local-vars [a 5] @a) ; zmienna lokalna
Tworzenie unikatowych symboli, gensym
Czasem zachodzi konieczność stworzenia symbolu, który będzie globalnie unikatowy,
tzn. jego nazwa będzie niepowtarzalna. Służy do tego funkcja gensym.
Użycie:
(gensym przedrostek?).
Funkcja gensym przyjmuje jeden opcjonalny argument, który powinien być łańcuchem
znakowym, a zwraca symbol. Jeżeli łańcucha nie podano, to jest generowany symbol
o unikatowej nazwie z przedrostkiem G__. Gdy podano argument, to jest on używany jako
przedrostek nazwy.
gensym
1;; całkowicie unikatowa nazwa
2
3(gensym)
4; => G__2862
5
6;; unikatowa nazwa z podanym przedrostkiem
7
8(gensym "siefca")
9; => siefca2865
;; całkowicie unikatowa nazwa
(gensym)
; => G__2862
;; unikatowa nazwa z podanym przedrostkiem
(gensym "siefca")
; => siefca2865
Testowanie typu, symbol?
Możemy sprawdzić, czy dany obiekt na pewno jest symbolem (formą stałą symbolu)
z użyciem predykatu symbol?.
Użycie:
(symbol? wartość).
Funkcja przyjmuje jeden argument, a zwraca wartość true (jeżeli podana
wartość jest symbolem) lub false (jeżeli podana wartość nie jest
symbolem).
symbol?
1(symbol? 'test) ; czy test jest symbolem?
2; => true ; tak, jest
3
4(symbol? test) ; czy wartość identyfikowana symbolem test jest symbolem?
5; => false ; nie, nie jest
(symbol? 'test) ; czy test jest symbolem?
; => true ; tak, jest
(symbol? test) ; czy wartość identyfikowana symbolem test jest symbolem?
; => false ; nie, nie jest
Testowanie kwalifikacji
Możemy sprawdzić, czy symbol zawiera przestrzeń nazw z użyciem predykatów:
(simple-symbol? wartość)– czy jest symbolem bez przestrzeni nazw,(qualified-symbol? wartość)– czy zawiera przestrzeń nazw.
simple-symbol? i qualified-symbol?
1(simple-symbol? 'test) ; czy test jest prostym symbolem?
2; => true ; tak, jest
3
4(qualified-symbol? 'x/test) ; czy x/test ma przestrzeń nazw?
5; => true ; tak, ma
(simple-symbol? 'test) ; czy test jest prostym symbolem?
; => true ; tak, jest
(qualified-symbol? 'x/test) ; czy x/test ma przestrzeń nazw?
; => true ; tak, ma
Symbole jako funkcje
Symbole mogą być używane jako funkcje. Są wtedy formami przeszukiwania kolekcji. Funkcje przeszukujące na bazie symboli przyjmują jeden obowiązkowy argument, którym powinna być mapa lub zbiór.
Użycie:
(symbol kolekcja wartość-domyślna?).
W podanej strukturze zostanie przeprowadzone wyszukanie elementu, którego kluczem
jest podany symbol, a jeżeli nie zostanie on odnaleziony, zwrócona będzie wartość
nil lub wartość podana jako drugi, opcjonalny argument.
W przypadku znalezienia elementu w mapie funkcja symbolowa zwraca wartość skojarzoną z tym symbolem, a w przypadku znalezienia elementu w zbiorze jego wartość.
1('a {'a 1, 'b 2} "brak") ; => 1
2('a {'x 1, 'b 2} "brak") ; => "brak"
3('a {'x 1, 'b 2}) ; => nil
4
5('a '{a 1, b 2} "brak") ; => 1
6('a '{x 1, b 2} "brak") ; => "brak"
7('a '{x 1, b 2}) ; => nil
8
9((quote a) '{a 1} "brak") ; => 1
10((quote a) '{x 1} "brak") ; => "brak"
11((quote a) '{x 1}) ; => nil
12
13('a #{'a 'b} "brak") ; => a
14('a #{'x 'b} "brak") ; => "brak"
15('a #{'x 'b}) ; => nil
16
17('a '#{a b} "brak") ; => a
18('a '#{x b} "brak") ; => "brak"
19('a '#{x b}) ; => nil
('a {'a 1, 'b 2} "brak") ; => 1
('a {'x 1, 'b 2} "brak") ; => "brak"
('a {'x 1, 'b 2}) ; => nil
('a '{a 1, b 2} "brak") ; => 1
('a '{x 1, b 2} "brak") ; => "brak"
('a '{x 1, b 2}) ; => nil
((quote a) '{a 1} "brak") ; => 1
((quote a) '{x 1} "brak") ; => "brak"
((quote a) '{x 1}) ; => nil
('a #{'a 'b} "brak") ; => a
('a #{'x 'b} "brak") ; => "brak"
('a #{'x 'b}) ; => nil
('a '#{a b} "brak") ; => a
('a '#{x b} "brak") ; => "brak"
('a '#{x b}) ; => nil
Metadane
Symbole (ale również kolekcje) mogą być opcjonalnie wyposażone w metadane (ang. metadata). Są to informacje pozwalające dokonywać pewnych adnotacji, czyli kojarzyć z obiektami dodatkowe, pomocnicze wartości, które mogą być potem wykorzystane do sterowania zachowaniem programu.
Niektóre metadane są rozpoznawane i użytkowane przez wbudowane mechanizmy
języka. Przykładem mogą być tu zmienne globalne, których właściwościami możemy
sterować z użyciem metadanych skojarzonych z symbolami używanymi do nadania im
nazw. Obiekty typu Var mogą być wyposażone w następujące metadane:
- łańcuchy dokumentacji dodawane do funkcji (klucz
:doc); - flaga oznaczająca tzw. zasięg dynamiczny (
:dynamic); - flaga sterująca widocznością (klucz
:private); - informacje o pliku, z którego pochodzi funkcja (klucz
:file).
Metadanych o samodzielnie nazwanych kluczach, które nie kolidują z wbudowanymi, programista może używać do własnych celów.
Metadane przechowywane są w mapach, a reprezentowane w postaci par klucz–wartość. Kluczami mogą być dowolne obiekty, lecz na zasadzie konwencji stosuje się najczęściej słowa kluczowe.
Metadane nie są składnikami wartości obiektów, do których je dołączono. Porównując dwa tożsame pod względem wartości obiekty, które mają różne metadane, uzyskamy logiczną prawdę.
Podczas tworzenia zmiennych globalnych, które identyfikowane
są symbolami, metadane umieszczone w tych ostatnich są kopiowane do obiektów typu
Var.
Odczytywanie metadanych, meta
Aby pobrać metadane symbolu, należy skorzystać z funkcji meta.
Użycie:
(meta symbol).
Funkcja meta przyjmuje symbol, a zwraca mapę metadanych, jeżeli symbolowi je
przypisano lub nil w przeciwnym razie.
meta
1;; tworzenie zmiennej globalnej (referencji do wartości 5)
2
3(def x 5)
4
5;; brak metadanych dla wartości 5 (wskazywanej symbolem)
6
7(meta x)
8; => nil
9
10;; brak metadanych dla symbolu x
11
12(meta 'x)
13; => nil
14
15;; są metadane dla zmiennej globalnej
16
17(meta #'x)
18; => { :ns #<Namespace user>,
19; => :name x, :file "NO_SOURCE_PATH",
20; => :column 1,
21; => :line 1 }
22
23;; wyrażenie metadanowe, są metadane
24
25(meta '^:testowa y)
26; => {:testowa true}
;; tworzenie zmiennej globalnej (referencji do wartości 5)
(def x 5)
;; brak metadanych dla wartości 5 (wskazywanej symbolem)
(meta x)
; => nil
;; brak metadanych dla symbolu x
(meta 'x)
; => nil
;; są metadane dla zmiennej globalnej
(meta #'x)
; => { :ns #<Namespace user>,
; => :name x, :file "NO_SOURCE_PATH",
; => :column 1,
; => :line 1 }
;; wyrażenie metadanowe, są metadane
(meta '^:testowa y)
; => {:testowa true}
Dodawanie metadanych, with-meta
Aby ustawić własne metadane symbolu, można użyć funkcji with-meta.
Użycie:
(with-meta symbol metadane).
Jako pierwszy argument należy funkcji with-meta przekazać symbol, a jako drugi
mapę zawierającą klucze i przypisane do nich wartości metadanych, które
powinny być przypisane symbolowi.
with-meta
(with-meta 'nazwa {:klucz "wartość"})
; => nazwa
(with-meta 'nazwa {:klucz "wartość"})
; => nazwa
Warto mieć na względzie, że tak ustawione metadane będą obecne wyłącznie w symbolu zwracanym przez to konkretne wyrażenie i nie zostaną dołączone do symbolu, na którym operujemy, ponieważ podobnie jak inne wartości jest on niemutowalny.
Istotną cechą obsługi symboli opatrzonych metadanymi jest to, że niektóre identyfikowane nimi obiekty kopiują je podczas tworzenia powiązania. Przykładem takiego zachowania są wspomniane zmienne globalne.
Aby nie popaść w zakłopotanie, należy pamiętać o rozróżnieniu metadanych symboli identyfikujących obiekty od metadanych tych obiektów, a nawet od metadanych obiektów wskazywanych przez obiekty (w przypadku typów referencyjnych, które będą dokładniej omówione w dalszych rozdziałach).
Całkiem możliwą i powszechną sytuacją jest, że symbol nie jest wyposażony w metadane, ale już identyfikowany nim obiekt ma je przypisane.
Wyrażenia metadanowe
W Clojure istnieje również makro czytnika, które wywołuje with-meta na wartości
umieszczonej po jego prawej stronie.
Użycie:
^:flaga wartość,'^:flaga wartość,^{ :klucz wartość … } wartość,'^{ :klucz wartość … } wartość.
Skorzystanie z niego polega na użyciu znaku akcentu przeciągłego
(ang. circumflex), po którym w nawiasach klamrowych następują pary (klucz i wartość)
określające metadane. Jeżeli metadana wyraża wartość logiczną true (czyli
jest flagą), to klamry i wartość można pominąć, jednak należy pamiętać o dwukropku
przed nazwą klucza.
Opcjonalnie zamiast pojedynczego klucza można podać łańcuch znakowy – zostanie wtedy
ustawiony klucz :tag z wartością tego łańcucha. W przypadku metadanych zgrupowanych
w nawiasach klamrowych kluczami mogą być łańcuchy znakowe, symbole lub słowa
kluczowe.
1;; tworzenie zmiennej globalnej (referencji do wartości 5)
2;; z ustawioną w symbolu metadaną wyrażającą ustawioną flagę
3
4(def ^:testowa x 5)
5; => #'user/x
6
7(meta #'x)
8; => { :ns #<Namespace user>,
9; => :name x, :file "NO_SOURCE_PATH",
10; => :column 1,
11; => :line 1,
12; => :testowa true}
13
14(def ^{ :testowa "napis", :druga 123 } x 5)
15; => #'user/x
16
17(meta #'x)
18; => { :ns #<Namespace user>,
19; => :name x, :file "NO_SOURCE_PATH",
20; => :column 1,
21; => :line 1,
22; => :testowa "napis",
23; => :druga 123 }
;; tworzenie zmiennej globalnej (referencji do wartości 5)
;; z ustawioną w symbolu metadaną wyrażającą ustawioną flagę
(def ^:testowa x 5)
; => #'user/x
(meta #'x)
; => { :ns #<Namespace user>,
; => :name x, :file "NO_SOURCE_PATH",
; => :column 1,
; => :line 1,
; => :testowa true}
(def ^{ :testowa "napis", :druga 123 } x 5)
; => #'user/x
(meta #'x)
; => { :ns #<Namespace user>,
; => :name x, :file "NO_SOURCE_PATH",
; => :column 1,
; => :line 1,
; => :testowa "napis",
; => :druga 123 }
Uwaga: W przypadku form stałych symboli, powstałych w wyniku ich zacytowania, makro czytnika należy umieścić po znaczniku cytowania, a przed nazwą symbolu, aby ustawianie metadanych było skuteczne.
Zobacz także:
- http://clojure.org/data_structures#Data%20Structures-Symbols
- http://clojure.org/namespaces
- http://clojure.org/metadata
Klucze
Klucze (ang. keys) lub słowa kluczowe (ang. keywords) to w Clojure typ danych przypominający symbole. Podobnie jak one, klucze służą do identyfikowania innych danych, jednak gdy nie zostały umieszczone na pierwszej pozycji listowego S-wyrażenia są formą stałą (wyrażają wartości własne). Klucze nie są w sposób specjalny traktowane przez czytnik i nie identyfikują innych danych w sposób automatyczny.
Słów kluczowych często używa się do etykietowania pewnych opcji lub flag, a także jako kluczy w asocjacyjnych strukturach danych. Dwa klucze o takiej samej nazwie są tożsame.
Internalizacja kluczy
Warto pamiętać, że w przeciwieństwie do symboli klucze są internalizowane, tzn. dwa tak samo nazwane klucze będą wewnętrznie reprezentowane przez ten sam obiekt pamięciowy.
