

Polimorfizm to zbiór mechanizmów, dzięki którym ta sama konstrukcja języka programowania może być używana do przetwarzania danych różnych rodzajów. Dzięki niemu możemy korzystać z wyabstrahowanych, generycznych operacji, zyskując na czasie i czytelności kodu. Polimorfizm w Clojure to przede wszystkim obsługa wieloargumentowości, multimetod, protokołów i rekordów, a także korzystanie z interfejsów Javy.
Polimorfizm
Polimorfizm (ang. polymorphism, z gr. polis – wiele i morfi – postać, kształt), w dosłownym tłumaczeniu wielopostaciowość, jest zbiorem mechanizmów języka programowania, dzięki którym te same konstrukcje mogą być używane w odniesieniu do danych o różnych charakterystykach, na przykład o różnych typach.
Używając bardziej ogólnych terminów, polimorfizmem możemy nazwać możliwość tworzenia uogólnionych interfejsów do pewnych klas operacji, które można przeprowadzać na danych różnych rodzajów.
Operowanie na różnorodnych danych z użyciem tych samych sposobów (np. funkcji) pozwala tworzyć warstwy abstrakcji, które upraszczają wyrażanie rozwiązań problemów. Tworzenie i modernizowanie programów zajmuje wtedy mniej czasu, a kod jest czytelniejszy.
Prostym przykładem polimorfizmu może być obecna w wielu językach programowania
konstrukcja print. Pozwala ona wysyłać na standardowe wyjście łańcuchy znakowe,
które reprezentują wartości podawanych argumentów, chociaż te ostatnie mogą być
danymi różnych typów: pojedynczymi znakami i łańcuchami znakowymi, liczbami
całkowitymi bądź zmiennoprzecinkowymi itp.
Inny przykład to wektor odniesień do obiektów umieszczonych w pamięci. Każdy z jego elementów może mieć inny typ, ale struktura danych umożliwia grupowanie ich wszystkich, ponieważ rodzaje obiektów, z których się składa, stanowią ich nadtyp (tzw. polimorfizm inkluzyjny) bądź zawierają dodatkowe pola znacznikowe, określające typy przechowywanych danych (tzw. rekordy wariantowe, przykład tzw. polimorfizmu doraźnego).
Zdefiniowaliśmy polimorfizm jako mechanizm uniezależniania operacji od typów danych, ale również od innych cech charakterystycznych. Owe cechy mogą być specyficzne dla języka bądź wskazywane przez programistę. Nie muszą być koniecznie związane z typami w rozumieniu ich klasycznej definicji. Na przykład dwa wektory przechowujące tylko liczby typu całkowitego mogą różnić się wyłącznie długością, a wtedy polimorfizmem będzie operacja ich przetwarzania, która doprowadzi do wywołania różnych wariantów funkcji w zależności od liczby elementów. Idąc tym tropem, polimorfizmem nazwiemy też zautomatyzowane wywoływanie funkcji obsługujących tę samą operację zależnie od charakteru wartości przekazanych jako argumenty (np. mieszczeniu się w określonym zakresie czy dopasowaniu do jakiegoś wzorca).
Dzięki polimorfizmowi możliwe jest tzw. programowanie generyczne (ang. generic programming), zwane też programowaniem uogólnionym – styl tworzenia oprogramowania, w którym algorytmy mogą operować na danych o właściwościach nieznanych lub znanych tylko częściowo podczas ich implementowania.
W kolejnych sekcjach wyjaśnione będą teoretyczne podstawy polimorfizmu i przedstawiona zostanie klasyfikacja jego różnych rodzajów. Jeżeli celem lektury tego rozdziału jest znalezienie praktycznego sposobu na rozwiązanie jednego z poniższych problemów, można od razu przenieść się do odpowiednich sekcji:
-
Gdy tworzona funkcja ma przyjmować argumenty, których wartości powinny być przekształcane do wartości innych typów (ze względu na kompatybilność lub wydajność), użyjemy koercji typu.
-
Gdy chcemy zmienić dane jednego typu w dane innego, możemy skorzystać z konwersji typu.
-
Gdy szukamy sposobu na ponowne definiowanie funkcji, która już istnieje, aby zastąpić ją nową wersją, pomocne będzie nadpisywanie funkcji.
-
Gdy chcemy utworzyć warianty tej samej funkcji, które będą różniły się liczbą przyjmowanych argumentów, przyda się przeciążanie argumentowości.
-
Gdy nasza funkcja ma mieć różne warianty w zależności od typu wartości przekazywanej jako pierwszy argument, użyjemy protokołów. Pozwolą one też na przypisywanie nowych wariantów funkcji do nowo tworzonych typów danych, nieznanych podczas deklarowania operacji.
-
Gdy nasza funkcja ma mieć różne warianty w zależności od typów lub innych właściwości wartości przekazywanych jako jej dowolne argumenty, wybierzemy multimetody. One również mogą być rozszerzane o nowe warianty operacji.
-
Gdy zamierzamy utworzyć rekordowy typ danych, przypominający w użyciu mapę, którego dodatkowe operacje mogą być opcjonalnie opisane protokołami, skorzystamy z rekordów.
-
Gdy chcemy utworzyć obiektowy typ danych, który nie będzie wyposażony w interfejs mapy, lecz również pozwoli na implementowanie protokołów, spróbujemy obiektowych typów własnych.
Problem wyrazu
Niektóre mechanizmy polimorficzne związane z obsługą różnych typów danych mogą być sposobem na poradzenie sobie z tzw. problemem wyrazu (ang. expression problem), który został sformułowany przez Philipa Waldera z Bell Labs w roku 1998. Wcześniej nazywany był on też problemem ekspresywności (ang. expressiveness problem).
Termin „ekspresywność” odnosi się tu do tzw. siły wyrazu (ang. expressive power) języków programowania. Oznacza ona zdolność do wyrażania algorytmów w przejrzysty i zwięzły sposób. W praktyce języki o dużej sile wyrazu wyposażone będą w konstrukcje składniowe i mechanizmy pozwalające tak abstrahować problemy, że ich reprezentacje w kodzie źródłowym będą przejrzyste oraz czytelne, tzn. zrozumiałe, jednoznaczne i bez zbędnych powtórzeń.
Języki, które pozwalają dodawać nowe konstrukcje składniowe będą miały większą siłę wyrazu od tych, gdzie polegamy wyłącznie na syntaktyce zaproponowanej przez ich twórców. Jednak składnia to nie wszystko, równie ważne są też zakorzenione w paradygmacie sposoby abstrahowania rodzajów danych i operacji, które można na tych rodzajach wykonywać.
W niepublikowanym oficjalnie opracowaniu badacz streścił problem wyrazu następująco:
Problem Wyrazu jest nową nazwą starego problemu. Celem jest definiowanie typu danych z użyciem przypadków w taki sposób, że do typu możemy dodawać nowe przypadki oraz nowe funkcje operujące na tym typie, bez rekompilacji istniejącego kodu i z zachowaniem bezpieczeństwa statycznego typizowania (np. bez rzutowania).
[…]
To, czy język potrafi rozwiązać Problem Wyrazu, jest dobitnym wskaźnikiem jego ekspresyjności.
Czym są wspomniane przypadki? Ogólnie rzecz ujmując, możemy nazwać je przypadkami zastosowań, a bardziej technicznie interfejsami lub protokołami dostępu do danych.
Program, nawet w języku dynamicznie typizowanym, składa się z danych określonych typów i z operacji, które na danych tych typów możemy przeprowadzać. Kwestią problematyczną jest znalezienie sposobu na to, aby dodawać obsługę nowych przypadków użycia, czyli skojarzeń nowych operacji z danymi istniejących typów lub nowych typów danych, na których dałoby się przeprowadzać już zdefiniowane operacje. Powinno być to możliwe bez konieczności zmiany i ponownego kompilowania wcześniej napisanego kodu i bez korzystania z rzutowania typów.
Gdy uda nam się rozwiązać problem wyrazu, będziemy mogli pisać na przykład takie programy, w których operacje wyrażane funkcjami można w przyszłości rozszerzać o obsługę rodzajów danych nieznanych w momencie ich tworzenia, w dodatku bez konieczności zmieniania wcześniej napisanych funkcji.
Aby zademonstrować problem, Walder zaproponował tabelę podobną do poniższej:
| definicje typów: | ||
|---|---|---|
class Liczba |
class Łańcuch |
|
| warianty operacji: |
def plus(a, b); … end |
def plus(a, b); … end |
def równe?(a, b); … end |
def równe?(a, b); … end |
|
end |
end |
|
Widzimy, że w językach zorientowanych obiektowo (tu przykłady w Rubym) łatwo możemy dodawać nowe typy danych. Wystarczy utworzyć nową klasę. Trudniej dodawać operacje (wyrażane metodami), ponieważ wymaga to do dopisania czegoś do istniejących już klas. W języku Ruby poradzimy sobie z tym na przykład przez domieszkowanie modułów (chociaż przez purystów może to uznane za zmienianie istniejącego kodu), a w obiektowych językach typizowanych statycznie przez użycie tzw. klas abstrakcyjnych czy mechanizmu szablonów. Jednak w tych drugich przypadkach będziemy musieli z góry określić, że dana klasa powinna w przyszłości mieć zdolność do bycia rozszerzaną.
W dalszej części pokazany będzie nieco bardziej elegancki sposób radzenia sobie z tą kwestią w językach zorientowanych obiektowo, z użyciem tzw. podwójnego rozdzielania metod.
Spójrzmy, jak wyglądałaby podobna tabela dla języka zorientowanego funkcyjnie, czyli dla Clojure, gdybyśmy na moment zapomnieli o omawianych dalej polimorficznych mechanizmach:
| warianty obsługi typów: | ||||
|---|---|---|---|---|
| definicje operacji: |
||||
(defn plus [a b] (cond |
(integer? a) … |
(string? a) … |
)) |
|
(defn równe? [a b] (cond |
(integer? a) … |
(string? a) … |
)) |
|
W przykładzie dla języka Clojure z łatwością dodamy obsługę nowych operacji (w postaci funkcji), ale trudniej będzie nam dodawać obsługę nowych typów. Pojawienie się nowego rodzaju danych, który należy obsługiwać nieco inaczej, spowoduje konieczność modyfikowania istniejących funkcji.
W językach funkcyjnych, szczególnie z silnym typizowaniem, ogólnym sposobem na zgeneralizowaną obsługę danych różnych typów jest implementowanie tzw. algebraicznego typu danych (ang. algebraic data type, skr. ADT). Jest to typ złożony (ang. composite type), który pozwala grupować elementy innych (dowolnych) typów. Przykładami mogą być tzw. typy produktowe (krotki, rekordy) czy typy sumaryczne (rekordy z wariantami). Operacje przeprowadzane na typie algebraicznym mogą być uszczegóławiane przez tworzenie nowych funkcji, chociaż typ danych nie zmienia się. Wadą takiego podejścia będzie jednak konieczność tworzenia osobnych, dodatkowych funkcji, o których trzeba pamiętać, gdy operuje się na strukturach konkretnych rodzajów. Użycie typu algebraicznego nie oznacza automatycznie, że będziemy mieli do czynienia z abstrakcyjnymi, polimorficznymi operacjami, ani tym bardziej, że rozwiążemy problem wyrazu.
Wróćmy jednak do wcześniejszej kwestii: w jaki sposób możemy sobie poradzić z problemem wyrazu w Clojure – języku dynamicznie typizowanym, którego system typów bazuje na obiektowo zorientowanej platformie gospodarza?
Poszukujemy rozwiązania, które spełnia trzy podstawowe warunki:
-
Możliwość dodawania nowych typów (rodzajów) danych i nowych operacji ich obsługi, a także łatwego rozszerzania istniejących operacji tak, aby działały dla nowych typów danych, nieznanych w momencie tworzenia obsługi operacji.
-
Brak wymogu powielania istniejącego kodu czy jego zmiany.
-
Otwarta możliwość rozszerzania programu o nowe typy i operacje (z użyciem rozszerzeń pochodzących z różnych źródeł, których można używać jednocześnie).
Chociaż Clojure jest językiem dynamicznie typizowanym, nie oznacza to, że informacje o typach nie są przydatne. Typów potrzebujemy choćby po to, aby wybierać takie warianty generycznych operacji, które nadają się do operowania na strukturach danych o pewnych właściwościach. Na przykład inaczej zrealizujemy algorytm dodawania do siebie dwóch łańcuchów znakowych, a inaczej wartości numerycznych.
Zamiast różnych funkcji przeznaczonych dla różnych typów chcielibyśmy mieć jedną, generyczną funkcję, która potrafi w jakiś sposób wykryć z jaką strukturą ma do czynienia i zaaplikować odpowiednią dla niej operację – możliwe, że realizowaną jako inna funkcja, chociaż nie jest to warunkiem koniecznym.
Przykładem takiej wbudowanej, polimorficznej funkcji jest conj, która
posługuje się innym algorytmem, gdy jako argument podamy wektor, innym, gdy będzie to
lista, a jeszcze innym w przypadku podania mapy:
(conj [1 2] 3) ; => [1 2 3]
(conj '(1 2) 3) ; => (1 2 3)
(conj {:a 2} {:b 4}) ; => {:a 2 :b 4}
Czy jesteśmy w stanie samodzielnie skonstruować funkcję, którą można rozszerzać o obsługę nowych typów danych, bez jej przepisywania, a tym samym rozwiązać problem wyrazu? W Clojure możemy poradzić sobie z tym na kilka sposobów:
-
Wprowadzając wydajny, dynamiczny polimorfizm, bazujący na typach rekordowych i protokołach (pozwala on na rozdzielanie wywołań w zależności od typu pierwszego argumentu przekazywanego do funkcji).
-
Wprowadzając wydajny, dynamiczny polimorfizm, bazujący na obiektowych typach własnych i protokołach (działa podobnie do rekordów, ale nie wymusza interfejsu w postaci asocjacyjnej struktury danych).
-
Korzystając z multimetod – elastycznego mechanizmu dynamicznego polimorfizmu, w którym decyzja o wywołaniu konkretnej implementacji operacji zależy od rezultatów obliczeń przeprowadzonych na dowolnych argumentach przekazanych do funkcji.
-
Implementując własne operacje polimorficzne, podobne do multimetod:
-
w postaci funkcji wyższego rzędu, które będzie można łatwo nadpisywać (zachowując odwołania do oryginałów) i uzależniać wynik od typu argumentów lub innych właściwości;
-
w postaci funkcji, które będą korzystały ze współdzielonej, globalnej zmiennej, zawierającej mapę odwołań do konkretnych implementacji w zależności od typu argumentów lub innych właściwości.
-
Rodzaje polimorfizmu
Możemy wyróżnić dwa podstawowe rodzaje polimorfizmu w zależności od etapu, na którym dochodzi do zastosowania mechanizmów jego obsługi:
-
statyczny, zwany też polimorfizmem czasu kompilacji (ang. compile-time polymorphism);
-
dynamiczny, zwany też polimorfizmem czasu uruchamiania lub polimorfizmem uruchomieniowym (ang. runtime polymorphism).
Polimorfizm statyczny realizowany jest w trakcie kompilacji, a dynamiczny podczas uruchamiania programu. Powszechnym przykładem zastosowania polimorfizmu statycznego jest przeciążanie funkcji i operatorów (w zależności od liczby argumentów), a polimorfizmu dynamicznego niektóre formy dziedziczenia i tzw. funkcje wirtualne w obiektowych językach programowania.
