
Sekwencje to przypominający iteratory mechanizm dostępu do elementów kolekcji. Są niemutowalnymi, abstrakcyjnymi listami, dzięki którym możliwe jest następcze operowanie na zbiorach danych. W programach pisanych w Clojure często korzystamy z sekwencji.
Sekwencje
Sekwencja (ang. sequence, skr. seq) jest specjalnym, abstrakcyjnym rodzajem listy, która pozwala na następczy dostęp do elementów powiązanej z nią struktury danych (np. kolekcji) lub operacji generującej kolejne wartości (np. funkcji).
Następczy sposób dostępu oznacza, że istnieją specyficzne dla sekwencji funkcje, pozwalające na odczyt wartości kolejnych elementów w liniowy sposób (jeden element za każdym razem).
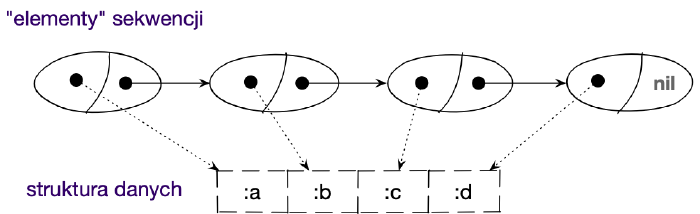
Sekwencja jako interfejs następczego dostępu do kolekcji w Clojure
W Clojure sekwencja nie zawiera konkretnych elementów, lecz jest interfejsem dostępu do wartości, które istnieją w jakiejś kolekcji lub są generowane przez jakąś funkcję.
Usłyszymy czasem, że kolekcje mogą być również sekwencjami. Oznacza to, że
implementują interfejs ISeq, który wymaga, aby możliwe było
odczytywanie kolejnych elementów i dodawanie nowych (wytwarzając nowy początek
sekwencji). Znajdziemy też takie kolekcje, którym brak jest sekwencyjnego interfejsu,
lecz mogą być o niego wzbogacone przez zastosowanie odpowiedniej funkcji, której
zadaniem jest zbudowanie sekwencji na bazie kolekcji – powinny być wtedy oznaczone
interfejsem Sequential.
Zaznajomieni z paradygmatem imperatywnym zauważą, że dostęp sekwencyjny przypomina
korzystanie z pętli typu foreach czy while, znanych z innych języków
programowania. Z kolei programiści obiektowi mogą zainteresować się sekwencjami,
rozwiązując problemy, w których skorzystaliby z iteratorów
(ang. iterators). Warto pamiętać, że sekwencje różnią się od nich ważnym szczegółem:
nie występuje w nich żaden mutowalny element, który służyłby do zapamiętywania
bieżącej pozycji (tzw. kursora).
Poruszanie się po kolejnych elementach sekwencji polega na dwóch operacjach:
- wyodrębnianiu wartości pierwszych elementów,
- tworzeniu sekwencji pochodnych bez pierwszego elementu.
Dzięki temu sekwencje w Clojure są bezpieczne w kontekście przetwarzania współbieżnego.
Sekwencyjny interfejs dostępu może być również użyty w odniesieniu do wbudowanych, mutowalnych tablic Javy.
Komórki cons
Obeznani z innymi dialektami języka Lisp zauważą związek między sekwencyjnym sposobem
dostępu a formą cons i jej produktem: jednokierunkową listą. To prawda, elementy
sekwencji przypominają znane z Lispu komórki cons (składniki list), jednak
w Clojure – w którym również znajdziemy funkcję cons i typ danych
clojure.lang.Cons – nie są one jedynym sposobem tworzenia sekwencji. Poza tym
będziemy mieć do czynienia z nieco inną implementacją i innymi operacjami, mimo
podobnego nazewnictwa.
Po pierwsze sekwencje znane z Clojure nie są konkretnym typem danych, lecz określonym
zestawem operacji, które możemy wykonywać na rozmaitych kolekcjach (nie tylko na
obiektach typu Cons), aby uzyskiwać dostęp do kolejnych elementów i dołączać nowe
(rozszerzając sekwencje). Po wtóre nawet w przypadku obiektów typu Cons, dla
których sekwencyjny interfejs jest podstawową metodą uzyskiwania dostępu
do elementów, mamy do czynienia z istotnymi różnicami w stosunku do popularnych
dialektów Lispu.
Lispowe komórki cons składają się z dwóch slotów (lewego car i prawego
cdr). Umieszczając w nich wartości i odwołania do innych komórek, możemy
konstruować jednokierunkowe listy; wprowadzając tylko wartości, jesteśmy w stanie
wyrażać powiązane logicznie pary elementów; a przypisując do obu slotów dane listowe,
wyrażać struktury wielowymiarowe.
W Clojure również istnieje funkcja cons, jednak nie pozwala ona na grupowanie
dowolnych wartości, lecz jest sposobem dołączania elementów do czoła
sekwencji. Efektem jej działania będzie utworzenie obiektu typu Cons, jednak
zamiast dwóch mutowalnych przestrzeni znajdziemy w nim dwa hermetyzowane odwołania:
do dodawanej wartości i do reszty sekwencji. Dostęp do wartości elementu, jak i do
pozostałej części sekwencji, będzie możliwy wyłącznie z użyciem odpowiednich funkcji.

Uproszczona wewnętrzna budowa obiektu typu clojure.lang.Cons
Obiekty typu Cons są zarówno konkretnym budulcem jednokierunkowych list, jak
i elementami abstrakcyjnych sekwencji (z uwagi na specyficzny, uproszczony
interfejs). Inne rodzaje kolekcji mogą mieć sekwencyjne reprezentacje wykorzystujące
zupełnie inne typy danych.
Sekwencyjny interfejs
Żeby dana kolekcja mogła być użytkowana w sekwencyjny sposób, musi obsługiwać trzy podstawowe funkcje, które dadzą się wywołać na jej obiekcie:
first– służącą do uzyskiwania wartości pierwszego elementu,rest– służącą do uzyskiwania sekwencji bez pierwszego elementu,cons– służącą do dodawania nowego elementu do czoła sekwencji.
Spójrzmy:
1(type (cons 1 [2 3]))
2; => clojure.lang.Cons
3
4(rest (cons 1 [2 3]))
5; => (2 3)
6
7(type (rest (cons 1 [2 3])))
8; => clojure.lang.PersistentVector$ChunkedSeq
(type (cons 1 [2 3]))
; => clojure.lang.Cons
(rest (cons 1 [2 3]))
; => (2 3)
(type (rest (cons 1 [2 3])))
; => clojure.lang.PersistentVector$ChunkedSeq
Powyżej widzimy, że funkcja cons dołączyła do wektora [1 2] nowy element, jednak
rezultatem jej działania nie był nowy wektor, ale obiekt Cons wyposażony
w sekwencyjny interfejs. Następnie użyliśmy funkcji rest (w linii nr 4), aby pobrać
wszystkie elementy sekwencji poza pierwszym. W linii nr 8 możemy zauważyć ciekawą
rzecz, która ukazuje różnicę w stosunku do klasycznych Lispów: wydzieloną resztą
wcale nie jest cały wektor, do którego wcześniej coś dołączyliśmy z użyciem cons,
lecz obiekt typu PersistentVector$ChunkedSeq, czyli automatycznie stworzona przez
wspomnianą funkcję sekwencja reprezentująca elementy źródłowego wektora. Doszło więc
do wyabstrahowania struktury kolekcji i utworzenia jej sekwencyjnej reprezentacji,
a następnie do niej dołączona została nową wartość (z użyciem obiektu typu Cons).
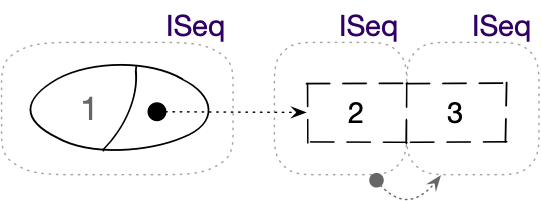
Traktowanie sekwencyjnej kolekcji jak sekwencji przez wywołanie funkcji cons: elementami sekwencji stają się wartości z wektora i wartość przypisana do komórki Cons
Sekwencyjną reprezentację kolekcji jesteśmy w stanie uzyskać również wprost,
korzystając z funkcji seq w odniesieniu do takich rodzajów danych, dla których
zdefiniowano odpowiednie warianty wymaganych funkcji:
1(seq [2 3])
2; => (2 3)
3
4(type (seq [2 3]))
5; => clojure.lang.PersistentVector$ChunkedSeq
6
7(type (seq {1 2 3 4}))
8; => clojure.lang.PersistentArrayMap$Seq
9
10(type (seq '(1 2 3)))
11; => clojure.lang.PersistentList
12
13(type (seq (cons :a '(1 2 3))))
14; => clojure.lang.Cons
(seq [2 3])
; => (2 3)
(type (seq [2 3]))
; => clojure.lang.PersistentVector$ChunkedSeq
(type (seq {1 2 3 4}))
; => clojure.lang.PersistentArrayMap$Seq
(type (seq '(1 2 3)))
; => clojure.lang.PersistentList
(type (seq (cons :a '(1 2 3))))
; => clojure.lang.Cons
Zauważmy, że w dwóch ostatnich przykładach funkcja seq zwraca obiekty tych samych
typów, co wartości przekazanych argumentów. Oznacza to, że zarówno lista
(PersistentList), jak i obiekt Cons są wyposażone w sekwencyjny interfejs i nie
ma potrzeby wytwarzać konstrukcji pośrednich, aby wyrażać je sekwencyjnie.
W Clojure korzystanie z seq jest również idiomatycznym sposobem na sprawdzanie, czy
dana kolekcja jest niepustą sekwencją. Funkcja ta zwraca nil dla kolekcji
pustych lub wartości nieustalonych nil.
Sekwencje leniwe
Sekwencyjne reprezentacje struktur danych (bądź szeregów zależnych od siebie wartości) mogą być obsługiwane w sposób zwłoczny (ang. delayed), zwany potocznie leniwym (ang. lazy).
Wyobraźmy sobie, że mamy wektor [1 2 3 4] i na bazie kolejnych umieszczonych w nim
wartości chcemy wytworzyć sekwencję, która będzie rezultatem przekształcenia każdego
elementu przez wielokrotne i czasochłonne działanie arytmetyczne.
Moglibyśmy stworzyć nowy wektor, którego elementy będą rezultatami wywołań operacji
na pierwszym, ale wtedy poza wytworzeniem dodatkowej struktury w pamięci
dokonalibyśmy kosztownej operacji wyliczania wszystkich wartości. Moglibyśmy więc
pokusić się o stworzenie sekwencji obiektów Cons na bazie wektora, przy czym każdy
jej element byłby odpowiednio przekształcany podczas tworzenia:
1(defn trudna-operacja [x] (if (> x 1000) x (* x x x x)))
2
3(defn sekwencjonuj
4 [coll]
5 (if (seq coll)
6 (cons (trudna-operacja (first coll)) (sekwencjonuj (next coll)))))
7
8(sekwencjonuj [1 2 3 4])
9; => (1 16 81 256)
(defn trudna-operacja [x] (if (> x 1000) x (* x x x x)))
(defn sekwencjonuj
[coll]
(if (seq coll)
(cons (trudna-operacja (first coll)) (sekwencjonuj (next coll)))))
(sekwencjonuj [1 2 3 4])
; => (1 16 81 256)
Efektem pracy rekurencyjnej funkcji sekwencjonuj jest szereg komórek typu
clojure.lang.Cons, które zawierają rezultaty przeprowadzonych operacji. Warto
zauważyć, że warunkiem zakończenia rekurencji jest w tym przypadku moment, gdy
przekazana jako argument kolekcja będzie pusta lub będzie wartością nieustaloną
nil. Dojdzie do tego zawsze po przetworzeniu ostatniego elementu, ponieważ
wywołanie (next coll) zwróci wtedy nil.
Przedstawiony kod można jeszcze optymalizować, na przykład korzystając z rekurencji
ogonowej, aby nie przepełniać stosu. Najistotniejsze
w przykładzie jest jednak to, że stwarzamy sekwencję obiektów Cons i obliczamy
umieszczane w nich wartości dla każdego elementu podanego wektora. A gdyby wektor był
bardzo długi, zaś obliczenia jeszcze bardziej skomplikowane? A może zamiast wektora
mielibyśmy inną sekwencję, która jest nieskończona? Doszłoby wtedy do zawieszenia
pracy programu, aż do przepełnienia dostępnej mu pamięci! Nawet wtedy, gdy
chcielibyśmy faktycznie skorzystać tylko z kilku pierwszych elementów.
W sytuacjach wspomnianych wyżej na ratunek przychodzą nam tzw. sekwencje wartościowane leniwie (ang. lazily evaluated sequences), zwane też skrótowo leniwymi sekwencjami (ang. lazy sequences). W ich przypadku wartości kolejnych elementów są obliczane dopiero wtedy, kiedy pojawiają się żądania ich odczytu. W ten sposób możemy konstruować szeregi zależnych od siebie wartości, a dopiero podczas „konsumowania” rezultatów wybierać, jaka ich liczba jest faktycznie potrzebna i powinna zostać wyliczona przez odpowiednią funkcję w roli generatora.
W Clojure wiele funkcji operujących na danych sekwencyjnych (w tym na wbudowanych
kolekcjach) działa w sposób zwłoczny i zwraca szeregi wyników w postaci zawieszonych
operacji zamkniętych w obiektach typu clojure.lang.LazySeq. Egzemplarze tej klasy
są podstawowym budulcem leniwych sekwencji i służą do kapsułkowania kolejnych
elementów w taki sposób, że tylko podczas pierwszego odczytu wartości każdego z nich
dochodzi do wywołania obliczającej ją funkcji, zaś kolejne odwołania (w odniesieniu
do już raz odczytanych elementów) czynią użytek z wartości
zapamiętanej.
Leniwe sekwencje pozwalają zarządzać procesem odczytywania szeregów danych, które cechuje duża złożoność obliczeniowa bądź duży rozmiar (nawet większy niż dostępna pamięć operacyjna). W Clojure przydają się one do kaskadowego filtrowania danych, obsługi parserów czy przetwarzania strumieni (dostęp do systemu plikowego i sieci, obróbka multimediów itp.).
Warto zaznaczyć, że leniwe sekwencje nie muszą odnosić się do kolekcji. Ich elementy
są stwarzane podczas odczytywania, a odpowiedzialna jest za to odpowiednia funkcja
generująca, która powinna zwracać obiekt implementujący interfejs ISeq, czyli
np. komórkę Cons lub kolejny element leniwej sekwencji (LazySeq). Owa funkcja
będzie składała się z wyrażeń umieszczonych w ciele makra lazy-seq omówionego
niżej.
Każde wywołanie funkcji rest (bądź next) na obiekcie leniwej sekwencji sprawi,
że zostanie uruchomiona funkcja obliczająca wartość czołowego elementu pozostałej
części sekwencji, aby sprawdzić, czy element ten dodatkowo odwołuje się do dalszych,
czy może jest ostatnim w szeregu.
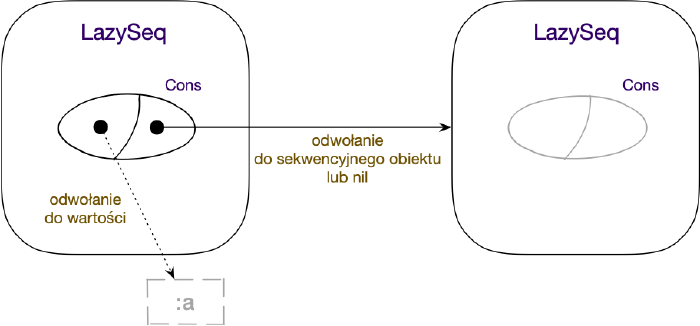
Generowanie komórek Cons przez funkcje wywoływane na LazySeq
Często spotykaną strategią jest takie projektowanie funkcji generujących leniwe
sekwencje, że rezultatami ich pracy będą komórki Cons. Spójrzmy:
1(defn trudna-operacja [x] (if (> x 1000) x (* x x x x)))
2
3(defn sekwencjonuj-leniwie
4 [coll]
5 (if (seq coll)
6 (lazy-seq
7 (cons (trudna-operacja (first coll))
8 (sekwencjonuj-leniwie (next coll))))))
9
10(sekwencjonuj-leniwie [1 2 3 4])
11; => (1 16 81 256)
(defn trudna-operacja [x] (if (> x 1000) x (* x x x x)))
(defn sekwencjonuj-leniwie
[coll]
(if (seq coll)
(lazy-seq
(cons (trudna-operacja (first coll))
(sekwencjonuj-leniwie (next coll))))))
(sekwencjonuj-leniwie [1 2 3 4])
; => (1 16 81 256)
W linii nr 6 wywołanie cons zostało umieszczone w makrze lazy-seq, które zamyka
całe wyrażenie w obiekcie clojure.lang.LazySeq i zmienia je w funkcyjny obiekt
przeznaczony do uruchomienia w przyszłości. Wartościowanie przekazanego wyrażenia
będzie przeprowadzone dopiero, gdy pojawi się żądanie odczytu elementu. Działa to tak
samo, jak obiekty typu referencyjnego Delay, który zostanie omówiony
w dalszych częściach podręcznika.
Zauważmy, że nie musimy tu korzystać z rekurencji ogonowej,
ponieważ wprowadzenie makra lazy-seq sprawia, że wewnętrznie mamy do czynienia
z mechanizmem rekurencji pośredniej, w którym kolejne
elementy nie powstają w wyniku rekurencyjnego wywołania funkcji generującej (tu
sekwencjonuj-leniwie), lecz funkcja ta zwracana jest jako wartość (obiekt typu
funkcyjnego). Mechanizmy języka nie muszą więc utrzymywać stosu ramek z adresami
powrotnymi dla tej konstrukcji.