1(identical? :a :a) ; czy te dwa klucze są tym samym obiektem?
2; => true ; tak są
3
4(= :a :a) ; czy te dwa klucze są równe?
5; => true ; tak, są
(identical? :a :a) ; czy te dwa klucze są tym samym obiektem?
; => true ; tak są
(= :a :a) ; czy te dwa klucze są równe?
; => true ; tak, są
Powyższej zademonstrowana cecha pozwala nam używać kluczy na przykład jako indeksów w strukturach asocjacyjnych. Po pierwsze mamy pewność odnośnie testów porównywania, a po drugie wiemy, że w pamięci nie powstanie zbyt wiele obiektów zawierających tekstowy identyfikator – będziemy mieli do czynienia z automatyczną kompresją słownikową dla takich samych kluczy.
Porównywanie referencyjne kluczy z użyciem identical? jest szybkie i zachęca do
użycia w bardzo często używanych ścieżkach, obiecując zwiększoną wydajność przy
milionach wywołań. Istnieją jednak rzadkie przypadki brzegowe, w których dwa tak samo
nazwane słowa kluczowe nie będą tym samym obiektem. Po pierwsze możemy mieć
specyficznie skonfigurowane środowisko, a po drugie konkretna implementacja języka
Clojure (np. nie działająca na JVM) może nie gwarantować internalizowania.
Gdy na przykład skorzystamy z kontenera modułowego z izolacją classloaderów, czyli
implementacji standardu modularyzacji Open Services Gateway initiative (skr. OSGi),
będziemy mogli mieć więcej niż jeden classloader w tym samym środowisku
uruchomieniowym JVM, z których każdy może załadować odrębne clojure.jar (gdy takie
dostarczono). W efekcie mechanizmy internalizowania kluczy, a nawet porównywania klas
obiektów mogą działać równolegle w więcej niż jednym oddzielnym wątku i używać więcej
niż jednej tabeli mapującej nazwy. W takich przypadkach identical? nie będzie
naszym jedynym problemem, bo nawet porównywanie przestanie dawać oczekiwane rezultaty
dla wybranych typów obiektów.
Z kolei na bardziej ogólnym poziomie, czyli w przypadku Clojure poza JVM, możemy mieć
różną implementację obsługi kluczy. Na przykład w języku ClojureScript dwa słowa
kluczowe o takich samych nazwach nie są identyczne, chociaż ich wartości są
równe. Wtedy identical? zwróci false, ale = zwróci true.
Jeżeli mamy pewność, że używane przez nas środowisko zawsze posługuje się
implementacją języka, która gwarantuje referencyjną równość słów kluczowych o tych
samych nazwach, możemy używać identical? i cieszyć się zwiększoną wydajnością. Gdy
jednak jesteśmy autorami kodu, lecz nie znamy warunków jego uruchamiania, lub też nie
mamy na nie wpływu (np. w przypadku bibliotek programistycznych), nie powinniśmy
polegać na tym mechanizmie. Możemy wtedy zastosować optymalizację w stylu:
(def a :raz)
(def b :raz)
(or (identical? a b) (= a b)) ; => true
(def a :raz)
(def b :raz)
(or (identical? a b) (= a b)) ; => true
W powyższym przykładzie korzystamy z szybkiej gałęzi tam, gdzie to możliwe (> 99,99% przypadków), ale w razie negatywnego rezultatu realizowane jest dodatkowe porównywanie wartości.
Przestrzenie nazw kluczy
Słowa kluczowe mogą opcjonalnie zawierać informacje o przypisaniu do konkretnej przestrzeni nazw. Możemy wtedy mówić o słowach kluczowych z dookreśloną przestrzenią nazw (ang. namespace-qualified keywords).
Z przestrzeni nazw warto korzystać wtedy, gdy pisany przez nas kod może być użytkowany przez innych, a tworzenie kluczy mogłoby zaburzyć pracę ich programów. Jeżeli na przykład sprawdzane jest samo istnienie obiektu klucza (utworzonego przez przynajmniej jednokrotne jego użycie) i zależy od tego logika działania programu, wtedy tworząc bibliotekę korzystającą z kluczy, a której użyje autor takiej aplikacji, potencjalnie moglibyśmy wpłynąć na jej poprawną pracę.
W zapisie literalnym słowa kluczowe mogą zawierać znak ukośnika, który posłuży do oddzielenia części reprezentującej przestrzeń nazw od właściwej nazwy słowa kluczowego.
Użytkowanie kluczy
Tworzenie kluczy, keyword
Słowa kluczowe możemy tworzyć korzystając z funkcji keyword.
Użycie:
(keyword przestrzeń? klucz).
W wariancie jednoargumentowym funkcja przyjmuje łańcuch znakowy określający nazwę klucza, a w wariancie dwuargumentowym dwa łańcuchy znakowe: nazwę przestrzeni nazw i nazwę klucza.
Funkcja zwraca obiekt słowa kluczowego, który jest internalizowany (jeżeli nie istniał, jest tworzony, a jeżeli już istniał, zwracana jest jego instancja).
keyword
(keyword "klucz") ; => :klucz
(keyword "przestrzeń" "a") ; => :przestrzeń/a
(keyword "klucz") ; => :klucz
(keyword "przestrzeń" "a") ; => :przestrzeń/a
Klucze literalne
Tworzyć słowa kluczowe możemy z wykorzystaniem literału kluczowego w postaci zapisu z wiodącym dwukropkiem.
Użycie:
:klucz,:przestrzeń/klucz,::klucz,::przestrzeń/klucz.
Przed właściwą nazwą klucza możemy umieścić nazwę przestrzeni nazw oddzieloną znakiem ukośnika. Gdy literał rozpoczęto znakiem pojedynczego dwukropka, to podawana przestrzeń nazw nie musi być zdefiniowana; możemy więc podać dowolny ciąg znaków.
Dwa dwukropki przy nazwie zawierającej znak ukośnika będą oznaczały, że życzymy sobie, aby tworzone słowo kluczowe było poddane procesowi rozpoznawania przestrzeni nazw określonej aliasem w przestrzeni bieżącej. Utworzony klucz będzie miał dookreśloną przestrzeń nazw ustawioną na przestrzeń docelową, wskazywaną aliasem.
Szczególną sytuacją jest literał słowa kluczowego, który poprzedzono dwoma
dwukropkami bez podawania przestrzeni nazw. Przestrzeń zostanie ustawiona zgodnie
z wartością wskazywaną przez specjalną zmienną dynamiczną *ns*, która oznacza
bieżącą przestrzeń nazw.
1:klucz ; => :klucz
2:przestrzeń/klucz ; => :przestrzeń/klucz
3
4(ns user) ; bieżąca przestrzeń nazw: user
5::klucz ; => :user/klucz
6::user/klucz ; => :user/klucz
7
8(ns siup) ; bieżąca przestrzeń nazw: siup
9::klucz ; => :siup/klucz
10
11;; importowanie powiązań z przestrzeni nazw clojure.string
12;; do przestrzeni bieżącej z użyciem aliasu s
13
14(require '[clojure.string :as s])
15
16::s/klucz ; => :clojure.string/klucz
:klucz ; => :klucz
:przestrzeń/klucz ; => :przestrzeń/klucz
(ns user) ; bieżąca przestrzeń nazw: user
::klucz ; => :user/klucz
::user/klucz ; => :user/klucz
(ns siup) ; bieżąca przestrzeń nazw: siup
::klucz ; => :siup/klucz
;; importowanie powiązań z przestrzeni nazw clojure.string
;; do przestrzeni bieżącej z użyciem aliasu s
(require '[clojure.string :as s])
::s/klucz ; => :clojure.string/klucz
Sprawdzane typu, keyword?
Sprawdzanie czy obiekt jest kluczem jest możliwe z wykorzystaniem z predykatu
keyword?.
Użycie:
(keyword? wartość).
Jeżeli podana wartość jest słowem kluczowym, zwrócona będzie wartość true,
a w przeciwnym razie false.
keyword?
(keyword? "klucz") ; => false (nie jest)
(keyword? :klucz) ; => true (jest)
(keyword? "klucz") ; => false (nie jest)
(keyword? :klucz) ; => true (jest)
Testowanie kwalifikacji
Możemy sprawdzić, czy słowo kluczowe zawiera przestrzeń nazw wykorzystując predykaty:
(simple-keyword? wartość)– czy jest kluczem bez przestrzeni nazw,(qualified-keyword? wartość)– czy zawiera przestrzeń nazw.
simple-keyword? i qualified-keyword?
1(simple-keyword? :test) ; czy test jest prostym słowem kluczowym?
2; => true ; tak, jest
3
4(qualified-keyword? ::x/test) ; czy x/test ma przestrzeń nazw?
5; => true ; tak, ma
(simple-keyword? :test) ; czy test jest prostym słowem kluczowym?
; => true ; tak, jest
(qualified-keyword? ::x/test) ; czy x/test ma przestrzeń nazw?
; => true ; tak, ma
Wyszukiwanie kluczy, find-keyword
Możemy sprawdzić, czy dane słowo kluczowe zostało internalizowane, posługując się
funkcją find-keyword.
Użycie:
(find-keyword klucz).
Funkcja pozwala odszukać klucz, który wcześniej utworzono, np. przez odwołanie się do niego.
find-keyword
1(find-keyword "słowo") ; istnieje?
2; => nil ; nie
3
4:słowo ; pierwsze użycie internalizuje klucz
5(find-keyword "słowo") ; istnieje?
6; => :słowo ; tak
(find-keyword "słowo") ; istnieje?
; => nil ; nie
:słowo ; pierwsze użycie internalizuje klucz
(find-keyword "słowo") ; istnieje?
; => :słowo ; tak
Można również dokonywać wyszukiwania kluczy z dookreślonymi przestrzeniami nazw:
find-keyword z przestrzeniami nazw
1(find-keyword "przestrzeń" "słowo") ; istnieje?
2; => nil ; nie
3
4:przestrzeń/słowo ; pierwsze użycie internalizuje klucz
5(find-keyword "przestrzeń" "słowo") ; istnieje?
6; => :przestrzeń/słowo ; tak
(find-keyword "przestrzeń" "słowo") ; istnieje?
; => nil ; nie
:przestrzeń/słowo ; pierwsze użycie internalizuje klucz
(find-keyword "przestrzeń" "słowo") ; istnieje?
; => :przestrzeń/słowo ; tak
Klucze jako funkcje
Słowa kluczowe mogą być używane jako funkcje. Przyjmują wtedy jeden obowiązkowy argument, którym powinna być mapa lub zbiór.
Użycie:
(klucz kolekcja wartość-domyślna?).
W podanej strukturze zostanie przeprowadzone wyszukanie elementu, którego kluczem
jest podane słowo kluczowe, a jeżeli nie zostanie on odnaleziony, zwrócona będzie
wartość nil lub wartość podana jako drugi, opcjonalny argument.
W przypadku znalezienia elementu w mapie funkcja kluczowa zwraca wartość skojarzoną z tym kluczem, a w przypadku znalezienia elementu w zbiorze jego wartość.
1(:a {:a 1, :b 2} "brak") ; => 1
2(:a {:x 1, :b 2} "brak") ; => "brak"
3(:a {:x 1, :b 2}) ; => nil
4(:a #{:a :b} "brak") ; => :a
5(:a #{:x :b} "brak") ; => "brak"
6(:a #{:x :b}) ; => nil
(:a {:a 1, :b 2} "brak") ; => 1
(:a {:x 1, :b 2} "brak") ; => "brak"
(:a {:x 1, :b 2}) ; => nil
(:a #{:a :b} "brak") ; => :a
(:a #{:x :b} "brak") ; => "brak"
(:a #{:x :b}) ; => nil
Funkcje obsługi identyfikatorów
Od wersji 1.9 język Clojure wyposażono w kilka funkcji, które pozwalają sprawdzać właściwości identyfikatorów (symboli i kluczy).
Testowanie identyfikatorów
Możemy sprawdzić, czy dany obiekt jest identyfikatorem (symbolem lub kluczem), a także jakie ma cechy, korzystając z następujących predykatów:
(ident? wartość)– czy jest identyfikatorem,(simple-ident? wartość)– czy jest identyfikatorem bez przestrzeni nazw,(qualified-ident? wartość)– czy jest identyfikatorem z przestrzenią nazw.
1(ident? 'test) ; czy test jest identyfikatorem?
2; => true ; tak, jest
3
4(simple-ident? 'test) ; czy test jest prostym identyfikatorem?
5; => true ; tak, jest
6
7(qualified-ident? 'x/test) ; czy x/test ma przestrzeń nazw?
8; => true ; tak, ma
9
10(ident? :test) ; czy :test jest identyfikatorem?
11; => true ; tak, jest
12
13(simple-ident? :test) ; czy :test jest prostym identyfikatorem?
14; => true ; tak, jest
15
16(qualified-ident? :x/test) ; czy :x/test ma przestrzeń nazw?
17; => true ; tak, ma
(ident? 'test) ; czy test jest identyfikatorem?
; => true ; tak, jest
(simple-ident? 'test) ; czy test jest prostym identyfikatorem?
; => true ; tak, jest
(qualified-ident? 'x/test) ; czy x/test ma przestrzeń nazw?