Zazwyczaj w językach statycznie typizowanych już podczas procesu kompilacji można wykryć, które wersje przeciążonych funkcji lub metod będą właściwymi do obsługi przekazywanego zestawu argumentów o określonych typach, a w językach typizowanych dynamicznie wiedza o właściwościach argumentów dostępna będzie dopiero po rozpoczęciu działania programu.
Języki dynamiczne mogą w czasie uruchamiania implementować te same mechanizmy polimorficzne, które w językach nie pozwalających na zmiany kodu w trakcie działania programu i/lub ze statycznym typizowaniem będą realizowane podczas kompilacji.
Przykładem powyższego jest przeciążanie metod. W języku C++ będzie ono realizowane
w czasie kompilowania programu, a w Javie w trakcie jego uruchamiania, chyba że
w podczas ich definiowania użyto modyfikatora static, private lub final.
W Clojure nie mamy do czynienia z przeciążaniem funkcji, ale z przeciążaniem ich argumentowości. Poza tym kryterium wyboru konkretnego ciała funkcji jest liczba argumentów, a nie ich typy. Przeciążanie tego rodzaju będzie techniką polimorfizmu statycznego, ponieważ właściwy obiekt uruchomieniowy określony zostanie w czasie kompilacji (nawet, jeżeli na poziomie języka Clojure funkcja wieloargumentowościowa jest jednym obiektem).
Możemy więc zauważyć, że współczesne języki programowania wysokiego poziomu mogą implementować polimorfizm na wiele sposobów i czasem to, czy będziemy mieli do czynienia z wariantem statycznym czy z dynamicznym zależy od konkretnego języka, a nawet od zastosowanych w kodzie konstrukcji.
Poza rodzajami polimorfizmu ze względu na etap zastosowania pewnych mechanizmów (w trakcie kompilacji lub w czasie uruchamiania programu) możemy też klasyfikować wielopostaciowe konstrukcje w zależności od osiąganego z ich pomocą celu czy wykorzystywanych instrumentów języka.
Polimorfizm doraźny
Najczęściej wykorzystywanym w Clojure rodzajem polimorfizmu jest tzw. polimorfizm doraźny (ang. ad hoc polymorphism), czyli taki, gdzie możemy stwarzać jednolite interfejsy obsługi pewnych operacji, które mogą być potem stosowane względem danych o różnej charakterystyce (np. o różnych typach).
Ten rodzaj polimorfizmu bazuje zwykle na decyzji odnośnie tego który wariant operacji zostanie zrealizowany, gdy odwołamy się do abstrakcyjnej, polimorficznej funkcji.
Przykładami polimorfizmu doraźnego będą:
- protokoły,
- multimetody,
- a także przeciążanie argumentowości i nadpisywanie funkcji.
Polimorfizm inkluzyjny
W interakcjach z systemami typów platformy gospodarza znajdziemy też mechanizmy polimorfizmu inkluzyjnego (ang. inclusive polymorphism), zwanego też polimorfizmem podtypowym (ang. subtype polymorphism), który bazuje na hierarchii typów. Dzięki niemu jesteśmy w stanie tworzyć operacje obsługujące wartości pewnych typów i automatycznie wszystkich ich podtypów.
Polimorfizm inkluzyjny jest powszechnie wykorzystywany w obiektowych językach programowania, ponieważ mamy tam do czynienia z dziedziczeniem. Wyobraźmy sobie klasę w języku Ruby i klasę pochodną utworzoną na jej bazie. Pierwsza będzie reprezentowała wartość numeryczną podanej liczby, a druga jej formę tekstową. W przypadku typów numerycznych jest to niecodzienny zabieg, lecz używamy go tu, aby ukazać pewne mechanizmy rozdzielania wywołań.
1class Liczba
2 attr_reader :value
3 def initialize(v) @value = v.to_f end
4 def dodaj_liczbe(other) self.class.new(@value + other.value) end
5end
6
7class Tekstowa < Liczba
8 def initialize(txt) @value = txt.to_s end
9 def dodaj_liczbe(other)
10 self.class.new(self.class.superclass.new(@value).value + other.value)
11 end
12end
13
14x = Liczba.new(12)
15y = Tekstowa.new("100")
16
17y.dodaj_liczbe(x).value
18# => 112
class Liczba
attr_reader :value
def initialize(v) @value = v.to_f end
def dodaj_liczbe(other) self.class.new(@value + other.value) end
end
class Tekstowa < Liczba
def initialize(txt) @value = txt.to_s end
def dodaj_liczbe(other)
self.class.new(self.class.superclass.new(@value).value + other.value)
end
end
x = Liczba.new(12)
y = Tekstowa.new("100")
y.dodaj_liczbe(x).value
# => 112
Implementowana w pochodnej klasie Tekstowa metoda dodaj_liczbe() pozwala nam
podać drugi obiekt, który powinien mieć pole value, aby dodawać jego wartość do
wartości liczbowej pochodzącej z bieżącego obiektu i produkować nową instancję
zawierającą sumę. Argument metody musi być numeryczny i jest to celowy wybór, który
ma podkreślić, że w celu obsługi dodawania korzystamy wyłącznie z dziedziczenia, nie
interesuje nas transformacja argumentu.
Możemy zauważyć, że nie rozwiązuje to problemu wyrazu, ponieważ w Rubym wybór
implementacji wywoływanej metody zależy tylko od klasy, dla której metoda o podanej
nazwie jest wywoływana, a więc mamy do czynienia z tzw. pojedynczą dyspozycją
(ang. single dispatch). Łatwo dodamy nowe podtypy, jednak będą one użyteczne
w kontekście napisanego wcześniej kodu pod warunkiem, że argument metody
dodaj_liczbe() będzie kompatybilny z argumentem tej metody w klasie bazowej.
Łatwo dodamy nowy podtyp Tekstowa i specyficzne implementacje metod, lecz nie mamy
kontroli nad tym jak instancje naszej nowej klasy będą traktowane przez metody klasy
bazowej Liczba. Próba wywołania metody dodaj_liczbe() na instancji Liczba
z argumentem klasy Tekstowa zakończy się niepowodzeniem.
Żeby poradzić sobie z powyższym możemy zbudować mechanizm podwójnej dyspozycji (ang. double dispatch), w którym wybór implementacji metody sumującej zależy nie tylko od klasy, ale również od typu przekazywanego argumentu. Będziemy potrzebowali dwóch metod: sumującej i przekształcającej argument do wartości, którą metoda sumująca może zaakceptować.
1class Liczba
2 attr_reader :value
3 def initialize(v) @value = v.to_f end
4
5 def dodaj(other)
6 return self.class.new(@value + other.value) if other.is_a? Liczba
7 a, b = other.coerce(self)
8 a.dodaj(b)
9 end
10end
11
12class Tekstowa < Liczba
13 def initialize(txt) super(txt.to_f); @txt = txt.to_s end
14 def to_s = @txt
15
16 def coerce(other)
17 case other
18 when Liczba then [self.class.new(other.value.to_s), self]
19 when Numeric then [self.class.new(other.to_s), self]
20 else raise TypeError, "Tekstowa nie współgra z #{other.class}"
21 end
22 end
23
24 def dodaj(other) self.class.new(super(other).value.to_s) end
25end
26
27x = Liczba.new(12)
28y = Tekstowa.new("100")
29
30x.dodaj(y).value # => 112.0
31y.dodaj(x).value # => 112.0
class Liczba
attr_reader :value
def initialize(v) @value = v.to_f end
def dodaj(other)
return self.class.new(@value + other.value) if other.is_a? Liczba
a, b = other.coerce(self)
a.dodaj(b)
end
end
class Tekstowa < Liczba
def initialize(txt) super(txt.to_f); @txt = txt.to_s end
def to_s = @txt
def coerce(other)
case other
when Liczba then [self.class.new(other.value.to_s), self]
when Numeric then [self.class.new(other.to_s), self]
else raise TypeError, "Tekstowa nie współgra z #{other.class}"
end
end
def dodaj(other) self.class.new(super(other).value.to_s) end
end
x = Liczba.new(12)
y = Tekstowa.new("100")
x.dodaj(y).value # => 112.0
y.dodaj(x).value # => 112.0
W powyższym przykładzie rozwiązujemy problem wyrazu tworząc mechanizm dynamicznie parametryzowanej koercji, podobnie jak jest to realizowane we wbudowanych klasach numerycznych Ruby’ego.
Poza metodą dodaj() pojawia się metoda coerce(), której zadaniem jest konwersja
wartości argumentu do postaci kompatybilnej z dodaj() z klasy Liczba. Zwraca ona
dwuelementową tablicę, której pierwszy element to nowy obiekt bieżącej klasy,
zbudowany na bazie podanego argumentu, a drugi to bieżący obiekt.
W ten sposób w klasach pochodnych rozdzielamy wywołania zarówno po klasie, dla której
metoda jest wzywana, jak i po klasie przekazywanego do metody argumentu, dzięki
wywołaniu coerce() obecnemu w bazowej implementacji metody dodaj() (z klasy
Liczba).
Upraszczając: klasa Liczba nic „nie wie” o podklasie Tekstowa, ale ta ostatnia
może wpływać na to, jaki kształt będzie miał argument przekazywany do metody
dodaj() klasy Liczba, żeby dało się go sumować z wartością liczbową z pola
value.
W Clojure najprostszym przykładem polimorfizmu inkluzyjnego jest koercja typu. Możemy też zaliczyć do niego niektóre zastosowania protokołów. Właśnie te ostatnie będą jednym z dwóch sposobów (obok multimetod) na idiomatyczne radzenie sobie z problemem wyrazu.
Polimorfizm parametryczny
W języku Clojure mamy również do czynienia z polimorfizmem parametrycznym (ang. parametric polymorphism), w którym możemy tworzyć funkcje obsługujące parametry (wartości przekazywanych argumentów) dowolnych typów.
Istotną różnicą względem polimorfizmu doraźnego jest to, że mamy do czynienia z jedną operacją, a nie jej wieloma wariantami i mechanizmem decyzyjnym. Wiąże się to z koniecznością dostarczenia precyzyjnej implementacji obsługi danego parametru (lub zestawu parametrów) już podczas wczesnych etapów interpretacji kodu źródłowego.
Przykładem polimorfizmu parametrycznego może być znany z C++ system szablonów czy
klas i metod generycznych w Javie. W Clojure polimorfizm tego rodzaju zaobserwujemy
np. w funkcji tożsamościowej, funkcji stałej czy
konstrukcjach map, reduce i podobnych – operują one na
wartościach lub kolekcjach wartości dowolnych typów.
Możemy też samodzielnie implementować ten rodzaj polimorfizmu, definiując funkcje wyższego rzędu. Często będziemy mieć wtedy funkcję, która pobiera argument dowolnego typu (bądź kolekcję takich argumentów), a dodatkowo inną funkcję (tzw. operator) używaną do obsługi właśnie takiego rodzaju danych.
Polimorfizm typów danych
W językach programowania wykorzystujących systemy typów, w których mamy do czynienia z możliwością tworzenia relacji między typami (wyróżnianiem podtypów i nadtypów) często spotkamy się z polimorficznymi mechanizmami wykorzystującymi ten sposób oznaczania danych.
Za polimorfizm bazujący na typach możemy uznać wtedy dziedziczenie klas (jeżeli dochodzi do rozdzielania wywołań metod) czy obsługę argumentów, które nie są deklarowanych typów, lecz typów pozostających z nimi w relacji.
Warto zauważyć, że konkretne implementacje polimorfizmu bazującego na typach znajdziemy zarówno we wspomnianej wyżej rodzinie mechanizmów polimorfizmu parametrycznego, jak również w polimorfizmie doraźnym.
Ukazany wcześniej przykład dwojakiej dyspozycji w Rubym, wykorzystującej polimorfizm podtypowy, jest wyraźnym przykładem polimorfizmu typów danych, jednak operacje rozdzielania bazujące na typach są związane nie tylko z obiektowo zorientowanym paradygmatem programowania.
Proste operacje polimorficzne
Pewne operacje na typach danych możemy uznać za proste mechanizmy polimorficzne, gdyż pozwalają traktować wartości danego typu tak, jakby były wartościami innego. Te operacje to:
- konwersja – tworzenie wartości nowego typu na bazie wartości innego typu;
- rzutowanie – traktowanie wartości danego typu jak wartości innego typu;
- koercja – konwersja typu wartości przekazywanej jako argument funkcji.
Warto na wstępie zaznaczyć, że w praktyce niektóre z wymienionych terminów używane bywają zamiennie z uwagi na nieprecyzyjne konwencje nazewnictwa i różnice w szczegółach działania kompilatorów i maszyn wirtualnych.
Konwersja typu
Konwersja typu (ang. type conversion) to operacja przekształcania wartości jednego typu do wartości innego typu danych. Podczas konwersji powstaje nowa wartość na bazie odpowiednio zmienionych danych struktury źródłowej.
Przykładem konwersji może być zmiana łańcucha znakowego reprezentującego liczbę
całkowitą w wartość numeryczną typu całkowitego lub zmiana wartości logicznej
w odpowiadający jej symboliczny napis. Z konwersją będziemy też mieli do czynienia,
gdy zmienimy liczbę całkowitą w jej dłuższy lub krótszy odpowiednik, tworząc nowy
obiekt – np. w konwersji wartości typu Integer do wartości typu Long czy Short.
W Clojure do konwersji typu służą odpowiednie funkcje – zazwyczaj te same, które używane są też do tworzenia nowych wartości określonych typów. Możemy między innymi dokonywać konwersji:
(byte wartość)– do bajtu,(short wartość)– do liczby całkowitej krótkiej,(int wartość)– do liczby całkowitej,(long wartość)– do liczby całkowitej długiej,(float wartość)– do liczby zmiennoprzecinkowej,(double wartość)– do liczby zmiennoprzecinkowej podwójnej precyzji,(bigdec wartość)– do liczby dziesiętnej nieograniczonej,(bigint wartość)– do liczby całkowitej nieograniczonej (typ Clojure),(biginteger wartość)– do liczby całkowitej nieograniczonej (typ Javy),(num wartość)– do obiektu wyrażającego liczbę,(rationalize wartość)– do liczby ułamkowej,(booleans tablica)– do tablicy wartości logicznych,(bytes tablica)– do tablicy bajtów,(chars tablica)– do tablicy znaków,(shorts tablica)– do tablicy liczb całkowitych krótkich,(ints tablica)– do tablicy liczb całkowitych,(longs tablica)– do tablicy liczb całkowitych długich,(floats tablica)– do tablicy liczb zmiennoprzecinkowych,(doubles tablica)– do zmiennoprzecinkowych podwójnej precyzji.
1(str 123) ; => "123"
2(int 123M) ; => 123
3(long 123M) ; => 123
4(str false) ; => "false"
5(int \a) ; => 97
6(char 97) ; => \a
7
8(Integer/parseInt "1234") ; => 1234
9(String/valueOf 1234) ; => "1234"
(str 123) ; => "123"
(int 123M) ; => 123
(long 123M) ; => 123
(str false) ; => "false"
(int \a) ; => 97
(char 97) ; => \a
(Integer/parseInt "1234") ; => 1234
(String/valueOf 1234) ; => "1234"
W przypadku kolekcji języka Clojure mamy do czynienia z interfejsem
java.util.Collection, którego konstruktor jest w stanie dokonywać konwersji.