Zaobserwujmy w jaki sposób zachowają się stworzone przez nas funkcje z dwóch
wcześniejszych przykładów, gdy wywołamy je dla bardzo dużej liczby
elementów. Pomożemy sobie funkcją range, która tworzy sekwencję liczb całkowitych
z podanego przedziału – będą to nasze źródłowe elementy:
1(last (sekwencjonuj (range 0 10000000)))
2; >> Execution error (StackOverflowError) at user/sekwencjonuj (REPL:1).
3
4(last (sekwencjonuj-leniwie (range 0 10000000)))
5; => 9999999
(last (sekwencjonuj (range 0 10000000)))
; >> Execution error (StackOverflowError) at user/sekwencjonuj (REPL:1).
(last (sekwencjonuj-leniwie (range 0 10000000)))
; => 9999999
Próba pobrania ostatniego elementu sekwencji tworzonej przez funkcję sekwencjonuj
zakończyła się zgłoszeniem wyjątku spowodowanego zbyt dużą liczbą ramek odłożonych na
stos. Ramki te zawierają miejsca w kodzie wywoływanych rekurencyjnie funkcji,
do których należy powrócić, gdy nastąpią zakończenia poprzednich wywołań.
Problemu tego nie ma z sekwencjonuj-leniwie, ponieważ tam nie dochodzi
do rekurencyjnego wywołania tej samej funkcji, lecz do natychmiastowego zwracania
przez lazy-seq funkcyjnego obiektu (będącego wartością stałą). Zwróconą funkcję
można wywołać, aby poznać zawartość elementu sekwencji, na którą składają się:
wartość bieżącego elementu i odwołanie do dalszej części sekwencji (kolejnego
elementu, czyli obiektu implementującego ISeq).
Jak mogliśmy zaobserwować we wcześniej zaprezentowanych przykładach, często w Clojure
będziemy mieli do czynienia z sytuacją, w której obiekt leniwej sekwencji (LazySeq)
zawiera odniesienie do tworzonego przez jej funkcję generującą obiektu Cons
(implementującego interfejs ISeq), który z kolei będzie przechowywał odwołanie do
kolejnego obiektu typu LazySeq. Powstanie więc pewnego rodzaju łańcuch
naprzemiennych odwołań (LazySeq → Cons → LazySeq → Cons itd.). W praktyce
będzie zmieniał się on w łańcuch Cons → Cons, gdy sekwencja będzie realizowana.
1(defn potęga [x] ; Definiujemy funkcję,
2 (* x x)) ; która potęguje podaną liczbę.
3
4(defn potęgi [x] ; Definiujemy funkcję,
5 (lazy-seq ; która zwraca leniwą sekwencję, gdzie
6 (cons ; generatorem jest funkcja tworząca obiekt Cons
7 (potęga x) ; · złożony z rezultatu potęgowania (lewy slot)
8 (potęgi ; · i z sekwencji będącej rezultatem
9 (inc x))))) ; rekurencyjnego wywołania dla x+1 (prawy slot).
10
11(take 3 (potęgi 1)) ; Pobieramy pierwsze 3 elementy.
12; => (1 4 9)
(defn potęga [x] ; Definiujemy funkcję,
(* x x)) ; która potęguje podaną liczbę.
(defn potęgi [x] ; Definiujemy funkcję,
(lazy-seq ; która zwraca leniwą sekwencję, gdzie
(cons ; generatorem jest funkcja tworząca obiekt Cons
(potęga x) ; · złożony z rezultatu potęgowania (lewy slot)
(potęgi ; · i z sekwencji będącej rezultatem
(inc x))))) ; rekurencyjnego wywołania dla x+1 (prawy slot).
(take 3 (potęgi 1)) ; Pobieramy pierwsze 3 elementy.
; => (1 4 9)
Sekwencje nieskończone
Dzięki leniwym sekwencjom możemy budować generatory nieskończonej liczby wartości, na przykład kolejnych liczb całkowitych:
1(defn kolejne
2 [start]
3 (lazy-seq
4 (cons start (kolejne (inc start)))))
5
6(nth (kolejne 0) 1000000)
7; => 1000000
(defn kolejne
[start]
(lazy-seq
(cons start (kolejne (inc start)))))
(nth (kolejne 0) 1000000)
; => 1000000
Powyższy zapis jest poprawny, lecz mało idiomatyczny. W Clojure do konstruowania
szeregu zależnych od siebie wartości reprezentowanych leniwą sekwencją najlepiej użyć
funkcji iterate:
(defn kolejne
[start]
(iterate inc start))
(nth (kolejne 0) 1000000)
; => 1000000
Retencja czołowa
Warto wiedzieć, że jeżeli czoło (ang. head) sekwencji, czyli jej pierwsza komórka, zostanie powiązane z jakimś obiektem referencyjnym (np. zmienną globalną), to z powodu wzajemnej zależności wszystkich kolejnych elementów rezultaty przechowywane w podręcznych buforach nie zostaną zwolnione przez Garbage Collectora. Stanie się tak nawet wtedy, gdy mechanizmy optymalizujące rozpoznają, że nie wystąpi już potrzeba odwoływania się do żadnego z elementów. Mówimy wtedy o przytrzymywaniu czoła sekwencji (ang. holding the head of the sequence), zwanego też retencją czołową (ang. head retention). Prowadzi ono do zachowania całej przeliczonej sekwencji w pamięci i może prowadzić do zajmowania przez program zbyt dużej przestrzeni RAM-u.
Niektóre z funkcji operujących na sekwencjach mogą korzystać z retencji czołowej,
żeby w pamięci pozostawały zbuforowane wartości elementów do ponownego użycia. To,
czy jest to pożądane, zależy od konkretnego zastosowania. Są na przykład takie
sekwencje, których wartości elementów nie powinny być zapamiętywane, ponieważ ich
liczba może doprowadzić do zajęcia całej dostępnej pamięci. Są też takie, które
chcemy buforować, ale tylko w określonym zasięgu leksykalnym – możemy wtedy np. użyć
let i powiązać sekwencję z jakimś symbolem na czas trwania obliczeń.
W takim przypadku cała sekwencja będzie zapisana w pamięci, ale tylko przez określony
leksykalnym zasięgiem czas wartościowania formy let (lub podobnej). Wybór
konkretnej strategii podyktowany będzie aktualną potrzebą.
Sekwencje pokawałkowane
Niektóre operacje tworzenia leniwych sekwencji zwracają rezultaty podzielone na pewne logiczne części obliczeniowe zwane kawałkami (ang. chunks). Sekwencje takie nazywamy wtedy pokawałkowanymi (ang. chunked). Wspomnianymi częściami są grupy kolejnych elementów, których wartości generowane będą dla wszystkich w obrębie zestawu, gdy tylko wystąpi żądanie odczytu pierwszego z nich. Można powiedzieć, że dochodzi wtedy do zachłannego (ang. eager) wartościowania określonej liczby elementów sekwencji.
Przyjęty mechanizm jest optymalizacją wprowadzoną przez twórców języka, którzy zauważyli, że statystycznie większość leniwych sekwencji, gdy jest wartościowana w umiarkowanie zachłanny sposób, odznacza się lepszą wydajnością niż sekwencje o całkowicie zwłocznej ewaluacji elementów. Wynika to z faktu, że można oszczędzić czas obliczeniowy procesora, eliminując niektóre operacje wykonywane na początku i na końcu generowania każdego elementu z osobna.
Dostęp do pokawałkowanych sekwencji jest taki sam, jak do zwyczajnych sekwencji. Mamy
do dyspozycji funkcje first i rest (względnie next) do odczytywania, a także
cons służącą do dołączania nowych elementów. Zachowanie tych operacji również jest
podobne, z tą różnicą, że podczas odwoływania się do wartości elementów generowana
będzie z wyprzedzeniem pewna liczba elementów następnych. Przypomina to buforowanie
danych wejściowych (np. odczytywanych z pliku czy gniazda sieciowego), gdzie dochodzi
do faktycznego wczytania przez system operacyjny większej ich ilości, niż potrzebuje
w danym momencie funkcja użytkownika.
Zilustrować zachowanie pokawałkowanych sekwencji możemy konstruując generator elementów leniwej sekwencji z efektem ubocznym w postaci podprogramu wypisującego znaki na standardowe urządzenie wyjściowe. Będziemy wtedy mogli zaobserwować liczbę wywołań generatora. Stwórzmy prostą funkcję, która tworzy ciąg arytmetyczny o różnicy równej 1, a dodatkowo wyświetla znak asterysku podczas obliczania wartości elementu:
1(defn kolejne
2 [start]
3 (lazy-seq
4 (print "*")
5 (cons start (kolejne (inc start)))))
6
7(take 5 (kolejne 0))
8; >> (**0 *1 *2 *3 4)
(defn kolejne
[start]
(lazy-seq
(print "*")
(cons start (kolejne (inc start)))))
(take 5 (kolejne 0))
; >> (**0 *1 *2 *3 4)
Widzimy, że liczba żądanych elementów (5) jest równa liczbie wywołań funkcji
generującej (zawartej w ciele makra lazy-seq). Nie mamy więc do czynienia
z zachłannym wartościowaniem fragmentów, lecz w pełni leniwą sekwencją.
Spróbujmy teraz użyć wbudowanej funkcji range, która działa bardzo
podobnie do naszej kolejne, lecz gdy podano górny zakres, tworzy sekwencję
pokawałkowaną. Ponieważ nie możemy przekazać żadnego operatora do range, a chcemy
wprowadzić naszą funkcję wyświetlającą znak gwiazdki, więc posłużymy się pewną
sztuczką i użyjemy funkcji wyższego rzędu map, która służy
do przekształcania elementów sekwencji. Jako jej operator podamy anonimową funkcję,
zwracającą wartość przekazanego argumentu:
1(take 5 (map (fn [n] (print "*") n) (range 1000)))
2; >> (********************************0 1 2 3 4)
(take 5 (map (fn [n] (print "*") n) (range 1000)))
; >> (********************************0 1 2 3 4)
Widzimy, że nawet gdy chcieliśmy pobrać tylko 5 pierwszych elementów (z użyciem
take), pojawiły się 32 znaki asterysku. Oznacza to, że funkcja generująca wewnątrz
range została wywołana 32 razy i właśnie tyleż rezultatów zostało spamiętanych
do ewentualnego użycia w przyszłości. Gdybyśmy powiązali pierwotną sekwencję z jakimś
symbolem, to dzięki zjawisku przytrzymywania jej czoła
(retencji czołowej) moglibyśmy skorzystać z już wytworzonych
wartości elementów:
1;; Czoło sekwencji powiązane ze zmienną globalną,
2;; a zawartość pochodzi z rezultatu funkcji range
3;; przekształconego z użyciem map i anonimowej
4;; funkcji w roli transformatora wartości elementów.
5
6(def siup
7 (map (fn [n] (print "*") n) (range 1000)))
8
9;; Pierwsze pobranie pięciu elementów
10;; – generowanych i spamiętywanych jest 32.
11
12(take 5 siup)
13; >> (********************************0 1 2 3 4)
14
15;; Drugie pobranie tych samych elementów
16;; – nie są już generowane, bo zostały spamiętane.
17
18(take 5 siup)
19; => (0 1 2 3 4)
20
21;; Pobranie dziesięciu pierwszych
22;; – również nie są generowane, bo spamiętano więcej.
23
24(take 10 siup)
25; => (0 1 2 3 4 5 6 7 8 9)
26
27;; Pobranie elementu 35.
28;; - kolejny 32-elementowy kawałek będzie generowany.
29
30(nth siup 35)
31; >> ********************************35
;; Czoło sekwencji powiązane ze zmienną globalną,
;; a zawartość pochodzi z rezultatu funkcji range
;; przekształconego z użyciem map i anonimowej
;; funkcji w roli transformatora wartości elementów.
(def siup
(map (fn [n] (print "*") n) (range 1000)))
;; Pierwsze pobranie pięciu elementów
;; – generowanych i spamiętywanych jest 32.
(take 5 siup)
; >> (********************************0 1 2 3 4)
;; Drugie pobranie tych samych elementów
;; – nie są już generowane, bo zostały spamiętane.
(take 5 siup)
; => (0 1 2 3 4)
;; Pobranie dziesięciu pierwszych
;; – również nie są generowane, bo spamiętano więcej.
(take 10 siup)
; => (0 1 2 3 4 5 6 7 8 9)
;; Pobranie elementu 35.
;; - kolejny 32-elementowy kawałek będzie generowany.
(nth siup 35)
; >> ********************************35
Istnieją takie zastosowania leniwych sekwencji, w których zachłanne wartościowanie grup elementów nie będzie pożądane. Pierwsze dotyczy efektów ubocznych funkcji generującej i mogliśmy zaobserwować je powyżej. Warto mieć na uwadze, że efekty te mogą być związane nie tylko z zapisem do standardowego wyjścia, ale też na przykład z operacjami na plikach czy przesyłaniem danych sieciowych. Stosowanie pokawałkowanych sekwencji w odniesieniu do zewnętrznych źródeł danych może być źródłem subtelnych błędów, które będą dawały o sobie znać w pewnych specyficznych warunkach brzegowych (np. gdy bufor operacji wejścia/wyjścia będzie mniejszy od rozmiaru kawałka itp.).
Kolejnym kłopotliwym zastosowaniem sekwencji wartościowanych we fragmentach są algorytmy, w których mamy do czynienia z wykładniczą (lub podobną) zależnością między kolejnymi wartościami. Dotyczy to zarówno zajmowanego miejsca (wielkości rezultatów), jak i złożoności obliczeniowej (czasu potrzebnego na obliczanie). Jeżeli dany algorytm już przy trzecim czy czwartym elemencie potrzebuje kilkaset razy więcej czasu (lub pamięci) na wygenerowanie wyniku, to zachłanne wyliczanie kolejnych 28 wartości sprawi, że program zawiesi się na realizowaniu tego zadania.
W sytuacjach opisanych powyżej możemy tak konstruować generatory leniwych sekwencji, aby były jak najmniej zachłanne w realizowaniu wyników, a w odniesieniu do wbudowanych funkcji, które wytwarzają sekwencje pokawałkowane, zastosować obejście zaproponowane przez Stuarta Sierrę:
unchunk, która wyłącza kawałkowanie sekwencji
(defn unchunk [s]
(when (seq s)
(lazy-seq
(cons (first s) (unchunk (next s))))))
Widzimy, że unchunk to w istocie generator leniwych sekwencji sprzężony z sekwencją
podaną jako argument, który sprawia, że tylko jeden element w tym samym czasie będzie
wartościowany podczas dostępu. Sprawdźmy to na funkcji range:
(take 5 (map (fn [n] (print "*") n) (unchunk (range 1000))))
; >> *(**0 *1 *2 *3 4)
Porównanie sekwencji
Spróbujmy dokonać małego porównania właściwości zwykłych sekwencji i ich odpowiedników o zwłocznym wartościowaniu elementów:
| Właściwość | Sekwencja | Sekwencja leniwa |
|---|---|---|
| Sposób działania | Sekwencyjne operacje na bazie struktury danych | Sekwencyjne operacje na bazie funkcji generującej kolejne elementy i kolejne funkcje |
| Typ danych | Cons,PersistentListi inne |
LazySeq |
Dostęp do pierwszego elementu (first) |
Wartość pierwszego elementu w efekcie odczytu ze struktury | Wartość pierwszego elementu sekwencji w efekcie wywołania funkcji generującej |
Dostęp do pozostałych elementów poza pierwszym (rest) |
Sekwencja wszystkich elementów poza pierwszym na bazie struktury | Rezultat wywołania funkcji generującej, który powinien być sekwencją |
| Dołączanie elementu | Z użyciem cons tworzony jest nowy obiekt typu Cons zawierający dodawaną wartość i odwołanie do czoła elementu istniejącej sekwencji bądź nil |
Z użyciem makra lazy-seq tworzony jest obiekt LazySeq zawierający funkcję, która jest wywoływana dopiero podczas próby odczytu; funkcja ta realizuje wyrażenia zawarte w ciele makra, które powinny zwracać obiekt implementujący sekwencyjny interfejs (ISeq) |
Tworzenie sekwencji
Do tworzenia sekwencji służy zestaw funkcji, które mogą być użyte w zależności od tego, co będzie wykorzystane jako źródło danych. Mogą nim być:
- kolekcje,
- inne sekwencje,
- ustalone wartości,
- funkcje generujące.
Większość wbudowanych w Clojure funkcji tworzących sekwencje zwraca sekwencje wartościowane leniwie.
Z kolekcji
Możemy tworzyć sekwencje bazujące na kolekcjach w sposób generyczny lub korzystając ze specyficznych funkcji przeznaczonych dla konkretnych rodzajów kolekcji.
Funkcja generyczna, seq
Do tworzenia sekwencji bazującej na kolekcji służy funkcja seq. Jej argumentem
powinna być kolekcja. Jeżeli argument pominięto, zwracaną wartością będzie nil.
Rezultat zwłoczny: (zależy od wejścia).
Użycie:
(seq kolekcja).
seq
1(seq (list 1 2 3)) ; => (1 2 3)
2(seq [1 2 3]) ; => (1 2 3)
3(seq {:a 1, :b 2}) ; => ([:b 2] [:a 1])
(seq (list 1 2 3)) ; => (1 2 3)
(seq [1 2 3]) ; => (1 2 3)
(seq {:a 1, :b 2}) ; => ([:b 2] [:a 1])
Warto zauważyć, że w REPL sekwencje przedstawiane są z użyciem symbolicznie wyrażonych list, chociaż naprawdę nie są one listami w ścisłym rozumieniu. Można się o tym przekonać, sprawdzając typ danych:
(type (seq [1 2 3]))
; => clojure.lang.PersistentVector$ChunkedSeq
Funkcja seq potrafi tworzyć sekwencje na bazie dowolnych obiektów Javy, które
implementują interfejs Iterable. Jeżeli obiekt ten działa w sposób
zwłoczny, zwrócona zostanie leniwa sekwencja z obiektem Cons na czele.
Z wartości map, vals
Funkcja vals pozwala tworzyć sekwencję na bazie wartości podanej mapy.