; => true ; tak, ma
(ident? :test) ; czy :test jest identyfikatorem?
; => true ; tak, jest
(simple-ident? :test) ; czy :test jest prostym identyfikatorem?
; => true ; tak, jest
(qualified-ident? :x/test) ; czy :x/test ma przestrzeń nazw?
; => true ; tak, ma
Wartości logiczne
Obsługa wartości logiki dwuwartościowej polega na użyciu typu Boolean
(java.lang.Boolean), którego obiekty mogą wyrażać wartości true lub false. Te
dwa symbole w formach symbolowych wartościowane są do obiektów typu Boolean,
oznaczających odpowiednio logiczną prawdę i logiczny fałsz.
Obiekty typu Boolean, mimo że wyrażają tylko dwa stany, zajmują w pamięci co najmniej 16 bajtów (z powodu nagłówka obiektu JVM). Typ prymitywny boolean zajmuje 1 bajt.
Użytkowanie wartości logicznych
Wartości logiczne są na zasadzie konwencji zwracane przez funkcje, których nazwy zakończone są pytajnikiem. Funkcje takie nazywamy predykatami (ang. predicates).
Poza tym istnieją funkcje specyficzne dla wartości logicznych, które pozwalają tworzyć je, rzutować i sprawdzać.
Wykonywanie warunkowe
W języku Clojure formy specjalne odpowiedzialne za warunkowe wykonywanie obliczeń
(np. if) traktują logiczny fałsz (wyrażony atomem false) i wartość pustą
(wyrażoną atomem nil) tak samo. Wewnętrznie dokonują one rzutowania danych
różnych typów do wartości logicznych (podobnie jak opisana niżej funkcja
boolean).
1(if true 'tak 'nie) ; => tak
2(if false 'tak 'nie) ; => nie
3(if nil 'tak 'nie) ; => nie
4(if 0 'tak 'nie) ; => tak
(if true 'tak 'nie) ; => tak
(if false 'tak 'nie) ; => nie
(if nil 'tak 'nie) ; => nie
(if 0 'tak 'nie) ; => tak
Tworzenie wartości logicznych, boolean
Wartości logiczne można tworzyć nie tylko przez umieszczanie literalnie wyrażonych
wartości true lub false, ale także z wykorzystaniem funkcji boolean.
Użycie:
(boolean wartość).
Funkcja przyjmuje wartość dowolnego typu i dokonuje rzutowania (ang. casting) do
true lub false. Zasada jest taka, że zwracaną wartością jest true, chyba że
jako argument podano nil lub false.
boolean
1(boolean nil) ; => false
2(boolean false) ; => false
3(boolean true) ; => true
4(boolean 123) ; => true
(boolean nil) ; => false
(boolean false) ; => false
(boolean true) ; => true
(boolean 123) ; => true
Testowanie typu, boolean?
Sprawdzania czy podany argument jest wartością logiczną można dokonać
z wykorzystaniem funkcji boolean?.
Użycie:
(boolean? wartość).
Jeżeli pierwszym argumentem funkcji będzie wartość logiczna (true lub false),
zwrócona zostanie wartość true, a w przeciwnym razie wartość false.
boolean?
1(boolean? true) ; => true
2(boolean? false) ; => true
3(boolean? nil) ; => false
4(boolean? 123) ; => false
(boolean? true) ; => true
(boolean? false) ; => true
(boolean? nil) ; => false
(boolean? 123) ; => false
Badanie wartości logicznych, true? i false?
Funkcje true? i false? są predykatami, które sprawdzają czy podane jako argument
wartości wyrażają logiczną prawdę lub logiczny fałsz.
Użycie:
(true? wartość),(false? wartość).
Funkcja true? zwróci true, gdy podana wartość jest równa true, a funkcja
false? zwróci true, gdy podana wartość jest równa false.
true? i false?
1(true? true) ; => true
2(true? false) ; => false
3(true? nil) ; => false
4(true? 5) ; => false
5(false? nil) ; => false
6(false? false) ; => true
(true? true) ; => true
(true? false) ; => false
(true? nil) ; => false
(true? 5) ; => false
(false? nil) ; => false
(false? false) ; => true
Testowanie wartościowości, some?
Predykat some? (dodany w Clojure 1.6) sprawdza, czy podany argument jest
wartościowy (tzn. czy nie jest wartością nil).
Użycie:
(some? wartość),
Jeżeli podana wartość nie jest wartością nil, zwracana jest wartość true,
a w przeciwnym razie false.
some?
1(some? nil) ; => false
2(some? true) ; => true
3(some? false) ; => true
4(some? 1) ; => true
5(some? ()) ; => true
(some? nil) ; => false
(some? true) ; => true
(some? false) ; => true
(some? 1) ; => true
(some? ()) ; => true
Testowanie bezwartościowości, nil?
Predykat nil? działa przeciwnie do some? i pozwala sprawdzać, czy podana wartość
jest wartością nil.
Użycie:
(nil? wartość).
Funkcja przyjmuje jeden argument i zwraca true, gdy jego wartość jest równa
nil.
nil?
1(nil? nil) ; => true
2(nil? true) ; => false
3(nil? false) ; => false
4(nil? 1) ; => false
5(nil? ()) ; => false
(nil? nil) ; => true
(nil? true) ; => false
(nil? false) ; => false
(nil? 1) ; => false
(nil? ()) ; => false
Odwracanie wartości logicznej, not
Funkcja not pozwala odwrócić wartość logiczną.
Użycie:
(not wartość).
Funkcja przyjmuje jeden argument i zwraca wartość true, jeżeli wartością tego
argumentu jest false lub nil. W przeciwnych przypadkach zwraca false.
not
1(not nil) ; => true
2(not false) ; => true
3(not true) ; => false
4(not 0) ; => false
5(not 1) ; => false
(not nil) ; => true
(not false) ; => true
(not true) ; => false
(not 0) ; => false
(not 1) ; => false
Zawsze prawda, any?
Funkcja any? zwraca logiczną prawdę dla każdej wartości argumentu.
Użycie:
(any? wartość).
Funkcja przyjmuje jeden argument i zwraca wartość true.
any?
1(any? nil) ; => true
2(any? false) ; => true
3(any? true) ; => true
4(any? 0) ; => true
5(any? 1) ; => true
(any? nil) ; => true
(any? false) ; => true
(any? true) ; => true
(any? 0) ; => true
(any? 1) ; => true
Iloczyn logiczny, and
Makro and służy do sterowania wykonywaniem się programu, pozwalając na
wyrażanie iloczynu logicznego.
Użycie:
(and & wyrażenie…).
Makro oblicza wartości kolejnych wyrażeń podanych jako jego argumenty (w porządku
występowania) dopóki ich wartością jest logiczna prawda (nie wartość false
i nie nil).
Zwracaną wartością jest wartość ostatnio podanego wyrażenia albo false lub nil,
jeżeli któreś z wyrażeń taką wartość zwróciło i przerwano przetwarzanie. Gdy nie
podano żadnych argumentów, zwracana jest wartość true.
and
1(and true false) ; => false
2(and false true) ; => false
3(and false false) ; => false
4(and true true) ; => true
(and true false) ; => false
(and false true) ; => false
(and false false) ; => false
(and true true) ; => true
Suma logiczna, or
Makro or służy do sterowania wykonywaniem się programu, pozwalając na
wyrażanie sumy logicznej.
Użycie:
(or & wyrażenie…).
Makro oblicza wartości kolejnych wyrażeń podanych jako jego argumenty
(w kolejności występowania) do momentu, aż wartością któregoś będzie
logiczna prawda (nie wartość false i nie nil).
Zwracaną wartością jest wartość ostatnio przetwarzanego wyrażenia. Gdy nie
podamy argumentów, makro or zwraca wartość nil.
or
1(or true false) ; => true
2(or false false) ; => false
3(or false true) ; => true
4(or true true) ; => true
(or true false) ; => true
(or false false) ; => false
(or false true) ; => true
(or true true) ; => true
Funkcjonały logiczne
W Clojure istnieją wbudowane funkcje wyższego rzędu, które pomagają operować na wartościach logicznych zwracanych przez inne funkcje lub posługują się predykatami podanymi jako logiczne operatory. Zostaną one dokładniej omówione w późniejszych rozdziałach.
Działania na predykatach:
complement– odwracanie wartości predykatu,fnil– wymuszanie wartościowości,some-fn– pierwszy argument spełniający jedno z kryteriów,every-pred– pierwszy argument spełniający wszystkie kryteria.
Pozostałe operacje:
filter– filtrowanie elementów sekwencji,filterv– filtrowanie elementów sekwencji,remove– usuwanie elementów sekwencji,drop-while– częściowe usuwanie elementów,take-while– częściowe wybieranie elementów,group-by– grupowanie elementów sekwencji,tree-seq– sekwencyjny dostęp do zagnieżdżonych map,every?– test prawdy dla każdego elementu sekwencji,not-every?– odwrócony test prawdy dla każdego elementu sekwencji,not-any?– odwrócony test prawdy dla dowolnego elementu sekwencji,some– pierwszy element sekwencji spełniający kryterium,clojure.set/select– tworzenie podzbioru.
Liczby
Wyrażać wartości liczbowe można w Clojure na wiele sposobów, korzystając na przykład z literałów liczbowych, które tworzą atomowe S-wyrażenia będące formami stałymi.
Numeryczne typy danych
Liczby w Clojure obsługiwane są przez wszystkie numeryczne typy danych obecne w Javie, a dodatkowo przez dwa dodatkowe typy, które są specyficzne dla tego języka. Niektóre z typów można wyrażać, posługując się literałami liczbowymi, inne wymagają podania odpowiedniej funkcji, która zwraca egzemplarz klasy odpowiedzialnej za ich obsługę.
-
Byte:
-
Short:
-
Integer:
-
Ratio:
-
Long:
-
BigInt:
-
BigInteger:
-
BigDecimal:
-
Float:
-
Double:
- klasa:
java.lang.Double, - zakres: od 2-1074 do 21024-2971,
- tworzenie:
(double wartość), - literały:
2.0-1.2e-5.
- klasa:
W przypadku typów o takich samych lub podobnych właściwościach, które są zarówno
wbudowanymi typami Javy, jak i typami języka Clojure (przestrzeń clojure.lang),
warto korzystać z tych drugich z uwagi na optymalizacje wydajnościowe.
Operatory arytmetyczne
Operatory arytmetyczne to funkcje, które pozwalają przeprowadzać podstawowe operacje rachunkowe na typach numerycznych.
Użycie:
-
operatory wieloargumentowe:
(+ & składnik…)– suma,(- odjemna & odjemnik…)– różnica,(* & czynnik…)– iloczyn,(/ dzielna & dzielnik…)– iloraz,(min wartość & wartość…)– minimum,(max wartość & wartość…)– maksimum;
-
operatory dwuargumentowe:
(quot dzielna dzielnik)– iloraz z dzielenia z resztą,(rem dzielna dzielnik)– reszta z dzielenia (może być ujemna),(mod dzielna dzielnik)– reszta z dzielenia (mod. Gaussa, znak wyniku zależy od znaku dzielnika);
-
operatory jednoargumentowe:
(inc wartość)– zwiększenie o jeden,(dec wartość)– zmniejszenie o jeden.
Operatory dla dużych liczb
Niektóre operacje mogą prowadzić do wystąpienia błędu przekroczenia zakresu
zmiennej całkowitej (ang. integer overflow). Wynika to z użycia w operacjach
arytmetycznych liczb całkowitych, tzn. obiektów typu java.lang.Long.
Z przekroczeniem zakresu mamy do czynienia, gdy dana operacja (np. sumowania czy
mnożenia) doprowadziłaby do uzyskania wartości większej niż obsługiwana przez ten typ
danych. Aby obsługiwać takie przypadki, w Clojure mamy do czynienia z dodatkowymi
operatorami, które w razie potrzeby dokonują odpowiedniego rzutowania do wartości
wyrażanych typami o szerszych zakresach. Funkcje te różnią się od swych regularnych
odpowiedników symbolicznymi nazwami – mają na końcu dodany znak apostrofu.
Użycie:
-
operatory wieloargumentowe:
(+' & składnik…)– suma,(*' & czynnik…)– iloczyn;
-
operatory jednoargumentowe:
(inc' wartość)– zwiększenie o jeden,(dec' wartość)– zmniejszenie o jeden.
Operatory bez kontroli przepełnień
Język Clojure w czasie uruchamiania dokonuje sprawdzania, czy podczas wykonywania pewnych operacji nie dojdzie do przepełnień (ang. overflows) lub niedomiarów (ang. underflows). Istnieją jednak warianty operatorów przeznaczone dla typu całkowitego (Integer), które pomijają te testy.
Użycie:
-
dwuargumentowe:
(unchecked-add-int składnik-1 składnik-2)– suma,(unchecked-subtract-int odjemna odjemnik)– różnica,(unchecked-multiply-int czynnik-1 czynnik-2)– iloczyn,(unchecked-divide-int dzielna dzielnik)– iloraz,(unchecked-remainder-int dzielna dzielnik)– reszta;
-
jednoargumentowe:
(unchecked-negate-int wartość)– zmiana znaku,(unchecked-inc-int wartość)– zwiększenie o 1,(unchecked-dec-int wartość)– zmniejszenie o 1.