Niektóre funkcje czynią z tego użytek.
1(java.util.ArrayList. [1 2 3]) ; => [1 2 3]
2(java.util.HashMap. {"a" 1}) ; => {"b" 2, "a" 1}
3(into [] '(1 2 3)) ; => [1 2 3]
4(into #{} '(1 2 3)) ; => #{1 2 3}
5(vec '(1 2 3)) ; => [1 2 3]
6(set '(1 2 3)) ; => #{1 2 3}
(java.util.ArrayList. [1 2 3]) ; => [1 2 3]
(java.util.HashMap. {"a" 1}) ; => {"b" 2, "a" 1}
(into [] '(1 2 3)) ; => [1 2 3]
(into #{} '(1 2 3)) ; => #{1 2 3}
(vec '(1 2 3)) ; => [1 2 3]
(set '(1 2 3)) ; => #{1 2 3}
Rzutowanie typu
Rzutowanie typu (ang. type casting) to operacja zmiany oznaczenia typu danych z pozostawieniem wartości w postaci identycznej z oryginalną. Polega na potraktowaniu wartości określonego typu danych tak, jakby była wartością innego typu, zazwyczaj w celu przeprowadzenia na niej operacji, której na oryginalnym typie nie można byłoby wykonać.
Rzutowanie bywa często używane do inicjowania nowo tworzonego obiektu wartością innego obiektu lub do przeprowadzenia operacji arytmetycznej, która wymaga użycia wartości o określonym typie.
Uwaga: Często spotkamy się z zastosowaniem terminu „rzutowanie” dla oznaczenia konwersji typów. Wynika to z nomenklatury przyjętej w niektórych środowiskach (np. w Javie). Warto zauważyć, że w niektórych konwersjach typów będzie dochodziło również do rzutowania.
Przykładem rzutowania może być potraktowanie jednobajtowej wartości jak znaku
reprezentowanego jej kodem (np. w języku C), albo liczby całkowitej typu Integer
jak liczby typu Long, aby w efekcie obliczeń uzyskać wynik typu Long.
W obiektowych systemach typów z rzutowaniem będzie często związany warunek mówiący, że typ obiektu, który ma być rzutowany, powinien być związany relacją dziedziczenia z obiektem, do którego jest rzutowany. Nie powstaje wtedy nowy obiekt, lecz obecny jest traktowany tak, jakby był instancją klasy bazowej lub pochodnej. Na przykład w Javie:
1String s = "napis"; /* obiekt typu String */
2Object o = value; /* automatyczne rzutowanie do nadtypu Object */
3String x = (String) o; /* jawne rzutowanie do podtypu String */
String s = "napis"; /* obiekt typu String */
Object o = value; /* automatyczne rzutowanie do nadtypu Object */
String x = (String) o; /* jawne rzutowanie do podtypu String */
Powyższe przykłady obrazują tzw. rzutowanie referencyjne, ponieważ zmienne s,
o i x nie zawierają obiektów, ale odniesienia do nich. Przypomina to rzutowanie
typów wskaźnikowych w języku C – zmienne wskaźnikowe zajmują tyle samo miejsca,
niezależnie od tego, na dane jakich typów wskazują, wystarczy więc odpowiednio je
oznaczyć, korzystając z operatora rzutowania:
char *c = "abc";
void *p = c;
char *x = (char *) p;
W Clojure praktycznie nie będziemy mieli do czynienia z bezpośrednim rzutowaniem typów. Na przykład podczas wykonywania konwersji typu używana w tym celu funkcja może skorzystać z operatora rzutowania Javy (bądź innej platformy gospodarza), ale nie będzie to operacja, którą programista wyrazi wprost. Możemy dowiadywać się, które konstrukcje języka Clojure będą korzystały z rzutowania, jednak bez kontekstu trudno będzie nam szybko odróżnić tę operację od konwersji.
1;; rzutowanie dokonywane wewnętrznie przez funkcję int:
2
3(int "1234")
4
5; >> java.lang.ClassCastException:
6; >> java.lang.String cannot be cast to java.lang.Character
7
8;; konwersja do java.lang.String (brak rzutowania):
9
10(str 1234)
11
12; => "1234"
13
14;; konwersja wykorzystująca rzutowanie do java.lang.Integer:
15
16(int 1234M)
17
18; => 1234
;; rzutowanie dokonywane wewnętrznie przez funkcję int:
(int "1234")
; >> java.lang.ClassCastException:
; >> java.lang.String cannot be cast to java.lang.Character
;; konwersja do java.lang.String (brak rzutowania):
(str 1234)
; => "1234"
;; konwersja wykorzystująca rzutowanie do java.lang.Integer:
(int 1234M)
; => 1234
-
Pierwsze wyrażenie wywołuje metodę Javy odpowiedzialną za jawną konwersję typu, która wewnętrznie będzie rzutowaniem. Niestety, rzutowanie łańcuchów znakowych do typu całkowitego nie jest możliwe i zgłaszany jest wyjątek.
-
Wyrażenie drugie to konwersja. Chociaż nazwa funkcji sugeruje jakobyśmy mieli do czynienia z rzutowaniem (przez analogię do obsługi typów numerycznych), w istocie jest to budowanie nowego obiektu i konwersja liczby całkowitej do łańcucha znakowego.
-
Przedostatni przykład to zmiana liczby typu
Longw krótszą (typuInteger). Nawet jeżeli w JVM dojdzie do rzutowania, rezultatem wywołania funkcjiintw Clojure będzie stworzenie nowej wartości (nowego obiektu typujava.lang.Integer). Będzie to więc rzutowanie z inicjowaniem, czyli konwersja.
Z rzutowaniem będziemy mieli najczęściej do czynienia wtedy, gdy dokonają go
wywoływane z poziomu konstrukcji języka Clojure operatory platformy gospodarza. Na
przykład funkcja int wewnętrznie rzutuje podaną wartość do typu Integer
i na tej podstawie tworzy nowy obiekt. Efektywnie mamy do czynienia z konwersją, ale
na poziomie JVM wykorzystywane może być właśnie rzutowanie.
Rzutowanie używane bywa również w odniesieniu do typów podstawowych. Dzięki temu możemy tworzyć wydajne pętle czy przeprowadzać szybkie rachunki arytmetyczne.
1(+ (double 2) 5)
2(let [a (long 3)] a)
3(fn [a] (int a))
4(loop [a (int 0)] (when (< a 10000) (recur (inc a))))
(+ (double 2) 5)
(let [a (long 3)] a)
(fn [a] (int a))
(loop [a (int 0)] (when (< a 10000) (recur (inc a))))
Funkcje long i double, służące do konwersji i rzutowania
typów, zwrócą wartości typów podstawowych (nieopakowanych) pod warunkiem, że
konstrukcja, do której trafią te wartości, będzie potrafiła z nich skorzystać.
Do ewentualnych optymalizacji dojdzie na etapie kompilacji programu.
Zobacz także:
- „Rzutowanie typów numerycznych”, rozdział IV.
Koercja typu
Koercja typu (ang. type coercion) przypomina konwersję i jest operacją, która polega na przekształcaniu wartości argumentu przekazanego do wywołania funkcji do wartości innego, oczekiwanego typu. Realizowana jest najczęściej z użyciem rzutowania lub konwersji typu, a w Clojure również z wykorzystaniem tzw. sugerowania typu.
Koercja jest stosowana w przypadkach, w których użycie oryginalnej wartości argumentu spowodowałoby wystąpienie błędu. Czasem też używana jest w celu zwiększenia wydajności obliczeń.
W Clojure z reguły powinno się unikać koercji, ponieważ kompilator sam potrafi dokonywać potrzebnych optymalizacji. Zdarzają się jednak sytuacje, w których warto przekształcić wartości przekazywanych argumentów, aby przeprowadzać operacje arytmetyczne lub wywoływać metody obiektów systemu gospodarza bez korzystania z mechanizmu refleksji.
Aby uruchamiać podprogramy (m.in. funkcje) Clojure korzysta z interfejsu
clojure.lang.IFn. Jeżeli jakiś obiekt go implementuje, może zostać wywołany, co
będzie polegało na uruchomieniu przypisanego mu podprogramu. W istocie wiąże się to
z wywołaniem metody invoke danego obiektu:
( str 123) ; => "123"
(.invoke str 123) ; => "123"
Podczas wywoływania funkcji przekazywane są do niej argumenty, a typem każdej
referencji, z użyciem której jest to dokonywane, wewnętrznie będzie Object
(w przypadku JVM). Jest to tylko mechanizm transportowania wartości do funkcji –
referencyjnej koercji, a nie konwersji. Gdy w ciele funkcji będziemy obsługiwali
wartości parametrów, ich oryginalne typy będą zachowane:
(defn fun [a] (type a))
(fun "test")
; => java.lang.String
Spójrzmy co się stanie, gdy w funkcji wywołamy metodę Javy, która powinna działać dla jakiegoś obiektu o z góry ustalonym typie:
1(set! *warn-on-reflection* true)
2
3(defn fun [a] (.length a))
4; >> Reflection warning, /tmp/form-init4959455601282597355.clj:1:15
5; >> - reference to field length can't be resolved.
6
7(fun "test")
8; => 4
(set! *warn-on-reflection* true)
(defn fun [a] (.length a))
; >> Reflection warning, /tmp/form-init4959455601282597355.clj:1:15
; >> - reference to field length can't be resolved.
(fun "test")
; => 4
Widzimy, że podczas kompilacji nie było możliwe ustalenie, czy przyjmowany obiekt
będzie wyposażony w metodę length – poinformował nas o tym komunikat
z ostrzeżeniem. Sprawdzanie zostanie więc odłożone do czasu uruchamiania programu, co
może mieć ujemny wpływ na wydajność obliczeń. Warto wtedy skorzystać z wyrażonej
wprost koercji.
W praktyce koercja w Clojure będzie polegała na konwersji parametru funkcji w jej ciele lub na zastosowaniu tzw. sugerowania typów w odniesieniu do argumentów i/lub wartości zwracanych.
1(set! *warn-on-reflection* true)
2
3;; bez koercji
4
5(defn sumuj [min max]
6 (loop [n min acc 0]
7 (if (> n max) acc (recur (inc n) (+ acc n)))))
8
9;; koercja bazująca na obiekcie funkcyjnym
10
11(defn sumuj-fun [f min max]
12 (let [min (f min) max (f max)]
13 (loop [n min acc (f 0)]
14 (if (> n max) acc (recur (inc n) (+ acc n))))))
15
16;; koercja lokalna do określonego typu
17
18(defn sumuj-long [min max]
19 (let [min (long min) max (long max)]
20 (loop [n min acc (long 0)]
21 (if (> n max) acc (recur (inc n) (+ acc n))))))
22
23;; koercja bazująca na sugerowaniu typów
24
25(defn sumuj-hinting ^long [^long min ^long max]
26 (loop [n min acc 0]
27 (if (> n max) acc (recur (inc n) (+ acc n)))))
28
29;; koercja bazująca na sugerowaniu typów
30;; jako makro (możliwość podania typu)
31
32(defmacro sumuj-steroids [t min max]
33 (let [ttag {:tag t}
34 fmin (gensym 'min)
35 fmax (gensym 'max)
36 fmina (with-meta fmin ttag)
37 fmaxa (with-meta fmax ttag)
38 fname (with-meta (gensym 'sum) ttag)]
39 `((fn ~fname [~fmina ~fmaxa]
40 (loop [n# ~fmin acc# 0]
41 (if (> n# ~fmax) acc# (recur (inc n#) (+ acc# n#)))))
42 ~min ~max)))
43
44(def n 10000000)
45
46(time (sumuj 0 n)) ; >> "Elapsed time: 2550.26655 msecs"
47(time (sumuj-fun long 0 n)) ; >> "Elapsed time: 2508.790539 msecs"
48(time (sumuj-long 0 n)) ; >> "Elapsed time: 884.280539 msecs"
49(time (sumuj-hinting 0 n)) ; >> "Elapsed time: 860.636767 msecs"
50(time (sumuj-steroids long 0 n)) ; >> "Elapsed time: 891.377236 msecs"
(set! *warn-on-reflection* true)
;; bez koercji
(defn sumuj [min max]
(loop [n min acc 0]
(if (> n max) acc (recur (inc n) (+ acc n)))))
;; koercja bazująca na obiekcie funkcyjnym
(defn sumuj-fun [f min max]
(let [min (f min) max (f max)]
(loop [n min acc (f 0)]
(if (> n max) acc (recur (inc n) (+ acc n))))))
;; koercja lokalna do określonego typu
(defn sumuj-long [min max]
(let [min (long min) max (long max)]
(loop [n min acc (long 0)]
(if (> n max) acc (recur (inc n) (+ acc n))))))
;; koercja bazująca na sugerowaniu typów
(defn sumuj-hinting ^long [^long min ^long max]
(loop [n min acc 0]
(if (> n max) acc (recur (inc n) (+ acc n)))))
;; koercja bazująca na sugerowaniu typów
;; jako makro (możliwość podania typu)
(defmacro sumuj-steroids [t min max]
(let [ttag {:tag t}
fmin (gensym 'min)
fmax (gensym 'max)
fmina (with-meta fmin ttag)
fmaxa (with-meta fmax ttag)
fname (with-meta (gensym 'sum) ttag)]
`((fn ~fname [~fmina ~fmaxa]
(loop [n# ~fmin acc# 0]
(if (> n# ~fmax) acc# (recur (inc n#) (+ acc# n#)))))
~min ~max)))
(def n 10000000)
(time (sumuj 0 n)) ; >> "Elapsed time: 2550.26655 msecs"
(time (sumuj-fun long 0 n)) ; >> "Elapsed time: 2508.790539 msecs"
(time (sumuj-long 0 n)) ; >> "Elapsed time: 884.280539 msecs"
(time (sumuj-hinting 0 n)) ; >> "Elapsed time: 860.636767 msecs"
(time (sumuj-steroids long 0 n)) ; >> "Elapsed time: 891.377236 msecs"
Widzimy, że wersja sumatora bez koercji z funkcji sumuj jest niemal trzykrotnie
wolniejsza, niż wersje z koercją, za wyjątkiem funkcji sumuj-fun, w której
dokonujemy koercji z użyciem przekazywanego obiektu funkcyjnego, który ma ją
obsłużyć: long. Okazuje się jednak, że tego typu konstrukcje nie są optymalizowane
w czasie kompilacji i do czynienia mamy z przekształcaniem typu w czasie pracy
programu, czyli korzystaniem z java.lang.Long.
W przypadku trzech ostatnich implementacji obserwujemy zysk wydajnościowy. Różnią się
one czasami realizacji, lecz wynika to z narzutu na tworzenie innych obiektów; na
przykład makro sumuj-steroids potrzebuje trochę czasu na przygotowanie
symboli. Warto mieć na uwadze, że podane czasy obejmują kompilację i ewaluację,
ponieważ mamy do czynienia z REPL.