Rezultat zwłoczny: NIE.
Użycie:
(vals mapa).
vals
(vals {:a 1, :b 2})
; => (2 1)
Z kluczy map, keys
Pokrewną funkcją jest keys, która robi to samo co vals, ale dla mapowych kluczy.
Rezultat zwłoczny: NIE.
Użycie:
(keys mapa).
keys
(keys {:a 1, :b 2})
; => (:b :a)
Z współbieżnych wywołań, pcalls
Funkcja pcalls pozwala tworzyć leniwą sekwencję na bazie wartości zwracanych przez
bezargumentowe funkcje podane jako jej argumenty. Każdy element będzie obliczany
równolegle, z wykorzystaniem Future’ów.
Do otoczenia każdej wywoływanej funkcji zostaną skopiowane wartości bieżące powiązań
dynamicznych obecnych w wątku wywołania pcalls. Normalnie
wartości bieżące obiektów typu Var są izolowane między wątkami
(współdzielone jest tylko powiązanie główne), więc w ten sposób zapewniana jest ich
widoczność.
Rezultat zwłoczny: NIE/TAK.
Użycie:
(pcalls funkcja…).
pcalls
(pcalls (fn [] 1) (fn [] 2) #(do 3) #(do (Thread/sleep 1000) 4)
; => (1 2 3 4)
Warto zauważyć, że wywoływanie funkcji przekazanych do pcalls rozpocznie się
niezwłocznie, w chwili jej wywołania, chociaż wyniki zostaną umieszczone
w leniwej sekwencji. Do ewaluacji wyrażeń wykorzystana będzie pula wątków (każde
wartościowanie w osobnym wątku), a próba odczytu wartości elementu odpowiadającemu
wywoływanej funkcji, gdy jeszcze nie zwróciła ona wartości, będzie wiązała się
z oczekiwaniem na wynik.
Wewnętrznie pcalls korzysta z pmap.
Z współbieżnych wyrażeń, pvalues
Makro pvalues pozwala tworzyć leniwą sekwencję na bazie wartości podanych wyrażeń,
przy czym każdy element tej sekwencji będzie obliczany równolegle,
z wykorzystaniem Future’ów.
Do otoczenia każdego z ewaluowanych wyrażeń zostaną skopiowane wartości bieżące
powiązań dynamicznych obecnych w wątku wywołania
pvalues. Normalnie wartości bieżące obiektów typu Var są izolowane między
wątkami (współdzielone jest tylko powiązanie główne), więc w ten sposób zapewniana
jest ich widoczność.
Rezultat zwłoczny: NIE/TAK.
Użycie:
(pvalues & wyrażenie…).
pvalues
(pvalues 1 2 3 (do (Thread/sleep 1000) 4))
; => (1 2 3 4)
Warto zauważyć, że wartościowanie wyrażeń przekazanych do makra rozpocznie się niezwłocznie, w chwili jego wywołania, chociaż wyniki zostaną umieszczone w leniwej sekwencji. Do ewaluacji wyrażeń wykorzystana będzie pula wątków (każde wyrażenie w osobnym wątku), a próba odczytu wartości elementu odpowiadającemu wyrażeniu, gdy obliczanie jego wartości jest jeszcze realizowane, będzie wiązała się z oczekiwaniem na wynik.
Wewnętrznie pvalues korzysta z omówionej wcześniej funkcji pcalls.
Z odwróconych kolekcji, rseq
Funkcja rseq w stałym czasie zwraca sekwencję na bazie podanej jako argument
kolekcji, która może być wektorem, mapą sortowaną lub
sortowanym zbiorem. Sekwencję cechuje odwrócona kolejność elementów
względem struktury bazowej. Funkcja zwraca leniwą sekwencję.
Rezultat zwłoczny: TAK.
Użycie:
(rseq kolekcja-uporządkowana).
rseq
1(rseq [1 2 3]) ; => (3 2 1)
2(rseq (sorted-map :a 1, :b 2, :c 3)) ; => ([:c 3] [:b 2] [:a 1])
3(rseq (sorted-set 1 2 3)) ; => (4 3 2 1)
(rseq [1 2 3]) ; => (3 2 1)
(rseq (sorted-map :a 1, :b 2, :c 3)) ; => ([:c 3] [:b 2] [:a 1])
(rseq (sorted-set 1 2 3)) ; => (4 3 2 1)
Z zakresu kolekcji, subseq
Funkcja subseq pozwala na bazie kolekcji utworzyć sekwencję zawierającą pewien
zakres elementów struktury bazowej, określony operatorami przekazanymi jako
argumenty. Pierwszy podany argument musi być kolekcją sortowaną (np. sortowaną
mapą lub zbiorem), a drugi funkcją porównującą (zwaną
komparatorem).
Jeżeli jako argumenty podano tylko jeden komparator i jedną wartość, będą one użyte do wybrania elementów spełniających podany warunek. Jeżeli podano dwa komparatory i dwie wartości, dla wybieranych elementów oba warunki będą musiały być spełnione równocześnie. Można używać tego sposobu, aby wyrażać pełne, obustronnie określone zakresy elementów.
Podczas dokonywania porównań badane są klucze, jeżeli podana kolekcja jest kolekcją asocjacyjną (np. mapą).
Funkcja subseq zwraca leniwą sekwencję.
Rezultat zwłoczny: TAK.
Użycie:
(subseq kolekcja-sortowana komparator wartość),(subseq kolekcja-sortowana komp-start wartość-start komp-stop wartość-stop).
subseq
1(subseq (sorted-set 1 2 3) <= 2) ; => (1 2)
2(subseq (sorted-set 1 2 3) > 1 <= 3) ; => (2 3)
3
4(subseq (sorted-map :a 1, :b 2, :c 3) <= :b) ; => ([:a 1] [:b 2])
5(subseq (sorted-map :a 1, :b 2, :c 3) > :a <= :c) ; => ([:b 2] [:c 3])
(subseq (sorted-set 1 2 3) <= 2) ; => (1 2)
(subseq (sorted-set 1 2 3) > 1 <= 3) ; => (2 3)
(subseq (sorted-map :a 1, :b 2, :c 3) <= :b) ; => ([:a 1] [:b 2])
(subseq (sorted-map :a 1, :b 2, :c 3) > :a <= :c) ; => ([:b 2] [:c 3])
Odwrócone z zakresu, rsubseq
Funkcja rsubseq, zachowuje się jak połączenie rseq i subseq, tzn. umożliwia
tworzenie sekwencji z zakresu elementów kolekcji, a dodatkowo ich kolejność jest
odwracana. Przyjmuje dwa obowiązkowe argumenty: pierwszym powinna być mapa
sortowana, a drugim funkcja porównująca (zwana komparatorem).
Jeżeli jako argumenty podano tylko jeden komparator i jedną wartość, będą one użyte do wybrania elementów spełniających podany warunek. Jeżeli podano dwa komparatory i dwie wartości, to dla wybieranych elementów oba warunki będą musiały być spełnione równocześnie. Można używać tego sposobu, aby wyrażać pełne, obustronnie określone zakresy elementów.
Podczas dokonywania porównań badane są klucze, jeżeli podana kolekcja jest kolekcją asocjacyjną (np. mapą).
Funkcja zwraca leniwą sekwencję.
Rezultat zwłoczny: TAK.
Użycie:
(rsubseq mapa-sortowana komparator wartość),(rsubseq mapa-sortowana komp-start wartość-start komp-stop wartość-stop).
rsubseq
1(rsubseq (sorted-map :a 1, :b 2, :c 3) <= :b) ; => ([:b 2] [:a 1])
2(rsubseq (sorted-map :a 1, :b 2, :c 3) > :a <= :c) ; => ([:c 3] [:b 2])
(rsubseq (sorted-map :a 1, :b 2, :c 3) <= :b) ; => ([:b 2] [:a 1])
(rsubseq (sorted-map :a 1, :b 2, :c 3) > :a <= :c) ; => ([:c 3] [:b 2])
Z ustalonych wartości
Leniwe sekwencje mogą być tworzone również na bazie stałej wartości lub zakresu wartości. Przydaje się to w przypadku konieczności powielenia lub powtarzania tego samego elementu, albo sekwencyjnego udostępnienia zakresu elementów.
Powtarzana wartość, repeat
Funkcja repeat tworzy leniwą sekwencję, której elementy są podaną jako argument
wartością. Jeżeli wywoływana jest z dwoma argumentami, pierwszy oznacza liczbę
elementów sekwencji.
Rezultat zwłoczny: TAK.
Użycie:
(repeat wartość),(repeat elementów wartość).
repeat
(take 3 (repeat :a)) ; => (:a :a :a)
(repeat 3 :a) ; => (:a :a :a)
Zakres wartości, range
Funkcja range zwraca leniwą sekwencję, której elementy określono zakresem.
Wywołana bez argumentów zwraca nieskończoną sekwencję liczb całkowitych, poczynając
od 0.
Rezultat zwłoczny: TAK.
Użycie:
(range),(range koniec),(range początek koniec krok?).
Wywołana z jednym argumentem, który powinien być typem numerycznym, zwraca zakres liczb całkowitych od 0 do podanego elementu (z wyłączeniem go).
Wywołana z dwoma argumentami zwraca sekwencję liczb całkowitych dla podanego zakresu początkowego (włączając element o podanej wartości) i końcowego (z wyłączeniem elementu o podanej wartości).
Jeżeli użyjemy wersji trójargumentowej, ostatnia przekazana wartość będzie oznaczała krok, czyli liczbę, która zostanie dodana do bieżącego elementu, aby uzyskać następny.
Wartością zwracaną jest obiekt typu clojure.lang.LongRange lub clojure.lang.Range
(jeżeli zastosowano rzutowanie jednego z argumentów do typu numerycznego krótszego
niż Long) o sekwencyjnym interfejsie dostępu.
range
1(take 3 (range)) ; => (0 1 2)
2(range 3) ; => (0 1 2)
3(range 3 5) ; => (3 4)
4(range 10 20 5) ; => (10 15)
(take 3 (range)) ; => (0 1 2)
(range 3) ; => (0 1 2)
(range 3 5) ; => (3 4)
(range 10 20 5) ; => (10 15)
Z form generujących
Funkcje i makra generujące sekwencje pozwalają tworzyć wirtualne zestawy danych, które zależą od wyników obliczeń i/lub są wieloskładnikowe, jeżeli chodzi o źródło.
Leniwa sekwencja, lazy-seq
Do tworzenia leniwych sekwencji zapamiętujących elementy służy makro lazy-seq.
Przyjmuje ono opcjonalny argument, który powinien być strukturą danych wyposażoną
w interfejs ISeq (na bazie której można tworzyć sekwencje), a zwraca obiekt typu
clojure.lang.LazySeq. Ma on taką właściwość, że podczas próby odczytu wartości
elementu operacja jego wyliczania (przekazana w ciele makra lazy-seq) będzie
przeprowadzona tylko raz, a każde następne odwołanie będzie korzystało z zachowanej
wcześniej wartości.
Rezultat zwłoczny: TAK.
Użycie:
(lazy-seq & sekwencer…).
lazy-seq
1(defn co-dwa-od [x]
2 (lazy-seq (cons x (co-dwa-od (+ x 2)))))
3
4(take 5 (co-dwa-od 10))
5; => (10 12 14 16 18)
(defn co-dwa-od [x]
(lazy-seq (cons x (co-dwa-od (+ x 2)))))
(take 5 (co-dwa-od 10))
; => (10 12 14 16 18)
W powyższym przykładzie najpierw tworzymy funkcję co-dwa-od, która wywołuje cons,
aby do czoła sekwencji dodać przekazaną jako argument wartość. Wartość ta jest
zachowywana w pierwszym slocie obiektu typu Cons, którego drugi slot zawiera
odniesienie do leniwej sekwencji generowanej z użyciem lazy-seq dla rekurencyjnie
wywoływanej funkcji co-dwa-od. Funkcja tworzy sekwencję, której kolejny dodawany
element jest większy o 2 od poprzedniego.
Łatwo zauważyć, że nie ma tu żadnego warunku zakończenia rekurencji. Nie jest on
potrzebny, ponieważ lazy-seq zwraca sekwencję, która nie będzie od razu obliczana –
funkcja co-dwa-od nie będzie wywoływana, dopóki nie wystąpi próba dostępu do
kolejnych elementów leniwej sekwencji.
Użyta później funkcja take przyjmuje leniwą sekwencję (zaczynającą się od elementu
o wartości 10) i dokonuje pobrania pierwszych pięciu elementów. Oznacza to, że
nastąpi tylko kilka wywołań co-dwa-od.
Warto pamiętać, że użyta wcześniej funkcja cons służy właśnie do uzupełniania
sekwencji o nowe elementy, umieszczane na początku. Obiekty Cons są
konkretyzowanymi sekwencjami. Wewnętrznie ich pierwszy slot (wartość) zawiera
dodawany element, natomiast drugi (reszta) referencję do sekwencji, która jest
rozszerzana.
Wywołania funkcji, repeatedly
Funkcja repeatedly służy do generowania leniwej sekwencji na podstawie rezultatów
zwracanych przez przekazaną, bezargumentową funkcję, która będzie wywoływana tyle
razy, ile pojawi się żądań dostępu do elementu. Opcjonalnie można podać dodatkowy
argument (jako pierwszy), który będzie oznaczał liczbę elementów sekwencji.
Rezultat zwłoczny: TAK.
Użycie:
(repeatedly funkcja),(repeatedly elementów funkcja).
repeatedly
1(take 3 (repeatedly #(rand-int 100))) ; => (92 53 8)
2(repeatedly 3 #(rand-int 100)) ; => (65 81 10)
(take 3 (repeatedly #(rand-int 100))) ; => (92 53 8)
(repeatedly 3 #(rand-int 100)) ; => (65 81 10)
Zauważmy użycie składni wyrażającej funkcję anonimową.
Wywołania funkcji sprzężonej, iterate
Funkcja iterate służy do tworzenia sekwencji na podstawie wywoływania przekazanej
funkcji w odniesieniu do kolejnych elementów, poczynając od wartości początkowej.
Rezultat zwłoczny: TAK.
Użycie:
(iterate operator początek).
Funkcja przyjmuje dwa argumenty: pierwszy to jednoargumentowa funkcja, a drugi wartość początkowa, która stanie się jednocześnie pierwszym elementem sekwencji.
Dla podanej wartości wywoływana jest funkcja, a zwracana przez nią wartość staje się kolejnym elementem sekwencji i jednocześnie wartością podawaną jako argument przy następnym wywołaniu funkcji.
Podawana jako argument funkcja nie powinna mieć efektów ubocznych.
Wartością zwracaną jest obiekt typu clojure.lang.Iterate o sekwencyjnym interfejsie
dostępu.
iterate
(take 3 (iterate inc 5)) ; => (5 6 7)
(take 3 (iterate #(*' % %) 5)) ; => (5 25 625)
W linii nr 2 użyliśmy anonimowej funkcji, lecz tym razem skorzystaliśmy dwukrotnie z argumentu (symbolizowanego znakiem procenta) i operatora mnożenia. W ten sposób stworzyliśmy funkcję, która dokonuje podniesienia do kwadratu każdego kolejnego elementu sekwencji.
Z innych obiektów
Leniwe sekwencje mogą być tworzone nie tylko jako reprezentacja elementów kolekcji czy generowane przez funkcje, ale również powstawać na bazie innych obiektów.
Linie z czytnika, line-seq
Funkcja line-seq przyjmuje obiekt czytnika (musi być instancją
java.io.BufferedReader lub klasy pochodnej), dla którego każda z kolejnych
odczytywanych linii staje się kolejnym elementem zwracanej sekwencji.
Czytnik to mechanizm Javy pozwalający w ujednolicony sposób uzyskiwać dostęp do plików, gniazd sieciowych, dokumentów HTTP i innych danych, które da się odczytywać strumieniowo.
Rezultat zwłoczny: TAK.
Użycie:
(line-seq czytnik).
line-seq
(with-open [czytnik (clojure.java.io/reader "http://google.pl/")]
(printf "%s\n" (clojure.string/join "\n" (line-seq czytnik))))
(with-open [czytnik (clojure.java.io/reader "http://google.pl/")]
(printf "%s\n" (clojure.string/join "\n" (line-seq czytnik))))
Mapy strukt. z rezultatów, resultset-seq
Mapy strukturalne to mapy, które mają z góry określony zestaw
kluczy. Zaznajomieni z językiem C mogą sobie je wyobrazić jako tablicę, której każdy
element jest strukturą (struct), wyposażoną dodatkowo w funkcję transformacji
kluczowej, aby dostęp do elementów był szybki.
W Javie istnieje interfejs java.sql.ResultSet, którego używa się w obiektach
służących do zwracania wyników zapytań SQL wykonywanych na bazach danych. Funkcja
resultset-seq pozwala na dostęp do rezultatu zapytania z poziomu Clojure. Zwraca
ona leniwą sekwencję, której każdy element to przekształcony do postaci mapy
strukturalnej rząd (ang. row) rezultatu.
Rezultat zwłoczny: TAK.
Użycie:
(resultset-seq rezultaty).
resultset-seq
1(with-connection
2 db (with-query-results
3 rs ["select enum_range(null::costam)"]
4 (get (first (resultset-seq
5 (.getResultSet (get (first(doall rs))
6 :enum_range))))
7 "VALUE")))
(with-connection
db (with-query-results
rs ["select enum_range(null::costam)"]
(get (first (resultset-seq
(.getResultSet (get (first(doall rs))
:enum_range))))
"VALUE")))
Wyrażenia regularne, re-seq
Dzięki funkcji re-seq możliwe jest tworzenie leniwej sekwencji, której elementy są
kolejnymi dopasowaniami wzorca do łańcucha tekstowego przeprowadzonymi z użyciem
metody java.util.regex.Matcher.find() i przetworzonymi z użyciem
re-groups.