Dynamiczna zmienna specjalna o nazwie *unchecked-math* pozwala
zmienić zachowanie wszystkich konwencjonalnych operacji arytmetycznych w taki sposób,
że testy kontroli przepełnień nie będą przeprowadzane.
Operatory porównania
Użycie:
(= wartość & wartość…)– równe,(== wartość & wartość…)– równe numerycznie,(not= wartość & wartość…)– nierówne,(< wartość & wartość…)– mniejsze,(> wartość & wartość…)– większe,(<= wartość & wartość…)– mniejsze lub równe,(>= wartość & wartość…)– większe lub równe,(compare wartość wartość )– porównuje wartości lub elementy kolekcji.
Zobacz także:
- „Komparator domyślny, compare”, rozdział XI.
Rzutowanie typów numerycznych
Rzutowanie do typów numerycznych możliwe jest z zastosowaniem funkcji podanych wcześniej, które służą też do tworzenia wartości liczbowych.
Użycie:
(byte wartość),(short wartość),(int wartość),(long wartość),(float wartość),(double wartość),(bigdec wartość),(bigint wartość),(num wartość),(rationalize wartość),(biginteger wartość).
Predykaty typów numerycznych
Używając predykatów, można testować różne cechy wartości numerycznych.
Użycie:
(zero? wartość)– czy wartość jest zerowa,(pos? wartość)– czy wartość jest dodatnia,(neg? wartość)– czy wartość jest ujemna,(pos-int?) wartość)– czy wartość całkowita jest dodatnia,(neg-int?) wartość)– czy wartość całkowita jest ujemna,(nat-int?) wartość)– czy wartość całkowita jest liczbą naturalną (wł. 0),(even? wartość)– czy wartość jest parzysta,(odd? wartość)– czy wartość jest nieparzysta,(number? wartość)– czy wartość jest typem numerycznym,(ratio? wartość)– czy wartość jest ułamkiem (typRatio),(rational? wartość)– czy wartość jest liczbą wymierną,(integer? wartość)– czy wartość to liczba całkowita (bezBigDecimal),(decimal? wartość)– czy wartość to liczba typuBigDecimal,(float? wartość)– czy wartość to liczba zmiennoprzecinkowa,(double? wartość)– czy wartość to liczba podwójnej precyzji,
Operatory bitowe
W odniesieniu do danych typu numerycznego możemy dokonywać operacji bitowych.
Użycie:
-
funkcje wieloargumentowe (min. 2):
(bit-and wartość wartość-2 & wartość…)– koniunkcja bitowa,(bit-and-not wartość wartość-2 & wartość…)– koniunkcja z negacją,(bit-or wartość wartość-2 & wartość…)– suma bitowa,(bit-xor wartość wartość-2 & wartość…)– różnica symetryczna;
-
funkcje dwuargumentowe:
(bit-test wartość pozycja)– odczyt stanu bitu o podanej pozycji,(bit-flip wartość pozycja)– zmiana stanu bitu o podanej pozycji,(bit-set wartość pozycja)– zapalenie bitu o podanej pozycji,(bit-clear wartość pozycja)– zgaszenie bitu o podanej pozycji,(bit-shift-left wartość n)– przesunięcie bitowe w lewo,(bit-shift-right wartość n)– przesunięcie bitowe w prawo,(unsigned-bit-shift-right wartość n)– przes. w prawo bez znaku;
-
funkcje jednoargumentowe:
(bit-not wartość)– negacja bitowa.
Liczby pseudolosowe
Liczby pseudolosowe to wartości numeryczne generowane algorytmicznie (w JVM przez java.util.Random),
które powinny być nieprzewidywalne i cechować się równomiernym rozkładem w czasie
(niepowtarzalność).
Generowanie liczb pseudolosowych, rand
Do generowania liczb pseudolosowych służy funkcja rand.
Użycie:
(rand górny-zakres?).
Funkcja przyjmuje jeden opcjonalny argument, wskazujący górną granicę przedziału, z którego ma być pobrany wynik (domyślnie 1, jeżeli nie podano argumentu). Przedział ten jest prawostronnie otwarty (nie zawiera wartości podanej jako prawa granica), a jego pierwszym elementem jest 0.
Zwracana przez funkcję wartość jest liczbą zmiennoprzecinkową.
Całkowite liczby pseudolosowe, rand
Funkcja rand-int działa podobnie jak rand, czyli generuje liczbę pseudolosową,
ale zwraca liczbę całkowitą.
Użycie:
(rand-int górny-zakres).
Funkcja przyjmuje jeden obowiązkowy argument, wskazujący górną granicę przedziału, z którego ma być pobrany wynik. Przedział ten jest prawostronnie otwarty (nie zawiera wartości podanej jako prawa granica), a jego pierwszym elementem jest 0.
Zwracana przez funkcję wartość jest liczbą całkowitą.
rand i rand-int
(rand) ; => 0.7355816410955994
(rand 2) ; => 1.0126588862070758
(rand-int 50) ; => 3
Konfiguracja
Niektóre funkcje i mechanizmy służące do obsługi numerycznych typów danych możemy konfigurować. Służą do tego odpowiednie funkcje i zmienne specjalne.
Testy przepełnień
Podczas etapu kompilowania kodu źródłowego dokonywane są sprawdzenia, czy funkcje
sumowania, odejmowania, mnożenia, zwiększania o jeden, zmniejszania o jeden
i zaokrąglania wartości nie zwrócą błędu przekroczenia zakresu. Testy te mogą zostać
wyłączone przez powiązanie zmiennej specjalnej *unchecked-math* z wartością true.
unchecked-match
(alter-var-root #'*unchecked-math* (constantly true))
(alter-var-root #'*unchecked-math* (constantly true))
Uwaga: Niektóre numeryczne typy danych i tak będą korzystały z testów przepełnień, ponieważ to ustawienie odnosi się tylko do sytuacji, gdy wszystkie operandy są typami wbudowanymi. Aby mieć pewność, że testy nie będą przeprowadzane, warto posłużyć się opcjonalnym statycznym typizowaniem przez skorzystanie z mechanizmu sugerowania typów (ang. type hinting).
Określanie dokładności, with-precision
W przypadku danych typu BigDecimal możemy sterować precyzją i trybem zaokrąglania
wyników. Służy do tego makro with-precision.
Użycie:
(with-precision dokładność wartość),(with-precision dokładność :rounding tryb wartość).
Jego pierwszy argument ustawia liczbę cyfr znaczących (precyzję), opcjonalny drugi argument sposób zaokrąglania, a ostatni argument jest wyrażeniem, które ma być przeliczone z użyciem tych ustawień.
with-precision
(with-precision 5 :rounding CEILING (/ 1M 3))
; => 0.33334M
(with-precision 5 :rounding CEILING (/ 1M 3))
; => 0.33334M
Możliwe tryby zaokrąglania:
CEILING– do górnego pułapu,FLOOR– do dolnego pułapu,HALF_UP– w górę do połówek (tryb domyślny),HALF_DOWN– w dół do połówek,HALF_EVEN– do bliższych połówek,UP– w górę,DOWN– w dół,UNNECESSARY– niewymagane.
W przypadku ostatniego trybu zgłoszony zostanie wyjątek, gdy w wyniku obliczeń pojawią się liczby po przecinku.
Zobacz także:
Znaki
Pojedyncze znaki są w Clojure reprezentowane przez obiekty klasy
java.lang.Character. Są to znaki wielobajtowe i mogą być literami alfabetu Unicode.
Tworzenie znaków
Znaki można tworzyć z użyciem odpowiednich funkcji lub literałów znakowych.
Literały znakowe
Korzystając z symbolicznego zapisu z odwróconym ukośnikiem (ang. backslash), możemy literalnie wyrażać pojedyncze znaki.
Użycie:
\znak,\znak-specjalny.
1\d ; literał znakowy
2; => \d
3
4\newline ; literał znakowy znaku specjalnego (nowa linia)
5; => \newline
\d ; literał znakowy
; => \d
\newline ; literał znakowy znaku specjalnego (nowa linia)
; => \newline
Znak z kodu, char
Używając funkcji char, możemy tworzyć znak podając jego kod zgodny ze standardem
UTF-16BE.
Użycie:
(char kod-znaku).
Funkcja przyjmuje jeden argument, który powinien być numerycznie wyrażonym kodem znaku, a zwraca znak o podanym kodzie. Zwracany znak może być wewnętrznie reprezentowany wartością wielobajtową.
char
(char 100) ; tworzymy znak o kodzie 100 (litera d)
; => \d
(char 261) ; litera ą
; => \ą
Znak z łańcucha, get
Dzięki funkcji get jesteśmy w stanie pobrać dowolny znak podanego łańcucha
znakowego.
Użycie:
(get łańcuch pozycja).
Pierwszym argumentem przekazywanym do funkcji powinien być łańcuch znakowy, a drugim pozycja, na której znajduje się znak, który chcemy pobrać (poczynając od 0).
Funkcja zwraca znak lub wartość nil, jeżeli nie udało się pobrać znaku
(np. z powodu niewłaściwego numeru pozycji).
(get "siefca" 2)
; => \e
(get "siefca" 2)
; => \e
Sekwencje znakowe
Warto zauważyć, że łańcuchy znakowe w Clojure można traktować jak sekwencje znakowe i używać w stosunku do nich funkcji przeznaczonych dla sekwencji.
Poniżej znajduje się lista wybranych sekwencyjnych operacji, które prowadzą do uzyskania znaku lub zestawu znaków z łańcucha.
Użycie:
(seq łańcuch)– tworzy sekwencję znaków,(first łańcuch)– pobiera pierwszy znak,(last łańcuch)– pobiera ostatni znak,(rest łańcuch)– pobiera wszystkie znaki poza pierwszym,(nth łańcuch indeks)– pobiera wskazany znak,(rand-nth łańcuch)– pobiera losowy znak,(apply funkcja łańcuch)– podstawia każdy znak jako arg. funkcji,(every? predykat łańcuch)– sprawdza warunek dla każdego znaku,(reverse łańcuch)– odwraca kolejność sekwencji znakowej,(frequencies łańcuch)– zlicza częstości występowania znaków,(when-first [znak łańcuch …] wyrażenie)– wartościuje dla 1-go znaku.
1(nth "siefca" 2 ) ; => \e
2(rand-nth "siefca" ) ; => \f
3(first "siefca" ) ; => \s
4(last "siefca" ) ; => \a
5(rest "siefca" ) ; => (\i \e \f \c \a)
6(apply vector "siefca" ) ; => [\s \i \e \f \c \a]
7(seq "siefca" ) ; => (\s \i \e \f \c \a)
8(every? char? "siefca" ) ; => true
9(reverse "siefca" ) ; => (\a \c \f \e \i \s)
10(frequencies "aaabbc" ) ; => {\a 3, \b 2, \c 1}
11(when-first [z "abcdef"] z) ; => \a
12
13; uwaga: nth dla nieistniejącego indeksu zgłosi wyjątek!
(nth "siefca" 2 ) ; => \e
(rand-nth "siefca" ) ; => \f
(first "siefca" ) ; => \s
(last "siefca" ) ; => \a
(rest "siefca" ) ; => (\i \e \f \c \a)
(apply vector "siefca" ) ; => [\s \i \e \f \c \a]
(seq "siefca" ) ; => (\s \i \e \f \c \a)
(every? char? "siefca" ) ; => true
(reverse "siefca" ) ; => (\a \c \f \e \i \s)
(frequencies "aaabbc" ) ; => {\a 3, \b 2, \c 1}
(when-first [z "abcdef"] z) ; => \a
; uwaga: nth dla nieistniejącego indeksu zgłosi wyjątek!
Przekształcanie znaków
Cytowanie specjalnych, char-escape-string
Generowanie sekwencji unikowej dla znaków o specjalnym znaczeniu możliwe jest dzięki
funkcji char-escape-string.
Użycie:
(char-escape-string znak).
Pierwszym argumentem powinien być znak specjalny (wyrażony literalnie lub w inny sposób).
Funkcja zwraca sekwencję unikową dla podanego znaku specjalnego lub nil, jeżeli nie
istnieje sekwencja unikowa.
char-escape-string
1;; brak sekwencji unikowej dla litery c
2
3(char-escape-string \c) ; => nil
4
5;; sekwencja unikowa dla nowej linii
6
7(char-escape-string \newline) ; => "\\n"
8
9;; sekwencja unikowa dla backspace'a
10
11(char-escape-string \backspace) ; => "\\b"
;; brak sekwencji unikowej dla litery c
(char-escape-string \c) ; => nil
;; sekwencja unikowa dla nowej linii
(char-escape-string \newline) ; => "\\n"
;; sekwencja unikowa dla backspace'a
(char-escape-string \backspace) ; => "\\b"
Nazwy specjalnych, char-name-string
Pobieranie nazw dla znaków o specjalnym znaczeniu umożliwia funkcja
char-name-string.
Użycie:
(char-name-string znak).