Istnieje kilka prostych zasad, o których warto pamiętać, gdy zamierzamy tworzyć funkcje, w których jawnie bądź automatycznie dochodzi do koercji:
-
Jeżeli koercji dokonujemy w ciele funkcji, wtedy warto korzystać z powiązań leksykalnych (np. formy
let), aby jednokrotnie dokonać konwersji, a następnie używać wartości odpowiedniego typu. -
Warto korzystać z wartości pochodzącej z konwersji w najbardziej zagnieżdżonym wyrażeniu, czyli tam, gdzie rzeczywiście jest to potrzebne (reszta konstrukcji powinna mieć dostęp do oryginalnej wartości parametru).
-
Tam, gdzie to możliwe, zaleca się używać tzw. sugerowania typów zamiast konwersji – jest to czytelny i wydajny sposób koercji.
Sugerowanie typu
Sugerowanie typu (ang. type hinting), zwane też podpowiadaniem typu, jest mechanizmem języka Clojure, który pozwala oznaczać niektóre wyrażenia (w tym argumenty i wartości zwracane przez funkcje) identyfikatorami typów danych.
Użycie:
^typ S-wyrażenie,^{:tag typ} S-wyrażenie.
Podpowiedzi dotyczące typów to metadane umieszczane przed symbolami lub innymi S-wyrażeniami, które tworzą powiązania bądź zwracane wartości. Możemy je zastosować:
- w nazwie zmiennej globalnej przed jej symbolem,
- w wektorze parametrycznym przed argumentami funkcji,
- w definicjach funkcji przed wektorem parametrycznym,
- w wektorze powiązań przed nazwami symboli,
- w formach wywołania funkcji przed ich listowymi S-wyrażeniami,
- w przypadku innych form implementujących interfejs
IMeta.
Ze względu na rodzinę typów, do których dokonywane jest rzutowanie, będziemy mieli do czynienia z dwoma rodzajami sugerowania:
- sugerowanie typów podstawowych,
- sugerowanie typów obiektowych.
Gdy przed S-wyrażeniem umieścimy znacznik sugerowania typu, w fazie kompilacji
dojdzie do uruchomienia procesu podążania za rezultatami wartościowania
reprezentowanej nim formy i w miarę możliwości oznaczania ich pierwotną sugestią
odnośnie typu. Dla każdej oznaczonej konstrukcji będą zastosowane optymalizacje
polegające na użyciu konkretnych, podanych typów zamiast typów uogólnionych
(np. Object). Zwiększa to wydajność, ponieważ wewnętrzne wywołania metod
pochodzących z platformy gospodarza nie muszą korzystać z mechanizmu refleksji. Poza
tym w przypadku typów podstawowych sugerowanie typów umożliwia operowanie
bezpośrednio na wartościach, a więc bez narzutu w postaci obsługi obiektów.
1(set! *warn-on-reflection* true)
2
3;; zmienna globalna
4
5(def ^String x "a")
6
7;; wektor parametryczny funkcji
8
9(defn fun [^String a] a)
10(fn [^String a] a)
11
12;; wartość zwracana funkcji
13
14(defn fun ^String [a] a)
15(fn ^String [a] a)
16
17;; wektor powiązań
18
19(let [^String a "a"] a)
20
21;; wywołania funkcji
22
23(.equals ^String (str "a") ^String (str "a"))
24(.equals ^String (fun "a") ^String (fun "a"))
25
26;; porównanie wydajności wywołania metody na obiekcie
27
28(defn długość [acc x] (+' acc (.length x)))
29(defn długość-string [acc ^String x] (+' acc (.length x)))
30(def łańcuchy (repeat 100000 "xxxxxxxxxxx"))
31
32(time (reduce długość 0 łańcuchy))
33
34; >> "Elapsed time: 1495.502125 msecs"
35; => 1100000
36
37(time (reduce długość-string 0 łańcuchy))
38
39; >> "Elapsed time: 34.815388 msecs"
40; => 1100000
(set! *warn-on-reflection* true)
;; zmienna globalna
(def ^String x "a")
;; wektor parametryczny funkcji
(defn fun [^String a] a)
(fn [^String a] a)
;; wartość zwracana funkcji
(defn fun ^String [a] a)
(fn ^String [a] a)
;; wektor powiązań
(let [^String a "a"] a)
;; wywołania funkcji
(.equals ^String (str "a") ^String (str "a"))
(.equals ^String (fun "a") ^String (fun "a"))
;; porównanie wydajności wywołania metody na obiekcie
(defn długość [acc x] (+' acc (.length x)))
(defn długość-string [acc ^String x] (+' acc (.length x)))
(def łańcuchy (repeat 100000 "xxxxxxxxxxx"))
(time (reduce długość 0 łańcuchy))
; >> "Elapsed time: 1495.502125 msecs"
; => 1100000
(time (reduce długość-string 0 łańcuchy))
; >> "Elapsed time: 34.815388 msecs"
; => 1100000
W przykładach powyżej mieliśmy do czynienia z sugerowaniem typów obiektowych, tzn. takich, których dane reprezentowane są z użyciem obiektowego systemu typów gospodarza.
Gdyby jednak zaszła potrzeba bezpośredniego skorzystania z wartości typu
podstawowego, który został opakowany, wtedy – poza rzutowaniem – możemy w Clojure
skorzystać z sugestii typów podstawowych (ang. primitive type hints). Użycie jej
sprawi, że już na etapie kompilacji dojdzie do optymalizacji zastosowanych
konstrukcji. Jeżeli nie będzie to możliwe, zgłoszony zostanie wyjątek
java.lang.ClassCastException, ponieważ proces wypakowywania wartości typu
podstawowego z obiektu realizowany jest wewnętrznie z użyciem rzutowania.
Obsługa sugerowania typów obejmuje (poza typami obiektowymi):
-
podstawowe typy proste:
long– liczba całkowita dłuższa,double– liczba zmiennoprzecinkowa podwójnej precyzji;
-
podstawowe typy złożone:
ints– tablica liczb całkowitych,longs– tablica liczb całkowitych dłuższych,floats– tablica liczb zmiennoprzecinkowych,doubles– tablica liczb zmiennoprzecinkowych podwójnej precyzji.
Uwaga: Nie możemy dokonywać sugerowania typów podstawowych w odniesieniu do
lokalnych powiązań. Zamiast tego należy stosować rzutowanie. Próby podpowiadania
typów spowodują zgłoszenia wyjątku java.lang.UnsupportedOperationException.
1(set! *warn-on-reflection* true)
2
3;; zmienna globalna
4
5(def ^long x 5)
6
7;; wektor parametryczny funkcji
8
9(defn fun [^double a] a)
10(fn [^double a] a)
11
12;; wartość zwracana funkcji
13
14(defn fun ^double [a] a)
15(fn ^double [a] a)
16
17;; wywołania funkcji
18
19^double (identity 5)
20(= ^long (+ 2) ^long (+ 2))
21(+ ^double (fun 2) ^double (fun 1))
(set! *warn-on-reflection* true)
;; zmienna globalna
(def ^long x 5)
;; wektor parametryczny funkcji
(defn fun [^double a] a)
(fn [^double a] a)
;; wartość zwracana funkcji
(defn fun ^double [a] a)
(fn ^double [a] a)
;; wywołania funkcji
^double (identity 5)
(= ^long (+ 2) ^long (+ 2))
(+ ^double (fun 2) ^double (fun 1))
Uwaga: W przypadku argumentów funkcji, które wyposażono w sugerowanie typów
podstawowych, a koercja wartości do wskazanego typu nie będzie możliwa, zgłoszony
zostanie wyjątek java.lang.ClassCastException.
Rekordy
Rekord (ang. record) jest strukturą danych służącą do przechowywania kolekcji elementów o z góry określonych identyfikatorach (np. nazwach) oraz typach (w językach mocno typizowanych). Elementy wchodzące w skład rekordów nazywamy polami (ang. fields).
Korzystanie z rekordów w Clojure polega na:
- zdefiniowaniu rekordowego typu danych,
- utworzeniu instancji zdefiniowanego typu.
Rekordy przypominają mapy strukturalne, ale wewnętrznie nie korzystają z mapowej struktury danych. Możemy co prawda dodawać do rekordów dodatkowe pola, nieznane podczas ich definiowania, ale wytwarzając kopię rekordu, każda wchodząca w jego skład wartość będzie skopiowana.
Z drugiej strony dostęp do zdefiniowanych wcześniej rekordowych pól jest operacją bardzo szybką, ponieważ implementowany jest tak jak dostęp do z góry określonych pól klasy. Wynika to z faktu, że rekordowe typy danych są de facto klasami Javy.
Obsługa rekordowego typu danych w Clojure może być przykładem mechanizmu polimorficznego z dwóch powodów:
-
Mimo, że jego obiekty są osobnym typem, możemy traktować je jak mapy i korzystać z funkcji obsługujących tę strukturę danych (polimorfizm podtypowy).
-
Definiując typy rekordowe, możemy potem korzystać z tzw. protokołów, dzięki którym jesteśmy w stanie rozdzielać wywołania właśnie po typach. Argumenty wywołań polimorficznych funkcji (określonych protokołami) będą obsługiwane przez specyficzne warianty funkcji w zależności od tego jakim typem rekordowym okaże się pierwszy przekazywany argument. Możliwe jest również dodawanie nowych funkcji obsługi do już istniejących typów rekordowych. Jest to polimorfizm doraźny.
Definiowanie rekordów, defrecord
Do tworzenia rekordowych typów danych możemy użyć makra defrecord.
Użycie:
(defrecord nazwa pole… & opcja… & specyfikacja…).
Pierwszym argumentem makra powinna być nazwa typu rekordowego, a kolejnymi (opcjonalnymi) nazwy pól, które mogą zawierać sugestie typów.
Po nazwach pól możemy podać opcje (obecnie nieobsługiwane) i tzw. specyfikacje (ang. skr. specs).
Każda specyfikacja powinna składać się z nazwy protokołu lub interfejsu platformy gospodarza, po której może (ale nie musi) pojawić się jedna lub więcej definicji metod w postaci:
(nazwa-metody [this & argument…] ciało).
Możemy i powinniśmy zdefiniować metody, które zostały zadeklarowane
w protokołach lub interfejsach. Dodatkowo możemy
umieszczać przeciążone wersje metod klasy Object.
Pierwszym przyjmowanym argumentem w przypadku definiowania metod zadeklarowanych
w interfejsach powinien być obiekt instancji bieżącej (odpowiednik this
z Javy). Podczas ich bezpośredniego wywoływania (z wykorzystaniem mechanizmów
odwoływania się do obiektów platformy gospodarza) będzie on przekazywany
automatycznie i nie należy podawać go wprost.
W odniesieniu do argumentów i wartości zwracanych przez wszystkie metody możliwe jest zastosowanie sugerowania typów.
W ciałach metod jesteśmy w stanie odwoływać się do definiowanej klasy (i w związku z tym do jej klasowych metod) przez podawanie jej symbolicznej nazwy.
Uwaga: Definicje metod nie zamykają w ciałach powiązań z leksykalnego otoczenia ich definicji. Mamy dostęp wyłącznie do zadeklarowanych pól.
defrecord ze specyfikacjami metod
1;; definiowanie protokołu
2
3(defprotocol Nazywane
4 "Zawiera operacje dla typów, które reprezentują obiekty nazywane."
5 (nazwa [this] "Zwraca nazwę.")
6 (nazywane? [this] "Sprawdza czy obiekt może być nazywany."))
7
8;; definiowanie typu rekordowego
9;; wraz ze specyfikacjami metod określonych protokołem Nazywane
10
11(defrecord Osoba [imię nazwisko e-mail]
12 Nazywane
13 (nazwa [this] (str imię " " nazwisko))
14 (nazywane? [this] true))
15
16; => user.Osoba
17
18;; tworzenie rekordu typu Osoba przez wywołanie konstruktora
19
20(def Paweł (Osoba. "Paweł" "Wilk" "pw-na-gnu.org"))
21
22;; tworzenie rekordu typu Osoba przez wywołanie funkcji ->
23
24(def Paweł (->Osoba "Paweł" "Wilk" "pw-na-gnu.org"))
25
26;; sprawdzanie typów
27
28(type Osoba) ; => java.lang.Class
29(type Paweł) ; => user.Osoba
30
31;; wywoływanie akcesorów pól
32
33(.imię Paweł) ; => "Paweł"
34(.nazwisko Paweł) ; => "Wilk"
35
36;; traktowanie rekordu jak mapy
37
38(:imię Paweł) ; => "Paweł"
39(:nazwisko Paweł) ; => "Wilk"
40
41(conj Paweł {:płeć :m})
42
43; => #user.Osoba{:e-mail "pw-na-gnu.org"
44; => :imię "Paweł"
45; => :nazwisko "Wilk"
46; => :płeć :m}
47
48;; sprawdzanie implementacji protokołu Nazywane
49
50(nazywane? Paweł) ; => true
51(nazwa Paweł) ; => "Paweł Wilk"
;; definiowanie protokołu
(defprotocol Nazywane
"Zawiera operacje dla typów, które reprezentują obiekty nazywane."
(nazwa [this] "Zwraca nazwę.")
(nazywane? [this] "Sprawdza czy obiekt może być nazywany."))
;; definiowanie typu rekordowego
;; wraz ze specyfikacjami metod określonych protokołem Nazywane
(defrecord Osoba [imię nazwisko e-mail]
Nazywane
(nazwa [this] (str imię " " nazwisko))
(nazywane? [this] true))
; => user.Osoba
;; tworzenie rekordu typu Osoba przez wywołanie konstruktora
(def Paweł (Osoba. "Paweł" "Wilk" "pw-na-gnu.org"))
;; tworzenie rekordu typu Osoba przez wywołanie funkcji ->
(def Paweł (->Osoba "Paweł" "Wilk" "pw-na-gnu.org"))
;; sprawdzanie typów
(type Osoba) ; => java.lang.Class
(type Paweł) ; => user.Osoba
;; wywoływanie akcesorów pól
(.imię Paweł) ; => "Paweł"
(.nazwisko Paweł) ; => "Wilk"
;; traktowanie rekordu jak mapy
(:imię Paweł) ; => "Paweł"
(:nazwisko Paweł) ; => "Wilk"
(conj Paweł {:płeć :m})
; => #user.Osoba{:e-mail "pw-na-gnu.org"
; => :imię "Paweł"
; => :nazwisko "Wilk"
; => :płeć :m}
;; sprawdzanie implementacji protokołu Nazywane
(nazywane? Paweł) ; => true
(nazwa Paweł) ; => "Paweł Wilk"
Opis użycia defrecord (z pominięciem części poświęconej specyfikowaniu
protokołów i implementowaniu metod) można znaleźć w rozdziale poświęconym kolekcjom.
Więcej informacji o protokołach znajduje się w dalszej części tego rozdziału.
Tworzenie rekordów
Istnieją trzy sposoby tworzenia rekordów na bazie wcześniej zdefiniowanego typu rekordowego:
- Z użyciem funkcji
->typ, gdzietypto zdefiniowany typ. - Z użyciem funkcji
map->typ, gdzietypto zdefiniowany typ. - Z użyciem rekordowego S-wyrażenia.
Własne typy obiektowe
Nowe typy obiektowe możemy tworzyć z użyciem makra deftype.
Powstające w ten sposób typy danych są implementowane z użyciem systemu klas
platformy gospodarza.