Funkcja przyjmuje dwa argumenty. Pierwszy to wyrażenie regularne, a drugi dopasowywany tekst. Wartością zwracaną jest leniwa sekwencja reprezentująca dopasowania.
Rezultat zwłoczny: TAK.
Użycie:
(re-seq regex).
re-seq
1(re-seq #"\w+" "Jestem bosym mleczarzem.")
2; => ("Jestem" "bosym" "mleczarzem")
3
4(map last (re-seq #"((.*?)[ \.]+)" "Jestem bosym mleczarzem."))
5; => ("Jestem" "bosym" "mleczarzem")
(re-seq #"\w+" "Jestem bosym mleczarzem.")
; => ("Jestem" "bosym" "mleczarzem")
(map last (re-seq #"((.*?)[ \.]+)" "Jestem bosym mleczarzem."))
; => ("Jestem" "bosym" "mleczarzem")
Drzewa, tree-seq
Funkcja tree-seq zwraca leniwą sekwencję, której kolejne elementy są węzłami drzewa
podanego jako ostatni argument. Pierwszym argumentem powinien być predykat, który
zwraca wartość prawdziwą (nie false i nie nil), jeżeli podany mu jako argument
węzeł może mieć węzły potomne (gałęzie). Z kolei drugim argumentem powinna być
jednoargumentowa funkcja, która generuje sekwencję węzłów potomnych względem
podanego.
Rezultat zwłoczny: TAK.
Użycie:
(tree-seq predykat gen-potomnych korzeń).
tree-seq
1(def drzewko { :korzeń
2 {
3 :gałązka1 nil,
4 :gałązka2 { :listek1 nil },
5 :gałązka3 { :listek1 nil, :listek2 nil }}})
6(tree-seq
7 #(or (map? %) (val %))
8 #(if (map? %) (val (first %)) (val %))
9 drzewko)
(def drzewko { :korzeń
{
:gałązka1 nil,
:gałązka2 { :listek1 nil },
:gałązka3 { :listek1 nil, :listek2 nil }}})
(tree-seq
#(or (map? %) (val %))
#(if (map? %) (val (first %)) (val %))
drzewko)
Pliki z katalogu, file-seq
Dzięki funkcji file-seq można rekurencyjnie sekwencjonować zawartości katalogów
systemu plikowego. Przyjmuje ona jeden argument, który powinien być plikiem lub
katalogiem (java.io.Files), a zwraca leniwą sekwencję z zawartością katalogu,
w której każdy element jest typu java.java.io.Filesio.File.
Rezultat zwłoczny: TAK.
Użycie:
(file-seq pliki).
file-seq
1(file-seq (clojure.java.io/file "/tmp"))
(file-seq (clojure.java.io/file "/tmp"))
Dokumenty XML, xml-seq
Funkcja xml-seq pozwala na tworzenie leniwych sekwencji reprezentujących strukturę
dokumentów XML. Przyjmuje ona jeden argument, który powinien być korzeniem drzewa
DOM.
Rezultat zwłoczny: TAK.
Użycie:
(xml-seq korzeń).
xml-seq
1;; Definiujemy jakiś mini-dokument XML.
2
3(def nasz-xml
4 "<?xml version=\"1.0\" encoding=\"UTF-8\"?>
5 <korzeń klucz=\"wartość\">
6 <pień>
7 <gałązka>listek1</gałązka>
8 listek2
9 </pień>
10 </korzeń>")
11
12;; Funkcja clojure.xml/parse wymaga, aby argumentem był obiekt
13;; reprezentujący strumień danych. Musimy więc łańcuch tekstowy
14;; udostęppnić jako strumień (javowy obiekt ByteArrayInputStream).
15
16(defn jako-strumień [tekst]
17 (java.io.ByteArrayInputStream.
18 (.getBytes tekst)))
19
20(xml-seq
21 (clojure.xml/parse (jako-strumień nasz-xml)))
22
23; => ({:tag :korzeń,
24; => :attrs {:klucz "wartość"},
25; => :content [{:tag :pień,
26; => :attrs nil,
27; => :content [{:tag :gałązka,
28; => :attrs nil,
29; => :content ["listek1"]}
30; => "\n listek2\n "]}]}
31; => {:tag :pień,
32; => :attrs nil,
33; => :content [{:tag :gałązka,
34; => :attrs nil,
35; => :content ["listek1"]}
36; => "\n listek2\n "]}
37; => {:tag :gałązka,
38; => :attrs nil,
39; => :content ["listek1"]}
40; => "listek1"
41; => "\n listek2\n ")
;; Definiujemy jakiś mini-dokument XML.
(def nasz-xml
"<?xml version=\"1.0\" encoding=\"UTF-8\"?>
<korzeń klucz=\"wartość\">
<pień>
<gałązka>listek1</gałązka>
listek2
</pień>
</korzeń>")
;; Funkcja clojure.xml/parse wymaga, aby argumentem był obiekt
;; reprezentujący strumień danych. Musimy więc łańcuch tekstowy
;; udostęppnić jako strumień (javowy obiekt ByteArrayInputStream).
(defn jako-strumień [tekst]
(java.io.ByteArrayInputStream.
(.getBytes tekst)))
(xml-seq
(clojure.xml/parse (jako-strumień nasz-xml)))
; => ({:tag :korzeń,
; => :attrs {:klucz "wartość"},
; => :content [{:tag :pień,
; => :attrs nil,
; => :content [{:tag :gałązka,
; => :attrs nil,
; => :content ["listek1"]}
; => "\n listek2\n "]}]}
; => {:tag :pień,
; => :attrs nil,
; => :content [{:tag :gałązka,
; => :attrs nil,
; => :content ["listek1"]}
; => "\n listek2\n "]}
; => {:tag :gałązka,
; => :attrs nil,
; => :content ["listek1"]}
; => "listek1"
; => "\n listek2\n ")
Iteratory Javy, iterator-seq
Dzięki funkcji iterator-seq możemy tworzyć sekwencje powiązane z iteratorami Javy
(obiektami implementującymi interfejs java.util.Iterator).
Rezultat zwłoczny: (zależy od wejścia).
Użycie:
(iterator-seq iterator).
iterator-seq
(iterator-seq (.iterator [1 2 3]))
; => 1 2 3
Powyższy przykład jest nieco abstrakcyjny, ponieważ uzyskujemy w nim dostęp do obiektu iteratora kolekcji, która jest wektorem. Na bazie wektorów, a także większości innych wbudowanych kolekcji języka Clojure, można tworzyć sekwencje bezpośrednio, bez konieczności odwoływania się do metod Javy.
Enumeratory Javy, enumeration-seq
Java wyposażona jest w interfejs enumeracji (java.util.Enumeration), który jest
starszym wariantem interfejsu Iterator. Nazwa może być nieco myląca, ponieważ nie
chodzi tu o typowe enumeratory, które w inżynierii oprogramowania oznaczają po prostu
warstwę abstrakcji służącą do dostarczania danych metodzie odpowiedzialnej za
reaktywną obsługę strumienia danych. W Javie interfejs Enumeration to uboższa
wersja interfejsu Iterator, która różni się tym, że ma dłuższe nazwy metod i nie
obsługuje operacji usuwania.
Dzięki funkcji enumerator-seq możemy tworzyć sekwencje powiązane z obiektami
implementującymi interfejs Enumeration.
Rezultat zwłoczny: (zależy od wejścia).
Użycie:
(enumeration-seq enumerator).
enumeration-seq
(enumeration-seq (java.util.StringTokenizer. "raz dwa trzy"))
; => ("raz" "dwa" "trzy")
Dostęp do elementów
Istnieje wiele funkcji, które pozwalają na dostęp do elementów wyrażanych sekwencyjnie. Dostęp ten może być zarówno następczy (operowanie na kolejnych elementach jeden po drugim), jak i quasi-swobodny (operowanie na elementach o wskazanej pozycji po przejściu przez poprzedzające).
Wartościowanie leniwych sekwencji
Leniwe sekwencje cechuje to, że wartości konkretnych elementów nie są obliczane od razu po ich wytworzeniu, lecz w momencie, gdy zażąda się do nich dostępu. Oczywiście poza wartością uzyskiwanego elementu będą też obliczone wartości wszystkich go poprzedzających.
Czasem może zdarzyć się tak, że wystąpi potrzeba wymuszenia obliczenia (ang. forcing evaluation) wartości wszystkich elementów sekwencji w celu operowania na jej elementach lub wywołania efektów ubocznych (np. wyświetlenia wartości na ekranie). Można wtedy skorzystać odpowiednich makr lub funkcji.
-
Dla więcej niż jednej sekwencji:
- z makra
doseq– gdy zależy nam na wartościach elementów podanych sekwencji, ale zamierzamy ich użyć w celu powstania efektów ubocznych w podanym wyrażeniu (wywoływanym dla każdego elementu).
- z makra
-
Dla dokładnie jednej sekwencji:
-
z funkcji
dorun– gdy nie zależy nam na wartościach elementów podanej sekwencji, ale dla każdego z nich chcemy wywołać funkcję generującą w celu powstania jej efektów ubocznych; -
z funkcji
doall– gdy zależy nam na wartościach elementów podanej sekwencji i chcemy z nich skorzystać w podanym wyrażeniu (wywoływanym dla każdego elementu).
-
Makro doseq i funkcja dorun nie przytrzymują czoła
sekwencji, a więc nie dochodzi do zajęcia pamięci. Funkcja doall
dokonuje retencji czołowej, a zbuforowane rezultaty są zwracane.
Warto na wstępie przestrzec, że wymienionych konstrukcji nie należy stosować na
sekwencjach o nieskończonej długości, ponieważ (jak łatwo się domyślić) spowoduje to
zawieszenie pracy bieżącego wątku i konsumpcję dostępnej pamięci, aż do awaryjnego
zakończenia działania. Jeżeli chodzi o dorun i doall, można
w takich przypadkach zawęzić żądany zbiór wyników do niezbędnego minimum, podając
dodatkowy, opcjonalny argument.
Wymuszone wartościowanie, doseq
Makro doseq służy do uruchomienia funkcji generującej dla każdego elementu leniwej
sekwencji w celu poznania kolejnych wartości i wywołania efektów ubocznych.
Jako pierwszy argument doseq przyjmuje wektor zawierający pary powiązań symboli
z sekwencjami, których kolejne wartości będą wskazywane przez te symbole. Będzie
można ich używać w wyrażeniach podanych jako opcjonalne argumenty makra. Wyrażenia
będą przeliczane tyle razy, ile jest elementów.
Jeżeli w wektorze powiązań umieścimy więcej niż jedną parę powiązaniową, wtedy dla każdego elementu pierwszej sekwencji będzie wykonane przejście przez wszystkie elementy kolejnej itd. Wtedy wyrażenia wykonane będą tylokrotnie, ile wynosi iloraz liczb elementów wszystkich podanych sekwencji.
Zwracaną wartością jest nil.
Użycie doseq nie powoduje zachowywania rezultatów w pamięciach podręcznych.
Rezultat zwłoczny: NIE.
Użycie:
(doseq wektor-powiązań & wyrażenie…).
doseq
(doseq [s (lazy-seq [1 2 3 4])] (println s))
; => nil
; >> 1
; >> 2
; >> 3
; >> 4
doseq z wieloma wyrażeniami
1(doseq [s (lazy-seq [:a :b]) d (list 1 2 3)] (println s d))
2; => nil
3; >> :a 1
4; >> :a 2
5; >> :a 3
6; >> :b 1
7; >> :b 2
8; >> :b 3
(doseq [s (lazy-seq [:a :b]) d (list 1 2 3)] (println s d))
; => nil
; >> :a 1
; >> :a 2
; >> :a 3
; >> :b 1
; >> :b 2
; >> :b 3
W powyższym przykładzie widać co się dzieje, gdy podamy więcej niż jedno
wyrażenie sekwencyjne. Poza tym w przypadku drugiej pary korzystamy
z sekwencyjnego interfejsu listy, a nie tworzymy sekwencji z użyciem lazy-seq.
Generowanie efektów ubocznych, dorun
Funkcja dorun wymusza wartościowanie elementów sekwencji podanej jako jej ostatni
argument, lecz bez odczytywania ich wartości. Służy do wywoływania funkcji
generującej, która może mieć efekty uboczne.
Pierwszym, opcjonalnym argumentem dorun, może być liczba elementów sekwencji, które
zostaną obsłużone.
W przypadku sekwencji, których funkcja generująca kolejne elementy ma efekty uboczne,
dorun sprawia, że są one emitowane dla każdego z nich. W normalnych warunkach
efekty uboczne funkcji generującej są emitowane dopiero w momentach pobierania
kolejnych wartości.
Funkcja dokonuje przejścia po elementach i zawsze zwraca wartość nil.
Użycie dorun nie powoduje zachowywania rezultatów w pamięciach podręcznych.
Rezultat zwłoczny: NIE.
Użycie:
(dorun liczba-elementów? sekwencja).
dorun
1;; map zwraca leniwą sekwencję, której funkcja po prostu wypisuje
2;; kolejne elementy powiązanej kolekcji
3
4(def powitki (map #(println "witaj" %) ["matko" "ojcze" "bracie"]))
5
6(dorun powitki)
7; => nil
8; >> witaj matko
9; >> witaj ojcze
10; >> witaj bracie
;; map zwraca leniwą sekwencję, której funkcja po prostu wypisuje
;; kolejne elementy powiązanej kolekcji
(def powitki (map #(println "witaj" %) ["matko" "ojcze" "bracie"]))
(dorun powitki)
; => nil
; >> witaj matko
; >> witaj ojcze
; >> witaj bracie
Efekty uboczne i wartości, doall
Funkcja doall podobnie jak dorun wymusza wartościowanie elementów
sekwencji podanej jako jej ostatni argument, jednak pozwala operować na uzyskiwanych
wartościach. Pierwszym, opcjonalnym argumentem, może być liczba elementów, które
chcemy pobrać.
W przypadku sekwencji, których funkcja generująca kolejne elementy ma efekty uboczne,
doall sprawia, że są one emitowane dla każdego z nich. W normalnych warunkach
efekty uboczne funkcji generującej są emitowane dopiero w momentach odczytywania
kolejnych wartości.
Funkcja dokonuje przejścia po elementach i zwraca wartości w postaci leniwej sekwencji.
Czołowy element sekwencji jest zachowywany w pamięci, a w rezultacie pozostają w niej wszystkie zbuforowane rezultaty.
Rezultat zwłoczny: TAK.
Użycie:
(doall liczba-elementów? sekwencja).
doall
1;; map zwraca leniwą sekwencję,
2;; dla której funkcja wypisuje kolejne elementy
3
4(def powitki (map #(do (println "witaj" %) %) ["matko" "ojcze" "bracie"]))
5
6(doall powitki)
7; => ("matko" "ojcze" "bracie")
8
9witaj matko
10witaj ojcze
11witaj bracie
;; map zwraca leniwą sekwencję,
;; dla której funkcja wypisuje kolejne elementy
(def powitki (map #(do (println "witaj" %) %) ["matko" "ojcze" "bracie"]))
(doall powitki)
; => ("matko" "ojcze" "bracie")
witaj matko
witaj ojcze
witaj bracie
Dostęp następczy
Pobieranie kolejnych elementów, zwane też iterowaniem po strukturze, można w kolekcjach implementujących sekwencyjny interfejs i sekwencjach zrealizować, korzystając z odpowiednich funkcji.
Pierwszy element, first
Za pobieranie wartości pierwszego elementu odpowiada funkcja first. Jako argument
przyjmuje sekwencję, a zwraca wartość pierwszego elementu lub wartość nieustaloną
nil, jeżeli podany argument ma także wartość nil lub pierwszy element nie
istnieje (zerowa długość).
Rezultat zwłoczny: NIE.
Użycie:
(first sekwencja).
first
(first (seq ["ab" 2 3])) ; => "ab"
(first ["ab" 2 3]) ; => "ab"
(first "abcdef") ; => \a
Pierwszy pierwszego, ffirst
Funkcja ffirst jest skróconym odpowiednikiem dwukrotnego wywołania first. Zwraca
pierwszy element sekwencji lub kolekcji powstałej w wyniku uprzedniego pobrania
pierwszego elementu sekwencji. Jako argument przyjmuje sekwencję, a zwraca wartość
pierwszego elementu sekwencji stanowiącej pierwszy element lub nil, jeżeli podany
argument ma także wartość nil lub element nie istnieje.
Rezultat zwłoczny: NIE.
Użycie:
(ffirst sekwencja).
ffirst
(ffirst ["ab" 2 3])
; => \a
Uwaga: Wywołanie ffirst na sekwencji, której pierwszy element nie jest sekwencją
spowoduje zgłoszenie wyjątku.
Następne elementy, next
Każdy element sekwencji jest powiązany z kolejnym. Dzięki funkcji next możemy
podążać za tą relacją i uzyskiwać wartości wszystkich elementów umieszczonych za
pierwszym w podanej jako argument sekwencji. Zwracaną wartością jest
sekwencja. Jeżeli poza pierwszym elementem nie istnieją już inne, zwrócona będzie
wartość nieustalona nil.
Rezultat zwłoczny: NIE.
Użycie:
(next sekwencja).
next
(next '(1 2 3 4))
; => (2 3 4)
Następne po następnym, nnext
Funkcja nnext jest idiomem zagnieżdżonego, dwukrotnego wywołania next. Zwracaną
wartością jest sekwencja zawierająca elementy sekwencji podanej jako pierwszy
argument poza dwoma pierwszymi. Jeżeli nie ma wystarczającej liczby elementów,
zwrócona będzie wartość nil.
Rezultat zwłoczny: NIE.
Użycie:
(nnext sekwencja).
nnext
;; odpowiednik (next (next sekwencja))
(nnext '(1 2 3 4))
; => (3 4)
Pierwszy z następnych, fnext
Funkcja fnext działa podobnie do next, lecz wywołuje first na rezultacie jej
wywołania. Przyjmuje sekwencję, a zwraca pojedynczy element, który jest elementem
następującym po pierwszym.