Funkcja przyjmuje jeden argument, którym powinien być (wyrażony literalnie lub w inny
sposób) znak specjalny, a zwraca nazwę tego znaku lub nil, jeżeli nie podano znaku
lub podany znak nie jest znakiem specjalnym.
char-name-string
(char-name-string \a) ; => nil
(char-name-string \tab) ; => "tab"
(char-name-string \a) ; => nil
(char-name-string \tab) ; => "tab"
Testy znaków
Testowanie typu, char?
Dzięki predykatowi char? możemy sprawdzić, czy podana wartość jest znakiem.
Użycie:
(char? wartość).
Funkcja jako pierwszy argument przyjmuje wartość, a zwraca true, jeżeli jest ona
znakiem.
char?
(char? \a) ; => true
(char? 1) ; => false
(char? \a) ; => true
(char? 1) ; => false
Porównywanie znaków, =
Sprawdzanie czy znaki są takie same można przeprowadzić korzystając z operatora
=.
Użycie:
(= znak & znak…).
Funkcja przyjmuje jeden obowiązkowy argument, którym powinien być znak i opcjonalne argumenty, którymi mogą być inne znaki.
Wartością zwracaną jest true, gdy wszystkie podane znaki są takie same, a false
w przeciwnym razie.
(= \a \a) ; => true
(= \a) ; => true
(= \a \a \a) ; => true
(= \a \a \b) ; => false
Porównywanie znaków, compare
Porównywanie czy podany znak powinien być pod względem kolejności pierwszy,
ostatni czy równy drugiemu znakowi (przydatne w sortowaniu) możliwe jest dzięki
funkcji compare.
Użycie:
(compare znak-1 znak-2).
Funkcja przyjmuje dwa argumenty, a zwraca -1 (lub wartość mniejszą), gdy pierwszy podany argument powinien być umieszczony wcześniej niż drugi, 1 (lub wartość większą) w przypadku przeciwnym i 0, jeżeli obydwa znaki mogą mieć tę samą (równą) pozycję. Pod uwagę brana jest pozycja znaków w alfabecie.
compare
(compare \a \b)
; => -1
(compare \a \b)
; => -1
Zobacz także:
- „Komparator domyślny, compare”, rozdział XI.
Łańcuchy znakowe
Łańcuchy znakowe w Clojure to obiekty klasy java.lang.String. W języku istnieją
odpowiednie funkcje, które pomagają w ich obsłudze, a poza tym można korzystać
z operujących na łańcuchach metod Javy.
Łańcuchy znakowe można również traktować jak sekwencje znakowe i korzystać z funkcji operujących na sekwencjach. Więcej o tym sposobie dostępu można przeczytać w sekcji poświęconej [sekwencyjnej obsłudze znaków](#Sekwencje znakowe).
Tworzenie łańcuchów
Istnieje kilka sposobów tworzenia łańcuchów znakowych. Można skorzystać z literału
tekstowego, użyć funkcji str, albo też innej funkcji, która na podstawie danych
wejściowych zwróci łańcuch.
Łańcuchy z literałów tekstowych
Użycie:
"To jest napis","".
"To jest napis"
; => "To jest napis"
""
; => ""
Łańcuchy z szeregu wartości, str
Funkcja str przyjmuje zero lub więcej argumentów. Wartość każdego stara się
przekształcić do łańcucha znakowego, aby następnie dokonać
złączenia wszystkich uzyskanych łańcuchów w jeden, który zostanie zwrócony.
Użycie:
(str & wartość…).
Funkcja przyjmuje zero lub więcej argumentów o dowolnych wartościach, a zwraca łańcuch tekstowy, który jest złączeniem podanych wartości skonwertowanych do łańcuchów tekstowych.
Jeżeli nie podano argumentów, funkcja str zwraca łańcuch pusty.
str
(str 1 2 3) ; => "123"
(str "a" "b" "c" \d 4) ; => "abcd4"
(str) ; => ""
Łańcuchy z formatu, format
Funkcja format przyjmuje minimum jeden argument, którym powinien być łańcuch
formatujący zgodny ze składnią używaną przez java.util.Formatter (odpowiadającą
składni wykorzystywanej w funkcji
sprintf znajdującej się
w bibliotece standardowej języka C).
Użycie:
(format łańcuch-formatujący & wartość…).
Dla każdej sekwencji sterującej podanej w pierwszym argumencie (łańcuchu formatującym), która wymaga danych wejściowych, należy podać odpowiedni argument wyrażający wartość do podstawienia.
Funkcja zwraca przetworzony łańcuch znakowy zbudowany zgodnie z podanym wzorcem formatowania.
format
(format "Witaj, %s!", "Baobabie")
; => "Witaj, Baobabie!"
(format "Witaj, %s!", "Baobabie")
; => "Witaj, Baobabie!"
Łańcuchy z wyjścia, with-out-str
Łańcuchy znakowe można tworzyć na podstawie danych pochodzących z przechwyconego
strumienia wyjściowego (zazwyczaj skojarzonego z deskryptorem standardowego
wyjścia). Służy do tego makro with-out-str.
Użycie:
(with-out-str & wyrażenie…)
Makro przyjmuje zestaw wyrażeń, które zostaną zrealizowane (obliczone). Jeżeli któreś z nich wygeneruje efekt uboczny w postaci zapisu do strumienia standardowego wyjścia, dane te będą przechwycone i umieszczone w zwracanym łańcuchu znakowym.
with-out-str
;; standardowe wyjście wyrażenia do łańcucha
(with-out-str (println "Baobab"))
; => "Baobab\n"
;; standardowe wyjście wyrażenia do łańcucha
(with-out-str (println "Baobab"))
; => "Baobab\n"
Łańcuchy z wartości, pr-str
Funkcja pr-str działa podobnie do str i służy do przekształcania podanych
wartości do ich symbolicznych reprezentacji (S-wyrażeń). Działa tak, jakby użyć
pr, ale rezultat nie jest wyświetlany, lecz zwracany jako łańcuch tekstowy.
(pr-str & wartość…)
Funkcja przyjmuje zero lub więcej wartości i każdą z nich rzutuje do łańcucha znakowego.
Wartością zwracaną jest złączenie tekstowych reprezentacji wartości z separatorami w postaci pojedynczego znaku spacji.
pr-str
(pr-str [1 2 3 4] '(1)) ; wpisuje w łańcuch reprezentację obiektów
; => "[1 2 3 4] (1)" ; zwróconą przez funkcję pr
(pr-str [1 2 3 4] '(1)) ; wpisuje w łańcuch reprezentację obiektów
; => "[1 2 3 4] (1)" ; zwróconą przez funkcję pr
Łańcuchy z wartości, prn-str
Funkcja prn-str działa podobnie do str i służy do przekształcania podanych
wartości do ich symbolicznych reprezentacji (S-wyrażeń). Działa tak, jakby użyć
prn, ale rezultat nie jest wyświetlany, lecz zwracany jako łańcuch tekstowy.
(prn-str & wartość…)
Funkcja przyjmuje zero lub więcej wartości i każdą z nich rzutuje do łańcucha znakowego.
Wartością zwracaną jest złączenie tekstowych reprezentacji wartości z separatorami w postaci pojedynczego znaku spacji. Łańcuch zakończony jest znakiem nowej linii.
prn-str
(prn-str [1 2 3 4] '(1)) ; wpisuje w łańcuch reprezentację obiektów
; => "[1 2 3 4] (1)\n" ; zwróconą przez funkcję prn
(prn-str [1 2 3 4] '(1)) ; wpisuje w łańcuch reprezentację obiektów
; => "[1 2 3 4] (1)\n" ; zwróconą przez funkcję prn
Łańcuchy z rezultatu print, print-str
Funkcja print-str działa tak jak print, ale zamiast wyświetlać rezultaty
zwraca zawierający je łańcuch znakowy.
(print-str & wartość…).
Funkcja przyjmuje zero lub więcej wartości i każdą z nich rzutuje do łańcucha znakowego.
Wartością zwracaną jest złączenie tekstowych reprezentacji wartości z separatorami w postaci pojedynczego znaku spacji.
print-str
(print-str "Ba" \o \b 'ab) ; tworzy łańcuch z efektu wywołania print
; => "Ba o b ab"
(print-str "Ba" \o \b 'ab) ; tworzy łańcuch z efektu wywołania print
; => "Ba o b ab"
Łańcuchy z rezultatu println, println-str
Funkcja println-str działa tak jak println, ale zamiast wyświetlać rezultaty
zwraca zawierający je łańcuch znakowy.
(println-str & wartość…).
Funkcja przyjmuje zero lub więcej wartości i każdą z nich konwertuje do łańcucha znakowego.
Wartością zwracaną jest złączenie tekstowych reprezentacji wartości z separatorami w postaci pojedynczego znaku spacji.
println-str
(println-str "Ba" \o \b 'ab) ; tworzy łańcuch z efektu wywołania println
; => "Ba o b ab\n"
(println-str "Ba" \o \b 'ab) ; tworzy łańcuch z efektu wywołania println
; => "Ba o b ab\n"
Porównywanie łańcuchów
Łańcuchy znakowe można porównywać, korzystając z generycznych operatorów.
Użycie:
-
(= łańcuch & łańcuch…)– równe, -
(compare łańcuch łańcuch )– porównuje leksykograficznie dwa łańcuchy.
Zobacz także:
- „Komparator domyślny, compare”, rozdział XI.
Przeszukiwanie łańcuchów
Funkcje index-of i last-index-of
Pobieranie pozycji podanego łańcucha w tekście możliwe jest z użyciem funkcji
clojure.string/index-of i clojure.string/last-index-of.
Użycie:
-
(clojure.string/index-of łańcuch fragment start?)
– wyszukuje pozycję pierwszego wystąpienia, -
(clojure.string/last-index-of łańcuch fragment start?)
– wyszukuje pozycję ostatniego wystąpienia.
Funkcje przyjmują dwa obowiązkowe argumenty: łańcuch tekstowy i poszukiwany fragment tekstu. Wartościami zwracanymi są pozycje (licząc od 0), pod którymi można znaleźć podane łańcuchy.
Gdy podano opcjonalny, trzeci argument start, powinien on określać pozycję, od
której rozpoczęte będzie przeszukiwanie.
index-of i last-index-of
(clojure.string/index-of "Baobab tu był." "b") ; => 3
(clojure.string/last-index-of "Baobab tu był." "b") ; => 10
(clojure.string/index-of "Baobab tu był." "b") ; => 3
(clojure.string/last-index-of "Baobab tu był." "b") ; => 10
Zliczanie znaków
Funkcja count
Funkcja count zlicza znaki w łańcuchu (włączając znaki wielobajtowe).
Dla łańcuchów znakowych zliczanie odbywa się w czasie stałym (O(1)), ponieważ wykorzystywana jest metoda .length() klasy String.
Użycie:
(count łańcuch).
Pierwszym przekazywanym argumentem powinien być łańcuch znakowy, a wartością zwracaną jest liczba znaków w tym łańcuchu.
(count "Baobab") ; liczba znaków (nawet wielobajtowych)
; => 6
(count "Baobab") ; liczba znaków (nawet wielobajtowych)
; => 6
Wyrażenia regularne
Wyrażenia regularne (ang. regular expressions, skr. regexps) to obiekty, które pozwalają opisywać wzorce dopasowywania do tekstu. Wewnętrznie reprezentowane są odpowiednio zoptymalizowanymi strukturami danych, ale podczas ich tworzenia korzysta się z czytelnego zapisu tekstowego, zrozumiałego dla człowieka.
Wyrażeń regularnych możemy używać w celu sprawdzania, czy podane łańcuchy znakowe lub ich części pasują do określonych wzorców. Jesteśmy też w stanie budować operatory, które na podstawie wyrażeń regularnych będą dokonywały zastępowania pasujących fragmentów tekstu innymi lub wyodrębniały te fragmenty.
Literały wyrażeń regularnych
W Clojure wyrażenia regularne mogą być tworzone z użyciem odpowiedniej, literalnej notacji:
#"wzorzec",
gdzie wzorzec jest łańcuchem znakowym określającym treść wyrażenia zgodnego
z formatem argumentu przyjmowanego przez konstruktor klasy
java.util.regex.Pattern.
Tworzenie z wzorca, re-pattern
Tworzenie obiektu wyrażenia regularnego z tekstowej reprezentacji wzorca
dopasowywania jest możliwe dzięki funkcji re-pattern. Wygenerowana wartość to
skompilowana forma podanej, tekstowej reprezentacji wyrażenia, a posługiwanie się
takim obiektem wpływa korzystnie na wykorzystanie zasobów procesora. Obiektu
wyrażenia regularnego można wielokrotnie używać, przekazując go jako argument do
funkcji operujących na wyrażeniach regularnych.
Użycie:
(re-pattern wzorzec).
Funkcja przyjmuje łańcuch znakowy reprezentujący wzorzec dopasowania, a zwraca obiekt wyrażenia regularnego.
re-pattern
(re-pattern "\\d+") ; tworzenie wyrażenia regularnego
#"\d+" ; lukier składniowy
(re-pattern "\\d+") ; tworzenie wyrażenia regularnego
#"\d+" ; lukier składniowy
Warto zauważyć podwójny znak odwróconego ukośnika, który odbiera jego specjalne znaczenie.