Tworzenie typów przypomina generowanie typów rekordowych: również tworzone są klasy
wyposażone w odpowiednie konstruktory, ale nie jest narzucany interfejs dostępu do
danych w postaci mapy (klasy nie implementują interfejsu
clojure.lang.IPersistentMap). Nie ma nawet wymogu, aby deklarować jakiekolwiek
pola.
Obsługa obiektowych typów danych w Clojure jest przykładem mechanizmu polimorficznego, ponieważ podczas ich definiowania możemy korzystać z tzw. protokołów i implementować konkretne warianty funkcji polimorficznych, których pierwszym przekazywanym argumentem będzie dany typ (polimorfizm doraźny). Możliwe jest również dodawanie nowych funkcji obsługi do istniejących typów.
Definiowanie typów, deftype
W Clojure możemy tworzyć nowe typy obiektowe, czyli de facto nowe, nazwane klasy systemu gospodarza. Klasy Javy odpowiadające nowym typom tworzone są dynamicznie, a definicje zawierać mogą zadeklarowane przez programistę pola i (opcjonalnie) metody. Stwarzane w Clojure klasy mogą implementować protokoły oraz interfejsy Javy.
Aby wytworzyć nowy typ obiektowy, możemy skorzystać z makra deftype.
Użycie:
(deftype nazwa pole… & opcja… & specyfikacja…);
gdzie:
nazwajest symbolem nazywającym klasę,polejest symbolem nazywającym pole klasy,opcjajest dodatkową opcją (obecnie nieobsługiwane),specyfikacjajest specyfikacją protokołów bądź interfejsów wraz z metodami.
Nazwa może być podana raz, natomiast pole, opcja i specyfikacja mogą pojawić się wiele razy.
Każda opcja powinna być parą klucz wartość, a obecnie jedynym użytecznym kluczem
jest :load-ns. Jeżeli skojarzymy go z wartością true, wtedy importowanie klasy
definiującej typ spowoduje, że załadowana zostanie przestrzeń nazw, w której ów
typ został zdefiniowany.
Każda specyfikacja powinna składać się z nazwy protokołu lub interfejsu platformy gospodarza, po której może (ale nie musi) pojawić się jedna lub więcej definicji metod w postaci:
(nazwa-metody [this & argument…] ciało).
Możemy i powinniśmy zdefiniować metody, które zostały zadeklarowane w protokołach lub
interfejsach. Dodatkowo możemy umieszczać przeciążone wersje metod klasy Object.
Pierwszym przyjmowanym argumentem w przypadku definiowania metod zadeklarowanych
w interfejsach powinien być obiekt instancji bieżącej (odpowiednik this
z Javy). Podczas ich bezpośredniego wywoływania (z wykorzystaniem mechanizmów
odwoływania się do obiektów platformy gospodarza) będzie on przekazywany
automatycznie i nie należy podawać go wprost.
W odniesieniu do argumentów i wartości zwracanych przez wszystkie metody możliwe jest zastosowanie sugerowania typów.
W ciałach metod jesteśmy w stanie odwoływać się do definiowanej klasy (i w związku z tym do jej klasowych metod) przez podawanie jej symbolicznej nazwy.
Uwaga: Definicje metod nie zamykają w ciałach powiązań z leksykalnego otoczenia ich definicji. Mamy dostęp wyłącznie do zadeklarowanych pól.
deftype ze specyfikacjami metod
1;; definiowanie protokołu
2
3(defprotocol Nazywane
4 "Zawiera operacje dla typów, które reprezentują obiekty nazywane."
5 (nazwa [this] "Zwraca nazwę.")
6 (nazywane? [this] "Sprawdza czy obiekt może być nazywany."))
7
8;; definiowanie typu
9;; wraz ze specyfikacjami metod określonych protokołem Nazywane
10
11(deftype Osoba [imię nazwisko wiek]
12 Nazywane
13 (nazwa [this] (str imię " " nazwisko))
14 (nazywane? [this] true))
15
16; => user.Osoba
17
18;; tworzenie instancji klasy Osoba przez wywołanie konstruktora
19
20(def Paweł (Osoba. "Paweł" "Wilk" 18))
21
22;; tworzenie instancji klasy Osoba przez wywołanie funkcji ->
23
24(def Paweł (->Osoba "Paweł" "Wilk" 18))
25
26;; sprawdzanie typów
27
28(type Osoba) ; => java.lang.Class
29(type Paweł) ; => user.Osoba
30
31;; wywoływanie akcesorów pól
32
33(.imię Paweł) ; => "Paweł"
34(.nazwisko Paweł) ; => "Wilk"
35
36;; sprawdzanie implementacji protokołu Nazywane
37
38(nazywane? Paweł) ; => true
39(nazwa Paweł) ; => "Paweł Wilk"
;; definiowanie protokołu
(defprotocol Nazywane
"Zawiera operacje dla typów, które reprezentują obiekty nazywane."
(nazwa [this] "Zwraca nazwę.")
(nazywane? [this] "Sprawdza czy obiekt może być nazywany."))
;; definiowanie typu
;; wraz ze specyfikacjami metod określonych protokołem Nazywane
(deftype Osoba [imię nazwisko wiek]
Nazywane
(nazwa [this] (str imię " " nazwisko))
(nazywane? [this] true))
; => user.Osoba
;; tworzenie instancji klasy Osoba przez wywołanie konstruktora
(def Paweł (Osoba. "Paweł" "Wilk" 18))
;; tworzenie instancji klasy Osoba przez wywołanie funkcji ->
(def Paweł (->Osoba "Paweł" "Wilk" 18))
;; sprawdzanie typów
(type Osoba) ; => java.lang.Class
(type Paweł) ; => user.Osoba
;; wywoływanie akcesorów pól
(.imię Paweł) ; => "Paweł"
(.nazwisko Paweł) ; => "Wilk"
;; sprawdzanie implementacji protokołu Nazywane
(nazywane? Paweł) ; => true
(nazwa Paweł) ; => "Paweł Wilk"
Opis użycia makra deftype (z pominięciem części poświęconej
specyfikowaniu protokołów i implementowaniu metod) można znaleźć w rozdziale
poświęconym systemom typów.
Więcej informacji o protokołach znajduje się w dalszej części tego rozdziału.
Tworzenie obiektów
Na bazie wcześniej zdefiniowanego typu możemy tworzyć obiekty z użyciem automatycznie
generowanej przez deftype funkcji ->typ, gdzie typ to zdefiniowany
typ.
Polimorfizm operacji
Polimorficzne mechanizmy obsługi funkcji umożliwiają tworzenie zgeneralizowanych operacji, których konkretne warianty będą zależały od wielu czynników, np. liczby bądź typów przekazywanych argumentów, czy nawet rezultatów obliczeń prowadzonych na danych wejściowych lub globalnych stanów.
Przeciążanie argumentowości
Przeciążanie argumentowości (ang. arity overloading) to mechanizm polimorfizmu doraźnego, polegający na statycznym lub dynamicznym wyborze jednej z wielu operacji widocznych pod jedną nazwą i implementowanych jako jeden obiekt w zależności od liczby bądź typów przekazywanych argumentów.
W Clojure przeciążanie argumentowości bazuje na liczbie przekazywanych argumentów i może być realizowane w odniesieniu do funkcji oraz makr.
1(defn fun
2 ([] "brak argumentów")
3 ([a] (str "jeden argument: " a))
4 ([a & args] (println "wiele argumentów:" a (apply print-str args))))
5
6(fun) ; => "brak argumentów"
7(fun 123) ; => "jeden argument: 123"
8(fun 1 2 3) ; => "wiele argumentów: 1 2 3"
(defn fun
([] "brak argumentów")
([a] (str "jeden argument: " a))
([a & args] (println "wiele argumentów:" a (apply print-str args))))
(fun) ; => "brak argumentów"
(fun 123) ; => "jeden argument: 123"
(fun 1 2 3) ; => "wiele argumentów: 1 2 3"
Zobacz także:
- „Funkcje wieloczłonowe”, rozdział VIII.
Nadpisywanie funkcji
Nadpisywanie funkcji (ang. function overriding) to mechanizm polimorfizmu doraźnego, w którym dochodzi do podmiany operacji na inną w pewnych kontekstach przy zachowaniu sygnatury jej wywołania oraz nazwy. Przykładem kontekstu w języku obiektowym może być użycie podtypu i wywołanie zdefiniowanej w klasie potomnej innej wersji tej samej metody.
W językach funkcyjnych nie mamy do czynienia z typowym nadpisywaniem, ale istnieją operacje, które efektywnie realizują cel tego procesu. Ich przykładami będą redefinicje lub przesłonięcia funkcji.
W języku Clojure mechanizmy, które wyrażają operację nadpisywania funkcji to:
- globalne aktualizowanie powiązania zmiennej globalnej z funkcją,
- globalne przesłanianie powiązania zmiennej dynamicznej z funkcją,
- leksykalne przesłanianie powiązania zmiennej globalnej z funkcją,
- globalna redefinicja powiązania zmiennej globalnej z funkcją.
1(defn funkcja-1 [] "pierwotna 1")
2(defn ^:dynamic *funkcja-2* [] "pierwotna 2")
3
4(funkcja-1) ; => "pierwotna 1"
5(*funkcja-2*) ; => "pierwotna 2"
6
7;; aktualizowanie funkcji globalnych
8
9(defn funkcja-1 [] "zaktualizowana 1")
10(funkcja-1) ; => "zaktualizowana 1"
11
12(alter-var-root (var funkcja-1)
13 (constantly (fn [] "bezpiecznie zaktualizowana 1")))
14(funkcja-1) ; => "bezpiecznie zaktualizowana 1"
15
16;; przesłanianie leksykalne funkcji
17
18(letfn [(funkcja-1 [] "przesłonięta leksykalnie 1")]
19 (funkcja-1)) ; => "przesłonięta leksykalnie 1"
20(funkcja-1) ; => "bezpiecznie zaktualizowana 1"
21
22(let [funkcja-1 (fn [] "przesłonięta leksykalnie 1")]
23 (funkcja-1)) ; => "przesłonięta leksykalnie 1"
24(funkcja-1) ; => "bezpiecznie zaktualizowana 1"
25
26;; przesłanianie funkcji dynamicznych
27
28(binding [*funkcja-2* (fn [] "dynamicznie przesłonięta 2")]
29 (*funkcja-2*)) ; => "dynamicznie przesłonięta 2"
30(*funkcja-2*) ; => "pierwotna 2"
31
32;; redefinicja funkcji
33
34(with-redefs [funkcja-1 (fn [] "redefiniowana 1")]
35 (funkcja-1)) ; => "redefiniowana 1"
36(funkcja-1) ; => "bezpiecznie zaktualizowana 1"
(defn funkcja-1 [] "pierwotna 1")
(defn ^:dynamic *funkcja-2* [] "pierwotna 2")
(funkcja-1) ; => "pierwotna 1"
(*funkcja-2*) ; => "pierwotna 2"
;; aktualizowanie funkcji globalnych
(defn funkcja-1 [] "zaktualizowana 1")
(funkcja-1) ; => "zaktualizowana 1"
(alter-var-root (var funkcja-1)
(constantly (fn [] "bezpiecznie zaktualizowana 1")))
(funkcja-1) ; => "bezpiecznie zaktualizowana 1"
;; przesłanianie leksykalne funkcji
(letfn [(funkcja-1 [] "przesłonięta leksykalnie 1")]
(funkcja-1)) ; => "przesłonięta leksykalnie 1"
(funkcja-1) ; => "bezpiecznie zaktualizowana 1"
(let [funkcja-1 (fn [] "przesłonięta leksykalnie 1")]
(funkcja-1)) ; => "przesłonięta leksykalnie 1"
(funkcja-1) ; => "bezpiecznie zaktualizowana 1"
;; przesłanianie funkcji dynamicznych
(binding [*funkcja-2* (fn [] "dynamicznie przesłonięta 2")]
(*funkcja-2*)) ; => "dynamicznie przesłonięta 2"
(*funkcja-2*) ; => "pierwotna 2"
;; redefinicja funkcji
(with-redefs [funkcja-1 (fn [] "redefiniowana 1")]
(funkcja-1)) ; => "redefiniowana 1"
(funkcja-1) ; => "bezpiecznie zaktualizowana 1"
W przypadku użycia defn i alter-var-root mamy do
czynienia z globalną zmianą powiązania głównego obiektu typu Var wskazującego na
funkcję. Nowa funkcja, na którą wskazuje powiązanie, będzie współdzielona między
wątkami.
W przypadku let oraz letfn będziemy mieli do czynienia
z przesłonięciem symbolu powiązanego ze zmienną globalną przechowującą odniesienie do
funkcji. Zmiana będzie izolowana w bieżącym wątku, a dodatkowo ograniczona
zasięgiem leksykalnym.
Gdy użyjemy binding, dojdzie do przesłonięcia powiązania obiektu typu
Var z funkcją. Powiązanie to będzie ograniczone zasięgiem dynamicznym i izolowane w bieżącym wątku. Pozostałe wątki będą korzystały
z powiązania głównego.
Ostatni przykład, polegający na wywołaniu with-redefs, bazuje na
globalnej zmianie powiązania głównego obiektu typu Var. Nowa wartość będzie
współdzielona między wątkami do momentu zakończenia przetwarzania wyrażeń
podanych jako ostatni argument. Po zakończeniu ewaluacji przywrócone będzie
poprzednie powiązanie główne.
Możemy również dokonywać operacji typowo obiektowych, nadpisując metody zdefiniowane w klasach obiektowego systemu typów:
Multimetody
Multimetody (ang. multimethods), zwane też wielometodami, dyspozycją wieloraką (ang. multiple dispatch) lub wielodyspozycją są mechanizmem dynamicznego polimorfizmu doraźnego, który polega na tym, że konkretny wariant operacji (dostosowany do obsługi danych o pewnej charakterystyce) wybierany jest w zależności od określonych przez programistę właściwości wartości przekazywanych jako argumenty wywołania polimorficznej funkcji. Tymi ostatnimi mogą być typy (w przypadku Clojure obiektowe lub doraźne), ale także inne cechy danych, które da się wyrazić pojedynczymi wartościami po przeprowadzeniu na nich jakichś obliczeń.
W Clojure obsługa multimetod polega na definiowaniu funkcji dyspozycyjnych (ang. dispatch functions) i związanych z nimi zestawów funkcji realizujących operację w różnych wariantach. Te ostatnie nazywane są metodami (ang. methods), lecz nie należy mylić tego pojęcia z definicją metody pochodzącą z programowania zorientowanego obiektowo.
Wartość zwracaną przez funkcję dyspozycyjną nazywamy wartością dyspozycyjną (ang. dispatch value). Będzie ona używana w celu wyboru konkretnej metody z zestawu metod o takich samych nazwach i argumentowościach, lecz różniących się przypisanymi im wartościami dyspozycyjnymi, umieszczanymi w definicjach (przed wektorami parametrycznymi).
Korzystanie z multimetod polega na wywoływaniu ich w taki sam sposób, w jaki czyni się to w odniesieniu do funkcji. Automatycznie wywołana zostanie funkcja dyspozycyjna, która na podstawie podanych argumentów obliczy wartość dyspozycyjną – do niej z kolei zostanie dopasowana metoda, którą zdefiniowano wcześniej i oznaczono taką samą wartością, typem lub nadtypem (w przypadku typu jako wartości dyspozycyjnej). Metoda zostanie wywołana z argumentami takimi samymi, jak przekazane przy wywoływaniu multimetody.