Rezultat zwłoczny: NIE
Użycie:
(fnext sekwencja).
fnext
;; odpowiednik (first (next sekwencja))
(fnext '(1 2 3 4))
; => 2
Kolejne od podanego, nthnext
Funkcja nthnext służy do uzyskiwania sekwencji elementów, poczynając od pozycji
o podanym numerze (licząc od zera). Przyjmuje dwa argumenty: sekwencję i numer
kolejny elementu, od którego należy zacząć pobieranie wszystkich następnych.
Zwracaną wartością jest sekwencja.
W przypadku podania numeru większego niż liczba elementów, zwracana jest wartość
nieustalona nil.
Rezultat zwłoczny: NIE.
Użycie:
(nthnext sekwencja numer-kolejny).
nthnext,
(nthnext '(1 2 3 4) 2)
; => (3 4)
Następne pierwszego, nfirst
Funkcja nfirst jest skróconym odpowiednikiem wywołania next na rezultacie
zwracanym przez first. Zwraca sekwencję zawierającą kolejne (poza pierwszym)
elementy kolekcji lub sekwencji stanowiącej pierwszy element sekwencji podanej jako
argument. Jeżeli podany argument ma także wartość nil lub element nie istnieje,
zwrócona zostanie wartość nieustaloną nil.
Rezultat zwłoczny: NIE.
Użycie:
(nfirst sekwencja).
nfirst
(nfirst ["abcd" 2 3])
; => (\b \c \d)
Uwaga: Wywołanie nfirst na sekwencji, której pierwszy element nie jest sekwencją
spowoduje zgłoszenie wyjątku.
Drugi element, second
Uzyskanie dostępu do drugiego elementu sekwencji umożliwia funkcja second.
Rezultat zwłoczny: NIE.
Użycie:
(second sekwencja).
second
(second ["ab" 2 3])
; => 2
Element o wskazanej pozycji, nth
Dzięki funkcji nth można pobrać element sekwencji o wskazanej pozycji. Pozycja
liczona jest od 0 (pierwszy element).
Warto zauważyć, że aby uzyskać dostęp do konkretnego elementu sekwencji, konieczne jest uzyskanie dostępu do (a w przypadku leniwych sekwencji obliczenie wartości) wszystkich elementów poprzedzających. Wynika to ze specyficznego rodzaju uzyskiwania wartości elementów sekwencji, gdzie na poziomie operacyjnym kolejne zależą od poprzednich.
Rezultat zwłoczny: NIE.
Użycie:
(nth sekwencja pozycja),(nth sekwencja pozycja wartość-domyślna).
nth
(nth ["ab" 2 3] 2) ; => 3
(nth ["ab" 2 3] 5 "brak") ; => "brak"
Ostatni element, last
Ostatni element sekwencji możemy pobrać z użyciem funkcji last. Przyjmuje ona jeden
argument, którym powinna być sekwencja, a zwraca wartość jej ostatniego elementu.
Warto zauważyć, że aby uzyskać dostęp do ostatniego elementu sekwencji, konieczne jest uzyskanie dostępu do (a w przypadku leniwych sekwencji obliczenie wartości) wszystkich elementów poprzedzających. Wynika to ze specyficznego rodzaju uzyskiwania wartości elementów sekwencji, gdzie na poziomie operacyjnym kolejne zależą od poprzednich.
Rezultat zwłoczny: NIE.
Użycie:
(last sekwencja).
last
(last ["ab" 2 3])
; => 3
Losowy element, rand-nth
Dzięki funkcji rand-nth można pobierać losowy element z kolekcji wyposażonej
w sekwencyjny interfejs dostępu. Przyjmuje ona jeden argument, którym powinna być
sekwencja, a zwraca wartość jej losowo wybranego elementu.
Warto zauważyć, że aby uzyskać dostęp do konkretnego elementu sekwencji, konieczne jest uzyskanie dostępu do (a w przypadku leniwych sekwencji obliczenie wartości) wszystkich elementów poprzedzających. Wynika to ze specyficznego rodzaju uzyskiwania wartości elementów sekwencji, gdzie na poziomie operacyjnym kolejne zależą od poprzednich.
Rezultat zwłoczny: NIE.
Użycie:
(rand-nth sekwencja).
rand-nth
(rand-nth ["ab" 2 3])
; => 2
Pierwszy jako powiązanie, when-first
Makro when-first przyjmuje jeden obowiązkowy argument, który powinien być wektorem
powiązań zawierającym dokładnie jedną parę powiązaniową (dwa
elementy). Pierwszym elementem pary musi być symbol w formie powiązaniowej,
natomiast drugim sekwencja lub kolekcja z sekwencyjnym interfejsem
dostępu. Pierwszy element tej ostatniej zostanie powiązany leksykalnie (z użyciem
let) z podanym symbolem i będzie można go użyć w wyrażeniu podanym jako
drugi argument.
Jeżeli pierwszego elementu nie da się uzyskać (np. mamy do czynienia z pustą
sekwencją lub z wartością nil), zwrócona zostanie wartość nieustalona
nil. W przeciwnym przypadku zwrócona będzie wartość wyrażenia podanego jako drugi
argument.
Rezultat zwłoczny: (zależy od wejścia).
Użycie:
(when-first wektor-powiązań & ciało…).
when-first
(when-first [x '(1 2 3)] x)
; => 1
Zobacz także:
- „Powiązanie 1-go niepustego”, rozdział VI.
Konwertowanie sekwencji
W Clojure istnieją funkcje, dzięki którym możliwe jest budowanie kolekcji czy zestawów argumentów na bazie sekwencji.
Do argumentów funkcji, apply
Funkcja apply pozwala używać wartości elementów sekwencji jako kolejnych
argumentów wywoływanej funkcji. Przyjmuje ona minimum dwa argumenty – pierwszy
powinien być funkcją, która zostanie wywołana, a drugi sekwencją, której elementy
będą przekazane jako jej argumenty. Opcjonalnie możemy po funkcji przekazać dodatkowe
argumenty, które zostaną użyte w wywołaniu jako pierwsze (przed argumentami
pochodzącymi z sekwencji). Funkcja zwraca rezultat wykonania przekazanej funkcji.
Rezultat zwłoczny: NIE.
Użycie:
(apply funkcja sekwencja),(apply funkcja argument-funkcji… sekwencja).
apply
(apply str "a" "b" "c" [1 2 3]) ; => "abc123"
(apply str [1 2 3]) ; => "123"
W powyższym przykładzie skorzystaliśmy z funkcji str, która przyjmuje
dowolną liczbę argumentów i zwraca łańcuch tekstowy na podstawie złączenia tekstowych
reprezentacji ich wartości.
Zobacz także:
- „Argumenty z sekwencji”, rozdział VIII.
Do kolekcji
Umieszczanie w kolekcji, into
Funkcja into pozwala umieścić wszystkie elementy podanej jako drugi argument
sekwencji w kolekcji, która została przekazana jako pierwszy argument. Zwraca
kolekcję zbudowaną na bazie oryginalnej z dodanymi elementami pochodzącymi
z sekwencji.
Rezultat zwłoczny: NIE.
Użycie:
(into kolekcja sekwencja).
into
(into [1 2] '(3 4 5))
; => [1 2 3 4 5]
Budowanie wektora, vec
Funkcja vec, która służy do tworzenia wektorów, może również korzystać
z sekwencji, aby na tej podstawie wypełnić strukturę elementami.
Rezultat zwłoczny: NIE.
Użycie:
(vec sekwencja).
vec
(vec '(1 2 3 4))
; => [1 2 3 4]
Budowanie zbioru, set
Analogicznie do vec działa funkcja set, która tworzy zbiory. Można użyć
sekwencji do zainicjowania nowej struktury.
Rezultat zwłoczny: NIE.
Użycie:
(set sekwencja).
set
(set '(1 2 3 4))
; => #{1 4 3 2}
Budowanie mapy częstości, frequencies
Dzięki funkcji frequencies możemy dowiedzieć się jaka jest częstotliwość
występowania poszczególnych wartości w sekwencji. Funkcja ta przyjmuje jeden
argument, a zwraca mapę zawierającą unikatowe wartości elementów jako klucze
i przypisane do nich liczby całkowite, które wyrażają jak często występowały
w sekwencji.
Rezultat zwłoczny: NIE.
Użycie:
(frequencies sekwencja).
frequencies
(frequencies '(Zuzia Ruzia Jadzia Zuzia))
; => {Zuzia 2, Ruzia 1, Jadzia 1}
Zazębianie do mapy, zipmap
Funkcja zipmap pozwala utworzyć mapę na podstawie dwóch sekwencji podanych jako
argumenty. Wartości elementów pierwszej staną się kluczami mapy, a drugiej
wartościami.
Użycie:
(zipmap sekwencja-kluczy sekwencja-wartości).
zipmap
(zipmap '(:a :b) '(1 2))
; => {:b 2, :a 1}
Grupowanie, group-by
Funkcja group-by umożliwia tworzenie map, których wartościami są wektory elementów
powstałych na bazie sekwencji podanej jako drugi argument, natomiast kluczami
rezultaty wykonania funkcji, którą podano jako pierwszy argument. Pozwala ona
grupować elementy sekwencji z użyciem podanego operatora.
Rezultat zwłoczny: NIE.
Użycie:
(group-by funkcja sekwencja-wartości).
group-by
1(group-by #(if (> % 9) :wielocyfrowe :jednocyfrowe)
2 '(1 2 30 40 50))
3
4; => {:jednocyfrowe [1 2], :wielocyfrowe [30 40 50]}
(group-by #(if (> % 9) :wielocyfrowe :jednocyfrowe)
'(1 2 30 40 50))
; => {:jednocyfrowe [1 2], :wielocyfrowe [30 40 50]}
Do wartości
Istnieją wbudowane funkcje języka Clojure, które umożliwiają konwersję elementów sekwencji do pojedynczej wartości lub struktury wielowartościowej.
Element z kryterium, some
Funkcja some zwraca wartość funkcji podanej jako pierwszy argument dla pierwszego
elementu podanej jako drugi argument sekwencji, dla którego przekazana funkcja zwraca
prawdę (wartość różną od nil i różną od false).
Jeżeli dla żadnego elementu sekwencji przekazana funkcja nie zwróci wartości
prawdziwej, zwracana jest wartość nil.
Rezultat zwłoczny: NIE.
Użycie:
(some warunek sekwencja).
some
1;; pierwszy test parzystości elementu o pozytywnym wyniku
2
3(some even? '(1 2 3 4 5 6 7 8))
4; => true
5
6;; pierwszy parzysty element
7
8(some #(if (even? %) %) '(1 2 3 4 5 6 7 8))
9; => 2
10
11;; pierwszy element, który jest większy niż 10
12
13(some #(if (> % 10) %) '(1 2 3 4 5 6 7 8))
14; => nil
15
16;; pierwszy element, który jest mniejszy niż 5
17
18(some #(if (< % 5) %) '(1 2 3 4 5 6 7 8))
19; => 1
20
21;; pierwszy element, który jest większy niż 3
22
23(some #(if (> % 3) %) '(1 2 3 4 5 6 7 8))
24; => 4
25
26;; pierwszy element należący do zbioru
27
28(some #{1 2 7} '(3 4 5 6 7))
29; => 7
;; pierwszy test parzystości elementu o pozytywnym wyniku
(some even? '(1 2 3 4 5 6 7 8))
; => true
;; pierwszy parzysty element
(some #(if (even? %) %) '(1 2 3 4 5 6 7 8))
; => 2
;; pierwszy element, który jest większy niż 10
(some #(if (> % 10) %) '(1 2 3 4 5 6 7 8))
; => nil
;; pierwszy element, który jest mniejszy niż 5
(some #(if (< % 5) %) '(1 2 3 4 5 6 7 8))
; => 1
;; pierwszy element, który jest większy niż 3
(some #(if (> % 3) %) '(1 2 3 4 5 6 7 8))
; => 4
;; pierwszy element należący do zbioru
(some #{1 2 7} '(3 4 5 6 7))
; => 7
Redukowanie do wartości, reduce
Funkcja reduce jako drugi argument przyjmuje sekwencję, a jako pierwszy
dwuargumentowy operator, który będzie użyty względem wartości kolejnych elementów tej
sekwencji w taki sposób, że wynik zastosowania go na wartości poprzedniego elementu
jest wcześniej akumulowany, a następnie używany jako pierwszy argument wywołania
operatora, gdy drugim argumentem operatora jest aktualnie przetwarzany element
sekwencji. Funkcja zwraca wartość ostatniego wywołania operatora.
W trójargumentowej wersji funkcja pozwala podać początkową wartość akumulatora jako drugi argument, a sekwencję jako trzeci.
Rezultat zwłoczny: (zależny od operatora i wejścia).
Użycie:
(reduce operator sekwencja),(reduce operator wartość sekwencja).
reduce
1(reduce + '(1 2 3 4)) ; => 10
2(reduce + 20 '(1 2 3 4)) ; => 30
3(reduce #(cons %2 %1) nil '(1 2)) ; => (2 1)
(reduce + '(1 2 3 4)) ; => 10
(reduce + 20 '(1 2 3 4)) ; => 30
(reduce #(cons %2 %1) nil '(1 2)) ; => (2 1)
Więcej szczegółów dotyczących redukowania (zwijania) sekwencji wartości można znaleźć w części poświęconej transduktorom.
Redukowanie z indeksem, reduce-kv
Funkcja reduce-kv użyta w odniesieniu do wektorów i innych kolekcji indeksowanych
numerycznie działa podobnie do reduce, z tą różnicą, że wywołuje podany
jako pierwszy argument operator dla każdego elementu i jego numeru indeksu (poza
akumulatorem i wartością aktualnie przetwarzanego elementu). Funkcja przyjmuje też
wartość początkową akumulatora jako argument na drugiej pozycji.
Funkcja zwraca rezultat ostatniego wywołania operatora na wartości akumulatora, ostatnio przetwarzanym elemencie wektora i jego numerze kolejnym (licząc od 0).
Użycie:
(reduce-kv operator akumulator wektor).
reduce-kv
(reduce-kv + 0 [1 2 3 4])
; => 16
Zatrzymywanie redukcji, reduced
Funkcja reduced przyjmuje wartość i zwraca obiekt, który powoduje zatrzymanie
procesu zwijania (redukcji), gdy zostanie zwrócony przez funkcję redukującą podaną do
reduce.
Zwracany obiekt nadal wyraża oryginalną wartość, lecz kapsułkowaną w instancji
odpowiedniego typu danych, który ma znaczenie sterujące dla reduce. Po
odkapsułkowaniu wartość będzie zwrócona przez reduce.
Użycie:
(reduced wartość).
reduced
1(reduce #(if (< %2 6)
2 (+ %1 %2)
3 (reduced :koniec)) ; wartość stała
4 '(1 2 3 4 5 6 7 8))
5; => :koniec
6
7(reduce #(if (< %2 100)
8 (+ %1 %2)
9 (reduced :koniec)) ; wartość stała
10 '(1 2 3 4 5 6 7 8))
11; => 36
12
13(reduce #(if (< %2 6)
14 (+ %1 %2)
15 (reduced %1)) ; akumulator
16 '(1 2 3 4 5 6 7 8))
17; => 15
(reduce #(if (< %2 6)
(+ %1 %2)
(reduced :koniec)) ; wartość stała
'(1 2 3 4 5 6 7 8))
; => :koniec
(reduce #(if (< %2 100)
(+ %1 %2)
(reduced :koniec)) ; wartość stała
'(1 2 3 4 5 6 7 8))
; => 36
(reduce #(if (< %2 6)
(+ %1 %2)
(reduced %1)) ; akumulator
'(1 2 3 4 5 6 7 8))
; => 15
Modyfikowanie sekwencji
Istnieje wiele funkcji, które pozwalają przekształcać sekwencje w taki sposób, że będą one zawierały więcej lub mniej elementów. Zazwyczaj kryterium selekcji będzie bazowało na wartościach, chociaż zdarzają się operacje pozwalające korzystać np. z numerów kolejnych.
Usuwanie elementów
Bez pierwszego elementu, rest
Pierwszy element sekwencji możemy usunąć z użyciem funkcji rest, która jest
podstawową funkcją sekwencyjnego interfejsu (jedną z wymaganych operacji). Przyjmuje
ona sekwencję i zwraca sekwencyjną strukturę (np. listę, obiekt typu ChunkedCons
bądź LazySeq), która reprezentuje wszystkie elementy sekwencji poza pierwszym.
Rezultat zwłoczny: (zależy od wejścia).
Użycie:
(rest sekwencja).
rest
1(rest [1 2 3]) ; => (2 3)
2(type (rest [1 2 3])) ; => clojure.lang.PersistentVector$ChunkedSeq
3
4(rest '(1 2 3)) ; => (2 3)
5(type (rest '(1 2 3))) ; => clojure.lang.PersistentList
6
7(rest (seq '(1 2 3))) ; => (2 3)
8(type (rest (seq '(1 2 3)))) ; => clojure.lang.PersistentList
9
10(rest (range 1 5)) ; => (2 3 4)
11(type (rest (range 1 5))) ; => clojure.lang.ChunkedCons
12
13(take 5 (rest (iterate inc 1))) ; => (2 3 4 5 6)
14(type (rest (iterate inc 1))) ; => clojure.lang.LazySeq
(rest [1 2 3]) ; => (2 3)
(type (rest [1 2 3])) ; => clojure.lang.PersistentVector$ChunkedSeq
(rest '(1 2 3)) ; => (2 3)
(type (rest '(1 2 3))) ; => clojure.lang.PersistentList
(rest (seq '(1 2 3))) ; => (2 3)
(type (rest (seq '(1 2 3)))) ; => clojure.lang.PersistentList
(rest (range 1 5)) ; => (2 3 4)
(type (rest (range 1 5))) ; => clojure.lang.ChunkedCons
(take 5 (rest (iterate inc 1))) ; => (2 3 4 5 6)
(type (rest (iterate inc 1))) ; => clojure.lang.LazySeq
Usuwanie początkowych, drop
Funkcja drop przyjmuje dwa argumenty. Pierwszym powinna być liczba całkowita,
a drugim sekwencja. Zwrócona zostanie sekwencja na bazie przekazanej bez pierwszych
elementów o podanej liczbie.