Tworzenie dopasowywacza, re-matcher
Tworzenie obiektu dopasowującego pozwala korzystać z funkcji służących do przetwarzania łańcuchów znakowych z użyciem wzorców dopasowania w formie wyrażeń regularnych. Dzięki niemu można wielokrotnie korzystać z dopasowania w jego już skompilowanej, wewnętrznej formie. Dopasowywacz jest mutowalnym obiektem Javy, który przechowuje wewnętrzne indeksy ulegające zmianie.
Do tworzenia obiektu dopasowującego używa się funkcji re-matcher.
Użycie:
(re-matcher wyrażenie łańcuch).
Funkcja przyjmuje dwa argumenty. Pierwszym powinien być obiekt wyrażenia regularnego, a drugim badany łańcuch.
Wartością zwracaną jest obiekt dopasowujący wyrażenia regularne.
re-matcher
(re-matcher #"\d+" "abcd1234efgh5678")
(re-matcher #"\d+" "abcd1234efgh5678")
Wywołanie funkcji z powyższego przykładu utworzy obiekt klasy
java.util.regex.Matcher. Pierwszym przekazywanym jej argumentem jest wyrażenie
regularne, a drugim dopasowywany do niego łańcuch znakowy. Stworzona wartość może być
następnie podana jako argument do niektórych funkcji ekstrahujących dopasowania,
np. re-find.
Uwaga: Wewnętrzne struktury obiektów typu Matcher mogą ulegać
zmianom w nieskoordynowany sposób, generując błędne rezultaty.
Wyszukiwanie dopasowań i grup, re-find
Funkcja re-find odnajduje dopasowania podanego łańcucha znakowego do wyrażenia
regularnego lub dopasowywacza. Przyjmuje ona dwa argumenty: wyrażenie regularne
i łańcuch znakowy. Można też użyć jej w formie jednoargumentowej – przyjmuje wtedy
obiekt dopasowujący (typu Matcher), a każdorazowe wywołanie zwraca kolejny pasujący
fragment.
Wyrażenia regularne mogą składać się z grup, czyli logicznych części, które
zawierają wzorce fragmentaryczne, pasujące do pewnych części łańcucha znakowego.
Grupy te mogą być zagnieżdżane. W przypadku wyrażenia regularnego z grupami, funkcja
re-find zwróci wektor, którego poszczególne elementy będą odpowiadały
kolejnym pasującym grupom. Wyjątkiem będzie element o indeksie zero, zawierający cały
fragment łańcucha, który pasuje do wszystkich wzorców.
Funkcja re-find wewnętrznie czyni użytek z opisanej niżej funkcji re-groups, aby
zwrócić wyniki.
Użycie:
(re-find dopasowywacz),(re-find wyrażenie łańcuch).
W wariancie jednoargumentowym przyjmowanym argumentem jest obiekt dopasowujący wyrażenia regularne. W wariancie dwuargumentowym należy podać obiekt wyrażenia regularnego i dopasowywany łańcuch znakowy.
Wartością zwracaną jest dopasowany fragment łańcucha znakowego lub wektor zawierający dopasowania.
re-find
1;; zwraca pierwsze dopasowanie
2
3(re-find #"\d+" "abc123def456")
4; => "123"
5
6;; zwraca pasujące grupy
7
8(re-find #"(\d+)-(\d+)-(\d+)" "000-111-222")
9; => ["000-111-222" "000" "111" "222"]
10
11;; nazywamy globalny obiekt dopasowujący
12
13(def pasuj (re-matcher #"\d+" "abc123def456"))
14; => #'user/pasuj
15
16;; powtarzamy trzykrotnie dopasowywanie
17
18(repeatedly 3
19 #(re-find pasuj))
20; => ("123" "456" nil)
;; zwraca pierwsze dopasowanie
(re-find #"\d+" "abc123def456")
; => "123"
;; zwraca pasujące grupy
(re-find #"(\d+)-(\d+)-(\d+)" "000-111-222")
; => ["000-111-222" "000" "111" "222"]
;; nazywamy globalny obiekt dopasowujący
(def pasuj (re-matcher #"\d+" "abc123def456"))
; => #'user/pasuj
;; powtarzamy trzykrotnie dopasowywanie
(repeatedly 3
#(re-find pasuj))
; => ("123" "456" nil)
Uwaga: Korzystanie z re-matcher nie jest bezpieczne wątkowo!
Odczyt pasujących grup, re-groups
Funkcja re-groups pozwala odczytać pasujące grupy wyrażenia regularnego, które było
ostatnio używane.
Użycie:
(re-groups dopasowywacz).
Funkcja przyjmuje tylko jeden argument, którym powinien być obiekt dopasowujący, a zwraca wektor fragmentów tekstu pasujących do grup.
Jeżeli ostatnia próba dopasowania łańcucha znakowego do wyrażenia zakończyła się
zwróceniem nil, to próba wywołania funkcji re-groups zgłosi wyjątek.
re-groups
1;; zmienna globalna tel wskazuje obiekt dopasowujący
2
3(def tel (re-matcher #"(\d+)-(\d+)-(\d+)" "000-111-222"))
4
5;; najpierw wykonujemy dopasowanie
6
7(re-find tel)
8; => "000-111-222"
9
10;; odczyt pasujących grup w postaci wektora
11
12(re-groups tel)
13; => ["000-111-222" "000" "111" "222"]
;; zmienna globalna tel wskazuje obiekt dopasowujący
(def tel (re-matcher #"(\d+)-(\d+)-(\d+)" "000-111-222"))
;; najpierw wykonujemy dopasowanie
(re-find tel)
; => "000-111-222"
;; odczyt pasujących grup w postaci wektora
(re-groups tel)
; => ["000-111-222" "000" "111" "222"]
Uwaga: Korzystanie z re-matcher nie jest bezpieczne wątkowo!
Dopasowywanie, re-matches
Funkcja re-matches pozwala sprawdzić, czy podany łańcuch znakowy pasuje do wzorca
reprezentowanego wyrażeniem regularnym.
Różnica między funkcjami re-find i re-matches polega na tym, że ta ostatnia nie
szuka dopasowań fragmentarycznych. Podany łańcuch musi pasować do wzorca wyrażenia
regularnego w całości.
Użycie:
(re-matches wyrażenie łańcuch).
Funkcja przyjmuje dwa argumenty. Pierwszym powinno być wyrażenie regularne, a drugim łańcuch znakowy.
Zwracaną wartością będzie pojedynczy łańcuch znakowy lub wektor łańcuchów, jeżeli
użyto grup (wewnętrznie funkcja korzysta z re-groups). W razie braku dopasowania
zwracana jest wartość nil.
re-matches
(re-matches #"(\d+)-(\d+)-(\d+)" "000-111-222")
; => ["000-111-222" "000" "111" "222"]
(re-matches #"(\d+)-(\d+)-(\d+)" "000-111-222")
; => ["000-111-222" "000" "111" "222"]
Dostęp sekwencyjny, re-seq
Bezpieczne pod względem wątkowym i zgodne ze stylem funkcyjnym jest używanie
sekwencji (a dokładniej leniwych sekwencji) do reprezentowania dopasowań
łańcuchów znakowych do wzorców wyrażeń regularnych. Służy do tego funkcja re-seq,
która wewnętrznie korzysta z metody java.util.regex.Matcher.find(), a następnie
używa re-groups, aby wygenerować wynik.
Użycie:
(re-seq wyrażenie łańcuch).
Funkcja przyjmuje dwa argumenty: wyrażenie regularne i łańcuch znakowy, a zwraca leniwą sekwencję kolejnych fragmentów pasujących do wzorca.
re-seq
(re-seq #"[\p{L}\p{Digit}_]+" "Podzielimy to na słowa")
; => ("Podzielimy" "to" "na" "słowa")
(re-seq #"[\p{L}\p{Digit}_]+" "Podzielimy to na słowa")
; => ("Podzielimy" "to" "na" "słowa")
Cytowanie, re-quote-replacement
Gdyby łańcuch znakowy używany jako zastępnik w wywołaniu clojure.string/replace był
generowany dynamicznie, konieczne może okazać się dodanie sekwencji unikowych
przed wzorcami, które mają znaczenie specjalne. Na przykład chcemy pewien wyraz
zastąpić przykładem zawierającym zapis $1, który w przypadku korzystania z wyrażeń
regularnych zostałby zastąpiony przez wartość pierwszego pasującego wyrażenia
grupowego. W przypadku statycznego napisu dodalibyśmy po prostu znak odwróconego
ukośnika (\$1), aby odebrać specjalne znaczenie zapisowi. Gdyby jednak zastępnik
był efektem działania programu, musielibyśmy go zmienić, zastępując specjalne wzorce
innymi. W czynności tej może wyręczyć nas funkcja re-quote-replacement.
Użycie:
(re-quote-replacement łańcuch).
Pierwszym i jedynym przyjmowanym przez funkcję argumentem powinien być łańcuch znakowy reprezentujący zastępnik, którego chcemy użyć w innych funkcjach. Wartością zwracaną jest łańcuch znakowy, w którym zacytowane zostały wzorce mające specjalne znaczenie w kontekście wyrażeń regularnych.
clojure.string/re-quote-replacement
1;; bez odbierania specjalnego znaczenia
2
3(clojure.string/replace "Kolor czerwony"
4 #"(\w+) ([Cc]zerwony)"
5 "$1 określony symbolem $2")
6; => "Kolor określony symbolem czerwony"
7
8;; z odbieraniem specjalnego znaczenia
9
10(clojure.string/replace "Kolor czerwony"
11 #"(\w+) ([Cc]zerwony)"
12 (str "$1 określony symbolem"
13 (clojure.string/re-quote-replacement
14 " $1")))
15; => "Kolor określony symbolem $1"
;; bez odbierania specjalnego znaczenia
(clojure.string/replace "Kolor czerwony"
#"(\w+) ([Cc]zerwony)"
"$1 określony symbolem $2")
; => "Kolor określony symbolem czerwony"
;; z odbieraniem specjalnego znaczenia
(clojure.string/replace "Kolor czerwony"
#"(\w+) ([Cc]zerwony)"
(str "$1 określony symbolem"
(clojure.string/re-quote-replacement
" $1")))
; => "Kolor określony symbolem $1"
Przekształcanie łańcuchów
Zmiana pierwszej litery w wielką, capitalize
Zmiana pierwszej litery w wielką umożliwia funkcja
clojure.string/capitalize.
Użycie:
(clojure.string/capitalize łańcuch).
Pierwszym i jedynym argumentem powinien być łańcuch tekstowy, a wartością zwracaną jest łańcuch, którego pierwsza litera jest zmieniona w wielką, a pozostałe litery zamienione w małe.
clojure.string/capitalize
(clojure.string/capitalize "baobab tu był.")
; => "Baobab tu był."
(clojure.string/capitalize "baobab tu był.")
; => "Baobab tu był."
Zmiana liter w małe, lower-case
Zmiana wszystkich liter w małe możliwe jest z wykorzystaniem funkcji
clojure.string/lower-case.
Użycie:
(clojure.string/lower-case łańcuch).
Funkcja przyjmuje jeden argument, którym powinien być łańcuch tekstowy, a zwraca nowy łańcuch, w którym przekształcono odpowiednie znaki.
clojure.string/lower-case
(clojure.string/lower-case "BAOBAB")
; => "baobab"
(clojure.string/lower-case "BAOBAB")
; => "baobab"
Zmiana liter w wielkie, upper-case
Zmiana wszystkich liter w wielkie możliwa jest z użyciem funkcji
clojure.string/upper-case.
Użycie:
(clojure.string/upper-case łańcuch).
Funkcja przyjmuje jeden argument, którym powinien być łańcuch tekstowy, a zwraca nowy łańcuch, w którym przekształcono odpowiednie znaki.
clojure.string/upper-case
(clojure.string/upper-case "baobab")
; => "BAOBAB"
(clojure.string/upper-case "baobab")
; => "BAOBAB"
Dodawanie sekwencji unikowych, escape
Funkcja clojure.string/escape pozwala na dodawanie sekwencji unikowych
(ang. escape sequences) przez zmianę określonych znaków w łańcuchy.
Użycie:
(clojure.string/escape łańcuch mapa).
Jako pierwszy argument funkcji należy podać łańcuch znakowy, a jako drugi mapę zawierającą pary, w których kluczami są znaki, a wartościami łańcuchy, na które mają zostać zamienione, gdy zostaną znalezione w tekście.
clojure.string/escape
(clojure.string/escape "echo *" { \* "\\*", \; "\\;" })
; => "echo \\*"
(clojure.string/escape "echo *" { \* "\\*", \; "\\;" })
; => "echo \\*"
Zmiana kolejności znaków, reverse
Do odwracania kolejności znaków w łańcuchu służy funkcja
clojure.string/reverse.
Użycie:
(clojure.string/reverse łańcuch).