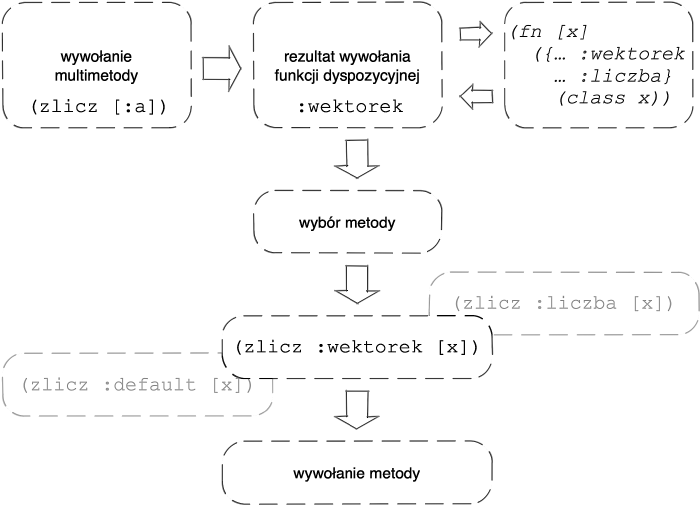
Proces wyboru wariantu multimetody na podstawie argumentu z użyciem funkcji dyspozycyjnej
Wybór będzie polegał na porównywaniu wartości dyspozycyjnej wyliczonej przez funkcję
dyspozycyjną z wartościami przypisanymi do konkretnych wariantów metod. Porównywanie
nie będzie odbywało się z użyciem operatora =, ale z wykorzystaniem funkcji
isa?, która działa w następujący sposób:
-
Sprawdza, czy wartość pierwszego argumentu jest równa wartości drugiego.
-
Jeżeli pierwszy argument jest typem obiektowym, sprawdza czy jest podtypem drugiego argumentu (uwzględniając klasy nadrzędne i wszystkie interfejsy).
-
Jeżeli pierwszy argument jest słowem kluczowym z dookreśloną przestrzenią nazw, traktuje go jak hierarchiczny typ doraźny i dokonuje sprawdzenia relacji, jak dla typów obiektowych.
-
Jeżeli argumenty są wektorami, porównuje elementy o tych samych pozycjach, stosując wyżej wymienione sposoby.
Gdy wartością któregokolwiek sprawdzenia jest true, funkcja isa? kończy pracę
i zwraca ją. W ten sposób realizowane jest dopasowywanie wartości dyspozycyjnych.
Definiowanie metod, defmethod
Definiowanie metod, które będą wywoływane na podstawie dopasowania wartości
dyspozycyjnej, możliwe jest z użyciem makra defmethod.
Użycie:
(defmethod nazwa wartość-dyspozycyjna & argument…).
Pierwszym obowiązkowym argumentem powinna być wyrażona niezacytowanym symbolem nazwa (taka sama, jak nazwa zdefiniowanej multimetody), a drugim wartość dyspozycyjna, którą oznaczony będzie definiowany wariant operacji. Pozostałe argumenty są opcjonalne i zostaną użyte jako argumenty tworzonej metody.
Rezultatem pracy makra jest zdefiniowanie metody przeznaczonej do dyspozycyjnego
wywoływania w zależności od dopasowania do podanej wartości dyspozycyjnej. Wartością
zwracaną jest obiekt typu clojure.lang.MultiFn.
defmethod
1(defmethod punktacja [::użytkownik ::komnata] [u k]
2 (u (:p-users (k @rooms))))
3
4(defmethod punktacja [::drużyna ::komnata] [d k]
5 (d (:p-teams (k @rooms))))
6
7(defmethod zlicz java.lang.String [s]
8 (count s))
(defmethod punktacja [::użytkownik ::komnata] [u k]
(u (:p-users (k @rooms))))
(defmethod punktacja [::drużyna ::komnata] [d k]
(d (:p-teams (k @rooms))))
(defmethod zlicz java.lang.String [s]
(count s))
Definiowanie multimetod, defmulti
Multimetody można definiować z użyciem makra defmulti.
Użycie:
(defmulti nazwa łańcuch-dok? metadane? dyspozytor & opcje).
Pierwszym, obowiązkowym argumentem powinna być nazwa multimetody. Po niej można umieścić opcjonalny łańcuch dokumentujący wyrażony literałem zawierającym z obu stron znaki cudzysłowu, a także opcjonalne mapowe S-wyrażenie zawierające metadane. Kolejnym obowiązkowym argumentem jest funkcja dyspozycyjna wyrażona niezacytowanym symbolem lub inną konstrukcją, która reprezentuje funkcyjny obiekt.
Reszta argumentów to opcje wyrażane mapą, której kluczami są słowa kluczowe:
-
:default– określa domyślną wartość dyspozycyjną
(będzie ustawiona na:default, gdy nie podano); -
:hierarchy– określa wyrażoną typem referencyjnym (np. zmienną globalną) hierarchię używaną do dopasowywania typów doraźnych (domyślnie używana jest hierarchia globalna).
Przekazywana funkcja dyspozycyjna powinna przyjmować tyle argumentów, co każda z metod implementujących różne warianty tej samej operacji, a zwracać wartość, która będzie dopasowywana do wartości dyspozycyjnych umieszczonych sygnaturach tych metod.
W efekcie wywołania makra zdefiniowana zostanie publiczna multimetoda, czyli polimorficzna funkcja wywołująca konkretne implementacje obsługiwanej operacji.
defmulti
1;; definiowanie multimetody
2
3(defmulti zlicz
4 "Zlicza elementy policzalnych struktur danych."
5 (fn ; wieloczłonowa funkcja dyspozycyjna:
6 ([] :default) ; · wariant dla braku argumentów
7 ([a] (type a)) ; · wariant dla jednego argumentu
8 ([a & args] :multi))) ; · wariant dla wielu argumentów
9
10;; definiowanie metody domyślnej dla zerowej liczby argumentów
11
12(defmethod zlicz :default [] 0)
13
14;; definiowanie metody dla więcej niż jednego argumentu
15
16(defmethod zlicz :multi [& args] (apply + (map zlicz args)))
17
18;; definiowanie metod dla jednego argumentu
19
20(defmethod zlicz Number [a] a)
21(defmethod zlicz java.lang.Character [a] 1)
22(defmethod zlicz java.util.Collection [a] (count a))
23(defmethod zlicz java.lang.String [a] (count a))
24
25;; wywoływanie multimetody
26
27(zlicz) ; => 0
28(zlicz 2) ; => 2
29(zlicz 2 2 \a) ; => 5
30(zlicz [:a :b :c [:a]] 7 "abc") ; => 14
;; definiowanie multimetody
(defmulti zlicz
"Zlicza elementy policzalnych struktur danych."
(fn ; wieloczłonowa funkcja dyspozycyjna:
([] :default) ; · wariant dla braku argumentów
([a] (type a)) ; · wariant dla jednego argumentu
([a & args] :multi))) ; · wariant dla wielu argumentów
;; definiowanie metody domyślnej dla zerowej liczby argumentów
(defmethod zlicz :default [] 0)
;; definiowanie metody dla więcej niż jednego argumentu
(defmethod zlicz :multi [& args] (apply + (map zlicz args)))
;; definiowanie metod dla jednego argumentu
(defmethod zlicz Number [a] a)
(defmethod zlicz java.lang.Character [a] 1)
(defmethod zlicz java.util.Collection [a] (count a))
(defmethod zlicz java.lang.String [a] (count a))
;; wywoływanie multimetody
(zlicz) ; => 0
(zlicz 2) ; => 2
(zlicz 2 2 \a) ; => 5
(zlicz [:a :b :c [:a]] 7 "abc") ; => 14
Grupowanie wartości dyspozycyjnych
Jeżeli uważnie przyjrzymy się przykładowi użycia makra defmulti
podanemu wcześniej, znajdziemy w nim powtórzoną definicję metody zlicz dla różnych
wartości dyspozycyjnych:
1(defmethod zlicz java.util.Collection [a] (count a))
2(defmethod zlicz java.lang.String [a] (count a))
(defmethod zlicz java.util.Collection [a] (count a))
(defmethod zlicz java.lang.String [a] (count a))
Zastosowane podejście sprawia, że w przyszłości bardzo prawdopodobne stanie się, iż
znowu dojdzie do powielenia kodu, gdy zechcemy dodać obsługę kolejnych typów danych,
których wartości można przekazać do wywołania count.
Problem ten można by rozwiązać stosując odpowiednie warunki w funkcji dyspozycyjnej, jednak wtedy zawierałaby ona statyczne dane (np. mapę) wmieszane w kod jej ciała, co nie byłoby ani zbyt zwięzłe, ani elastyczne – dodawanie nowych przypadków obsługi wiązałoby się z aktualizowaniem struktury zawartej w funkcji, czyli z modyfikowaniem tej ostatniej.
Moglibyśmy zamiast mapy skorzystać z odniesienia do jakiegoś globalnego typu
referencyjnego, np. zmiennej globalnej, jednak wtedy też nie
byłoby to zbyt eleganckie, bo rozwijając kod musielibyśmy pamiętać, że gdzieś
w funkcji przekazywanej do wywołania defmulti powinniśmy szukać danych
kontrolujących jej zachowanie.
Możemy jednak skorzystać z doraźnego systemu typów, aby z pomocą ustalonej hierarchii zgrupować m.in. typy obiektowe, czyniąc je potomkami jednego, znacznikowego nadtypu. Jest to możliwe, ponieważ:
- makro
defmultipozwala przekazać własną hierarchię; - doraźny system typów pozwala tworzyć znacznikowe nadtypy dla typów obiektowych;
- podczas rozdysponowywania wywołań wykorzystywane są relacje między typami.
Oto jak możemy to zaimplementować:
1;; tworzenie hierarchii
2
3(def ^:private ^:dynamic *zlicz-h*
4 (-> (make-hierarchy)
5 (derive java.lang.Character ::pojedyncze)
6 (derive java.lang.Number ::identyczne)
7 (derive java.lang.String ::policzalne)
8 (derive java.util.Collection ::policzalne)))
9
10;; definiowanie multimetody
11
12(defmulti zlicz
13 (fn
14 ([] ::niema-args)
15 ([a] (type a))
16 ([a & args] ::wiele-args))
17 :default ::niema-args
18 :hierarchy (var *zlicz-h*))
19
20;; definiowanie metod
21
22(defmethod zlicz nil [a] 0)
23(defmethod zlicz ::niema-args [ ] 0)
24(defmethod zlicz ::ignorowane [_] 0)
25(defmethod zlicz ::pojedyncze [a] 1)
26(defmethod zlicz ::identyczne [a] a)
27(defmethod zlicz ::policzalne [a] (count a))
28(defmethod zlicz ::wiele-args [& args] (apply + (map zlicz args)))
29
30;; wywoływanie multimetody
31
32(zlicz) ; => 0
33(zlicz nil) ; => 0
34(zlicz 2 2 "aa" [1]) ; => 7
35(zlicz (seq "aa")) ; => 2
36
37;; dodawanie obsługi nowych typów
38;; w izolowanym wątku dynamicznego zasięgu
39
40(binding
41 [*zlicz-h* (-> *zlicz-h*
42 (derive clojure.lang.StringSeq ::policzalne)
43 (derive clojure.lang.IPersistentMap ::policzalne))]
44 (zlicz {:a 1, :b 2}))
45
46; => 2
47
48;; dodawanie obsługi nowych typów
49;; we wszystkich wątkach zasięgu nieograniczonego
50;; (aktualizacja powiązania głównego zmiennej specjalnej)
51
52(alter-var-root
53 (var *zlicz-h*)
54 #(-> %1
55 (derive clojure.lang.StringSeq ::policzalne)
56 (derive clojure.lang.IPersistentMap ::policzalne)
57 (derive clojure.lang.Keyword ::pojedyncze)))
58
59(zlicz {:a 1, :b 2}) ; => 2
60(zlicz :a :b) ; => 2
;; tworzenie hierarchii
(def ^:private ^:dynamic *zlicz-h*
(-> (make-hierarchy)
(derive java.lang.Character ::pojedyncze)
(derive java.lang.Number ::identyczne)
(derive java.lang.String ::policzalne)
(derive java.util.Collection ::policzalne)))
;; definiowanie multimetody
(defmulti zlicz
(fn
([] ::niema-args)
([a] (type a))
([a & args] ::wiele-args))
:default ::niema-args
:hierarchy (var *zlicz-h*))
;; definiowanie metod
(defmethod zlicz nil [a] 0)
(defmethod zlicz ::niema-args [ ] 0)
(defmethod zlicz ::ignorowane [_] 0)
(defmethod zlicz ::pojedyncze [a] 1)
(defmethod zlicz ::identyczne [a] a)
(defmethod zlicz ::policzalne [a] (count a))
(defmethod zlicz ::wiele-args [& args] (apply + (map zlicz args)))
;; wywoływanie multimetody
(zlicz) ; => 0
(zlicz nil) ; => 0
(zlicz 2 2 "aa" [1]) ; => 7
(zlicz (seq "aa")) ; => 2
;; dodawanie obsługi nowych typów
;; w izolowanym wątku dynamicznego zasięgu
(binding
[*zlicz-h* (-> *zlicz-h*
(derive clojure.lang.StringSeq ::policzalne)
(derive clojure.lang.IPersistentMap ::policzalne))]
(zlicz {:a 1, :b 2}))
; => 2
;; dodawanie obsługi nowych typów
;; we wszystkich wątkach zasięgu nieograniczonego
;; (aktualizacja powiązania głównego zmiennej specjalnej)
(alter-var-root
(var *zlicz-h*)
#(-> %1
(derive clojure.lang.StringSeq ::policzalne)
(derive clojure.lang.IPersistentMap ::policzalne)
(derive clojure.lang.Keyword ::pojedyncze)))
(zlicz {:a 1, :b 2}) ; => 2
(zlicz :a :b) ; => 2
Ujednoznacznianie wyboru, prefer-method
Może zdarzyć się tak, że w definicji metody zamiast pojedynczej wartości dyspozycyjnej umieszczony będzie zestaw wartości wyrażony np. wektorem, ponieważ funkcja dyspozycyjna zwraca wektor.
Jeżeli do innej metody również zostanie przypisana taka sama wartość dyspozycyjna (jako element wektora lub pojedynczo), a funkcja dyspozycyjna zwróci właśnie ją na pozycji pasującej do obu wywołań, będziemy mieli do czynienia z konfliktem wynikającym z niejednoznacznego dopasowania.
1;; tworzymy własną hierarchię tagów
2
3(def ^:dynamic *powitania* (make-hierarchy))
4
5;; mapujemy kraje na języki urzędowe
6;; i aktualizujemy powiązanie główne zmiennej dynamicznej
7;; we wszystkich wątkach
8
9(alter-var-root (var *powitania*)
10 #(-> %
11 (derive ::polska ::pl)
12 (derive ::francja ::fr)
13 (derive ::anglia ::en)
14 (derive ::usa ::en)
15 (derive ::kanada ::en)
16 (derive ::kanada ::fr)))
17
18;; definiujemy multimetodę
19
20(defmulti powitaj identity :hierarchy (var *powitania*))
21
22;; tworzymy implementacje dla różnych wartości dyspozycyjnych
23
24(defmethod powitaj ::pl [_] "Cześć!")