W wariancie jednoargumentowym funkcja zwraca transduktor wykorzystujący obiekt reprezentujący zmienny stan.
Rezultat zwłoczny: TAK.
Użycie:
(drop liczba),(drop liczba sekwencja).
drop
(drop 3 '(1 2 3 4 5 6 7))
; => (4 5 6 7)
Usuwanie początkowych, drop-while
Funkcja drop-while jako pierwszy argument przyjmuje predykat, a jako drugi
sekwencję. Przekazana funkcja jest wywoływana dla każdego elementu i dopóki
zwraca prawdę (wartość różną od false i różną od nil), elementy są pomijane. Gdy
choć raz funkcja zwróci logiczną prawdę, wtedy przestaje być wywoływana, a element
aktualnie przetwarzany i wszystkie kolejne są umieszczane w sekwencji wynikowej.
W wariancie jednoargumentowym funkcja zwraca transduktor wykorzystujący obiekt reprezentujący zmienny stan.
Rezultat zwłoczny: TAK.
Użycie:
(drop-while predykat),(drop-while predykat sekwencja).
drop-while
(drop-while #(not= 5 %) '(1 2 3 4 5 6 7))
; => (5 6 7)
Usuwanie końcowych, drop-last
Funkcja drop-last przyjmuje dwa argumenty. Pierwszym powinna być liczba całkowita,
a drugim sekwencja. Zwrócona zostanie leniwa sekwencja na bazie przekazanej bez
końcowych elementów o podanej liczbie. W wariancie jednoargumentowym pomijany jest
tylko ostatni element.
Rezultat zwłoczny: TAK.
Użycie:
(drop-last sekwencja),(drop-last liczba sekwencja).
drop-last
(drop-last 3 '(1 2 3 4 5 6 7)) ; => (1 2 3 4)
(drop-last '(1 2 3 4 5 6 7)) ; => (1 2 3 4 5 6)
Usuwanie ostatniego, butlast
Funkcja butlast działa podobnie do drop-last, lecz przyjmuje tylko jeden
argument, którym powinna być sekwencja. Zwrócona zostanie sekwencja na bazie
przekazanej bez ostatniego elementu.
Funkcja ta jest ok. 20% szybsza od drop-last, ale nie zwraca sekwencji leniwej.
Rezultat zwłoczny: NIE.
Użycie:
(butlast sekwencja).
butlast
(butlast '(1 2 3 4 5 6 7))
; => (1 2 3 4 5 6)
Pozostawianie pierwszych, take
Funkcja take pozwala zachować podaną liczbę elementów podanej sekwencji. Przyjmuje
ona dwa argumenty: liczbę całkowitą (określającą liczbę elementów)
i sekwencję. Zwraca sekwencję pochodną zawierającą podaną liczbę elementów źródłowej
sekwencji, licząc od czoła.
W wariancie jednoargumentowym funkcja zwraca transduktor wykorzystujący obiekt reprezentujący zmienny stan.
Rezultat zwłoczny: TAK.
Użycie:
(take liczba),(take liczba sekwencja).
take
(take 3 '(1 2 3 4 5 6 7))
; => (1 2 3)
Pozostawianie pierwszych, take-while
Funkcja take-while pozwala zachować wszystkie elementy, które spełniają podany
warunek. Przyjmuje ona dwa argumenty: predykat (wyrażony jednoargumentową funkcją)
i sekwencję. Zwraca sekwencję pochodną z zachowanymi elementami od pierwszego (jeżeli
spełnia warunek predykatu) do ostatniego dla którego predykat zwrócił logiczną prawdę
(wartość różną od false i różną od nil).
W wariancie jednoargumentowym funkcja zwraca transduktor wykorzystujący obiekt reprezentujący zmienny stan.
Rezultat zwłoczny: TAK.
Użycie:
(take-while predykat),(take-while predykat sekwencja).
take-while
(take-while #(not= 5 %) '(1 2 3 4 5 6 7))
; => (1 2 3 4)
Pozostawianie ostatnich, take-last
Funkcja take-last przyjmuje dwa argumenty. Pierwszym powinna być liczba całkowita,
a drugim sekwencja. Zwrócona zostanie sekwencja na bazie przekazanej z usuniętymi
wszystkimi elementami poza podaną liczbą końcowych elementów, które należy zachować.
Rezultat zwłoczny: TAK.
Użycie:
(take-last liczba sekwencja).
take-last
(take-last 3 '(1 2 3 4 5 6 7))
; => (5 6 7)
Pozostawianie z krokiem, take-nth
Funkcja take-nth przyjmuje dwa argumenty. Pierwszym powinna być liczba całkowita,
a drugim sekwencja. Zwrócona zostanie sekwencja na bazie przekazanej z pozostawionymi
wyłącznie tymi elementami, których pozycja jest wielokrotnością podanej liczby,
poczynając od pierwszego elementu.
W wariancie jednoargumentowym funkcja zwraca transduktor wykorzystujący obiekt reprezentujący zmienny stan.
Uwaga: Przekazanie wartości 0 jako pierwszego argumentu prowadzi do nieskończonego zapętlenia funkcji.
Rezultat zwłoczny: TAK.
Użycie:
(take-nth krok),(take-nth krok sekwencja).
take-nth
(take-nth 3 '(1 2 3 4 5 6 7))
; => (1 4 7)
Filtrowanie, filter
Funkcja filter tworzy leniwą sekwencję składającą się z tych elementów sekwencji
podanej jako drugi argument, dla których jednoargumentowa funkcja podana jako
pierwszy argument zwraca logiczną prawdę (wartości różne od false i różne od
nil).
W wariancie jednoargumentowym funkcja zwraca transduktor.
Rezultat zwłoczny: TAK.
Użycie:
(filter predykat),(filter predykat sekwencja).
filter
(filter odd? '(1 2 3 4 5))
; => (1 3 5)
Eliminowanie, remove
Funkcja remove tworzy leniwą sekwencję, składającą się z tych elementów sekwencji
podanej jako drugi argument, dla których jednoargumentowa funkcja przekazana jako
pierwszy argument zwraca logiczny fałsz (wartość false lub nil). Pomijane są
elementy, dla których predykat tworzy logiczną prawdę.
W wariancie jednoargumentowym funkcja zwraca transduktor.
Rezultat zwłoczny: TAK.
Użycie:
(remove predykat),(remove predykat sekwencja).
remove
(remove odd? '(1 2 3 4 5))
; => (2 4)
Niepowtarzalność, distinct
Funkcja distinct zwraca sekwencję, która jest takim przekształceniem sekwencji
podanej jako argument, że zawiera wyłącznie elementy unikatowe (niepowtarzalne).
Powtórzenia elementów są usuwane.
Rezultat zwłoczny: TAK.
Użycie:
(distinct sekwencja).
distinct
(distinct '(1 2 2 5 2))
; => (1 2 5)
Uwaga: Wewnętrznie funkcja korzysta ze zbioru przechowywanego w pamięci, w którym zapamiętywane są wszystkie unikatowe wartości.
Deduplikacja, dedupe
Funkcja dedupe zwraca sekwencję, która jest takim przekształceniem sekwencji
podanej jako argument, że zawiera wyłącznie elementy unikatowe (niepowtarzalne)
w obrębie sąsiadujących ze sobą. Powtórzenia elementów umiejscowionych obok siebie są
usuwane.
Rezultat zwłoczny: TAK.
Użycie:
(distinct sekwencja).
dedupe
(dedupe '(1 2 2 5 2))
; => (1 2 5 2)
Dodawanie elementów
Sekwencje można uzupełniać o nowe elementy z użyciem odpowiednich funkcji.
Dołączanie elementu, cons
Funkcja cons dodaje element do czoła sekwencji, a zwraca leniwą sekwencję z dodanym
obiektem Cons, który reprezentuje jej pierwszy element.
Rezultat zwłoczny: TAK.
Użycie:
(cons element sekwencja).
cons
(cons 10 '(1 2 3))
; => (10 1 2 3)
Łączenie sekwencji, concat
Dzięki funkcji concat możliwe jest tworzenie sekwencji składającej się z zera lub
większej liczby sekwencji podanych jako jej argumenty.
Wariantem concat jest makro lazy-cat, które działa tak samo, ale faktyczne
operacje przeliczenia sekwencji nastąpią dopiero przy próbie dostępu do elementów lub
wymuszonym wartościowaniu. Każda sekwencja wchodząca w skład sekwencji wynikowej jest
przekształcana do postaci leniwej. Jak nietrudno się domyślić rezultatem jest również
leniwa sekwencja.
Rezultat zwłoczny:
concat: NIE,lazy-cat: TAK.
Użycie:
(concat & sekwencja…),(lazy-cat & sekwencja…).
concat i lazy-cat
1(concat [1 2 3 4] [5 6 7 8]) ; => (1 2 3 4 5 6 7 8)
2(concat) ; => ()
3
4(do (lazy-cat [1 2] [3 4])) ; => (1 2 3 4)
(concat [1 2 3 4] [5 6 7 8]) ; => (1 2 3 4 5 6 7 8)
(concat) ; => ()
(do (lazy-cat [1 2] [3 4])) ; => (1 2 3 4)
Zapętlanie, cycle
Funkcja cycle generuje leniwą, nieskończoną sekwencję złożoną z powtarzanych
elementów sekwencji podanej jako argument.
Rezultat zwłoczny: TAK.
Użycie:
(cycle sekwencja).
Wartością zwracaną jest obiekt typu clojure.lang.Cycle o sekwencyjnym interfejsie
dostępu.
cycle
(take 10 (cycle '(1 2)))
; => (1 2 1 2 1 2 1 2 1 2)
Przeplatanie, interleave
Dzięki funkcji interleave możemy przeplatać elementy podanych sekwencji. Zwraca ona
leniwą sekwencję, która jest połączeniem sekwencji podanych jako argumenty w taki
sposób, że w wyniku umieszczane są najpierw pierwsze elementy każdej sekwencji,
następnie drugie z każdej itd.
Rezultat zwłoczny: TAK.
Użycie:
(interleave & sekwencja…).
interleave
1(interleave [:a :b] [1 2]) ; => (:a 1 :b 2)
2(interleave [:a :b] [1 2] ['x 'y]) ; => (:a 1 x :b 2 y)
3(interleave) ; => ()
(interleave [:a :b] [1 2]) ; => (:a 1 :b 2)
(interleave [:a :b] [1 2] ['x 'y]) ; => (:a 1 x :b 2 y)
(interleave) ; => ()
Wstawianie, interpose
Dzięki funkcji interpose możemy umieszczać element o podanej wartości między
elementami istniejącej sekwencji. Rezultatem jest leniwa sekwencja, w której
wartością co drugiego elementu jest wartość przekazana jako argument.
Wartość nie zostanie nigdy umieszczona po ostatnim elemencie sekwencji.
W wariancie jednoargumentowym funkcja zwraca transduktor wykorzystujący obiekt reprezentujący zmienny stan.
Rezultat zwłoczny: TAK.
Użycie:
(interpose separator),(interpose separator sekwencja).
interpose
(interpose 0 [:a :b :c])
; => (:a 0 :b 0 :c)
Zmiana porządku
Funkcje zmieniające porządek sekwencji pozwalają reorganizować kolejność elementów, jednak przy zachowaniu ich liczby oraz wartości.
Odwracanie kolejności, reverse
Funkcja reverse pozwala odwracać kolejność sekwencji podanej jako argument. Zwraca
listę typu clojure.lang.PersistentList (z sekwencyjnym interfejsem dostępu),
której elementy ułożone są odwrotnie niż sekwencja wejściowa.
Rezultat zwłoczny: NIE.
Użycie:
(reverse sekwencja).
reverse
(reverse '(1 2 3 4))
; => (4 3 2 1)
Uwaga: Funkcja reverse tworzy nową strukturę danych i jej użycie może
w niektórych przypadkach nie być optymalne pod względem oszczędności pamięci. Jeżeli
to możliwe, należy korzystać z omówionej wcześniej funkcji rseq lub rsubseq.
Sortowanie, sort
Funkcje sort i sort-by zwracają sekwencję bazującą na uporządkowanej tablicy
(obiekt klasy clojure.lang.ArraySeq), zawierającej elementy sekwencji podanej jako
argument, które zostały posortowane zgodnie z podanymi kryteriami.
Funkcja sort przyjmuje sekwencję lub (w wariancie dwuargumentowym) funkcję
porównującą elementy (tzw. komparator) i sekwencję. Komparator powinien być
obiektem implementującym interfejs java.util.Comparator, a jeżeli go nie podano,
użyta będzie funkcja compare. Warto nadmienić, że w Clojure każda
definiowana funkcja implementuje interfejs Comparator, więc może być użyta jako
operator porównujący.
Funkcja sort-by działa podobnie, ale wymaga podania dodatkowego, początkowego
argumentu. Jego wartością powinna być funkcja, która dokona wartościowania każdego
elementu zgodnie z intencją programisty. Uzyskana w ten sposób wartość będzie
porównywana, aby uporządkować elementy. Ten wariant sortowania wykorzystuje się na
przykład w obsłudze struktur asocjacyjnych, gdzie wartość skojarzona z konkretnym
kluczem powinna być potraktowana jak kryterium uporządkowania.
Uwaga: Jeżeli zamiast sekwencji zostanie podany obiekt tablicy Javy, zostanie on
zmodyfikowany. Aby się przed tym uchronić, należy korzystać z jego kopii
(np. używając funkcji aclone).
Rezultat zwłoczny: NIE.
Użycie:
(sort sekwencja),(sort komparator sekwencja),(sort-by ewaluator sekwencja),(sort-by ewaluator komparator sekwencja).
sort i sort-by
1;; sortowanie z użyciem wbudowanego komparatora
2
3(sort '(4 3 1 2))
4; => (1 2 3 4)
5
6;; operator "większe niż" użyty jako komparator
7
8(sort > '(4 3 1 2))
9; => (4 3 2 1)
10
11;; własny komparator
12
13(defn komparator [x y] (> x y))
14(sort komparator '(1 2 4 3))
15; => (4 3 2 1)
16
17;; funkcja zliczająca elementy (tu znaki) jako ewaluator
18
19(sort-by count '("siała" "baba" "mak"))
20; => ("mak" "baba" "siała")
21
22;; sortowanie mapy z funkcją val jako ewaluatorem
23
24(sort-by val {:a 1, :b 2, :c 3})
25; => ([:a 1] [:b 2] [:c 3])
26
27;; sortowanie mapy z funkcją val jako ewaluatorem
28;; i z operatorem "większe niż" w roli komparatora
29
30(sort-by val < {:a 1, :b 2, :c 3})
31; => ([:c 3] [:b 2] [:a 1])
;; sortowanie z użyciem wbudowanego komparatora
(sort '(4 3 1 2))
; => (1 2 3 4)
;; operator "większe niż" użyty jako komparator
(sort > '(4 3 1 2))
; => (4 3 2 1)
;; własny komparator
(defn komparator [x y] (> x y))
(sort komparator '(1 2 4 3))
; => (4 3 2 1)
;; funkcja zliczająca elementy (tu znaki) jako ewaluator
(sort-by count '("siała" "baba" "mak"))
; => ("mak" "baba" "siała")
;; sortowanie mapy z funkcją val jako ewaluatorem
(sort-by val {:a 1, :b 2, :c 3})
; => ([:a 1] [:b 2] [:c 3])
;; sortowanie mapy z funkcją val jako ewaluatorem
;; i z operatorem "większe niż" w roli komparatora
(sort-by val < {:a 1, :b 2, :c 3})
; => ([:c 3] [:b 2] [:a 1])
Tasowanie, shuffle
Funkcja shuffle pozwala losowo zmienić kolejność elementów sekwencji podanej jako
jej pierwszy argument. Zwraca wektor zawierający losową permutację elementów
sekwencji wejściowej.
Rezultat zwłoczny: NIE.
Użycie:
(shuffle sekwencja).
shuffle
(shuffle '(1 2 3 4 5))
; => [3 1 5 2 4]
Reorganizacja struktury
Funkcje reorganizujące strukturę sekwencji pozwalają zmieniać sposób grupowania elementów z użyciem sekwencji zagnieżdżonych, które powstały w efekcie zastosowania odpowiednich operacji. Mamy tu na myśli zarówno wytwarzanie dodatkowych sekwencji zagnieżdżonych, jak też eliminowanie zagnieżdżenia.
Spłaszczanie, flatten
Dzięki funkcji flatten możemy przekształcić zagnieżdżone sekwencje i inne struktury
z sekwencyjnym interfejsem dostępu (np. wektory czy listy) w taki sposób, że wynikowa
sekwencja będzie miała tylko jeden wymiar (nie będzie zagnieżdżona).
W przypadku przekazania wartości nil jako pierwszego argumentu zwracana jest
sekwencja pusta.
Rezultat zwłoczny: TAK.
Użycie:
(flatten sekwencja).
flatten
1(flatten '(zakupy (spożywczy (płatki ser) (kiosk szlugi))))
2; => (zakupy spożywczy płatki ser kiosk szlugi)
(flatten '(zakupy (spożywczy (płatki ser) (kiosk szlugi))))
; => (zakupy spożywczy płatki ser kiosk szlugi)
Dzielenie na pozycji, split-at
Podziału sekwencji na dwie we wskazanym miejscu można dokonać z użyciem funkcji
split-at. Przyjmuje ona dwa obowiązkowe argumenty: pozycję (wyrażoną liczbą
naturalną, licząc od pierwszego elementu) i sekwencję. Zwracaną wartością jest wektor
zawierający dwie leniwe sekwencje, gdzie ostatnim elementem pierwszej jest element
o pozycji przekazanej jako pierwszy argument.
Rezultat zwłoczny: TAK.
Użycie:
(split-at pozycja sekwencja).
split-at
(split-at 3 '(1 2 3 4 5 6))
; => [(1 2 3) (4 5 6)]
Dzielenie predykatem, split-with
Podziału sekwencji na dwie w miejscu określonym zaaplikowaniem predykatu do wartości
elementów można dokonać z użyciem funkcji split-with. Przyjmuje ona dwa obowiązkowe
argumenty: predykat (wyrażony jednoargumentową funkcją) i sekwencję. Zwracaną
wartością jest wektor zawierający dwie leniwe sekwencje, gdzie pierwsza zawiera
elementy, dla których przekazana funkcja zwraca logiczną prawdę (nie wartość false
i nie nil).
Warunkiem koniecznym tego, aby pierwsza sekwencja wyjściowa była niepusta jest pozytywny rezultat działania predykatu dla przynajmniej pierwszego elementu sekwencji wejściowej. Działa tu bowiem warunek końcowego momentu stanu: elementy umieszczane są w pierwszej sekwencji dopóki predykat zwraca prawdę.
Rezultat zwłoczny: TAK.
Użycie:
(split-with predykat sekwencja).
split-with
1(split-with #(<= % 3) '(1 2 3 4 5 6))
2; => [(1 2 3) (4 5 6)]
3
4(split-with #{1 2 3} '(1 2 3 4 5 6))
5; => [(1 2 3) (4 5 6)]
(split-with #(<= % 3) '(1 2 3 4 5 6))
; => [(1 2 3) (4 5 6)]
(split-with #{1 2 3} '(1 2 3 4 5 6))
; => [(1 2 3) (4 5 6)]
W drugim przykładzie możemy zauważyć użycie zbioru jako funkcji, czyli formy przeszukiwania kolekcji.
Partycjonowanie, partition
Funkcja partition służy do partycjonowania, czyli dzielenia sekwencji na podgrupy
(będące również sekwencjami). Występuje w trzech wariantach ze względu na liczbę
przyjmowanych argumentów.
W wersji dwuargumentowej pierwszym argumentem powinna być liczba elementów do umieszczenia w każdej z grup, a drugim sekwencja. Rezultatem będzie leniwa sekwencja złożona z leniwych sekwencji, z których każda będzie zawierała podaną liczbę elementów. Jeżeli elementów sekwencji źródłowej nie da się bez reszty podzielić na grupy i ostatnia grupa byłaby niepełna, elementy takie zostaną pominięte w rezultatach.
W wersji trójargumentowej pierwszym argumentem powinna być liczba elementów do
umieszczenia w każdej z grup, drugim tzw. krok, czyli liczba elementów, które
zostaną pominięte po przejściu do generowania kolejnej grupy, a ostatnim
sekwencja. Jeżeli jako krok podamy wartość mniejszą niż pierwszy argument, to
pewne elementy będą powielone w kolejnych grupach, a jeżeli większą, pomijane (nie
pojawią się w żadnej grupie). Wartość kroku równa liczbie elementów (podanej jako
pierwszy argument) sprawi, że funkcja zachowa się tak jak jej wariant
dwuargumentowy. Krok jest po prosu liczbą elementów, o jaką wykonywany jest przeskok
za każdym razem, gdy zakończone jest generowanie grupy i następuje przejście do
kolekcjonowania elementów następnej. Określa on względną pozycję, od której zacznie
się ich pobieranie. Rezultatem wywołania trójargumentowego wariantu funkcji
partition będzie leniwa sekwencja złożona z leniwych sekwencji, z których każda
będzie zawierała podaną liczbę elementów. Jeżeli elementów sekwencji źródłowej nie da
się bez reszty (uwzględniając też krok) podzielić na grupy i ostatnia grupa byłaby
niepełna, elementy takie zostaną pominięte w rezultatach.
W wersji czteroargumentowej pierwszym argumentem powinna być liczba elementów do umieszczenia w każdej z grup, drugim tzw. krok (liczba elementów, które zostaną pominięte po przejściu do generowania kolejnej grupy), trzecim dopełnienie (sekwencja elementów umieszczanych w ostatniej grupie, jeżeli jest niepełna), a ostatnim sekwencja. Rezultatem wywołania funkcji będzie leniwa sekwencja złożona z leniwych sekwencji, z których każda będzie zawierała podaną liczbę elementów. Jeżeli elementów sekwencji źródłowej nie da się bez reszty (uwzględniając też krok) podzielić na grupy i ostatnia grupa byłaby niepełna, zostanie ona uzupełniona kolejnymi elementami pochodzącymi z sekwencji dopełniającej (podanej jako przedostatni argument). Jeżeli sekwencja ta zawiera mniejszą liczbę elementów niż potrzebna do uzupełnienia ostatniej grupy, wtedy będzie ona mniej liczna niż wszystkie pozostałe.
Rezultat zwłoczny: TAK.
Użycie:
(partition liczba sekwencja),(partition liczba krok sekwencja),(partition liczba krok dopełnienie sekwencja).
partition
1(partition 2 [1 2 3 4 5]) ; => ((1 2) (3 4))
2(partition 2 2 [1 2 3 4 5]) ; => ((1 2) (3 4))
3(partition 2 1 [1 2 3 4 5]) ; => ((1 2) (2 3) (3 4) (4 5))
4(partition 2 3 [1 2 3 4 5]) ; => ((1 2) (4 5))
5(partition 2 2 [0] [1 2 3 4 5]) ; => ((1 2) (3 4) (5 0))
6(partition 2 2 (repeat 0) [1 2 3 4 5]) ; => ((1 2) (3 4) (5 0))
7(partition 2 "trala") ; => ((\t \r) (\a \l))
8(take 3 (partition 3 0 [1 2 3 4 5])) ; => ((1 2 3) (1 2 3) (1 2 3))
(partition 2 [1 2 3 4 5]) ; => ((1 2) (3 4))
(partition 2 2 [1 2 3 4 5]) ; => ((1 2) (3 4))
(partition 2 1 [1 2 3 4 5]) ; => ((1 2) (2 3) (3 4) (4 5))
(partition 2 3 [1 2 3 4 5]) ; => ((1 2) (4 5))
(partition 2 2 [0] [1 2 3 4 5]) ; => ((1 2) (3 4) (5 0))
(partition 2 2 (repeat 0) [1 2 3 4 5]) ; => ((1 2) (3 4) (5 0))
(partition 2 "trala") ; => ((\t \r) (\a \l))
(take 3 (partition 3 0 [1 2 3 4 5])) ; => ((1 2 3) (1 2 3) (1 2 3))
Uwaga: Podanie 0 jako kroku spowoduje wygenerowanie sekwencji o nieskończonej długości (nieskończonej liczbie grup), ponieważ nie będzie wykonywany przeskok (nawet o jeden element).
Partycjonowanie wszystkich, partition-all
Funkcja partition-all działa podobnie do partition, jednak ostatnia grupa
elementów zostanie wygenerowana nawet, jeżeli ich liczba będzie mniejsza niż
wymagana. Występuje w dwóch wariantach ze względu na liczbę przyjmowanych
argumentów.
W wariancie jednoargumentowym funkcja zwraca transduktor wykorzystujący obiekt reprezentujący zmienny stan.
W wersji dwuargumentowej pierwszym argumentem powinna być liczba elementów do umieszczenia w każdej z grup, a drugim sekwencja. Rezultatem będzie leniwa sekwencja złożona z leniwych sekwencji, z których każda będzie zawierała podaną liczbę elementów. Ostatnia grupa może zawierać mniej elementów, jeżeli podział bez reszty nie jest możliwy.
W wersji trójargumentowej pierwszym argumentem powinna być liczba elementów do
umieszczenia w każdej z grup, drugim tzw. krok, czyli liczba elementów, które
zostaną pominięte po przejściu do generowania kolejnej grupy, a ostatnim
sekwencja. Krok jest liczbą elementów, o jaką wykonywany jest przeskok, gdy
zakończone jest generowanie grupy i następuje kolekcjonowanie elementów wchodzących
w skład następnej. Określa on względną pozycję, od której zacznie się
grupowanie. Rezultatem wywołania trójargumentowego wariantu funkcji partition-all
będzie leniwa sekwencja złożona z leniwych sekwencji, z których każda będzie
zawierała podaną liczbę elementów. Ostatnia grupa może zawierać mniej elementów,
jeżeli podział bez reszty nie jest możliwy.
Rezultat zwłoczny: TAK.
Użycie:
(partition-all liczba),(partition-all liczba sekwencja),(partition-all liczba krok sekwencja).
partition-all
1(partition-all 2 [1 2 3 4 5]) ; => ((1 2) (3 4) (5))
2(partition-all 2 2 [1 2 3 4 5]) ; => ((1 2) (3 4) (5))
3(partition-all 2 1 [1 2 3 4 5]) ; => ((1 2) (2 3) (3 4) (4 5) (5))
4(partition-all 2 3 [1 2 3 4 5]) ; => ((1 2) (4 5))
5(partition-all 2 "trala") ; => ((\t \r) (\a \l) (\a))
6(take 3 (partition-all 3 0 [1 2 3 4])) ; => ((1 2 3) (1 2 3) (1 2 3))
(partition-all 2 [1 2 3 4 5]) ; => ((1 2) (3 4) (5))
(partition-all 2 2 [1 2 3 4 5]) ; => ((1 2) (3 4) (5))
(partition-all 2 1 [1 2 3 4 5]) ; => ((1 2) (2 3) (3 4) (4 5) (5))
(partition-all 2 3 [1 2 3 4 5]) ; => ((1 2) (4 5))
(partition-all 2 "trala") ; => ((\t \r) (\a \l) (\a))
(take 3 (partition-all 3 0 [1 2 3 4])) ; => ((1 2 3) (1 2 3) (1 2 3))
Uwaga: Podanie 0 jako kroku spowoduje wygenerowanie sekwencji o nieskończonej długości (nieskończonej liczbie grup), ponieważ nie będzie wykonywany przeskok (nawet o jeden element).
Partycjonowanie operatorem, partition-by
Funkcja partition-by działa podobnie do partition, tzn. dzieli podaną sekwencję
na grupy, lecz kryterium decydującym o elementach wchodzących w skład grup nie jest
liczba i/lub krok, ale rezultat wykonywania funkcji przekazanej jako pierwszy
argument wywołania. Powinna ona przyjmować jeden argument, którym będzie wartość
każdego z przetwarzanych elementów i zwracać pojedynczą wartość. Drugim argumentem
powinna być źródłowa sekwencja.
Rezultatem wykonania funkcji będzie leniwa sekwencja złożona z leniwych sekwencji, które mogą różnić się liczbą elementów. Do podziału będzie dochodziło wtedy, gdy przekazana funkcja zwróci wartość różną od poprzednio zwracanej.
W wariancie jednoargumentowym funkcja zwraca transduktor wykorzystujący obiekt reprezentujący zmienny stan.
Rezultat zwłoczny: TAK.
Użycie:
(partition-by funkcja),(partition-by funkcja sekwencja).
partition-by
1(partition-by #(= 3 %) [1 2 3 4 5]) ; => ((1 2) (3) (4 5))
2(partition-by #(not= 3 %) [1 2 3 4 5]) ; => ((1 2) (3) (4 5))
3(partition-by identity [1 2 3 4 5]) ; => ((1) (2) (3) (4) (5))
4(partition-by identity [1 1 2 3 3]) ; => ((1 1) (2) (3 3))
5(partition-by #{\a} "trala") ; => ((\t \r) (\a) (\l) (\a))
(partition-by #(= 3 %) [1 2 3 4 5]) ; => ((1 2) (3) (4 5))
(partition-by #(not= 3 %) [1 2 3 4 5]) ; => ((1 2) (3) (4 5))
(partition-by identity [1 2 3 4 5]) ; => ((1) (2) (3) (4) (5))
(partition-by identity [1 1 2 3 3]) ; => ((1 1) (2) (3 3))
(partition-by #{\a} "trala") ; => ((\t \r) (\a) (\l) (\a))
Zauważmy, że w ostatniej linii przykładu korzystamy ze zbioru jako funkcji, czyli z formy przeszukiwania kolekcji.
Modyfikowanie wartości elementów
Grupa funkcji odpowiedzialna za modyfikowanie wartości elementów sekwencji pozwala tworzyć sekwencje pochodne.
Przeliczanie
Przeliczaniem sekwencji nazwiemy takie przetwarzanie jej kolejnych elementów, że na bazie przeprowadzanych operacji powstaje sekwencja pochodna, której liczba elementów może być różna od wejściowej, a której wartości elementów są rezultatami wykonywanych obliczeń na elementach sekwencji wejściowej. W kategorii tej znajdą się funkcje, które nie modyfikują każdego elementu z osobna, ale tworzą nowe sekwencje na podstawie operacji, które uwzględniają więcej niż jeden element źródłowy w tym samym czasie.
Rezultaty redukowania, reductions
Dzięki funkcji reductions możemy poznać kolejne etapy redukcji przeprowadzanej
z użyciem reduce, czyli wartości zwracane przez podaną funkcję operatora.
Nietrudno więc się domyślić, że reductions działa w podobny sposób, co reduce
ale zamiast pojedynczej wartości tworzy sekwencję wartości pośrednich.
Funkcja jako drugi argument przyjmuje sekwencję, a jako pierwszy dwuargumentowy operator, który powinien być użyty względem kolejnych elementów tej sekwencji w taki sposób, że wynik zastosowania operatora na poprzednim elemencie jest wcześniej akumulowany, a następnie używany jako pierwszy argument następnego wywołania operatora, gdy drugim argumentem operatora jest aktualnie przetwarzany element sekwencji.
W trójargumentowej wersji funkcja pozwala podać początkową wartość akumulatora jako drugi argument, a sekwencję jako trzeci.
Rezultat zwłoczny: TAK.
Użycie:
(reductions operator sekwencja).(reductions operator wartość sekwencja).
reductions
(reductions + '(1 2 3 4)) ; => (1 3 6 10)
(reductions + 20 '(1 2 3 4)) ; => (20 21 23 26 30)
Transformowanie
Przekształcanie warunkowe, keep
Funkcja keep działa podobnie jak filter, z tą jednak różnicą, że
zamiast predykatu jako pierwszy argument przyjmuje funkcję, która transformuje
wartości kolejnych elementów sekwencji podanej jako drugi argument. Wyjątkiem są te
wywołania funkcji przekształcającej, dla których zwraca ona wartość nieustaloną
nil. Takie elementy nie będą umieszczane w sekwencji wynikowej.
Warto zauważyć, że funkcja wygeneruje wyniki dla wartości true i false zwróconych
przez funkcję transformującą, gdy użyjemy predykatu.
W wariancie jednoargumentowym funkcja zwraca transduktor.
Wariantem funkcji keep jest keep-indexed. W jej przypadku funkcja
przekształcająca jako pierwszy argument powinna przyjmować numer kolejny elementu
w sekwencji (poczynając od 0), a element jako drugi.
Rezultat zwłoczny: TAK.
Użycie:
(keep transformator),(keep transformator sekwencja),(keep-indexed transformator),(keep-indexed transformator sekwencja).
keep i keep-indexed
1(keep inc '(1 2 3 4 5)) ; => (2 3 4 5 6)
2(keep #(if (<= % 3) %) '(1 2 3 4 5)) ; => (1 2 3)
3(keep odd? '(1 2 3 4 5)) ; => (true false true false true)
4
5(keep-indexed #(if (odd? %1) %2) '(1 2 3 4 5)) ; => (2 4)
6(keep-indexed #(if (even? %1) %2) '(a b c d)) ; => (a c)
(keep inc '(1 2 3 4 5)) ; => (2 3 4 5 6)
(keep #(if (<= % 3) %) '(1 2 3 4 5)) ; => (1 2 3)
(keep odd? '(1 2 3 4 5)) ; => (true false true false true)
(keep-indexed #(if (odd? %1) %2) '(1 2 3 4 5)) ; => (2 4)
(keep-indexed #(if (even? %1) %2) '(a b c d)) ; => (a c)
Odwzorowywanie, map
Dzięki funkcji map możemy przekształcać wartości elementów na podstawie podanej
funkcji transformującej. Przyjmuje ona dwa argumenty. Pierwszy z nich to funkcja,
która będzie wywoływana dla kolejnych elementów, a drugi to sekwencja poddawana
przekształcaniu. Zwracaną przez map wartością jest leniwa sekwencja na bazie
podanej ze zmienionymi wartościami elementów.
Gdy podano więcej niż jedną sekwencję, przekazana funkcja musi być w stanie przyjąć odpowiednio większą liczbę argumentów, ponieważ w takim przypadku przetwarzane będą kolejne elementy z każdej podanej sekwencji jednocześnie.
W wariancie jednoargumentowym funkcja zwraca transduktor.
Odmianą funkcji map, która do funkcji przekształcającej przekazuje dodatkowo numer
kolejny elementu (poczynając od 0) jest map-indexed.
Rezultat zwłoczny: TAK.
Użycie:
(map transformator sekwencja & sekwencja…),(map transformator),
map
1(map inc '(1 2 3 4))
2; => (2 3 4 5)
3
4(map + [1 2 3] [1 2 3])
5; => (2 4 6)
6
7(map #(if (even? %) %) [1 2 3 4])
8; => (nil 2 nil 4)
9
10(remove nil? (map #(if (even? %) %) [1 2 3 4]))
11; => (2 4)
12
13(map #(str "Witaj, " %) '(świecie matko ojcze))
14; => ("Witaj, świecie" "Witaj, matko" "Witaj, ojcze")
(map inc '(1 2 3 4))
; => (2 3 4 5)
(map + [1 2 3] [1 2 3])
; => (2 4 6)
(map #(if (even? %) %) [1 2 3 4])
; => (nil 2 nil 4)
(remove nil? (map #(if (even? %) %) [1 2 3 4]))
; => (2 4)
(map #(str "Witaj, " %) '(świecie matko ojcze))
; => ("Witaj, świecie" "Witaj, matko" "Witaj, ojcze")
Odwzorowywanie indeksem, map-indexed
Odmianą funkcji map, która do funkcji przekształcającej przekazuje dodatkowo numer
kolejny elementu (poczynając od 0) jest map-indexed. Ona również wymaga podania
wartości pierwszego argumentu w postaci funkcji transformującej, a sekwencji jako
następnego.
Gdy podano więcej niż jedną sekwencję, przekazana funkcja musi być w stanie przyjąć odpowiednio większą liczbę argumentów, ponieważ w takim przypadku przetwarzane będą kolejne elementy z każdej podanej sekwencji jednocześnie.
W wariancie jednoargumentowym funkcja zwraca transduktor.
Rezultat zwłoczny: TAK.
Użycie:
(map-indexed transformator),(map-indexed transformator sekwencja & sekwencja…).
map-indexed
(map-indexed #(str %1 ". Witaj, " %2) '(świecie matko ojcze))
("0. Witaj, świecie" "1. Witaj, matko" "2. Witaj, ojcze")
(map-indexed #(str %1 ". Witaj, " %2) '(świecie matko ojcze))
("0. Witaj, świecie" "1. Witaj, matko" "2. Witaj, ojcze")
Odwzorowywanie równoległe, pmap
Ciekawym wariantem funkcji map jest pmap. Zasada jej działania jest taka sama jak
omówionej poprzedniczki, ale operacje przeprowadzane są
równolegle. Zrównoleglaniu podlega wywoływanie funkcji transformującej wartości
i dzieje się to dla każdego elementu. Wątki są koordynowane i synchronizowane
przed oddawaniem kolejnych rezultatów, więc elementy sekwencji wyjściowej mają
zachowaną kolejność.
Ta funkcja również wymaga podania wartości pierwszego argumentu w postaci funkcji transformującej, a sekwencji jako następnego.
Gdy podano więcej niż jedną sekwencję, przekazana funkcja musi być w stanie przyjąć odpowiednio większą liczbę argumentów, ponieważ w takim przypadku przetwarzane będą kolejne elementy z każdej podanej sekwencji jednocześnie.
Do otoczenia funkcji transformującej zostaną skopiowane wartości bieżące powiązań
dynamicznych obecnych w wątku wywołania pmap. Normalnie
wartości bieżące obiektów typu Var są izolowane między wątkami
(współdzielone jest tylko powiązanie główne), więc w ten sposób zapewniana jest ich
widoczność.
Rezultat zwłoczny: TAK.
Użycie:
(pmap transformator sekwencja & sekwencja…).
pmap
(pmap inc '(1 2 3 4)) ; => (2 3 4 5)
(pmap + [1 2 3] [1 2 3]) ; => (2 4 6)
Spójrzmy na różnicę w czasie realizacji między map i pmap, gdy podana funkcja
trwa dłużej.
map i pmap.
1(defn długo [n] (Thread/sleep 1000) n)
2
3(time (doall (map długo [1 2 3])))
4; >> "Elapsed time: 3000.512006 msecs"
5; => (1 2 3)
6
7(time (doall (pmap długo [1 2 3])))
8; >> "Elapsed time: 1003.371378 msecs"
9; => (1 2 3)
(defn długo [n] (Thread/sleep 1000) n)
(time (doall (map długo [1 2 3])))
; >> "Elapsed time: 3000.512006 msecs"
; => (1 2 3)
(time (doall (pmap długo [1 2 3])))
; >> "Elapsed time: 1003.371378 msecs"
; => (1 2 3)
Wewnętrznie do obsługi współbieżnych wywoływań funkcji transformującej wykorzystywane są Future’y.
Zastępowanie, replace
Dzięki funkcji replace możemy zastępować wartości sekwencji innymi na podstawie
podanej mapy lub wektora. Występuje ona w dwóch wariantach. Pierwszy bazuje na
wektorze podanym jako pierwszy argument. Dla każdego elementu sekwencji (podanej jako
drugi argument) zostanie wykonane przeszukanie wektora pod kątem istnienia indeksu
o numerze określonym wartością tego elementu. Jeżeli element o podanym indeksie
znajduje się w wektorze, zastąpi on numer indeksu będący elementem sekwencji.
Drugi wariant replace jako pierwszy argument przyjmuje mapę, której klucze
określają elementy przeznaczone do zamiany, a przypisane do nich wartości mówią o tym
co powinno być podstawione w ich miejsce. Jest to transformacja słownikowa.
Oba warianty funkcji replace przyjmują sekwencję jako drugi argument, a zwracają
sekwencję z zastąpionymi wartościami elementów.
W wywołaniu jednoargumentowym funkcja zwraca transduktor.
Rezultat zwłoczny: TAK.
Użycie:
(replace wektor),(replace mapa),(replace wektor sekwencja),(replace mapa sekwencja).
replace
1(replace [:a :b :c] '(0 1 1 0)) ; => (:a :b :b :a)
2(replace {:a 1, :b 2, :c 'trzy} '(:a :b :c :d)) ; => (1 2 trzy :d)
(replace [:a :b :c] '(0 1 1 0)) ; => (:a :b :b :a)
(replace {:a 1, :b 2, :c 'trzy} '(:a :b :c :d)) ; => (1 2 trzy :d)
Zaawansowane przekształcanie, for
Makro for służy do zaawansowanego przekształcania sekwencji z użyciem podanych jako
pierwszy argument par powiązaniowych, składających się z symboli
i przypisanych im kolekcji o sekwencyjnym interfejsie dostępu. W wektorze powiązań
mogą znaleźć się także specyficzne dla for pary modyfikatorów o etykietach
wyrażonych słowami kluczowymi:
Umieszczenie modyfikatora w wektorze powiązań sprawia, że będzie wywołana forma specjalna lub makro o odpowiadającej mu nazwie, a znajdujące się po nim wartości zostaną przekazane jako argumenty. W forme tej będzie można korzystać z symbolicznych identyfikatorów ustawionych wcześniej.
Rezultatem wywołania for jest wartość wyrażenia podanego jako jego drugi
argument. Wyrażenie to objęte jest leksykalnym zasięgiem symbolicznych
identyfikatorów skojarzonych wcześniej z wartościami w wektorze powiązań. Dla każdego
przebiegu symbol będzie powiązany z wartością kolejnego elementu sekwencji.
W przypadku więcej niż jednej pary powiązaniowej for dokona zagnieżdżonej
iteracji dla każdego elementu z każdym, poczynając od elementów powiązania podanego
jako pierwsze.
Rezultat zwłoczny: TAK.
Użycie:
(for wektor-powiązań wyrażenie).
for
1(def sekwencja (seq '(1 2 3)))
2
3;; mnożenie przez 2
4
5(for [element1 sekwencja] (* element1 2))
6; => (2 4 6)
7
8;; dodawanie każdego elementu do każdego
9;; (zagnieżdżone iteracje)
10
11(for [element1 sekwencja
12 element2 sekwencja]
13 (+ element1 element2))
14; => (2 3 4 3 4 5 4 5 6)
15
16;; kilka działań z wykorzystaniem modyfikatorów
17
18(for [element1 sekwencja
19 :let [razy-dwa (* 2 element1)]
20 :while (< razy-dwa 5)]
21 razy-dwa)
22; => (2 4)
23
24;; tworzenie sekwencji wektorów z kombinacjami
25;; (zagnieżdżone iteracje)
26
27(for [element1 sekwencja
28 element2 '(:a :b)]
29 [element2 element1])
30; => ([:a 1] [:b 1] [:a 2] [:b 2] [:a 3] [:b 3])
(def sekwencja (seq '(1 2 3)))
;; mnożenie przez 2
(for [element1 sekwencja] (* element1 2))
; => (2 4 6)
;; dodawanie każdego elementu do każdego
;; (zagnieżdżone iteracje)
(for [element1 sekwencja
element2 sekwencja]
(+ element1 element2))
; => (2 3 4 3 4 5 4 5 6)
;; kilka działań z wykorzystaniem modyfikatorów
(for [element1 sekwencja
:let [razy-dwa (* 2 element1)]
:while (< razy-dwa 5)]
razy-dwa)
; => (2 4)
;; tworzenie sekwencji wektorów z kombinacjami
;; (zagnieżdżone iteracje)
(for [element1 sekwencja
element2 '(:a :b)]
[element2 element1])
; => ([:a 1] [:b 1] [:a 2] [:b 2] [:a 3] [:b 3])
Zobacz także:
- „Pętla ogólna”, rozdział XII.
Łączenie z transformacją, mapcat
Funkcja mapcat działa podobnie do concat, ale przyjmuje dodatkowy argument, który
powinien zawierać funkcję przekształcającą wywoływaną dla wartości każdego kolejnego
argumentu zanim dokonane będzie połączenie. W tym celu wywołana będzie wewnętrznie
funkcja map.
W wariancie jednoargumentowym funkcja zwraca transduktor.
Rezultat zwłoczny: TAK (z ograniczeniami).
Użycie:
(mapcat funkcja),(mapcat funkcja & sekwencja…).
Przekazywana jako pierwszy argument funkcja powinna zwracać obiekty wyposażone w sekwencyjny interfejs dostępu. Wartościami kolejnych, opcjonalnych argumentów powinny być sekwencje lub kolekcje o sekwencyjnym interfejsie dostępu, które będą poddane złączeniu.
Uwaga: Funkcja map będzie wywołana dla każdej sekwencji podanej jako argument,
a nie dla każdego elementu sekwencji.
Jeżeli przekazana funkcja zwróci nil lub kolekcję pustą, wtedy sekwencja wejściowa
zostanie pominięta i nie będzie dołączona do sekwencji wynikowej.
Wartością zwracaną jest leniwa sekwencja.
mapcat
1(mapcat reverse [[1 2] [3 4]]) ; => (2 1 4 3)
2(mapcat #(remove odd? %) [[1 2] [3 4 5]]) ; => (2 4)
(mapcat reverse [[1 2] [3 4]]) ; => (2 1 4 3)
(mapcat #(remove odd? %) [[1 2] [3 4 5]]) ; => (2 4)
Uwaga: Funkcja mapcat korzysta wewnętrznie z funkcji apply,
i w pewnych warunkach jej użycie może prowadzić do wygenerowania rezultatów obliczeń
zamiast leniwej sekwencji.
Jeżeli użyjemy mapcat do rekurencyjnego przekształcania i łączenia zagnieżdżonych
struktur, może zdarzyć się, że wywoływana przez nią funkcja apply wymusi
przeliczanie niektórych fragmentów. Aby temu zaradzić, można zamiast mapcat
zastosować funkcję, która zabezpiecza nas przed wystąpieniem takiego zjawiska:
mapcat
1(defn lazy-mapcat
2 "W pełni zwłoczny wariant funkcji mapcat."
3 [f kol]
4 (lazy-seq
5 (when (not-empty kol)
6 (concat (f (first kol)) (lazy-mapcat f (rest kol))))))
(defn lazy-mapcat
"W pełni zwłoczny wariant funkcji mapcat."
[f kol]
(lazy-seq
(when (not-empty kol)
(concat (f (first kol)) (lazy-mapcat f (rest kol))))))
Testy
Istnieje szereg funkcji, dzięki którym możemy sprawdzać właściwości sekwencji oraz ich elementów.
Predykaty
Sprawdzić, czy dana sekwencja spełnia pewne warunki odnośnie jej cech można z użyciem
odpowiednich predykatów. Funkcje te zwracają wartość true, gdy dana właściwość
występuje, a false, kiedy jest nieobecna.
Rezultat zwłoczny: NIE
Użycie:
(every? pred sek)– czy predykat prawdziwy dla każdego elementu;(not-any? pred sek)– czy predykat fałszywy dla każdego elementu;(not-every? pred sek)– czy predykat fałszywy dla choć jednego elementu;(empty? sek)– czy sekwencja nie ma żadnych elementów;(realized? sek)– czy sekwencja leniwa została przeliczona;(counted? sek)– czy sekwencja jest policzalna w skończonym czasie;(chunked-seq? sek)– czy sekwencja jest kawałkowana;(seq? wartość)– czy wartość jest sekwencją;(seqable? wartość)– czy wartość można reprezentować sekwencją;(sequential? wartość)– czy wartość ma sekwencyjny interfejs;(reduced? wartość)– czy wartość jest efektem wywołaniareduced.
Niepustość, not-empty
Dzięki funkcji not-empty jesteśmy w stanie upewnić się, że podana jako
argument sekwencja nie jest pusta. Jeżeli jest, zwrócona będzie wartość nil,
a w przeciwnym razie podana sekwencja.
Rezultat zwłoczny: (zależny od wejścia).
Użycie:
(not-empty sekwencja).
not-empty
(not-empty (seq '(1 2 3))) ; => (1 2 3)
(not-empty (seq ())) ; => nil
Sekwencje jako kolejki
Kolejka (ang. queue) to struktura danych o liniowym charakterze, która wykorzystywana jest do obsługi komunikacji związanej ze zdarzeniami, gdzie wymagane jest buforowanie wymienianych danych z zachowaniem kolejności ich napływania. Przypomina listę, ponieważ również mamy do czynienia z uporządkowanymi elementami, jednak jej interfejs dostępowy jest nieco uboższy. Podstawowymi operacjami jest umieszczenie elementu w kolejce i pobranie elementu.
Obiekty dodawane do kolejki trafiają na jej koniec, natomiast pobierane z niej są te, które znajdują się na początku. Taką podstawową kolejkę nazywamy w skrócie FIFO (z ang. First In, First Out – pierwszy na wejściu, pierwszy na wyjściu).
Istnieją także inne warianty kolejek, np. tzw. kolejki priorytetowe, używane w systemach operacyjnych do szeregowania zadań, które pozwalają na dostęp do elementów z użyciem kluczy określających ich priorytety.
Kolejki pełnią często rolę buforów w operacjach wejścia–wyjścia i w sieciowej transmisji strumieniowej. Ich użycie sprawia, że dane, które napływają bądź są wysyłane z opóźnieniami, mogą być dostarczane w stałym, średnim tempie i/lub w porcjach o jednakowej wielkości.
Kolejki Javy
W Javie można tworzyć kolejki z wykorzystaniem interfejsu Queue. Sprawia on, że na
podanej kolekcji można używać metod offer (do wstawiania elementów na początek
kolejki), poll (do pobierania elementów z końca kolejki) i peek (do sprawdzania
czoła kolejki bez usuwania elementu).
W Javie istnieje też mechanizm tzw. kolejek blokujących (ang. blocking queues). Przydają się one w programowaniu współbieżnym, np. do rozdzielania zadań na poszczególne wątki i do gromadzenia rezultatów, które mają dalej być przetwarzane nierównolegle lub prezentowane.
W interfejsie BlockingQueue znajdziemy te same metody, co w Queue, ale dodatkowo
w wariantach, dzięki którym możliwe jest oczekiwanie, aż kolejka nie będzie pusta
podczas pobierania elementu, a także oczekiwanie na możliwość dodania nowego
elementu, gdy kolejka jest całkowicie zapełniona. Opcjonalnie można podawać
maksymalne długości czasów oczekiwań na wykonanie operacji.
Kolejki w Clojure
Język Clojure wyposażono, chociaż jeszcze nie oficjalnie (kwiecień 2015), w obsługę
kolejek Javy. Za ich tworzenie odpowiada funkcja
clojure.lang.PersistentQueue/EMPTY, która nie doczekała się jeszcze literalnej
reprezentacji w postaci makra czytnika czy funkcji opakowującej.
1(def kolejka (conj (clojure.lang.PersistentQueue/EMPTY) :a :b :c))
2
3(seq kolejka) ; => (:a :b :c)
4(seq (pop kolejka)) ; => (:b :c)
(def kolejka (conj (clojure.lang.PersistentQueue/EMPTY) :a :b :c))
(seq kolejka) ; => (:a :b :c)
(seq (pop kolejka)) ; => (:b :c)
Sekwencje kolejkujące, seque
Dzięki funkcji seque możemy utworzyć sekwencję kolejkującą (ang. queued
sequence) na bazie podanej sekwencji. Mechanizmy funkcji zadbają o to, aby podana
w argumencie sekwencja była wyliczana, a wytwarzane przez nią rezultaty buforowane
z użyciem mechanizmu blokującej kolejki (interfejsy BlockingQueue
i LinkedBlockingQueue).
Działanie sekwencji kolejkującej pomaga obsługiwać sytuacje, w których sekwencja bazuje na zewnętrznym strumieniu wejściowym (np. gnieździe sieciowym) lub jej funkcja generująca jest nierównomiernie czasochłonna, a istnieje potrzeba buforowania, np. w celu uzyskiwania danych w stałym tempie i/lub przetwarzania stałej liczby elementów za każdym razem.
Funkcja występuje w trzech wariantach. Pierwszy przyjmuje sekwencję, a zwraca leniwą sekwencję powiązaną wewnętrznie z kolejką, której generatorem zawartości będzie sekwencja podana jako argument.
Drugi wariant seque przyjmuje dwa argumenty. Pierwszy z nich powinien określać
wielkość bufora kolejkującego (wyrażoną w liczbie elementów), a drugi być sekwencją
źródłową.
Trzeci wariant funkcji jest również dwuargumentowy, ale pierwszy argument powinien
być obiektem BlockingQueue, który zostanie powiązany z sekwencją.
Rezultat zwłoczny: TAK.
Użycie:
(seque sekwencja),(seque liczba sekwencja),(seque obiekt-kolejki sekwencja).
seque
1(def kolejka (seque
2 (repeatedly #(Thread/sleep 300))))
3(println "zapełnianie bufora...")
4(Thread/sleep 3000)
5(doseq [x (take 20 kolejka)]
6 (println "mam" (new java.util.Date)))
(def kolejka (seque
(repeatedly #(Thread/sleep 300))))
(println "zapełnianie bufora...")
(Thread/sleep 3000)
(doseq [x (take 20 kolejka)]
(println "mam" (new java.util.Date)))