Przyjmuje ona jako pierwszy argument łańcuch znakowy, a zwraca łańcuch, który jest odwróconą wersją podanego.
clojure.string/reverse
(clojure.string/reverse "nicraM")
; => "Marcin"
(clojure.string/reverse "nicraM")
; => "Marcin"
Odwrócona sekwencja znaków, reverse
Funkcja reverse z przestrzeni nazw clojure.core działa odmiennie niż
clojure.string/reverse, ponieważ zwraca sekwencję znaków
o odwróconej kolejności. Sekwencję taką można następnie przekształcić do
łańcucha znakowego, np. z użyciem apply czy str.
Użycie:
(reverse łańcuch).
Pierwszym argumentem powinien być łańcuch znakowy, a zwracaną wartością jest sekwencja znaków, której kolejność została odwrócona względem kolejności podanego łańcucha.
reverse
(apply str (reverse "nicraM"))
; => "Marcin"
(apply str (reverse "nicraM"))
; => "Marcin"
Przycinanie łańcuchów, trim
Usuwanie białych znaków (w tym znaków nowej linii) z obu krańców łańcucha
znakowego może być dokonane z wykorzystaniem funkcji clojure.string/trim.
Użycie:
(clojure.string/trim łańcuch).
Funkcja przyjmuje jako pierwszy argument łańcuch znakowy, a zwraca jego wersję z usuniętymi białymi znakami i znakami nowej linii z jego początku i końca.
clojure.string/trim
(clojure.string/trim " Baobab tu był. ")
; => "Baobab tu był."
(clojure.string/trim " Baobab tu był. ")
; => "Baobab tu był."
Przycinanie z lewej, triml
Usuwanie białych znaków (w tym znaków nowej linii) z lewej strony łańcucha
znakowego możliwe jest dzięki funkcji clojure.string/triml.
Użycie:
(clojure.string/triml łańcuch).
Funkcja przyjmuje jako pierwszy argument łańcuch znakowy, a zwraca jego wersję z usuniętymi białymi znakami i znakami nowej linii z jego początku.
clojure.string/triml
(clojure.string/triml " Baobab tu był. ")
; => "Baobab tu był. "
(clojure.string/triml " Baobab tu był. ")
; => "Baobab tu był. "
Przycinanie z prawej, trimr
Na usuwanie białych znaków (w tym znaków nowej linii) z prawej strony łańcucha
znakowego pozwala funkcja clojure.string/trimr.
Użycie:
(clojure.string/trimr łańcuch).
Funkcja przyjmuje jako pierwszy argument łańcuch znakowy, a zwraca jego wersję z usuniętymi białymi znakami i znakami nowej linii z jego końca.
clojure.string/trimr
(clojure.string/trimr " Baobab tu był. ")
; => " Baobab tu był."
(clojure.string/trimr " Baobab tu był. ")
; => " Baobab tu był."
Przycinanie nowej linii, trim-newline
Usuwanie znaków nowej linii z prawej strony łańcucha znakowego możliwe jest
z użyciem funkcji clojure.string/trim-newline.
Użycie:
(clojure.string/trim-newline łańcuch).
Funkcja przyjmuje jako pierwszy argument łańcuch znakowy, a zwraca jego wersję z usuniętymi znakami nowej linii (z jego końca).
clojure.string/trim-newline
(clojure.string/trim-newline "Baobab tu był.\n")
; => "Baobab tu był."
(clojure.string/trim-newline "Baobab tu był.\n")
; => "Baobab tu był."
Zamiana fragmentów tekstu, replace
Zamiana fragmentów łańcucha znakowego na inne realizowana jest przez funkcję
replace, której pierwszym argumentem powinien być łańcuch znakowy, drugim wzorzec
dopasowania (w postaci wyrażenia regularnego, tekstu bądź znaku), natomiast trzecim
zastępnik umieszczany w miejscach pasujących do wzorca (tekst, znak bądź funkcja
przekształcająca). Wartością zwracaną jest łańcuch tekstowy, w którym dopasowane
do wzorca fragmenty (lub całość) zostały zastąpione odpowiednimi składnikami
zastępnika (lub całą wartością zastępnika).
Użycie:
(clojure.string/replace łańcuch wzorzec zastępnik);
gdzie wzorzec to:
- łańcuch znakowy,
- pojedynczy znak,
- wyrażenie regularne;
a zastępnik to:
- łańcuch znakowy,
- pojedynczy znak,
- funkcja przekształcająca.
Możliwe są następujące kombinacje wzorców i zastępników:
- łańcuch znakowy i łańcuch znakowy,
- pojedynczy znak i pojedynczy znak,
- wyrażenie regularne i łańcuch znakowy,
- wyrażenie regularne i funkcja przekształcająca.
W przypadku łańcuchów znakowych i pojedynczych znaków tekst zastępujący nie jest traktowany specjalnie, tzn. nie można w nim korzystać z żadnych interpolowanych wzorców. Inaczej jest, gdy jako wzorzec podamy wyrażenie regularne – można wtedy podać odpowiednie znaczniki, które zostaną zastąpione wartościami przechwyconymi podczas analizy tych wyrażeń.
Jeżeli wzorzec wyrazimy wyrażeniem regularnym, a zastępnik zdefiniujemy obiektem funkcyjnym, wtedy przekazywana jako ostatni argument funkcja musi przyjmować jeden argument i zwracać łańcuch znakowy. Jako argument przekazany jej będzie wektor dopasowań, przy czym jego pierwszy element (o indeksie 0) będzie zawierał zgrupowane wszystkie dopasowania do wzorca. Zwrócona przez funkcję wartość stanie się nowym łańcuchem znakowym, która w całości zastąpi wejściowy.
clojure.string/replace
1;; wzorzec jako tekst, zastępnik jako tekst
2
3(clojure.string/replace "Kolor czerwony" "czerwony" "niebieski")
4; => "Kolor niebieski"
5
6;; wzorzec jako tekst, zastępnik jako tekst
7
8(clojure.string/replace "Litera A" \A \B)
9; => "Litera B"
10
11;; wzorzec jako wyrażenie regularne, zastępnik jako tekst
12
13(clojure.string/replace "Kolor czerwony" #"\b(\w+ )(\w+)" "$1niebieski")
14; => "Kolor niebieski"
15
16;; wzorzec jako wyrażenie regularne, zastępnik jako funkcja
17
18(clojure.string/replace "Kolor czerwony"
19 #"\b(\w+ )(\w+)"
20 #(str (%1 1) "niebieski"))
21; => "Kolor niebieski"
;; wzorzec jako tekst, zastępnik jako tekst
(clojure.string/replace "Kolor czerwony" "czerwony" "niebieski")
; => "Kolor niebieski"
;; wzorzec jako tekst, zastępnik jako tekst
(clojure.string/replace "Litera A" \A \B)
; => "Litera B"
;; wzorzec jako wyrażenie regularne, zastępnik jako tekst
(clojure.string/replace "Kolor czerwony" #"\b(\w+ )(\w+)" "$1niebieski")
; => "Kolor niebieski"
;; wzorzec jako wyrażenie regularne, zastępnik jako funkcja
(clojure.string/replace "Kolor czerwony"
#"\b(\w+ )(\w+)"
#(str (%1 1) "niebieski"))
; => "Kolor niebieski"
Zwróćmy uwagę, że w ostatnim przykładzie używamy literału funkcji
anonimowej, w którym używamy funkcji str, aby złączyć dwa
łańcuchy znakowe: pierwszy będący wynikiem użycia formy przeszukiwania wektora
przekazanego jako pierwszy i jedyny argument, a drugi będący stałym
napisem. S-wyrażenie (%1 1) jest więc wywołaniem umieszczonego na pierwszej pozycji
wektora jako funkcji z argumentem 1, który oznacza drugi
element do pobrania. W naszym przypadku jest nim napis Kolor umieszczony
w wektorze właśnie na tej pozycji. Dla przypomnienia: pozycja wcześniejsza,
o indeksie 0, zawiera cały dopasowany łańcuch znakowy bez podziału na grupy.
Zamiana pierwszego, replace-first
Funkcja clojure.string/replace-first jest wariantem opisanej wyżej funkcji
clojure.string/replace, który działa tylko dla pierwszego napotkanego
wystąpienia podanego wzorca.
Pierwszym argumentem powinien być łańcuch znakowy, drugim wzorzec dopasowania (w postaci wyrażenia regularnego, tekstu bądź znaku), natomiast trzecim zastępnik umieszczany w miejscach pasujących do wzorca (tekst, znak bądź funkcja przekształcająca). Wartością zwracaną jest łańcuch tekstowy, w którym dopasowane do wzorca fragmenty (lub całość) zostały zastąpione odpowiednimi składnikami zastępnika (lub całą wartością zastępnika).
Użycie:
(clojure.string/replace-first łańcuch wzorzec zastępnik);
gdzie wzorzec to:
- łańcuch znakowy,
- pojedynczy znak,
- wyrażenie regularne;
a zastępnik to:
- łańcuch znakowy,
- pojedynczy znak,
- funkcja przekształcająca.
Możliwe są następujące kombinacje wzorców i zastępników:
- łańcuch znakowy i łańcuch znakowy,
- pojedynczy znak i pojedynczy znak,
- wyrażenie regularne i łańcuch znakowy,
- wyrażenie regularne i funkcja przekształcająca.
replace-first
(clojure.string/replace-first "zamieni miejscami słowa raz dwa trzy"
#"(\w+)(\s+)(\w+)" "$3$2$1")
(clojure.string/replace-first "zamieni miejscami słowa raz dwa trzy"
#"(\w+)(\s+)(\w+)" "$3$2$1")
Zauważmy, że trzy ostatnie słowa z podanego napisu nie zostały zastąpione.
Łączenie i dzielenie łańcuchów
Wydzielanie fragmentów, subs
Wydzielanie łańcucha o wskazanym położeniu początkowym i (opcjonalnie)
końcowym możliwe jest z użyciem funkcji subs.
Użycie:
(subs łańcuch początek koniec?)
Jako pierwszy argument funkcja przyjmuje łańcuch znakowy, a jako kolejny numer pozycji (licząc od 0), od której należy rozpocząć wydzielanie fragmentu. Opcjonalny trzeci argument może wyrażać pozycję końcową.
Funkcja zwraca łańcuch znakowy, a w razie przekroczenia zakresów lub podania błędnych zakresów pozycji generowany jest wyjątek.
subs
(subs "Baobab" 3) ; => "bab"
(subs "Baobab" 2 5) ; => "oba"
(subs "Baobab" 2 2) ; => ""
Łączenie łańcuchów, str
Łańcuchy znakowe mogą być łączone z użyciem funkcji str.
Użycie:
(str & tekst…).
Argumentami funkcji str mogą być łańcuchy znakowe, a zwracaną wartością będzie
efekt ich złączenia.
str do łączenia łańcuchów znakowych
(str "Pierwszy " "Drugi" " Trzeci")
; => "Pierwszy Drugi Trzeci"
(str "Pierwszy " "Drugi" " Trzeci")
; => "Pierwszy Drugi Trzeci"
Korzystając z funkcji str i traktując łańcuchy znakowe jak sekwencje
znakowe, możemy również dokonywać złączeń z zastosowaniem wybranego
łącznika (tekstu lub pojedynczego znaku):
1(apply str (interpose "--" ["raz" "dwa" "trzy"]))
2; => "raz--dwa--trzy"
3
4(apply str (interpose \- ["raz" "dwa" "trzy"]))
5; => "raz-dwa-trzy"
(apply str (interpose "--" ["raz" "dwa" "trzy"]))
; => "raz--dwa--trzy"
(apply str (interpose \- ["raz" "dwa" "trzy"]))
; => "raz-dwa-trzy"
Łączenie łańcuchów łącznikiem, join
Łączenie łańcuchów w jeden łańcuch z opcjonalnym użyciem podanego łącznika
w postaci łańcucha znakowego można uzyskać również z wykorzystaniem funkcji
clojure.string/join.
Użycie:
(clojure.string/join sekwencja),(clojure.string/join łącznik sekwencja).
Aby złączyć łańcuchy znakowe należy umieścić je w kolekcji o sekwencyjnym interfejsie dostępu lub po prostu wyrazić sekwencyjnie.
W wariancie jednoargumentowym należy przekazać sekwencję łańcuchów znakowych. W wariancie dwuargumentowym sekwencję przekazujemy jako drugi argument, a jako pierwszy łącznik, czyli element, który będzie użyty do złączenia elementów (może to być np. spacja wyrażona łańcuchem znakowym lub pojedynczym znakiem).
clojure.string/join
1(clojure.string/join " " ["raz" "dwa"])
2; => "raz dwa"
3
4(clojure.string/join "" ["Bao" "bab"])
5; => "Baobab"
6
7(clojure.string/join \space ["Bao" "bab"])
8; => "Bao bab"
9
10(clojure.string/join (seq '(B a o b a b)))
11; => "Baobab"
12
13(clojure.string/join ", " [1 2 3 4])
14; => "1, 2, 3, 4"
(clojure.string/join " " ["raz" "dwa"])
; => "raz dwa"
(clojure.string/join "" ["Bao" "bab"])
; => "Baobab"
(clojure.string/join \space ["Bao" "bab"])
; => "Bao bab"
(clojure.string/join (seq '(B a o b a b)))
; => "Baobab"
(clojure.string/join ", " [1 2 3 4])
; => "1, 2, 3, 4"
Dzielenie łańcuchów, split
Dzielenie łańcucha znakowego na części możliwe jest z użyciem wyrażenia
regularnego przekazywanego jako drugi argument funkcji clojure.string/split.