25(defmethod powitaj ::fr [_] "Bonjour!")
26(defmethod powitaj ::en [_] "Hello!")
27
28;; wywołujemy multimetodę
29
30(powitaj ::pl) ;=> "Cześć!"
31(powitaj ::usa) ;=> "Hello!"
32
33(powitaj ::kanada)
34
35; >> Execution error (IllegalArgumentException) at user/eval160 (REPL:1).
36; >> Multiple methods in multimethod 'powitaj' match dispatch value:
37; >> :user/kanada -> :user/fr and :user/en, and neither is preferred
;; tworzymy własną hierarchię tagów
(def ^:dynamic *powitania* (make-hierarchy))
;; mapujemy kraje na języki urzędowe
;; i aktualizujemy powiązanie główne zmiennej dynamicznej
;; we wszystkich wątkach
(alter-var-root (var *powitania*)
#(-> %
(derive ::polska ::pl)
(derive ::francja ::fr)
(derive ::anglia ::en)
(derive ::usa ::en)
(derive ::kanada ::en)
(derive ::kanada ::fr)))
;; definiujemy multimetodę
(defmulti powitaj identity :hierarchy (var *powitania*))
;; tworzymy implementacje dla różnych wartości dyspozycyjnych
(defmethod powitaj ::pl [_] "Cześć!")
(defmethod powitaj ::fr [_] "Bonjour!")
(defmethod powitaj ::en [_] "Hello!")
;; wywołujemy multimetodę
(powitaj ::pl) ;=> "Cześć!"
(powitaj ::usa) ;=> "Hello!"
(powitaj ::kanada)
; >> Execution error (IllegalArgumentException) at user/eval160 (REPL:1).
; >> Multiple methods in multimethod 'powitaj' match dispatch value:
; >> :user/kanada -> :user/fr and :user/en, and neither is preferred
Widzimy, że wywołanie powitaj z argumentem ::kanada sprawia kłopoty. Multimetoda
nie może rozdysponować wywołania, ponieważ więcej niż jedna funkcja pasuje
do uzyskanej z użyciem identity wartości dyspozycyjnej. Dla Kanady mamy bowiem
zdefiniowane podtypy znacznikowe ::en i ::fr, ponieważ w tym kraju zarówno
angielski, jak i francuski, są językami urzędowymi. Musimy zdecydować się więc
i podpowiedzieć programowi, którą wartość powinien wybrać.
Obsługa takich przypadków możliwa jest z użyciem funkcji prefer-method.
Użycie:
(prefer-method nazwa wartość-dyspozycyjna…).
Funkcja przyjmuje multimetodę, której identyfikator wyrażono symbolem, oraz jedną lub więcej wartości dyspozycyjnych, które zostaną uszeregowane w kolejności ich podawania. Porządek podanych wartości będzie wpływał na wybór wariantu multimetody, gdy wystąpi sytuacja konfliktowa spowodowana dopasowaniem więcej niż jednej z nich (preferowana będzie pierwsza występująca wartość).
Wartością zwracaną jest obiekt multimetody, której tabela preferowanych wartości
(pole preferTable) została zaktualizowana we wszystkich wątkach.
Żeby rozwiązać problem z poprzedniego przykładu, wystarczy dopisać następujące linie:
prefer-method
38;; preferencje języków, gdy pasuje więcej niż jeden
39
40(prefer-method powitaj ::en ::fr)
41
42;; wywołujemy multimetodę
43
44(powitaj ::pl) ;=> "Cześć!"
45(powitaj ::usa) ;=> "Hello!"
46(powitaj ::kanada) ;=> "Hello!"
;; preferencje języków, gdy pasuje więcej niż jeden
(prefer-method powitaj ::en ::fr)
;; wywołujemy multimetodę
(powitaj ::pl) ;=> "Cześć!"
(powitaj ::usa) ;=> "Hello!"
(powitaj ::kanada) ;=> "Hello!"
Protokoły
Protokół (ang. protocol) to pojęcie wywodzące się z obiektowego paradygmatu programowania. W ogólnym rozumieniu oznacza ono zbiór zasad określający sposób komunikacji między instancjami różnych klas (obiektami). Wspomniana komunikacja to nic innego jak wywoływanie przypisanych do obiektów metod, których nazwy i argumentowości zostały wcześniej określone (zapowiedziane) protokołem.
Mamy więc dodatkowy mechanizm, który umożliwia dodawanie do klas pewnego rodzaju adnotacji, dzięki którym inne części programu „wiedzą”, jakich operacji spodziewać się po tych klasach. W jaki sposób te dodatkowe informacje mogą być pomocne? Czy tego samego nie osiągniemy trzymając się ustalonej konwencji nazewniczej dla metod?
Możemy powiedzieć, że dzięki protokołom możliwe jest wprowadzanie pewnych
kontraktów, które określają, jakie metody będzie można wywoływać na obiektach. Co
istotne zadziała to zarówno dla klas znanych w momencie tworzenia programu, jak i dla
klas jeszcze nie stworzonych bądź importowanych z zewnątrz. Widzimy tu wyraźnie
ograniczenie użycia samych nazw metod. Możemy wprawdzie umówić się z zespołem
tworzącym program, że metoda dodaj będzie zawsze oznaczała dodawanie, ale nie
będziemy mogli tego samego wymagać od dostawców zewnętrznych bibliotek, ani nie
przewidzimy (szczególnie w projektach otwartoźródłowych) jak potoczą się losy naszego
projektu w przyszłości.
Dzięki protokołom możemy wytwarzać dodatkową warstwę, która nie będzie od klas zależała, ale pozwoli określać ich zachowanie przez wyrażanie znaczenia metod o podanych nazwach.
Jeżeli jakaś klasa definiuje określone pewnym protokołem metody, wtedy powiemy, że implementuje protokół. Oczywiście same protokolarne kontrakty nie zawierają szczegółów implementacyjnych, lecz tylko ich zapowiedzi (deklaracje). Konkretne metody będzie więc trzeba zdefiniować.
W praktyce protokół to zbiór deklaracji powiązanych logicznie metod lub funkcji, który potem staje się wzorcem dla tworzenia nowych typów danych lub rozszerzania istniejących. Jeżeli jakiś typ danych implementuje protokół, to znaczy, że na wartościach tego typu możemy dokonywać określonych protokołem operacji.
Protokoły przypominają stanowiska piastowane w miejscu pracy. Do pracowników (klas) mogą być przypisane różne role (protokoły), a z każdą z nich związany będzie pewien konkretny zestaw obowiązków (zadeklarowane metody). Znając czyjeś stanowisko jesteśmy w stanie dowiedzieć się, czy piastujący je pracownik może nam pomóc w rozwiązaniu konkretnego problemu. Doświadczeni pracownicy mogą mieć kompetencje w wielu dziedzinach (wiele protokołów opisujących klasę) i efektywnie być przypisani do więcej niż jednego stanowiska (gdy np. ich kolega wybierze się na urlop). Analogicznie: pojedynczy typ danych (definiowany klasą) może implementować wiele protokołów, z których każdy mówi o zdolności do przeprowadzania na tym typie innych zestawów operacji.
Zorientowane obiektowo języki programowania wyposażone są często w konstrukcje pozwalające tworzyć protokoły, aby potem implementować zadeklarowane nimi metody w poszczególnych klasach. W Javie odpowiednikiem protokołów są tzw. interfejsy (ang. interfaces) i w ten właśnie sposób wewnętrznie reprezentowane są protokoły w Clojure, gdy platformą gospodarza jest JVM.
Protokoły są mechanizmem polimorfizmu doraźnego i pozwalają deklarować możliwe do wykonania operacje na danych, ale bez wskazywania konkretnych typów tych ostatnich. Dopiero późniejsze definicje typów (np. klasy w Javie, czy rekordy bądź definicje typów własnych w Clojure) mogą włączać protokoły do użytku i definiować określone nimi funkcje.
Dzięki protokołom:
-
możemy określić, jak korzystać z danych konkretnych typów w pewnych okolicznościach, tzn. jakie operacje można na nich wykonywać;
-
możemy wymóc definiowanie pewnych zestawów operacji dla danych istniejących lub nowo tworzonych typów;
-
możemy rozpoznawać czy dane określonych typów implementują protokoły i różnie traktować je w programie, np. badać, czy typ obsługiwanej przez nasz program wartości implementuje interfejs pozwalający zapisywać lub odczytywać metadane.
Na przykład protokół Policzalne może zawierać zapowiedź abstrakcyjnej operacji
zlicz, której zadaniem jest obliczanie liczby elementów. Inaczej będziemy zliczali
litery łańcuchów znakowych, a inaczej elementy tablic bądź wektorów, jednak dane
wymienionych typów mogą być obsłużone w podobny sposób pod względem osiąganego
celu. Protokół pozwala wskazać, że tak jest. Jeżeli jakiś typ danych implementuje
protokół Policzalne, mamy pewność, że można wywołać metodę zlicz na jego obiekcie
(w językach zorientowanych obiektowo) lub wywołać funkcję zlicz, przekazując jej
wartość tego typu (w językach funkcyjnych).
W Clojure protokół to nazwany zestaw metod o określonych sygnaturach i nazwach, które mogą być potem dopasowywane do różnych obiektowych typów danych systemu gospodarza. Tworzenie protokołów odbywa się w fazie uruchamiania programu – jest to więc mechanizm polimorfizmu dynamicznego.
Wraz z rekordami i definicjami typów protokoły stanowią jedno z rozwiązań problemu wyrazu. Można je w tym kontekście nazwać przypadkami użycia – zawierają deklaracje operacji, które powinny być zdefiniowane w wariantach przeznaczonych do obsługi różnych typów danych.
Na przykład wcześniej wspomniana funkcja zlicz (zadeklarowana w hipotetycznym
protokole Policzalne) zostanie inaczej zaimplementowana dla łańcuchów znakowych
(typ java.lang.String), a inaczej dla wektorów (typ
clojure.lang.PersistentVector). W przypadku tych pierwszych będą zliczane znaki,
a w przypadku drugich elementy, chociaż dla obu wywołamy tę samą polimorficzną
funkcję.
Widać tu istotną różnicę w stosunku do języków bazujących na obiektowym paradygmacie programowania. Nowe operacje nie są tu metodami, które wywołujemy na obiektach, lecz niezależnymi, publicznymi funkcjami. Decyzja o wybraniu konkretnego wariantu danej funkcji (przypisanego do danego typu danych) jest podejmowana w czasie wywoływania wersji polimorficznej, a podstawą tej decyzji jest typ pierwszego przekazywanego argumentu.
Korzystanie z protokołów polega na ich tworzeniu, a następnie implementowaniu
zadeklarowanych w nim metod w odniesieniu do nowych lub istniejących typów
danych. W przypadku nowych typów wykorzystywanymi konstrukcjami będą
defrecord lub deftype, natomiast w przypadku
istniejących (w tym wbudowanych typów obiektowych)
extend, extend-type
i extend-protocol.
Definiowanie protokołów, defprotocol
Z użyciem makra defprotocol możemy tworzyć nowe protokoły, czyli nazwane zestawy
operacji wykorzystywanych podczas definiowania i rozszerzania obiektowych typów
danych.
Protokoły będą stworzone w oparciu o mechanizm platformy gospodarza, np. w przypadku JVM jako interfejsy Javy i wzbogacone o odpowiednie struktury kontrolne specyficzne dla Clojure.
Użycie:
(defprotocol nazwa łańcuch-dok? & opcja… & sygnatura…).
Podawana jako pierwszy argument nazwa protokołu powinna być niezacytowanym symbolem, który stanie się nazwą tworzonego interfejsu (w przypadku platformy JVM). Po nazwie można umieścić opcjonalny łańcuch dokumentujący wyrażony łańcuchem znakowym w postaci literału ujętego w znaki cudzysłowu.
Kolejne argumenty makra to opcje i deklaracje polimorficznych funkcji wyrażone sygnaturami zbudowanymi na bazie listowych S-wyrażeń:
(nazwa [this argument…] łańcuch-dok?).
Naczelnym elementem listy powinna być nazwa polimorficznej funkcji, a kolejnym
wektorowe S-wyrażenie grupujące przyjmowane przez nią
argumenty. Pierwszym z nich będzie zawsze obiekt instancji bieżącej (odpowiednik
this z Javy). Podczas wywoływania funkcji (zdefiniowanych potem na bazie protokołu
dla danego typu danych) będzie on przekazywany automatycznie i nie należy podawać go
wprost.
W odniesieniu do argumentów i wartości zwracanych przez metody możliwe jest zastosowanie sugerowania typów.
Każda deklarowana funkcja będzie identyfikowana z użyciem podanej nazwy z dookreśloną
przestrzenią nazw, która będzie taka, jak bieżąca przestrzeń ustawiona
w momencie wywoływania makra defprotocol.
Efektem pracy makra będzie utworzenie:
- interfejsu systemu gospodarza (np.
user.Nazwa), - mapy protokolarnej reprezentowanej mapą (np.
user/Nazwa), - polimorficznych funkcji (np.
user/funkcja).
Nazwa interfejsu będzie taka sama jak nazwa obiektu reprezentującego protokół, a umieszczony on zostanie w pakiecie o nazwie takiej, jak bieżąca przestrzeń nazw.
Poza obiektem interfejsu umieszczonym w pakiecie stworzona zostanie też zmienna
globalna internalizowana w bieżącej przestrzeni nazw. Jej
powiązanie główne będzie wskazywało na mapę (wartość typu
clojure.lang.PersistentArrayMap) opisującą protokół.
Polimorficzne funkcje będą dodatkowo identyfikowane zmiennymi globalnymi zinternalizowanymi w bieżącej przestrzeni nazw.
Makro defprotocol wymaga, aby deklarowane metody zawsze specyfikowały pierwszy
argument, który będzie służył do przekazywania wartości, na których funkcje będą
operowały. Dodatkowo typ danych tego pierwszego argumentu zostanie użyty, aby
zdecydować, który wariant polimorficznej funkcji powinien być wywołany. Możemy
więc mieć na przykład tak samo nazwaną funkcję obsługi dla liczb i dla łańcuchów
znakowych, a to, która implementacja zostanie wybrana, zależy od pierwszego
argumentu.
W związku z powyższym możemy więc powiedzieć, że mamy tu do czynienia z tzw. polimorfizmem jednodyspozycyjnym (ang. single-dispatch polymorphism), działającym na bazie typów (ang. type-driven) w sposób dynamiczny. Jednodyspozycyjność oznacza, że mamy do czynienia z pojedynczym obiektem, który używany jest do podjęcia decyzji o przekazaniu wywołania do konkretnej implementacji (typ pierwszego argumentu funkcji), natomiast dynamiczność, że decyzja ta zapada w trakcie działania programu, a nie podczas kompilacji.
Właściwe definicje abstrakcyjnych funkcji zadeklarowanych w protokołach możemy
kojarzyć z tworzonymi typami danych z użyciem makr deftype,
defrecord czy reify. Jesteśmy też w stanie rozszerzać
istniejące typy o protokoły (i dodawać przeznaczone dla nich implementacje operacji),
korzystając z extend, albo z łatwiejszych w użyciu odpowiedników:
extend-protocol i extend-type.
defprotocol
1;; definicja protokołu
2
3(defprotocol Policzalne
4 "Zawiera operacje dla policzalnych typów danych."
5
6 (zlicz
7 [this] [this more]
8 "Zlicza elementy podanej struktury.")
9
10 (policzalne?
11 [this]
12 "Dla policzalnych typów danych zwraca logiczną prawdę."))
13
14;; sprawdzanie typów utworzonych obiektów
15
16(type user/Policzalne) ; => clojure.lang.PersistentArrayMap
17(type user.Policzalne) ; => java.lang.Class
18(interface? user.Policzalne) ; => true
19
20;; wyświetlanie mapy opisującej protokół
21
22user/Policzalne
23; => Policzalne
24; => {:doc "Zawiera operacje dla policzalnych typów danych."
25; => :method-builders {
26; => #'user/policzalne? #object[user$eval106$fn__10621 0x424 "user$eval106$fn__10621@424"]
27; => #'user/zlicz #object[user$eval106$fn__10634 0x728 "user$eval106$fn__10634@728"]}
28; => :method-map {:policzalne? :policzalne? :zlicz :zlicz}
29; => :on user.Policzalne
30; => :on-interface user.Policzalne
31; => :sigs {
32; => :policzalne? {
33; => :arglists ([this])
34; => :doc "Dla policzalnych typów danych zwraca logiczną prawdę."
35; => :name policzalne?}
36; => :zlicz {
37; => :arglists ([this] [this & args])
38; => :doc "Zlicza elementy podanej struktury."
39; => :name zlicz}}
40; => :var #'user/Policzalne}
41
42;; definiowanie rekordowego typu implementującego protokół Policzalne
43
44(defrecord Osoba [imię nazwisko wiek]
45 Policzalne ; implementacja protokołu:
46 (zlicz [this] (:wiek this)) ; · implementacja metody
47 (policzalne? [this] true)) ; · implementacja metody
48
49;; tworzenie rekordu (implementującego protokół Policzalne)
50
51(def Paweł (->Osoba "Paweł" "Wilk" 99))
52
53;; sprawdzanie działania funkcji polimorficznych
54
55(policzalne? Paweł) ; => true
56(zlicz Paweł) ; => 99
;; definicja protokołu
(defprotocol Policzalne
"Zawiera operacje dla policzalnych typów danych."
(zlicz
[this] [this more]
"Zlicza elementy podanej struktury.")
(policzalne?
[this]
"Dla policzalnych typów danych zwraca logiczną prawdę."))
;; sprawdzanie typów utworzonych obiektów
(type user/Policzalne) ; => clojure.lang.PersistentArrayMap
(type user.Policzalne) ; => java.lang.Class
(interface? user.Policzalne) ; => true
;; wyświetlanie mapy opisującej protokół
user/Policzalne
; => Policzalne
; => {:doc "Zawiera operacje dla policzalnych typów danych."
; => :method-builders {
; => #'user/policzalne? #object[user$eval106$fn__10621 0x424 "user$eval106$fn__10621@424"]
; => #'user/zlicz #object[user$eval106$fn__10634 0x728 "user$eval106$fn__10634@728"]}
; => :method-map {:policzalne? :policzalne? :zlicz :zlicz}
; => :on user.Policzalne
; => :on-interface user.Policzalne
; => :sigs {
; => :policzalne? {
; => :arglists ([this])
; => :doc "Dla policzalnych typów danych zwraca logiczną prawdę."
; => :name policzalne?}
; => :zlicz {
; => :arglists ([this] [this & args])
; => :doc "Zlicza elementy podanej struktury."
; => :name zlicz}}
; => :var #'user/Policzalne}
;; definiowanie rekordowego typu implementującego protokół Policzalne
(defrecord Osoba [imię nazwisko wiek]
Policzalne ; implementacja protokołu:
(zlicz [this] (:wiek this)) ; · implementacja metody
(policzalne? [this] true)) ; · implementacja metody
;; tworzenie rekordu (implementującego protokół Policzalne)
(def Paweł (->Osoba "Paweł" "Wilk" 99))
;; sprawdzanie działania funkcji polimorficznych
(policzalne? Paweł) ; => true
(zlicz Paweł) ; => 99
Rozszerzanie protokołów, extend-protocol
Z użyciem makra extend-protocol możemy powiązać wcześniej zdefiniowany protokół
z wybranymi typami danych, tworząc implementacje polimorficznych funkcji
zadeklarowanych w tym protokole. Jest to idiomatyczna i zwięzła forma rozszerzania
protokołu, pozwalająca przypisać implementacje do wielu typów w jednej konstrukcji.
Użycie:
(extend-protocol protokół & wyrażenie…);
gdzie wyrażenie to pary:
typ specyfikacja…,
a specyfikacja to:
(nazwa-metody [this & argument…] ciało).
Pierwszym argumentem makra powinna być nazwa protokołu, który został wcześniej
utworzony z użyciem defprotocol.
Kolejne argumenty to specyfikacje. Każda powinna składać się z nazwy typu, protokołu lub interfejsu platformy gospodarza, po której powinna pojawić się jedna lub więcej definicji metod.
Podawane typy mogą być zarówno typami natywnymi platformy gospodarza (np. String,
Long, Object), jak i typami zdefiniowanymi przez użytkownika z użyciem
deftype bądź defrecord.
Pierwszym przyjmowanym argumentem każdej definiowanej metody o podanej nazwie
powinien być obiekt instancji bieżącej (odpowiednik this z Javy). Jest to zgodne
z wymaganiami mechanizmu rozpoznawania typów bazującego na pojedynczym rozdzielaniu
wywołań, na którym opiera się system protokołów w Clojure. Typ pierwszego argumentu
decyduje o tym, która implementacja zostanie wybrana w czasie działania programu.
W przeciwieństwie do extend, makro extend-protocol pozwala podać ciała
funkcji, pozwalając na ich wyrażenie w naturalnej postaci (zamiast przypisywania ich
do mapy).
W ramach jednego wywołania extend-protocol możemy podać implementacje dla wielu
typów jednocześnie. Dla każdego z nich można zdefiniować jeden lub więcej wariantów
funkcji zadeklarowanych w protokole. Należy przy tym zadbać, aby nazwy oraz liczba
parametrów odpowiadały tym, które zostały tym protokołem określone — w przeciwnym
razie makro zgłosi błąd kompilacji.
extend-protocol
1;; definicja protokołu
2
3(defprotocol Policzalne
4 "Zawiera operacje dla policzalnych typów danych."
5
6 (zlicz
7 [this] [this more]
8 "Zlicza elementy podanej struktury.")
9
10 (policzalne?
11 [this]
12 "Dla policzalnych typów danych zwraca logiczną prawdę."))
13
14;; definiowanie rekordowego typu implementującego protokół Policzalne
15
16(defrecord Osoba [imię nazwisko wiek])
17
18;; rozszerzenie protokołu o implementacje dla typu Osoba
19
20(extend-protocol Policzalne ; rozszerzanie protokołu:
21 Osoba ; · dla typu rekordowego Osoba
22 (zlicz [this] (:wiek this)) ; · implementacja metody
23 (policzalne? [this] true)) ; · implementacja metody
24
25;; tworzenie rekordu (implementującego protokół Policzalne)
26
27(def Paweł (->Osoba "Paweł" "Wilk" 99))
28
29;; sprawdzanie działania funkcji polimorficznych
30
31(policzalne? Paweł) ; => true
32(zlicz Paweł) ; => 99
;; definicja protokołu
(defprotocol Policzalne
"Zawiera operacje dla policzalnych typów danych."
(zlicz
[this] [this more]
"Zlicza elementy podanej struktury.")
(policzalne?
[this]
"Dla policzalnych typów danych zwraca logiczną prawdę."))
;; definiowanie rekordowego typu implementującego protokół Policzalne
(defrecord Osoba [imię nazwisko wiek])
;; rozszerzenie protokołu o implementacje dla typu Osoba
(extend-protocol Policzalne ; rozszerzanie protokołu:
Osoba ; · dla typu rekordowego Osoba
(zlicz [this] (:wiek this)) ; · implementacja metody
(policzalne? [this] true)) ; · implementacja metody
;; tworzenie rekordu (implementującego protokół Policzalne)
(def Paweł (->Osoba "Paweł" "Wilk" 99))
;; sprawdzanie działania funkcji polimorficznych
(policzalne? Paweł) ; => true
(zlicz Paweł) ; => 99
Rozszerzanie typów, extend-type
Z użyciem makra extend-type możemy przypisać implementacje wybranych protokołów do
konkretnego typu danych, tworząc w ten sposób zbiorczą specyfikację zachowań tego
typu.
Jest to skrócona forma rozszerzania wielu protokołów naraz dla pojedynczego typu, wygodna szczególnie wtedy, gdy chcemy zachować modularność kodu wokół konkretnej reprezentacji danych.
Użycie:
(extend-type typ specyfikacja…).
gdzie:
typto nazwa typu danych lub interfejsu,specyfikacjato przypisania metod do protokołów lub interfejsów.
Pierwszym argumentem powinien być typ danych, dla którego przypisujemy
implementacje. Typ ten może być zarówno typem natywnym platformy gospodarza
(np. String, Long, Object), jak i typem zdefiniowanym z użyciem
deftype lub defrecord.
Każda specyfikacja powinna składać się z nazwy protokołu lub interfejsu platformy gospodarza, po której może (ale nie musi) pojawić się jedna lub więcej definicji metod w postaci:
(nazwa-metody [this & argument…] ciało).
Każda funkcja musi zawierać jako pierwszy argument bieżącą instancję (oznaczaną
zazwyczaj jako this) — to na podstawie typu tego argumentu zostanie dokonany wybór
odpowiedniej implementacji w czasie działania programu.
Ciała funkcji można definiować bezpośrednio, bez konieczności tworzenia mapy, co
odróżnia extend-type od bardziej niskopoziomowego extend. Wszystkie
metody muszą odpowiadać wcześniej zdefiniowanym sygnaturom funkcji zawartych
w rozszerzanych protokołach — ich brak lub niezgodność będzie skutkować błędem
podczas kompilacji.
Makro extend-type szczególnie dobrze sprawdza się w przypadkach, gdy chcemy
określić zachowanie jednego typu wieloma protokołami — umożliwia to zorganizowanie
implementacji w jednym miejscu, zgodnie z zasadą kapsułkowania zachowań względem
struktury danych.
extend-type
1;; definicja dwóch protokołów
2
3(defprotocol Zliczalne
4 "Zawiera operacje do zliczania czegoś."
5 (zlicz [this]))
6
7(defprotocol Imienne
8 "Zawiera operacje związane z imieniem."
9 (imię [this]))
10
11;; definicja typu rekordowego
12
13(defrecord Osoba [imię nazwisko wiek])
14
15;; przypisanie implementacji obu protokołów dla typu Osoba
16
17(extend-type Osoba
18 Zliczalne
19 (zlicz [this] (:wiek this))
20
21 Imienne
22 (imię [this] (str (:imię this) " " (:nazwisko this))))
23
24;; tworzenie instancji
25
26(def p (->Osoba "Paweł" "Wilk" 18))
27
28;; użycie funkcji polimorficznych
29
30(zlicz p) ; => 18
31(imię p) ; => "Paweł Wilk"
;; definicja dwóch protokołów
(defprotocol Zliczalne
"Zawiera operacje do zliczania czegoś."
(zlicz [this]))
(defprotocol Imienne
"Zawiera operacje związane z imieniem."
(imię [this]))
;; definicja typu rekordowego
(defrecord Osoba [imię nazwisko wiek])
;; przypisanie implementacji obu protokołów dla typu Osoba
(extend-type Osoba
Zliczalne
(zlicz [this] (:wiek this))
Imienne
(imię [this] (str (:imię this) " " (:nazwisko this))))
;; tworzenie instancji
(def p (->Osoba "Paweł" "Wilk" 18))
;; użycie funkcji polimorficznych
(zlicz p) ; => 18
(imię p) ; => "Paweł Wilk"
Rozszerzanie przypadków, extend
Z użyciem makra extend możemy przypisać implementacje wybranych
protokołów lub interfejsów platformy gospodarza do
wskazanego typu danych.
Jest to najbardziej niskopoziomowa forma rozszerzania protokołów w Clojure i wymaga ona jawnego zadeklarowania funkcji, które następnie przypisywane są do protokołów z użyciem mapy.
Użycie:
(extend typ wyrażenie);
gdzie:
wyrażenieto paryprotokół mapa-specyfikacji …
składające się z:- identyfikatorów protokołów bądź interfejsów (
protokół), - specyfikacji metod (
mapa-specyfikacji) wyrażających implementacje metod z użyciem map w formie{:nazwa funkcja}.
- identyfikatorów protokołów bądź interfejsów (
Pierwszym argumentem powinien być typ, do którego przypisujemy
zachowania. Może to być zarówno typ platformy JVM (np. String, Object, Long),
jak i typ utworzony przez użytkownika z użyciem deftype lub
defrecord.
Każde dwa argumenty wyrażenia (wyrażenie) to pary, których pierwszy element
powinien identyfikować protokół lub interfejs systemu
gospodarza, a drugi powinien być mapą (mapa-specyfikacji).
Mapa specyfikacji powinna zawierać nazwy zadeklarowanych protokołem metod (:nazwa)
wyrażone kluczami i przypisane do nich funkcje (funkcja).
W odróżnieniu od extend-type i extend-protocol, które automatycznie przetwarzają
postać uproszczoną, makro extend wymaga podania obiektu funkcyjnego, który może być
efektem ręcznego utworzenia funkcji anonimowej lub podania
symbolu identyfikującego funkcję nazwaną.
Jest to forma niskopoziomowa i zazwyczaj niezalecana w zastosowaniach ogólnych, jednak bywa użyteczna przy dynamicznym rozszerzaniu typów lub w sytuacjach, w których wykorzystujemy metaprogramowanie, np. generując implementacje w czasie działania programu.
Makro extend nie obsługuje rozszerzania wielu typów naraz. Dla każdego typu należy
osobno wywołać extend z odpowiednią mapą.
1;; definicja protokołu
2
3(defprotocol Zliczalne
4 "Zawiera operacje do zliczania czegoś."
5 (zlicz [this]))
6
7;; definicja typu rekordowego
8
9(defrecord Osoba [imię nazwisko wiek])
10
11;; przypisanie implementacji protokołu Zliczalne
12;; w formie jawnej mapy metod
13
14(extend Osoba
15 Zliczalne
16 {:zlicz (fn [this] (:wiek this))})
17
18;; tworzenie instancji
19
20(def p (->Osoba "Paweł" "Wilk" 18))
21
22;; wywołanie funkcji zadeklarowanej w protokole
23
24(zlicz p) ; => 18
;; definicja protokołu
(defprotocol Zliczalne
"Zawiera operacje do zliczania czegoś."
(zlicz [this]))
;; definicja typu rekordowego
(defrecord Osoba [imię nazwisko wiek])
;; przypisanie implementacji protokołu Zliczalne
;; w formie jawnej mapy metod
(extend Osoba
Zliczalne
{:zlicz (fn [this] (:wiek this))})
;; tworzenie instancji
(def p (->Osoba "Paweł" "Wilk" 18))
;; wywołanie funkcji zadeklarowanej w protokole
(zlicz p) ; => 18