Użycie:
(clojure.string/split łańcuch wzorzec limit?).
Pierwszym argumentem funkcji powinien być poddawany podziałowi łańcuch, drugim wyrażenie regularne, a opcjonalnym trzecim limit, czyli maksymalna liczba elementów, które zostaną wydzielone.
Funkcja zwraca wektor, którego kolejne elementy są wydzielonymi fragmentami.
clojure.string/split
1(clojure.string/split "Baobab tu był." #" ")
2; => ["Baobab" "tu" "był."]
3
4(clojure.string/split "B123a09o2b1a55b322 1t4u 90b8y42ł3." #"\d+")
5; => ["B" "a" "o" "b" "a" "b" " " "t" "u " "b" "y" "ł" "."]
6
7(clojure.string/split "B123a09o2b1a55b322 1t4u 90b8y42ł3." #"\d+" 7)
8; => ["B" "a" "o" "b" "a" "b" " 1t4u 90b8y42ł3."]
(clojure.string/split "Baobab tu był." #" ")
; => ["Baobab" "tu" "był."]
(clojure.string/split "B123a09o2b1a55b322 1t4u 90b8y42ł3." #"\d+")
; => ["B" "a" "o" "b" "a" "b" " " "t" "u " "b" "y" "ł" "."]
(clojure.string/split "B123a09o2b1a55b322 1t4u 90b8y42ł3." #"\d+" 7)
; => ["B" "a" "o" "b" "a" "b" " 1t4u 90b8y42ł3."]
Dzielenie na nowych liniach, split-lines
Dzielenie łańcucha znakowego na części w miejscach występowania znaków nowej
linii można zrealizować z wykorzystaniem funkcji clojure.string/split-lines.
Użycie:
(clojure.string/split-lines łańcuch).
Funkcja przyjmuje jeden argument (łańcuch znakowy), a zwraca wektor, którego elementami są kolejne fragmenty, czyli linie tekstu źródłowego.
clojure.string/split-lines
(clojure.string/split-lines "Baobab\ntu\nbył.")
; => [ "Baobab" "tu" "był." ]
(clojure.string/split-lines "Baobab\ntu\nbył.")
; => [ "Baobab" "tu" "był." ]
Dzielenie sekwencyjne, re-seq
Podziału łańcuchów znakowych na mniejsze części można też dokonać w sposób
sekwencyjny z wykorzystaniem funkcji re-seq lub przez potraktowanie
łańcucha jako sekwencji znakowej.
1(def tekst "\n\nDzielenie na linie\nDruga")
2
3;; sekwencja na podstawie tekstu i wyrażenia regularnego
4
5(re-seq #"(?s)[^\n]+" tekst)
6; => ("Dzielenie na linie" "Druga")
7
8;; sekwencyjny podział na znaki i dzielenie na linie
9
10(->> tekst ; dla tekstu
11 (partition-by #{\newline}) ; sekwencje sekwencji znaków
12 (map #(apply str %)) ; - dla każdej łączymy znaki
13 (drop-while #(= \newline (first %))) ; - odrzucamy pocz. nowe linie
14 (take-nth 2)) ; - pobieramy co drugi
15; => ("Dzielenie na linie" "Druga")
(def tekst "\n\nDzielenie na linie\nDruga")
;; sekwencja na podstawie tekstu i wyrażenia regularnego
(re-seq #"(?s)[^\n]+" tekst)
; => ("Dzielenie na linie" "Druga")
;; sekwencyjny podział na znaki i dzielenie na linie
(->> tekst ; dla tekstu
(partition-by #{\newline}) ; sekwencje sekwencji znaków
(map #(apply str %)) ; - dla każdej łączymy znaki
(drop-while #(= \newline (first %))) ; - odrzucamy pocz. nowe linie
(take-nth 2)) ; - pobieramy co drugi
; => ("Dzielenie na linie" "Druga")
Ostatni przykład wymaga kilku wyjaśnień, bo zawiera konstrukcje, które nie były do tej pory używane. Wybiegamy nim nieco w przyszłość, ponieważ nie poznaliśmy jeszcze sekwencji i funkcji specyficznych dla nich, dlatego możemy się umówić, że nie trzeba dobrze go rozumieć, ale warto do niego wrócić po zapoznaniu się z kolejnymi rozdziałami.
W linii nr 5 widzimy ciekawe makro oznaczone symbolem strzałki o podwójnym
grocie (->>). Dzięki niemu można stwarzać łańcuchy przetwarzania i unikać
„piętrowych” wyrażeń. Jest to lukier składniowy, dzięki któremu kod programu
staje się bardziej czytelny.
Makro to „przewleka” wartość podanego wyrażenia przez wszystkie podane dalej formy w taki sposób, że zostaje ono najpierw dołączone do pierwszej listy jako jej ostatni argument, a następnie rezultat obliczenia wartości pierwszej listy jest podstawiany jako ostatni argument drugiej podanej listy itd. Efekt działania widać dobrze na poniższym przykładzie.
->>
1;; wersja bez makra ->>
2
3(vec (map inc (take-nth 3 (vector 1 2 3 4 5 6 7 8 9 10))))
4; => [2 5 8 11]
5
6;; wersja z makrem ->>
7
8(->> (vector 1 2 3 4 5 6 7 8 9 10)
9 (map inc)
10 (take-nth 3)
11 (vec))
12; => [2 5 8 11]
;; wersja bez makra ->>
(vec (map inc (take-nth 3 (vector 1 2 3 4 5 6 7 8 9 10))))
; => [2 5 8 11]
;; wersja z makrem ->>
(->> (vector 1 2 3 4 5 6 7 8 9 10)
(map inc)
(take-nth 3)
(vec))
; => [2 5 8 11]
Widzimy, że przewlekanie wartości końcowej przez kolejne formy może być dobrym sposobem reprezentowania złożonych, kaskadowych wyrażeń o większej liczbie operacji.
Wiemy już w jaki sposób zorganizowane są kolejne etapy filtrowania danych w naszym poprzednim przykładzie. Spróbujmy rozpisać wykonywane operacje i zobaczyć co się dzieje:
-
tekst:"\n\nDzielenie na linie\nDruga""\n\nDzielenie na linie\nDruga" -
Po
(partition-by #{\newline}):( (\newline \newline) (\D \z \i \e \l \e \n \i \e \space \n \a \space \l \i \n \i \e) (\newline) (\D \r \u \g \a) )( (\newline \newline) (\D \z \i \e \l \e \n \i \e \space \n \a \space \l \i \n \i \e) (\newline) (\D \r \u \g \a) )Funkcja
partition-bydzieli sekwencję na wiele sekwencji, używając funkcji podanej jako pierwszy argument. W naszym przypadku dokonany został podział sekwencji znaków pochodzących ztekst(dodanego przez makro) na 4 sekwencje. Operacja używana do przeprowadzenia podziału to zbiór, który może być nie tylko strukturą danych, ale również funkcją.Wywołany w formie funkcji zbiór działa w ten sposób, że zwracana jest wartość elementu, który podano jako argument, jeżeli ten element znajduje się w zbiorze; gdy go brak, zwracana jest wartość
nil. W tym przypadku jedynym elementem zbioru jest znak nowej linii, więc korzystająca z takiej funkcji porównującej funkcjapartition-bypodzieli sekwencję w miejscach, gdzie elementami są znaki nowej linii (każdy element sekwencji będzie wcześniej porównany z użyciem funkcji zbioru). -
Po
(map #(apply str %)):("\n\n" "Dzielenie na linie" "\n" "Druga")("\n\n" "Dzielenie na linie" "\n" "Druga")Funkcja
mapprzyjmie sekwencję sekwencji i dla każdej z tych pierwszych (czyli dla wydzielonych linii i znaków nowej linii przedstawionych jako sekwencje znakowe) wywoła funkcjęstr, przekazując wszystkie elementy danej sekwencji jako argumenty. Zostaną one zamienione na łańcuchy znakowe. -
Po
(drop-while #(= \newline (first %))):("Dzielenie na linie" "\n" "Druga")("Dzielenie na linie" "\n" "Druga")Funkcja
drop-whilesprawia, że usunięty zostanie każdy element, który spełni warunek podany jako anonimowa funkcja. Ta funkcja z kolei sprawdza, czy pierwszy znak napisu jest nową linią. Funkcja ta działa tylko dla pierwszych elementów, dopóki spełniają one warunek. Używamy jej, aby wyeliminować wiodące napisy, które składają się wyłącznie ze znaków nowej linii. -
Po
(take-nth 2):("Dzielenie na linie" "Druga")("Dzielenie na linie" "Druga")Ostatnim filtrem stworzonego przez nas łańcucha przetwarzania jest funkcja
take-nth, która pobiera w tym przypadku co drugi element sekwencji. Jest to konieczne, ponieważpartition-bypodzieliła sekwencję znaków, ale pozostawiła w niej znaki nowej linii, na bazie których dzielenie było wykonywane (a tych nie potrzebujemy). Widzimy przy okazji dlaczego istotne było usunięcie wiodących łańcuchów znakowych, które na początku zawierają znaki nowej linii. Gdyby nie to, nie moglibyśmy trafić z filtrem, który „w ciemno” eliminuje co drugi element, spodziewając się tam właśnie tych zbędnych znaków (na tym etapie zmienionych już w napisy). Oczywiście moglibyśmy przeszukać sekwencję i odfiltrować elementy, które zaczynają się znakami nowej linii, ale byłoby to mniej wydajne od usuwania parzystych elementów.
Predykaty łańcuchowe
Testowanie typu, string?
Sprawdzania czy podany argument jest łańcuchem znakowym można dokonać
z wykorzystaniem funkcji string?.
Użycie:
(string? wartość).
Pierwszym argumentem funkcji powinna być wartość. Jeżeli będzie ona łańcuchem
znakowym, zwrócona zostanie wartość true, a w przeciwnym razie wartość false.
string?
(string? "Baobab") ; => true
(string? 7) ; => false
(string? "Baobab") ; => true
(string? 7) ; => false
Sprawdzanie czy jałowy, blank?
Sprawdzanie czy łańcuch znakowy jest jałowy (jest wartością nil, ma zerową długość
lub składa się z samych białych znaków) możliwe jest z użyciem funkcji
clojure.string/blank?.
Użycie:
(clojure.string/blank? łańcuch).
Funkcja przyjmuje łańcuch znakowy, a zwraca true, jeżeli łańcuch jest czysty,
a false w przeciwnym razie.
clojure.string/blank?
1(clojure.string/blank? "") ; => true
2(clojure.string/blank? " ") ; => true
3(clojure.string/blank? nil) ; => true
4(clojure.string/blank? "Baobab") ; => false
(clojure.string/blank? "") ; => true
(clojure.string/blank? " ") ; => true
(clojure.string/blank? nil) ; => true
(clojure.string/blank? "Baobab") ; => false
Sprawdzanie czy pusty, empty?
Sprawdzić czy łańcuch znakowy jest pusty możemy z wykorzystaniem funkcji
empty?. Traktuje ona jednak łańcuchy w sposób bardziej uogólniony i przez to nie
wykrywa specyficznych warunków, które mogłyby świadczyć o tym, że w sensie
informacyjnym mamy do czynienia z brakiem zapisu tekstowego.
Użycie:
(empty? łańcuch).
Funkcja zwraca true tylko wtedy, gdy przekazany argument ma wartość nil lub jest
łańcuchem znakowym o zerowej długości, a false w przeciwnym razie.
empty?
(empty? "")
; => true
(empty? "")
; => true
Wysyłanie łańcuchów
Łańcuchy do wejścia, with-in-str
Łańcuchy znakowe można wysyłać do strumienia wejściowego (zazwyczaj skojarzonego
z deskryptorem standardowego wejścia). Służy do tego makro with-in-str.
Użycie:
(with-in-str łańcuch & wyrażenie…)
Makro przyjmuje łańcuch znakowy i zestaw wyrażeń, które zostaną zrealizowane (obliczone). Jeżeli któreś z nich wygeneruje efekt uboczny w postaci odczytu ze standardowego strumienia wejściowego, dane z łańcucha będą do niego dostarczone.
Dzięki with-in-str możemy emulować interakcję z użytkownikiem bądź potokiem wejścia
z innego polecenia.
with-in-str
(with-in-str "Baobab" (read-line))
; => "Baobab"
(with-in-str "Baobab" (read-line))
; => "Baobab"
Kolekcje i sekwencje
Kolekcja to abstrakcyjna klasa złożonych struktur danych, które służą do przechowywania danych wieloelementowych. Z kolei sekwencja to w działaniu przypominający iteratory interfejs dostępu do wielu obecnych w Clojure kolekcji. Różnica w stosunku do iteratorów polega jednak na tym, że sekwencje nie pozwalają na mutacje danych.
Obu wspomnianym składnikom języka poświęcone są kolejne części serii „Poczytaj mi Clojure”: