

Powiązania pozwalają identyfikować pamięciowe obiekty, z których korzystamy w programach (nadawać im stałe tożsamości), a przestrzenie nazw umożliwiają zarządzanie widocznością i kapsułkowanie fragmentów kodu źródłowego. W tym odcinku dowiemy się, jak rozumieć te mechanizmy w Clojure i jak ich używać.
Powiązania i przestrzenie nazw
Istotnym elementem programowania komputerów jest zarządzanie identyfikatorami, czyli zrozumiałymi dla człowieka etykietami, które pozwalają odwoływać się do obiektów umieszczonych w pamięci.
Powiązania
Powiązanie (ang. binding), zwane też wiązaniem, jest skrótowym określeniem
procesu powiązywania nazw (ang. name binding) bądź wiązania nazw. Polega on
na kojarzeniu pamięciowych obiektów (danych lub podprogramów)
z identyfikatorami. Na przykład litera a może być powiązana z komórką pamięci
przechowującą wartość 123.
(def a 123) ; powiązanie globalne
(let [a 123] a) ; powiązanie leksykalne
Dzięki powiązaniom nazw możemy w kodzie źródłowym programów komputerowych odwoływać się do umieszczonych w pamięci danych z użyciem czytelnych identyfikatorów zamiast np. pamięciowych adresów. Poza tym otwierają one drogę do abstrahowania struktur danych, tzn. uniezależniania dostępu do nich od sprzętowej architektury.
Nawet gdyby istniał komputer, w którym pamięciowe adresy są alfanumeryczne i definiowane przez programistę, powiązania wciąż byłyby pomocne, ponieważ uniezależniałyby dane od ich lokalizacji w pamięci. Powiązanie można zmienić w trakcie działania programu, natomiast adresu pamięciowego (nawet najbardziej czytelnego) już nie. Temat ten jest szerzej omówiony w rozdziale XIII.
Przykłady wiązania nazw z wartościami mogą kojarzyć się z operowaniem na zmiennych, jednak wytwarzanie asocjacji wartości z identyfikatorem niekoniecznie oznacza, że zawartość obszaru pamięci, w którym znajduje się wartość będzie można zmieniać. Proces powiązywania nazw jest więc czymś bardziej elementarnym, niż tworzenie zmiennych i może być jego etapem.
Języki programowania mogą różnić się w sposobie tworzenia powiązań w zależności od etapów przetwarzania, na których powstają. Będziemy więc mieli do czynienia z wiązaniem statycznym (ang. static binding), zwanym też wiązaniem wczesnym (ang. early binding), które dokonuje się zanim dojdzie do uruchomienia programu (np. w trakcie jego wczytywania bądź w czasie kompilacji), a także z wiązaniem dynamicznym (ang. dynamic binding), zwanym też wiązaniem późnym (ang. late binding), gdy powiązania nazw z obiektami będą tworzone podczas uruchamiania.
W Clojure mamy do czynienia z obsługą obydwu wspomnianych wyżej rodzajów powiązań, chociaż bliższymi stanu faktycznego terminami będą w tym przypadku określenia „powiązanie statyczne” i „powiązanie dynamiczne”, ponieważ podczas rozróżniania nie kładziemy nacisku na etap tłumaczenia kodu źródłowego, lecz na cechy powiązań (np. możliwość ich aktualizowania).
Inżynieria oprogramowania wyróżnia dwie ważne właściwości, które decydują o tym jak i gdzie możemy korzystać z powiązań i wskazywanych nimi wartości:
- zasięg (ang. scope),
- widoczność (ang. visibility).
Zobacz także:
- „Obsługa powiązań” w tym rozdziale.
Zasięg
Zasięgiem powiązania (identyfikatora z pamięciowym obiektem) nazwiemy część programu, w której możemy skorzystać z takiego powiązania, aby odwołać się do obiektu używając przypisanej mu nazwy.
Częścią programu będzie najczęściej leksykalny fragment kodu źródłowego (np. blok, moduł, funkcja, plik z kodem źródłowym, itp.), ale może być też ona rozpatrywana dynamicznie i zależeć od stanu wykonywania się programu w danym punkcie czasu.
Zasięg, który zależy od umiejscowienia, nazwiemy zasięgiem leksykalnym
(ang. lexical scope), a zasięg, który zależy od stanu zasięgiem dynamicznym
(ang. dynamic scope). W tym drugim przypadku dla każdego identyfikatora utrzymywany
będzie specjalny stos powiązań, który może zmieniać się w czasie, w zależności od
kontekstu i przeprowadzanych na powiązaniu operacji. Na przykład w funkcji możemy
odwoływać się do zmiennej dynamicznej nazwanej d zdefiniowanej poza funkcją, której
wartość zostanie zmieniona tuż przed wywołaniem funkcji. Gdyby zasięg d był
leksykalny, to w funkcji zawsze odwoływalibyśmy się do wartości d z chwili
definiowania funkcji (w przypadku języków obsługujących
tzw. domknięcia) lub byłaby ona w funkcji niepowiązana z żadną
wartością.
W Clojure obsługiwane są następujące rodzaje zasięgów powiązań:
- leksykalny – zależny od umiejscowienia identyfikatora w kodzie źródłowym,
- dynamiczny – zależny od kontekstu wywołań zmiennych dynamicznych,
- nieograniczony – wyrażany zmiennymi globalnymi.
1;; zasięg leksykalny
2;; ograniczony ciałem formy let
3
4(let [a 123] ; powiązanie symbolu z wartością
5 a) ; użycie wartości identyfikowanej symbolem
6
7;; zasięg nieograniczony
8
9(def a 123) ; powiązanie zmiennej globalnej z wartością
10a ; użycie wartości bieżącej identyfikowanej symbolem
11
12;; zasięg dynamiczny
13
14(def ^:dynamic a 456) ; powiązanie zmiennej dynamicznej z wartością
15a ; użycie wartości bieżącej identyfikowanej symbolem
16(binding [a 789] ; dynamiczna zmiana wartości bieżącej
17 a) ; użycie zmienionej wartości bieżącej
;; zasięg leksykalny
;; ograniczony ciałem formy let
(let [a 123] ; powiązanie symbolu z wartością
a) ; użycie wartości identyfikowanej symbolem
;; zasięg nieograniczony
(def a 123) ; powiązanie zmiennej globalnej z wartością
a ; użycie wartości bieżącej identyfikowanej symbolem
;; zasięg dynamiczny
(def ^:dynamic a 456) ; powiązanie zmiennej dynamicznej z wartością
a ; użycie wartości bieżącej identyfikowanej symbolem
(binding [a 789] ; dynamiczna zmiana wartości bieżącej
a) ; użycie zmienionej wartości bieżącej
Widoczność
Widocznością nazwiemy część programu, w której możemy uzyskać dostęp i korzystać z powiązanej z identyfikatorem wartości przechowywanej w pamięciowej strukturze. Powiemy więc, że (zależnie od języka) widoczna jest: zmienna, stała, wartość lub inna konstrukcja odpowiedzialna za przechowywanie danych.
Przykładem różnicy między widocznością a zasięgiem jest sytuacja, w której pamięciowy
obiekt (np. liczba całkowita 2) identyfikowany symboliczną nazwą (np. x) w pewnym
obszarze leksykalnym (np. wewnątrz definicji funkcji) przestaje być widoczny,
ponieważ nazwa x została użyta jako parametr funkcji, którego zadaniem jest
odwoływanie się do wartości przekazywanego argumentu wywołania. Wartość 2 nie znika,
ale jej identyfikacja jest tymczasowo przesłaniana w obszarze definicji
funkcji. Gdy definiujący funkcję fragment kodu źródłowego się zakończy x nadal
będzie odnosić się do wartości 2. Powiemy więc o zasięgu x (lub powiązania x
z wartością), ale o widoczności wartości 2 powiązanej z x.
Widoczność identyfikowanego obiektu nie będzie nigdy większa, niż zasięg powiązania, ale zasięg powiązania może być większy, niż widoczność – tak jak np. w powyższym przykładzie.
W Clojure widocznością możemy sterować, korzystając z przestrzeni nazw i określając globalne identyfikatory jako prywatne bądź publiczne, natomiast zasięg zależy od rodzaju użytych konstrukcji i od kontekstu.
Przestrzenie nazw
W Clojure funkcjonuje mechanizm przestrzeni nazw (ang. namespace). Dzięki niemu można organizować poszczególne elementy programów i separować symboliczne identyfikatory, które pochodzą z różnych źródeł, aby unikać konfliktów nazewnictwa.
Przestrzeń nazw jest w sensie abstrakcyjnym słownikiem terminów, z których każdy powinien być niepowtarzalny w jej obrębie. W sposób bardziej przystępny możemy określić przestrzeń nazw z Clojure mianem kontenera o unikatowej nazwie służącego do przechowywania globalnie dostępnych powiązań.
Programy pisane w języku Clojure, w których tworzone są powiązania o zasięgu nieograniczonym (służące do identyfikowania funkcji bądź odwołań do wartości), zawsze będą korzystały z przestrzeni nazw, ponieważ właśnie w nich powiązania będą umieszczane.
Przestrzeń bieżąca
Skąd kompilator czerpie wiedzę na temat tego, o jaką przestrzeń chodzi? Po pierwsze może korzystać z aktualnie ustawionej przestrzeni bieżącej. Gdy spojrzymy na plik z kodem źródłowym dowolnego programu, zobaczymy na jego wstępie zapis podobny do poniższego:
(ns smangler.api
(:require [clojure.string :as string]
[clojure.set :refer all]))
(ns smangler.api
(:require [clojure.string :as string]
[clojure.set :refer all]))
Mówi on kompilatorowi, żeby podczas dalszego wczytywania kodu źródłowego ustawił
specjalne odwołanie identyfikowane symbolem *ns* na wartość odpowiadającą obiektowi
typu clojure.lang.Namespace, czyli właśnie na przestrzeń nazw. Jeżeli przestrzeń
o podanej nazwie (w tym przykładzie smangler.api) jeszcze nie istnieje, zostanie
utworzona. Konsekwencją tej operacji będzie umieszczanie każdego tworzonego dalej
powiązania o zasięgu nieograniczonym właśnie w tej przestrzeni, a dokładniej
w znajdującej się w jej obiekcie specjalnej mapie.
Poniższy zapis sprawi, że w przestrzeni bieżącej (np. smangler.api) pojawi się
powiązanie symbolu a z obiektem typu Var odwołującym się do wartości 1:
(def a 1)
(def a 1)
Każdy niezacytowany symbol użyty w pliku źródłowym po wystąpieniu ns, który nie
został leksykalnie powiązany, będzie poszukiwany właśnie w przestrzeni bieżącej
(wskazywanej przez bieżącą wartość *ns*), aby znaleźć skojarzoną z nim konstrukcję
przechowującą odwołanie do jakiejś wartości.
Makro ns obsługuje sporo dodatkowych opcji, jednak :require jest
najczęściej wykorzystywaną. Sprawia ona, że w przestrzeni powstają tzw. aliasy, które
pozwalają odwoływać się do innych przestrzeni (opcja :as). Można go również używać
do umieszczania w bieżącej przestrzeni powiązań pochodzących z innej, aby nie trzeba
było poprzedzać symboli jej nazwą (opcja :refer).
Widzimy więc, że powołując do istnienia funkcje czy zmienne globalne w Clojure,
programista musi wybrać, w jakiej przestrzeni będą rezydowały ich symboliczne
identyfikatory. Jest potem w stanie odwoływać się do dwóch różnych konstruktów
o takich samych nazwach, lecz zarejestrowanych w różnych przestrzeniach, np. funkcji
sumuj z przestrzeni lata-świetlne i funkcji sumuj z przestrzeni
liczby-wymierne (z użyciem zapisu lata-świetlne/sumuj
i liczby-wymierne/sumuj). Może też zdecydować, że niektóre powiązania pochodzące
z innych przestrzeni mają być odzwierciedlone w przestrzeni bieżącej, jeżeli ich
nazwy są wystarczająco unikatowe, a nawet dokonać przemianowania.
Przestrzeń dookreślona
Do globalnych identyfikatorów umiejscowionych w przestrzeniach nazw możemy odwoływać się również z użyciem specjalnej formy symbolowej, w której poza właściwą nazwą identyfikującą znajdziemy też nazwę przestrzeni, np.:
(clojure.core/println 1 2 3)
(clojure.core/println 1 2 3)
Powyższy zapis oznacza, że chcemy wywołać funkcję identyfikowaną nazwą println
z przestrzeni nazw clojure.core. Aby odnaleźć podprogram funkcji, kompilator użyje
określonej przez nas przestrzeni zamiast korzystać z tej wskazywanej wartością
bieżącą zmiennej *ns*.
Budowa przestrzeni
W bardziej usystematyzowany sposób scharakteryzujemy przestrzeń nazw jako obiekt
(typu clojure.lang.Namespace):
-
służący do przechowywania:
- identyfikatorów zmiennych globalnych,
- identyfikatorów odwołujących się do klas Javy,
- identyfikatorów odwołujących się do innych przestrzeni nazw;
-
zawierający dwie asocjacyjne struktury:
- mapę aliasów,
- mapę odwzorowań;
-
rejestrowany w globalnym repozytorium w momencie wytworzenia, aby mechanizmy języka mogły z niego skorzystać podczas automatycznej zamiany symbolicznych identyfikatorów na odpowiadające im pamięciowe obiekty skrywające wartości.
Funkcją obecnej w przestrzeni nazw mapy aliasów jest tworzenie odwołań do innych przestrzeni nazw z użyciem przypisanych im alternatywnych identyfikatorów w postaci symboli.
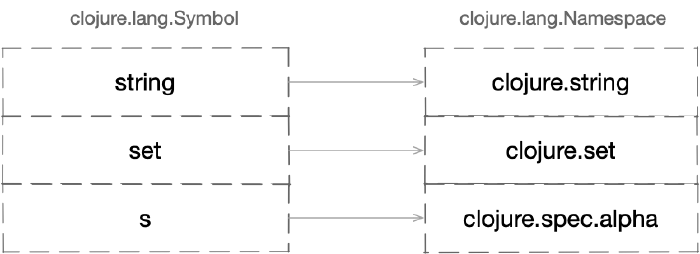
Mapa aliasów przestrzeni nazw przyporządkowuje symbole do obiektów innych przestrzeni
Zamiast poprzedzać każdą nazwę symbolu długą nazwą przestrzeni
(np. io.randomseed.blog.kalkulator/dodaj) możemy w przestrzeni bieżącej wytworzyć
jej alias (np. kalkulator) i podczas odwoływania się do identyfikowanych wartości
bądź funkcji używać skróconej wersji (np. kalkulator/dodaj).
Mapa odwzorowań zawiera pary elementów, w których kluczami są również symbole, a skojarzonymi z nimi wartościami mogą być:
- obiekty typu
Var, - odwołania do klas Javy.
Warto zauważyć, że obiekt typu Var umieszczony w przestrzeni nazw nazywamy zmienną
globalną. Zmiennych globalnych w Clojure używa się
do identyfikowania informacji konfiguracyjnych bądź podprogramów (np. funkcji czy
makr).
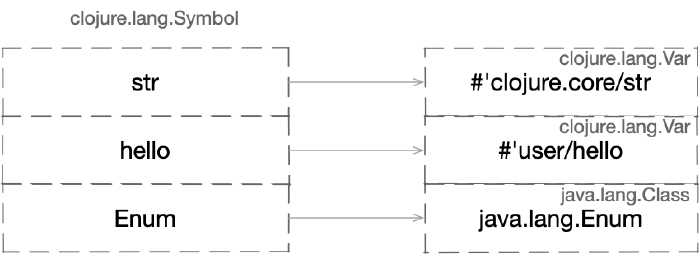
Mapa odwzorowań przestrzeni nazw przyporządkowuje symbole do obiektów typu Var lub klas Javy
Wśród wartości znajdujących się w mapie odwzorowań możemy znaleźć nie tylko Vary stworzone i przypisane do tej samej przestrzeni, ale też obiekty znajdujące się w innych przestrzeniach.
Odniesienia do obiektów typu Var pochodzących z innych przestrzeni tworzy się
z użyciem funkcji refer lub use, odniesienia do klas Javy
z użyciem import, natomiast nowe zmienne globalne odwzorowywane są automatycznie
w chwili ich stwarzania (np. z użyciem def czy intern).
Zmienne publiczne i prywatne
Wartym odnotowania jest fakt, że odwzorowania w przestrzeni nazw mogą być oznaczone jako prywatne (ang. private). Nie będą wtedy widoczne poza przestrzenią nazw, w której zostały umieszczone, czyli:
-
Będzie można się do nich odwoływać z wnętrza funkcji, które zdefiniowano w tej samej przestrzeni.
-
Będzie można się do nich odwoływać wtedy, gdy bieżącą, ustawioną przestrzenią nazw jest ta, do której przynależą. Jest to dodatkowy sposób kontrolowania widoczności.
Inicjowanie przestrzeni nazw
Gdy przygotowywane jest środowisko uruchomieniowe języka Clojure, inicjalizowana jest
przestrzeń nazw clojure.core. Symbol *ns* identyfikuje globalną
zmienną dynamiczną zdefiniowaną w clojure.core, a jej bieżąca
wartość wskazuje obiekt bieżącej przestrzeni nazw. W sesji REPL wartość ta zwykle
wskazuje przestrzeń user.
Dla każdej publicznej zmiennej globalnej z clojure.core tworzone są odniesienia
w przestrzeni bieżącej, dzięki czemu funkcje i makra rdzenia języka są dostępne bez
konieczności podawania pełnych nazw. Formy specjalne są obsługiwane bezpośrednio
przez kompilator i nie są przechowywane jako odwzorowania przestrzeni nazw.
Wśród automatycznie dodawanych odniesień znajdziemy między innymi takie, które identyfikują poniższe funkcje:
-
in-ns– służy do ustawiania bieżącej przestrzeni nazw, -
import– przypisuje nazwy klas podanego pakietu Javy do identyfikatorów w bieżącej przestrzeni, -
refer– przypisuje w bieżącej przestrzeni symbole do obiektówVarz innej przestrzeni.
Dzięki temu programista może dalej rozszerzać zawartość przestrzeni nazw o nowe przyporządkowania.
Przedstawione dalej funkcje pozwalają na mniej lub bardziej ogólny dostęp do
przestrzeni nazw. W praktyce jednak rzadko używa się ich bezpośrednio, ale
korzysta z makra ns.
Tworzenie przestrzeni nazw
Aby skorzystać z danej przestrzeni nazw, trzeba najpierw ją utworzyć. Niektóre
przestrzenie powstają automatycznie, np. clojure.core czy user (gdy
używamy REPL). Gdybyśmy jednak chcieli samodzielnie utworzyć przestrzeń nazw, na
przykład w celu hermetyzacji tworzonej przez nas biblioteki bądź lepszego zarządzania
widocznością w aplikacji, możemy skorzystać z odpowiedniej funkcji.
Tworzenie przestrzeni, create-ns
Funkcja create-ns przyjmuje nazwę przestrzeni nazw w postaci literalnego symbolu
i tworzy podaną przestrzeń, jeżeli ta jeszcze nie istnieje. W przypadku, gdy
przestrzeń o podanej nazwie już została utworzona, nie jest podejmowana żadna
czynność.
Użycie:
(create-ns symboliczna-nazwa).
Funkcja przyjmuje nazwę przestrzeni wyrażoną symbolem w formie stałej, a zwraca
obiekt przestrzeni nazw (typu clojure.lang.Namespace).
create-ns
(create-ns 'nowa)
; => #<Namespace nowa>
Zobacz także:
Używanie przestrzeni nazw
Korzystanie z przestrzeni nazw polega na odwoływaniu się do rozmaitych obiektów
z użyciem form symbolowych, czyli symboli w niezacytowanej postaci, które
identyfikują inne obiekty. Umieszczając taki symbol w kodzie źródłowym programu,
sprawiamy, że przeszukana będzie (z użyciem funkcji resolve) odpowiednia przestrzeń
nazw, a następnie pobrana będzie przypisana do symbolicznej nazwy wartość obiektu,
który jest nią identyfikowany.
Przypomnijmy sobie, że symbole mogą mieć dookreśloną przestrzeń nazw lub nie zawierać informacji o przestrzeni. Właściwość ta pozwala używać ich w dwojaki sposób i przekłada się na różne tryby odwoływania się do przestrzeni nazw.
Gdy podamy symbol i nie określimy w nim przestrzeni nazw (np. replace), to
zostanie przeszukana bieżąca przestrzeń nazw. Jeżeli natomiast podamy w symbolu
przestrzeń (np. clojure.string/replace), to będzie przeszukana określona
przestrzeń nazw.
Po operacji przeszukiwania z przestrzeni nazw zostanie pobrany skojarzony
z symboliczną nazwą obiekt. Będzie to albo zmienna globalna typu Var, albo klasa
Javy. Jeżeli mamy do czynienia z odwołaniem do obiektu w innej przestrzeni nazw, to
zostanie ono użyte, aby go uzyskać.
Ustawianie przestrzeni bieżącej, in-ns
Bieżąca przestrzeń nazw może dynamicznie się zmieniać w zależności od woli
programisty. Odwołanie do niej rezyduje w globalnej
zmiennej dynamicznej o nazwie *ns*. Jesteśmy więc
w stanie w danym pliku źródłowym (lub nawet w wyrażeniu przekazanym do makra
binding) dokonać przełączenia przestrzeni przez podmianę wartości tej zmiennej
w wybranym kontekście. Kontekst ten nie musi być leksykalny, chociaż częstą praktyką
jest ustawianie bieżącej przestrzeni nazw na początku pliku źródłowego, którego
wszystkie definicje funkcji, makr i zmiennych globalnych będą podczas jego
wczytywania domyślnie rejestrowały globalne powiązania w wybranej przestrzeni.
Aby nie zastanawiać się nad sposobem przechowywania informacji o bieżącej
przestrzeni, a więc nad metodami operowania na niej, możemy skorzystać z gotowej
funkcji przeznaczonej do przełączania przestrzeni bieżącej. Nazywa się ona in-ns.
Użycie:
(in-ns symboliczna-nazwa).
Funkcja przyjmuje jeden argument, który powinien być formą stałą symbolu. Jeżeli
określona nim przestrzeń nazw jeszcze nie istnieje, będzie wywołana funkcja
create-ns, aby ją utworzyć. Po wykonaniu funkcji powiązanie dynamicznej, globalnej
zmiennej *ns* będzie podmienione i zwrócony zostanie obiekt przestrzeni.
in-ns
(in-ns 'nowa)
; => #<Namespace nowa>
Po wykonaniu powyższego kodu w REPL możemy zdziwić się, że interpreter nie „widzi”
funkcji języka, które wcześniej były osiągalne przez podanie ich symbolicznych
identyfikatorów. Dzieje się tak dlatego, że do nowo utworzonej przestrzeni nie
zaimportowaliśmy powiązań symboli obecnych w przestrzeni user, z której fabrycznie
korzysta REPL.
Żeby korzystać z nazw powiązanych ze zmiennymi globalnymi z innej przestrzeni, należy
skorzystać z (omówionej dalej) funkcji refer, która wytworzy odpowiednie
odniesienia. Istnieje też wygodne makro ns, które zostanie omówione później.
Ustalanie nazwy przestrzeni, namespace
Dzięki funkcji namespace możemy na podstawie podanego symbolu (w literalnej
postaci) zawierającego nazwę przestrzeni, uzyskać właśnie informację o jej nazwie.
Użycie:
(namespace symboliczna-nazwa).
Funkcja ta nie dokonuje przeszukania przestrzeni nazw, po prostu pozyskuje z podanego jako argument symbolu odpowiedni składnik jego nazwy.
Zwracaną wartością jest łańcuch tekstowy lub nil, jeżeli mamy do czynienia
z symbolem bez dookreślonej przestrzeni nazw.
namespace
(namespace 'przestrzeń/jakaś-nazwa)
; => "przestrzeń"
Rozpoznawanie po nazwach, ns-resolve
Dzięki funkcji ns-resolve można uzyskać obiekt identyfikowany symbolem, jeżeli
symbol o takiej nazwie został przypisany do niego w przestrzeni nazw podanej jako
pierwszy argument (jako literalny symbol lub obiekt przestrzeni). Ostatnim argumentem
jest symbol w formie stałej, który identyfikuje poszukiwany obiekt.
Funkcja zwraca obiekt o podanej, wyrażonej literalnym symbolem, nazwie lub wartość
nil, jeżeli w danej przestrzeni nie znaleziono odwzorowania.
Przeszukiwana przestrzeń nazw musi istnieć, a jeżeli nie istnieje, zgłoszony zostanie wyjątek.
W wariancie trójargumentowym funkcja jako drugi argument przyjmuje nazwę
tzw. otoczenia (ang. environment). Może to być dowolna kolekcja, na której można
wywołać funkcję contains? (np. zbiór lub mapa). Jeżeli podany
symbol zostanie w środowisku znaleziony, nie będzie przeszukiwana przestrzeń nazw,
a funkcja zwróci wartość nil.
Użycie:
(ns-resolve przestrzeń-nazw symboliczna-nazwa),(ns-resolve przestrzeń-nazw środowisko symboliczna-nazwa).
ns-resolve
1(ns-resolve 'user 'replace) ; => #'clojure.core/replace
2(ns-resolve *ns* 'replace) ; => #'clojure.core/replace
3(ns-resolve 'clojure.string 'replace) ; => #'clojure.string/replace
4(ns-resolve 'clojure.string 'cośtam) ; => nil
5(ns-resolve *ns* #{'replace 'coś} 'replace) ; => nil
(ns-resolve 'user 'replace) ; => #'clojure.core/replace
(ns-resolve *ns* 'replace) ; => #'clojure.core/replace
(ns-resolve 'clojure.string 'replace) ; => #'clojure.string/replace
(ns-resolve 'clojure.string 'cośtam) ; => nil
(ns-resolve *ns* #{'replace 'coś} 'replace) ; => nil
Rozpoznawanie w bieżącej, resolve
Funkcja resolve jest mniej wymagającą wersją ns-resolve. Nie trzeba jej podawać
nazwy przestrzeni nazw, ponieważ domyślnie korzysta ona z bieżącej (określonej
zmienną globalną *ns*). Można jednak podać symbol w formie stałej z dookreśloną
przestrzenią nazw, a funkcja skorzysta z tej informacji. Wartością zwracaną jest
obiekt typu Var.
Użycie:
(resolve symboliczna-nazwa),(resolve środowisko symboliczna-nazwa).
resolve
1(resolve 'replace)
2; => #'clojure.core/replace
3
4;; podajemy środowisko zawierające symbol
5
6(resolve #{'replace} 'replace)
7; => nil
8
9;; podajemy symbol z dookreśloną przestrzenią nazw
10
11(resolve 'clojure.string/replace)
12; => #'clojure.core/replace
(resolve 'replace)
; => #'clojure.core/replace
;; podajemy środowisko zawierające symbol
(resolve #{'replace} 'replace)
; => nil
;; podajemy symbol z dookreśloną przestrzenią nazw
(resolve 'clojure.string/replace)
; => #'clojure.core/replace
Zarządzanie przestrzeniami
Dzięki funkcjom all-ns i find-ns możemy wyszukiwać przestrzenie nazw
i pobierać ich listy.
Pobieranie listy przestrzeni, all-ns
Funkcja all-ns nie przyjmuje żadnych argumentów, a zwraca sekwencję (obiekt typu
clojre.lang.IteratorSeq) zawierającą wszystkie zdefiniowane przestrzenie nazw
w postaci reprezentujących je obiektów.
Użycie:
(all-ns).
all-ns
(all-ns)
; => (#<Namespace reply.main> #<Namespace clojure.tools.nrepl.misc> … )
Wyszukiwanie przestrzeni, find-ns
Funkcja find-ns zwraca obiekt przestrzeni, której nazwa określona symbolem w formie
stałej została podana jako jej pierwszy argument. Jeżeli przestrzeń o podanej nazwie
nie istnieje, zwracana jest wartość nil.
Użycie:
(find-ns nazwa-przestrzeni).
find-ns
(find-ns 'user)
; => #<Namespace user>
Usuwanie przestrzeni, remove-ns
Przestrzenie nazw można nie tylko dodawać, ale też usuwać. Operacja ta jest możliwa
z użyciem funkcji remove-ns. Przyjmuje ona jeden argument, który jest nazwą
przestrzeni do usunięcia wyrażoną symbolem w formie stałej.
Funkcja zwraca wartość nil, gdy przestrzeń nie istnieje lub obiekt przestrzeni, gdy
dokonano usunięcia. Nie można jej użyć do pozbycia się przestrzeni nazw clojure.core.
Użycie:
(remove-ns nazwa-przestrzeni).
remove-ns
(remove-ns 'clojure.string)
; => nil
Zarządzanie odwzorowaniami
Powiązania symboli ze zmiennymi globalnymi lub obiektami Javy można dodawać do przestrzeni nazw, używając jednej z kilku przeznaczonych do tego celu funkcji.
Dodawanie odniesień do zmiennych, refer
Funkcja refer umożliwia dodawanie w bieżącej przestrzeni nazw odniesień do obiektów
typu Var umieszczonych w innych przestrzeniach. Jako pierwszy argument
przyjmuje ona nazwę źródłowej przestrzeni nazw w postaci formy stałej symbolu, a jako
kolejne, opcjonalne argumenty, filtry, które zostaną użyte, aby uszczegółowić
przeprowadzane operacje.
Funkcja zwraca nil, a w przypadku nieistniejącej przestrzeni nazw generowany jest
wyjątek.
Użycie:
(refer nazwa-przestrzeni & filtry).
W efekcie wywołania refer z podanej przestrzeni nazw zostaną pobrane wszystkie
symbole wskazujące na obiekty typu Var, a następnie w bieżącej przestrzeni
utworzone będą odniesienia o takich samych symbolicznych nazwach, chyba że użyto
odpowiednich filtrów.
W przypadku, gdy tworzone odwołanie ma taką samą symboliczną nazwę, jak już istniejące przyporządkowanie, zostanie ono nadpisane, a na standardowe wyjście diagnostyczne wysłane będzie stosowne ostrzeżenie.
W bieżącej przestrzeni nazw symbolom będą bezpośrednio przyporządkowane obiekty Var
rezydujące w źródłowej przestrzeni. Gdy w oryginalnej przestrzeni powiązanie zostanie
usunięte (np. z użyciem ns-unmap), bieżąca przestrzeń nadal będzie
zawierała przyporządkowanie symbolu do obiektu typu Var.
Możliwe do zastosowania filtry to:
:exclude sekwencja-symboli– symbole do pominięcia,:only sekwencja-symboli– symbole do wyłącznego przetworzenia,:rename mapa-symboli– symbole do przemianowania.
Filtry te powinny składać się z nazwy w formie słowa kluczowego, po której
następuje sekwencja symboli, określająca wartości filtra, którymi będą
symboliczne nazwy do uwzględnienia (:only) lub pominięcia (:exclude).
Sekwencjami mogą być dowolne kolekcje (np. wektory) wyposażone w sekwencyjny
interfejs dostępu. Jeżeli zażądano przemianowania (:rename), to zamiast sekwencji
należy podać mapę zawierającą pary przekształceń. W ten sposób do danej
zmiennej globalnej będzie można odwoływać się w bieżącej przestrzeni pod inną
symboliczną nazwą.
refer
1;; stwórz odniesienia do wszystkich Varów z clojure.string
2
3(refer 'clojure.string)
4; => nil
5
6;; stwórz odniesienie tylko do identyfikatora 'replace'
7
8(refer 'clojure.string :only '[replace])
9; => nil
10
11;; stwórz odniesienia do wszystkich Varów z clojure.string
12;; za wyjątkiem 'replace' i 'reverse'
13
14(refer 'clojure.string :exclude '[replace reverse])
15; => nil
16
17;; stwórz odniesienia do wszystkich Varów z clojure.string
18;; za wyjątkiem 'replace', a 'reverse' zamień na 'nazad'
19
20(refer 'clojure.string
21 :exclude '[replace]
22 :rename '{reverse nazad})
23; => nil
;; stwórz odniesienia do wszystkich Varów z clojure.string
(refer 'clojure.string)
; => nil
;; stwórz odniesienie tylko do identyfikatora 'replace'
(refer 'clojure.string :only '[replace])
; => nil
;; stwórz odniesienia do wszystkich Varów z clojure.string
;; za wyjątkiem 'replace' i 'reverse'
(refer 'clojure.string :exclude '[replace reverse])
; => nil
;; stwórz odniesienia do wszystkich Varów z clojure.string
;; za wyjątkiem 'replace', a 'reverse' zamień na 'nazad'
(refer 'clojure.string
:exclude '[replace]
:rename '{reverse nazad})
; => nil
Zobacz także:
Dodawanie odniesień Clojure, refer-clojure
Wariantem funkcji refer jest makro refer-clojure, które można traktować jak
lukier składniowy, ponieważ wywołuje refer z przekazywaną wartością pierwszego
argumentu ustawioną na 'clojure-core.
Z refer-clojure często skorzystamy, gdy będziemy chcieli zrezygnować
z automatycznego tworzenia odniesień do wszystkich funkcji i makr zdefiniowanych
w głównej bibliotece języka Clojure, a wybrać tylko te, z których w danym pliku
źródłowym korzystamy. Zazwyczaj będzie ono wtedy wywołane pośrednio, przez jedną
z klauzul makra ns.
Kiedy możemy tego potrzebować? Na przykład wtedy, gdy nasza biblioteka definiuje we
własnej przestrzeni funkcje bądź makra o takich samych nazwach, jak
w clojure.core. Unikamy wtedy ostrzeżeń o przesłanianiu istniejących
identyfikatorów.
Makro zwraca nil.
Użycie:
(refer-clojure & filtry).
W efekcie ewaluacji kodu produkowanego przez makro w bieżącej przestrzeni nazw
zostaną dodane odniesienia do obiektów typu Var pochodzących
z clojure.core. Kolejne, opcjonalne argumenty, mogą wyrażać filtry, które zostaną
użyte, aby uszczegółowić przeprowadzane operacje.
W przypadku, gdy tworzone odwołanie ma taką samą symboliczną nazwę, jak już istniejące w bieżącej przestrzeni przyporządkowanie, zostanie ono nadpisane, a na standardowe wyjście diagnostyczne wysłane będzie stosowne ostrzeżenie.
W bieżącej przestrzeni nazw symbolom będą bezpośrednio przyporządkowane obiekty Var
rezydujące w clojure.core. Gdy w oryginalnej przestrzeni powiązanie zostanie
usunięte (np. z użyciem ns-unmap), bieżąca przestrzeń nadal będzie
zawierała przyporządkowanie symbolu do obiektu typu Var.
Możliwe do zastosowania filtry to:
:exclude sekwencja-symboli– symbole do pominięcia,:only sekwencja-symboli– symbole do wyłącznego przetworzenia,:rename mapa-symboli– symbole do przemianowania.
Filtry te powinny składać się z nazwy w formie słowa kluczowego, po której
następuje sekwencja symboli, określająca wartości filtra, którymi będą
symboliczne nazwy do uwzględnienia (:only) lub pominięcia (:exclude).
Sekwencjami mogą być dowolne kolekcje (np. wektory) wyposażone w sekwencyjny
interfejs dostępu. Jeżeli zażądano przemianowania (:rename), to zamiast sekwencji
należy podać mapę zawierającą pary przekształceń. W ten sposób do danej
zmiennej globalnej będzie można odwoływać się w bieżącej przestrzeni pod inną
symboliczną nazwą.
refer-clojure
1;; usuń powiązania dla apply i format
2;; z bieżącej przestrzeni nazw
3
4(ns-unmap *ns* 'apply)
5(ns-unmap *ns* 'format)
6
7;; stwórz odniesienia do wszystkich Varów z clojure.core
8;; za wyjątkiem apply i format
9
10(refer-clojure :exclude '[apply format])
11; => nil
12
13;; brak ostrzeżenia przy definiowaniu apply
14;; w bieżącej przestrzeni nazw
15
16(defn apply [] "aplikacja")
;; usuń powiązania dla apply i format
;; z bieżącej przestrzeni nazw
(ns-unmap *ns* 'apply)
(ns-unmap *ns* 'format)
;; stwórz odniesienia do wszystkich Varów z clojure.core
;; za wyjątkiem apply i format
(refer-clojure :exclude '[apply format])
; => nil
;; brak ostrzeżenia przy definiowaniu apply
;; w bieżącej przestrzeni nazw
(defn apply [] "aplikacja")
Dodawanie odniesień do klas Javy, import
Makro import pozwala dodawać do przestrzeni nazw przyporządkowania symboli do
odniesień odwołujących się do klas Javy, które znajdują się w podanym pakiecie.
Przyjmowanymi argumentami mogą być pojedyncze symbole – znaczy to wtedy, że
zaimportowane mają być konkretne klasy umieszczone w pakietach. Argumentem może być
również lista symboli – w takim przypadku pierwszy z nich określa pakiet
(np. java.util), a kolejne są nazwami klas z tego pakietu (np. Date).
W efekcie działania makra do bieżącej przestrzeni zostaną dodane symboliczne nazwy takie same jak nazwy klas Javy, wraz z przyporządkowanymi im odniesieniami do tych klas.
Funkcja zwraca wartość obiektu ostatnio zaimportowanej klasy, a w przypadku nieistniejącego pakietu lub nazwy klasy zgłaszany jest wyjątek.
Użycie:
(import [& symbol…] & lista-symboli…).
Gdzie lista-symboli to:
(symbol-pakietu symbole-nazw-klas).
import
1;; importowanie pojedynczych klas
2
3(import java.util.Date)
4
5;; importowanie wybranych klas z pakietu
6
7(import '(java.util Date Dictionary))
8
9;; użycie obiektu
10
11(Date.)
12; => #inst "2015-04-02T11:35:43.980-00:00"
;; importowanie pojedynczych klas
(import java.util.Date)
;; importowanie wybranych klas z pakietu
(import '(java.util Date Dictionary))
;; użycie obiektu
(Date.)
; => #inst "2015-04-02T11:35:43.980-00:00"
Funkcja import może być również używana do importowania nowych typów danych
utworzonych w Clojure (np. z użyciem deftype czy defrecord).
Zobacz także:
Internalizowanie obiektów Var, intern
Funkcja intern służy do internalizowania obiektów typu Var i tworzenia w ten
sposób zmiennych globalnych. Przyjmuje ona dwa argumenty: nazwę
przestrzeni nazw wyrażoną symbolem w formie stałej lub obiekt przestrzeni i nazwę
zmiennej w postaci stałej symbolu.
Użycie intern sprawia, że w podanej przestrzeni nazw tworzone jest
przyporządkowanie podanego symbolu do obiektu typu Var. Jeżeli obiekt typu Var
już istnieje pod podaną nazwą, nie zostanie zastąpiony nowym.
W wersji trójargumentowej funkcja inicjuje obiekt podaną wartością, to znaczy ustawia
wewnątrz zmiennej globalnej referencję, która odnosi się do wskazanego obiektu
pamięciowego (tzw. powiązanie główne zmiennej globalnej). Jeżeli zmienna globalna już
istnieje, zostanie zaktualizowana jej referencja bez wytwarzania nowego obiektu
typu Var.
Funkcja zwraca obiekt typu Var identyfikowany symbolem.
Uwaga: Funkcja intern zastępuje obiektami typu Var istniejące już w przestrzeni
nazw odniesienia do klas Javy o takich samych nazwach, nawet jeżeli nie ustawiono
wartości początkowej.
Użycie:
(intern przestrzeń-nazw symboliczna-nazwa & wartość-początkowa).
intern
1(intern 'user 'zmienna) ; => #'user/zmienna
2(intern 'user 'zmienna 5) ; => #'user/zmienna
3user/zmienna ; => 5
4zmienna ; => 5
5(intern (find-ns 'user) 'a 10) ; => #'user/a
(intern 'user 'zmienna) ; => #'user/zmienna
(intern 'user 'zmienna 5) ; => #'user/zmienna
user/zmienna ; => 5
zmienna ; => 5
(intern (find-ns 'user) 'a 10) ; => #'user/a
Możemy sprawić, aby internalizowana zmienna globalna została potraktowana jako
prywatna, tzn. była widoczna tylko w przestrzeni nazw, do której ją
dodano. W praktyce będzie to oznaczało, że odwoływać się do takiej zmiennej z użyciem
jej identyfikatora będą mogły konstrukcje z obszarów programu, w których bieżąca
przestrzeń nazw jest ustawiona na taką samą, jak przestrzeń zdefiniowanej
zmiennej. Aby oznaczyć globalną zmienną jako prywatną, należy skorzystać
z tzw. metadanych symboli w odniesieniu do przekazywanego argumentu
nazwy. Konkretnie chodzi tu o metadaną określaną kluczem :private.
intern do tworzenia prywatnych powiązań
1(intern 'user '^:private zmienna) ; => #'user/zmienna
2(intern 'user '^{:private true} zmienna-2) ; => #'user/zmienna
3(intern 'user (with-meta 'zmienna-3 {:private true})) ; => #'user/zmienna
(intern 'user '^:private zmienna) ; => #'user/zmienna
(intern 'user '^{:private true} zmienna-2) ; => #'user/zmienna
(intern 'user (with-meta 'zmienna-3 {:private true})) ; => #'user/zmienna
Pełna lista metadanych, które są istotne podczas internalizowania obiektu typu Var,
jest podana w opisie formy specjalnej def.
Zmienne typu Var mogą być aktualizowane przez ponowne wywołanie funkcji
intern. Aktualizowanie polega na powiązaniu ich z nowymi wartościami. Jeżeli
zmienna już istnieje, to jej obiekt w przestrzeni nazw nie zostanie zastąpiony innym,
będzie po prostu zmienione jego wewnętrzne wskazanie na konkretną wartość.
1(intern 'user 'xx 5) ; utworzenie i powiązanie z wartością 5
2
3(pprint #'xx) ; wyświetlenie obiektu referencyjnego
4; >> #<Var@7a0ad359: 5>
5
6(intern 'user 'xx 7) ; powiązanie z wartością 7
7(pprint #'xx) ; wyświetlenie obiektu referencyjnego
8; >> #<Var@7a0ad359: 7>
(intern 'user 'xx 5) ; utworzenie i powiązanie z wartością 5
(pprint #'xx) ; wyświetlenie obiektu referencyjnego
; >> #<Var@7a0ad359: 5>
(intern 'user 'xx 7) ; powiązanie z wartością 7
(pprint #'xx) ; wyświetlenie obiektu referencyjnego
; >> #<Var@7a0ad359: 7>
Uwaga: Funkcja intern może być użyta do zmiany powiązania głównego, które jest
współdzielone między wątkami, nawet gdy znajdujemy się w konstrukcji izolującej
zmienną w wątku (np. w zasięgu dynamicznym).
Dodawanie obiektów Var, def
Forma specjalna def działa podobnie do intern, ale operuje na bieżącej
przestrzeni nazw i wymaga podania niezacytowanego symbolu jako pierwszego
argumentu. Symbol w tym kontekście nie będzie tworzył formy symbolowej ani formy
stałej, lecz formę powiązaniową.
Forma def przyjmuje jeden obligatoryjny argument (wspomniany symbol, którego nazwa
ma być skojarzona z tworzonym obiektem typu Var) i dwa argumenty opcjonalne:
tekstowy łańcuch dokumentujący i wartość początkową zmiennej globalnej (która będzie
użyta do aktualizacji, jeżeli zmienna już istnieje).
Jeżeli podano symbol z dookreśloną przestrzenią nazw, musi to być przestrzeń bieżąca
– w przeciwnym razie zostanie zgłoszony wyjątek. Z wyjątkiem będziemy też mieli do
czynienia, gdy użyjemy def do aktualizacji odwzorowania, które identyfikuje klasę
Javy lub jest odniesieniem do obiektu z innej przestrzeni nazw.
Funkcja zwraca obiekt typu Var identyfikowany symbolem, który jest tożsamy
z obiektem umieszczonym w przestrzeni nazw.
Użycie:
(def symbol łańcuch-dokumentujący? wartość-początkowa?).
def
1(def zmienna) ; => #'user/zmienna
2(def zmienna 5) ; => #'user/zmienna
3(def zmienna "dokumentacja" 5) ; => #'user/zmienna
4user/zmienna ; => 5
5zmienna ; => 5
6
7;; dostęp do dokumentacji – funkcja doc
8
9(doc zmienna)
10; >> user/zmienna
11; >> dokumentacja zmiennej
12; => nil
(def zmienna) ; => #'user/zmienna
(def zmienna 5) ; => #'user/zmienna
(def zmienna "dokumentacja" 5) ; => #'user/zmienna
user/zmienna ; => 5
zmienna ; => 5
;; dostęp do dokumentacji – funkcja doc
(doc zmienna)
; >> user/zmienna
; >> dokumentacja zmiennej
; => nil
W przypadku def również można dodać do symbolu metadaną, która wskaże,
że w przestrzeni nazw przyporządkowanie ma być prywatne, czyli widoczne wyłącznie
przez konstrukcje z tej samej przestrzeni.
Skojarzone z symbolem metadane zostaną skopiowane do obiektu typu Var podczas jego
tworzenia.
def do tworzenia globalnej zmiennej prywatnej
1(def ^:private zmienna) ; => #'user/zmienna
2(def ^{ :private true } zmienna 5) ; => #'user/zmienna
(def ^:private zmienna) ; => #'user/zmienna
(def ^{ :private true } zmienna 5) ; => #'user/zmienna
Poniżej znajduje się spis wszystkich metadanych, które mają znaczenie podczas
korzystania z def:
| Klucz | Typ | Znaczenie |
|---|---|---|
:private |
java.lang.Boolean |
Flaga logiczna, która wskazuje, że zmienna ma być prywatna |
:dynamic |
java.lang.Boolean |
Flaga logiczna, która wskazuje, że zmienna ma być dynamiczna |
:doc łańcuch |
java.lang.String |
Łańcuch tekstowy dokumentujący tożsamość zmiennej |
:tag obiekt |
Class lub Symbol |
Symbol stanowiący nazwę klasy lub obiektu typu Class, który
wskazuje na typ obiektu Javy znajdującego się w zmiennej (chyba, że jest to
funkcja – wtedy będzie to jej zwracana wartość) |
:test funkcja |
(implementujący IFn) |
Bezargumentowa funkcja używana do testów (obiekt zmiennej będzie
w niej osiągalny jako literał fn umieszczony w metadanych) |
Podczas tworzenia obiektu typu Var zostaną w nim automatycznie umieszczone
następujące metadane:
| Klucz | Typ | Znaczenie |
|---|---|---|
:file |
java.lang.String |
Nazwa pliku źródłowego |
:line |
java.lang.Integer |
Numer linii pliku źródłowego |
:name |
clojure.lang.Symbol |
Nazwa zmiennej |
:ns |
clojure.lang.Namespace |
Przestrzeń nazw |
:macro |
java.lang.Boolean |
Flaga oznaczająca, że obiekt odnosi się do makra |
:arglists |
PersistentVector$ChunkedSeq |
Sekwencja wektorowa z argumentami, jeżeli obiekt odnosi się do funkcji lub makra |
Zmienne globalne mogą być aktualizowane m.in. przez ponowne wywołanie funkcji
def. Polega to na powiązaniu referencji wewnątrz obiektu Var z nową
wartością. Jeżeli zmienna identyfikowana podanym symbolem już istnieje, jej obiekt
w przestrzeni nazw nie zostanie zastąpiony innym, ale zmienione będzie jego
odniesienie do konkretnej wartości (powiązanie główne).
Var
1(def xx 5) ; utworzenie i powiązanie z wartością 5
2(pprint #'xx) ; wyświetlenie obiektu
3; >> #<Var@4eee52c: 5>
4
5(def xx 7) ; powiązanie z wartością 7
6(pprint #'xx) ; wyświetlenie obiektu
7; >> #<Var@4eee52c: 7>
(def xx 5) ; utworzenie i powiązanie z wartością 5
(pprint #'xx) ; wyświetlenie obiektu
; >> #<Var@4eee52c: 5>
(def xx 7) ; powiązanie z wartością 7
(pprint #'xx) ; wyświetlenie obiektu
; >> #<Var@4eee52c: 7>
Uwaga: Forma specjalna def może być użyta do zmiany powiązania głównego, które
jest współdzielone między wątkami, nawet jeżeli znajdujemy się w konstrukcji
izolującej zmienną w wątku (np. w zasięgu dynamicznym).
Dodawanie jednokrotne Varów, defonce
Makro defonce pozwala utworzyć obiekt typu Var i umieścić go w bieżącej
lub określonej niezacytowanym symbolem przestrzeni nazw. Działa podobnie do
def, jednak nie dokonuje aktualizowania powiązania, gdy obiekt typu
Var już je ma.
Makro nie pozwala na ustawianie łańcuchów dokumentacyjnych, bowiem przyjmuje tylko dwa argumenty: niezacytowany symbol (mogący zawierać informację o przestrzeni nazw) i wyrażenie, którego wartość po przeliczeniu stanie się wartością powiązania głównego zmiennej.
Makro zwraca obiekt typu Var, jeżeli ustawiono powiązanie główne lub wartość nil,
jeżeli powiązanie już istniało.
Makro defonce przydaje się przy nazywaniu obiektów funkcyjnych i wszędzie tam,
gdzie trzeba odwoływać się do stałej wartości, która powinna być wynikiem pierwszego
wartościowania jakiegoś wyrażenia lub pierwszego pobrania danych z zewnątrz.
Uwaga: Nawet jeżeli powiązanie z wartością nie doszło do skutku, to ustawione będą metadane pochodzące z przekazanego symbolu i zastąpią poprzednie.
Użycie:
(defonce symbol wyrażenie).
defonce
1(defonce zmienna) ; => #'user/zmienna
2(defonce zmienna 5) ; => #'user/zmienna
3(defonce ^:flaszka zmienna 1000) ; => #'user/zmienna
4user/zmienna ; => 5
5zmienna ; => 5
6
7(meta #'zmienna)
8; => { :ns #<Namespace user>, :name zmienna,
9; => :flaszka true, :file "NO_SOURCE_PATH",
10; => :column 1, :line 1 }
(defonce zmienna) ; => #'user/zmienna
(defonce zmienna 5) ; => #'user/zmienna
(defonce ^:flaszka zmienna 1000) ; => #'user/zmienna
user/zmienna ; => 5
zmienna ; => 5
(meta #'zmienna)
; => { :ns #<Namespace user>, :name zmienna,
; => :flaszka true, :file "NO_SOURCE_PATH",
; => :column 1, :line 1 }
Usuwanie odwzorowań, ns-unmap
Dzięki funkcji ns-unmap możemy usuwać z przestrzeni nazw powiązania symboli
ze zmiennymi globalnymi lub klasami Javy. Przyjmuje ona dwa argumenty.
Pierwszy jest określeniem przestrzeni (z użyciem symbolu w formie stałej lub obiektu
przestrzeni), a drugi symbolicznie wyrażoną nazwą konkretnego przyporządkowania,
które ma być usunięte.
Funkcja zwraca wartość nil, a gdy podana przestrzeń nie istnieje,
zgłaszany jest wyjątek.
Użycie:
(ns-unmap przestrzeń-nazw symboliczna-nazwa).
ns-unmap
1;; tworzymy zmienną globalną x
2
3(def x 5)
4; => #'user/x
5
6;; sięgamy po jej wartość
7
8x
9; => 5
10
11;; dodatkowo tworzymy odwołanie do obiektu Var tej zmiennej
12
13(def y (var x))
14
15;; usuwamy odwzorowanie
16
17(ns-unmap 'user 'x)
18; => nil
19
20;; sprawdzamy, czy identyfikator x jest wciąż widoczny
21
22(resolve 'x)
23; => nil
24
25;; sprawdzamy, czy sam obiekt Var istnieje,
26;; choć nie jest już powiązany z symbolem x
27
28(deref y)
29; => 5
;; tworzymy zmienną globalną x
(def x 5)
; => #'user/x
;; sięgamy po jej wartość
x
; => 5
;; dodatkowo tworzymy odwołanie do obiektu Var tej zmiennej
(def y (var x))
;; usuwamy odwzorowanie
(ns-unmap 'user 'x)
; => nil
;; sprawdzamy, czy identyfikator x jest wciąż widoczny
(resolve 'x)
; => nil
;; sprawdzamy, czy sam obiekt Var istnieje,
;; choć nie jest już powiązany z symbolem x
(deref y)
; => 5
W powyższym przykładzie pokazaliśmy przy okazji, że gdy usuwane jest odwzorowanie
w przestrzeni nazw, sam obiekt klasy Var (lub inny) nie jest niszczony, lecz traci
nazwę.
Dodawanie aliasów, alias
Mechanizm aliasów pozwala odwoływać się do różnych przestrzeni nazw z użyciem alternatywnych identyfikatorów umieszczonych w bieżącej przestrzeni.
Funkcja alias pozwala dodawać do bieżącej przestrzeni alternatywne nazwy innych
przestrzeni nazw. Przyjmuje ona dwa argumenty: pierwszy powinien być symbolem
w formie stałej, a drugi obiektem przestrzeni nazw lub jej nazwą wyrażoną literalnym
symbolem. Pierwszy argument to nazwa aliasu, a drugi przestrzeń nazw, do której
odniesienie ma być wytworzone.
Funkcja zwraca wartość nil, a w przypadku podania nieistniejącej przestrzeni nazw
zgłaszany jest wyjątek.
Użycie:
(alias symboliczna-nazwa przestrzeń-nazw).
alias
(alias 'st 'clojure.string)
(st/reverse "abcdef")
; => "fedcba"
Zobacz także:
Usuwanie aliasów, unalias
Funkcja ns-unalias usuwa aliasy dodane z użyciem alias. Przyjmuje dwa
argumenty. Pierwszy powinien określać przestrzeń nazw z użyciem formy stałej symbolu
lub obiektu przestrzeni, a drugi powinien być nazwą aliasu wyrażoną symbolicznie.
Funkcja zawsze zwraca wartość nil, niezależnie od tego, czy dany alias istniał, lub
czy nie było możliwe jego usunięcie, ponieważ nie był w istocie aliasem. Gdy podana
przestrzeń nazw nie istnieje, zgłaszany jest wyjątek.
Użycie:
(ns-unalias przestrzeń-nazw symboliczna-nazwa).
ns-unalias
(ns-unalias 'user 'st)
; => nil
Odczytywanie zawartości
Odczyt nazwy, ns-name
Funkcja ns-name jako argument przyjmuje obiekt przestrzeni nazw (lub symbol
reprezentujący jej nazwę), a zwraca symbol określający nazwę przestrzeni. Jeżeli
przestrzeń nie istnieje, zgłaszany jest wyjątek.
Użycie:
(ns-name przestrzeń-nazw).
ns-name
(ns-name 'user) ; => user
(ns-name (find-ns 'user)) ; => user
Odczyt aliasów, ns-aliases
Funkcja ns-aliases przyjmuje jeden argument, którym powinien być symbol w formie
stałej określający nazwę przestrzeni nazw lub obiekt tej przestrzeni, a zwraca
mapę zawierającą zdefiniowane aliasy, czyli przyporządkowania obiektów
innych przestrzeni nazw do symbolicznych identyfikatorów. Jeżeli przestrzeń nie
istnieje, zgłoszony zostanie wyjątek.
Użycie:
(ns-aliases przestrzeń-nazw).
ns-aliases
1(ns-aliases 'clojure.core) ; => {jio #<Namespace clojure.java.io>}
2(alias 'stri 'clojure.string) ; => nil
3(ns-aliases 'user) ; => {stri #<Namespace clojure.string>}
(ns-aliases 'clojure.core) ; => {jio #<Namespace clojure.java.io>}
(alias 'stri 'clojure.string) ; => nil
(ns-aliases 'user) ; => {stri #<Namespace clojure.string>}
Odczyt odwzorowań Varów, ns-interns
Funkcja ns-interns przyjmuje jeden argument, którym powinien być symbol w formie
stałej określający nazwę przestrzeni nazw lub obiekt tej przestrzeni, a zwraca
mapę zawierającą przyporządkowania symbolicznych identyfikatorów
do zmiennych globalnych (obiektów typu Var). Jeżeli przestrzeń nie istnieje,
zgłoszony zostanie wyjątek.
Użycie:
(ns-interns przestrzeń-nazw).
ns-interns
1(ns-interns 'user)
2; => {apropos-better #'user/apropos-better, cdoc #'user/cdoc,
3; => find-name #'user/find-name, help #'user/help,
4; => clojuredocs #'user/clojuredocs}
(ns-interns 'user)
; => {apropos-better #'user/apropos-better, cdoc #'user/cdoc,
; => find-name #'user/find-name, help #'user/help,
; => clojuredocs #'user/clojuredocs}
Odczyt odniesień do Varów, ns-refers
Funkcja ns-refers przyjmuje jeden argument, którym powinien być symbol w formie
stałej określający nazwę przestrzeni nazw lub obiekt tej przestrzeni, a zwraca
mapę zawierającą przyporządkowania symbolicznych identyfikatorów do
obiektów typu Var, które zostały zaimportowane do bieżącej przestrzeni
(np. z użyciem fn-refer).
Użycie:
(ns-refers przestrzeń-nazw).
ns-refers
1(ns-refers 'user)
2; => {primitives-classnames #'clojure.core/primitives-classnames,
3; => +' #'clojure.core/+', …}
(ns-refers 'user)
; => {primitives-classnames #'clojure.core/primitives-classnames,
; => +' #'clojure.core/+', …}
Warto wiedzieć, że oryginalne powiązanie symbolu z Varem w innej przestrzeni nazw
może zostać usunięte (np. z użyciem funkcji ns-unmap). W takim
przypadku powiązanie odzwierciedlone w przestrzeni bieżącej nie zniknie, ponieważ
symbol będzie przyporządkowany bezpośrednio do obiektu typu Var, a nie do elementu
w wewnętrznej mapie innej przestrzeni. Minusem takiej sytuacji może być jednak pewna
niezgodność metadanych docelowego obiektu ze stanem faktycznym: zapisana w Var
metadana o kluczu :ns będzie wskazywała na oryginalną przestrzeń nazw, w której nie
znajdziemy już powiązania.
Odczyt odniesień do klas, ns-imports
Funkcja ns-imports przyjmuje jeden argument, którym powinien być symbol w formie
stałej określający nazwę przestrzeni nazw lub obiekt tej przestrzeni, a zwraca
mapę zawierającą przyporządkowania symbolicznych identyfikatorów do odniesień
wskazujących klasy Javy. Jeżeli przestrzeń nie istnieje, zgłoszony zostanie
wyjątek.
Użycie:
(ns-imports przestrzeń-nazw).
ns-imports
(ns-imports 'user)
; => {Enum java.lang.Enum, InternalError java.lang.InternalError, …}
Odczyt wszystkich odwzorowań, ns-map
Funkcja ns-map przyjmuje jeden argument, którym powinien być symbol w formie stałej
określający nazwę przestrzeni nazw lub obiekt tej przestrzeni, a zwraca mapę
zawierającą wszystkie przyporządkowania symbolicznych identyfikatorów do
obiektów (zmiennych referencyjnych typu Var i klas Javy). Jeżeli przestrzeń nie
istnieje, wygenerowany zostanie wyjątek.
Użycie:
(ns-map przestrzeń-nazw).
ns-map
(ns-map 'user)
; => {primitives-classnames #'clojure.core/primitives-classnames, … }
Odczyt publicznych, ns-publics
Funkcja ns-publics przyjmuje jeden argument, którym powinien być symbol
w formie stałej określający nazwę przestrzeni nazw lub obiekt tej przestrzeni,
a zwraca mapę zawierającą publiczne przyporządkowania symbolicznych
identyfikatorów do obiektów. Jeżeli przestrzeń nie istnieje, wygenerowany
zostanie wyjątek.
Użycie:
(ns-publics przestrzeń-nazw).
ns-publics
1(ns-publics 'user)
2; => {apropos-better #'user/apropos-better, cdoc #'user/cdoc,
3; => find-name #'user/find-name, help #'user/help, clojuredocs #'user/clojuredocs}
(ns-publics 'user)
; => {apropos-better #'user/apropos-better, cdoc #'user/cdoc,
; => find-name #'user/find-name, help #'user/help, clojuredocs #'user/clojuredocs}
Obsługa bibliotek
Biblioteka (ang. library), a dokładniej biblioteka oprogramowania (ang. software library), zwana też po polsku biblioteką programistyczną, to zbiór umieszczonych w plikach zasobów, które mogą być wykorzystywane przez oprogramowanie, aby wzbogacać dostępne funkcje. W bibliotece mogą znajdować się dane, podprogramy (np. makra czy funkcje), a nawet definicje nowych typów danych. Dzięki bibliotekom możliwe jest ponowne korzystanie z już zaimplementowanych metod rozwiązywania problemów.
W zależności od języka programowania biblioteki programistyczne mogą składać się wyłącznie z kodu źródłowego lub występować w wersjach skompilowanych z dodatkiem w postaci plików źródłowych zawierających deklaracje, dzięki którym kompilator potrafi połączyć wywołania podprogramów z odpowiednimi implementacjami w języku maszynowym bądź kodzie bajtowym.
W Clojure będziemy mieli najczęściej do czynienia z bibliotekami kodu źródłowego
w archiwach Javy (JAR-ach) zawierających wyłącznie kod napisany
w Clojure. W niektórych, rzadkich przypadkach możemy mieć do czynienia
z bibliotekami, które zamiast kodu źródłowego w Clojure będą zawierały skompilowane
do kodu bajtowego pliki .class.
Wczytywanie bibliotek
Ładowanie bibliotek programistycznych, a następnie umieszczanie potrzebnych odwołań
w bieżącej przestrzeni nazw wymaga skorzystania z kilku przedstawionych wcześniej
funkcji i makr (np. refer czy import). Na szczęście
programiści nie muszą zbytnio się trudzić, ponieważ istnieją makra, które pozwalają
w zwięzły sposób wyrazić, co ma być załadowane i jakie dodatkowe czynności należy
przeprowadzić na przestrzeniach nazw.
W Clojure pliki danej biblioteki powinny znajdować się w katalogu umieszczonym w ścieżce przeszukiwania klas (ang. classpath), zaś zgodnie z konwencją jej nazwa będzie wyrażana jako symbol w formie stałej (podczas przekazywania jej do różnych makr czy funkcji).
Wczytywanie samodzielne, load
Za ładowanie bibliotek odpowiada funkcja load. Przyjmuje ona zero lub więcej
argumentów, które powinny być ścieżkami systemu plikowego wyrażonymi łańcuchami
znakowymi.
Użycie:
(load & ścieżka…).
Dla każdej podanej względnej ścieżki (nie rozpoczynającej się separatorem nazw ścieżkowych) plik biblioteki będzie poszukiwany w katalogu głównym (ang. root directory) bieżącej przestrzeni nazw. Katalog główny jest uzyskiwany przez:
- pobranie nazwy bieżącej przestrzeni nazw;
- dodatnie z przodu znaku ukośnika (
/); - zamianie wszystkich dywizów (
-) na znaki podkreślenia (_); - zamianie wszystkich kropek (
.) na znaki ukośnika (/); - wydzielenie fragmentu od początku do ostatniego wystąpienia ukośnika;
- dodanie na końcu znaku ukośnika;
- dodanie na końcu ścieżki podanej jako argument.
Dla każdej ścieżki bezwzględnej (rozpoczynającej się separatorem nazw ścieżkowych) dokonane zostanie przeszukanie wszystkich lokalizacji, które są złożeniami kolejnych ścieżek umieszczonych w ścieżce przeszukiwania klas (ang. classpath).
Przykłady katalogów głównych w zależności od nazwy przestrzeni i podanej ścieżki:
-
bieżąca przestrzeń nazw
user:(load "test"):/test,(load "raz/dwa"):/raz/dwa,
-
bieżąca przestrzeń nazw
clojure.core:(load "test"):/clojure/test,(load "raz/dwa"):/clojure/raz/dwa,(load "string"):/clojure/string.
Niezależnie od tego, czy podano ścieżkę względną czy bezwzględną, ostatni element
podanej ścieżki będzie potraktowany jak nazwa pliku do wczytania i zostanie do niego
dołączony łańcuch tekstowy z rozszerzeniem .clj.
Możemy przekonać się, w jaki sposób tworzone są nazwy, ustawiając zmienną dynamiczną
*clojure.core/loading-verbosely* na wartość różną od false i różną od nil
w zasięgu dynamicznym makra binding.
load
1;; ładowanie pliku projektu
2;; src/projekt/core.clj
3
4(load "projekt/core")
5; => nil
6
7;; ładowanie pliku głównego
8;; biblioteki clojure.string
9
10(load "/clojure/string")
11; => nil
;; ładowanie pliku projektu
;; src/projekt/core.clj
(load "projekt/core")
; => nil
;; ładowanie pliku głównego
;; biblioteki clojure.string
(load "/clojure/string")
; => nil
Makro require
Makro require ładuje zewnętrzne biblioteki programistyczne. Każdy podawany argument
powinien być jedną z kilku klauzul:
- specyfikacji biblioteki (ang. library spec),
- listy przedrostkowej (ang. prefix list),
- flagi modyfikatora (ang. modifier flag).
Specyfikacja biblioteki to albo symbolicznie wyrażona nazwa biblioteki, albo wektor zawierający nazwę i dodatkowe parametry. Nazwy tych parametrów powinny być wyrażone słowami kluczowymi i zgrupowane w sekwencyjnej kolekcji. Dzięki parametrom specyfikacji biblioteki możemy zdecydować co stanie się zaraz po załadowaniu jej do pamięci.
Możliwe parametry to:
-
:as symboliczna-nazwa– korzysta z funkcjialiasi wytwarza odniesienie do ładowanej biblioteki pod podaną nazwą w bieżącej przestrzeni nazw; -
:refer (symboliczne-nazwy)– korzysta z funkcjireferi dla sekwencji symbolicznie wyrażonych nazw wytwarza odniesienia w bieżącej przestrzeni nazw (podanie klucza:alloznacza żądanie wytworzenia odniesień do wszystkich publicznych zmiennych globalnych);
Lista przedrostkowa umożliwia załadowanie bibliotek, których nazwy zaczynają się tak samo. Oszczędza to klawiaturę i nasze palce. Zamiast podanego, wspólnego przedrostka tworzy się listę specyfikacji bibliotek. Istotnym warunkiem jest to, że nazwy z tej listy nie mogą już zawierać kropek, tzn. muszą być ostatnimi elementami ścieżki (i nazwy).
Flagi modyfikatorów pozwalają wpływać na zachowanie makra. Są to słowa kluczowe:
-
:reload– wymusza ponowne wczytanie bibliotek do pamięci, nawet jeżeli już zostały wczytane; -
:reload-all– działa jak:reload, ale wpływa na wszystkie biblioteki zależne, ładowane przez wczytywaną (jeżeli jest w nich czyniony użytek zuselubrequire); -
:verbose– sprawia, że wypisane zostaną informacje diagnostyczne dotyczące ładowania i tworzenia odniesień.
Makro działa w ten sposób, że dla każdej wczytywanej biblioteki stwarzana jest przestrzeń nazw i odpowiedni pakiet Javy – ich nazwy są tworzone na bazie podanej nazwy symbolicznej. Załadowanie biblioteki jest w istocie wczytaniem jej pliku głównego (ang. root file), zlokalizowanego w katalogu głównym biblioteki. Nazwa pliku głównego jest tworzona według następującego schematu:
- kropki są zamieniane na separatory nazw ścieżkowych (np.
a.bnaa/b); - ostatnia część nazwy uznawana jest za nazwę pliku (np.
b.clj); - pozostała część nazwy uznawana jest za nazwę katalogu głównego (np.
a); - względna ścieżka wraz z nazwą pliku jest dołączana do kolejnych ścieżek przeszukiwania klas, aż zostanie odnaleziony główny plik biblioteki.
W głównym pliku powinna być zdefiniowana przestrzeń nazw całej biblioteki.
Jeżeli biblioteka już została wcześniej wczytana do pamięci, to nie jest wykonywane jej ponowne ładowanie.
Użycie:
(require & specyfikacja… & lista-przedrostkowa… & flaga…).
require
1;; wczyta bibliotekę i utworzy przestrzeń nazw clojure.string
2
3(require 'clojure.string)
4; => nil
5
6;; możemy podać kilka bibliotek
7
8(require 'clojure.string 'clojure.test 'clojure.set)
9
10;; możemy podać kilka bibliotek o wspólnym przedrostku
11
12(require '[clojure string test set])
13
14;; wczyta bibliotekę i utworzy przestrzeń nazw clojure.string
15;; nawet, jeżeli już była wczytana
16
17(require 'clojure.string :reload :verbose)
18; => (clojure.core/load "/clojure/string")
19; => nil
20
21;; wczyta bibliotekę, jeżeli jeszcze nie była wczytana
22;; i utworzy alias w bieżącej przestrzeni nazw, aby
23;; przestrzeń clojure.string była widoczna jako st
24
25(require '[clojure.string :as st] :verbose)
26; => (clojure.core/in-ns 'user)
27; => (clojure.core/alias 'st 'clojure.string)
28; => nil
;; wczyta bibliotekę i utworzy przestrzeń nazw clojure.string
(require 'clojure.string)
; => nil
;; możemy podać kilka bibliotek
(require 'clojure.string 'clojure.test 'clojure.set)
;; możemy podać kilka bibliotek o wspólnym przedrostku
(require '[clojure string test set])
;; wczyta bibliotekę i utworzy przestrzeń nazw clojure.string
;; nawet, jeżeli już była wczytana
(require 'clojure.string :reload :verbose)
; => (clojure.core/load "/clojure/string")
; => nil
;; wczyta bibliotekę, jeżeli jeszcze nie była wczytana
;; i utworzy alias w bieżącej przestrzeni nazw, aby
;; przestrzeń clojure.string była widoczna jako st
(require '[clojure.string :as st] :verbose)
; => (clojure.core/in-ns 'user)
; => (clojure.core/alias 'st 'clojure.string)
; => nil
Makro use
Makro use działa tak samo jak require i w ten sam sposób się je
wywołuje, ale do bieżącej przestrzeni nazw automatycznie dodawane są odniesienia do
każdej zmiennej globalnej z ładowanej biblioteki, z wykorzystaniem funkcji
refer.
Makro use może przyjmować dodatkowe parametry w specyfikacji bibliotek:
:exclude sekwencja-symboli– symbole do pominięcia,:only sekwencja-symboli– symbole do wyłącznego przetworzenia,:rename mapa-symboli– symbole do przemianowania.
Użycie:
(use & specyfikacja… & lista-przedrostkowa… & flaga…).
Od wydania 1.4 języka Clojure zaleca się zamiast z use korzystać z makra
require lub ns z odpowiednimi parametrami.
Makro ns
Makro ns zostało stworzone, aby nie trzeba było wywoływać innych makr i funkcji
związanych z obsługą przestrzeni nazw, lecz zgrupować wszystkie ważne czynności
w jednym miejscu (np. w nagłówkowej części pliku z kodem źródłowym).
Makro pozwala określić bieżącą przestrzeń nazw (utworzyć, jeżeli jeszcze nie istnieje i przełączyć się na nią), a następnie dokonywać wczytywania potrzebnych plików z kodem źródłowym, importowania wszystkich lub wybranych odwzorowań i generowania pseudokodu dla podanych klas.
Makro przyjmuje nazwę przestrzeni, która będzie ustawiona jako bieżąca, a także opcjonalny zestaw tzw. klauzul referencyjnych, które mogą zawierać polecenia wykonania dodatkowych operacji. Klauzule powinny być zgrupowane w listowym S-wyrażeniu zawierającym słowa kluczowe będące ich nazwami. Argumenty podawane po kluczach nie muszą być cytowane – zostaną po przeliczeniu przekazane do wywoływanych funkcji lub makr.
Opcjonalnie można po nazwie przestrzeni podać łańcuch dokumentujący (np. opisujący plik źródłowy), a także mapę atrybutów.
Użycie:
(ns nazwa-przestrzeni łańcuch-dokumentujący? mapa-atrybutów? & klauzula…).
Klauzule referencyjne:
(:require …)– wywołujerequire,(:use …)– wywołujeuse,(:import …)– wywołujeimport,(:load …)– wywołujeload,(:gen-class …)– wywołujegen-class,(:refer-clojure …)– wywołujerefer-clojure.
W przypadku gen-class domyślnie przekazywanymi do wywołania argumentami są:
:name nazwa-przestrzeni,:impl-ns nazwa-przestrzeni,:main true.
Jeżeli nie zachodzi proces kompilacji AOT, klauzula :gen-class jest ignorowana.
Jeżeli nie użyto tej klauzuli, a kompilacja się odbywa, wytworzony będzie wyłącznie
kod dla nazwa-przestrzeni__init.class.
ns
1(ns randomseed.pl.przykłady
2 (:refer-clojure :exclude [printf])
3 (:require [clojure.set :as set ]
4 [clojure.string :as string ]
5 [clojure.repl :refer [doc dir] ]
6 [randomseed.pl.zasoby.plikowe :as pliki ])
7 (:use [randomseed.pl.podręczne :only [funkcja inna]])
8 (:import [java.util Date Random ]))
(ns randomseed.pl.przykłady
(:refer-clojure :exclude [printf])
(:require [clojure.set :as set ]
[clojure.string :as string ]
[clojure.repl :refer [doc dir] ]
[randomseed.pl.zasoby.plikowe :as pliki ])
(:use [randomseed.pl.podręczne :only [funkcja inna]])
(:import [java.util Date Random ]))
W powyższym przykładzie widzimy, że tworzona jest przestrzeń nazw
randomseed.pl.przykłady, a zaraz potem ładowane są odniesienia do zmiennych
globalnych ze standardowej biblioteki języka, ale z wyłączeniem obiektu oznaczonego
symbolem printf.
Następnie w przestrzeni randomseed.pl.przykłady wytwarzane są aliasy dla
przestrzeni nazw clojure.set, clojure.string, randomseed.pl.zasoby.plikowe
w celu ich łatwiejszego specyfikowania. W tej samej sekcji wytwarzane są również
odwołania do zmiennych globalnych z przestrzeni clojure.repl (m.in. dla doc
i dir), aby można było je wywoływać bez określania przestrzeni.
Klauzula :use działa podobnie jak :require z parametrem :refer, tzn. w podanej
przestrzeni (tu randomseed.pl.podręczne) lokalizowane są obiekty (tu o nazwach
funkcja i inna) i w obsługiwanej przez makro przestrzeni (tu
randomseed.pl.przykłady) wytwarzane są do nich odniesienia. Zaleca się korzystanie
z :require (z parametrem :refer) zamiast z :use.
Ostatnia klauzula (:import) wytwarza odniesienia do klas Javy (Date i Random)
z pakietu java.util.
Obsługa powiązań
Dzięki powiązaniom możemy w Clojure identyfikować obiekty umieszczone w pamięci. Identyfikacja ta będzie polegała na:
- nadawaniu wartościom nazw z użyciem form powiązaniowych symboli,
- tworzeniu odniesień do wartości z użyciem tzw. typów referencyjnych,
- odczytywaniu wartości powiązań z użyciem:
- form symbolowych (w przypadku identyfikatorów);
- form dereferenyjnych (w przypadku typów referencyjnych).
Odczytywanie wartości powiązań to zadanie dla mechanizmów języka (wystarczy w kodzie źródłowym użyć niezacytowanego symbolu), a w przypadku typów referencyjnych zadanie dla programisty, w którym bardzo pomagają gotowe funkcje i makra czytnika. Poniżej skupimy się więc na wytwarzaniu powiązań w zależności od ich rodzajów i używanych w tym celu konstrukcji.
W przypadku form powiązaniowych mamy do czynienia z powiązaniami symbolicznych identyfikatorów z wartościami. Ich wartości nie można aktualizować, lecz możliwe jest ich przesłanianie przez powiązanie symbolu o podanej nazwie z inną wartością w pewnym kontekście (np. leksykalnym bądź dynamicznym).
W przypadku typów referencyjnych możemy dokonywać aktualizacji wartości bieżących, do których instancje tych typów się odnoszą, korzystając z odpowiednich funkcji. W ten sposób możemy wytwarzać stałe tożsamości, które będą odnosiły się do zmiennych stanów.
Rodzaje powiązań
Technicznie rzecz ujmując, w Clojure możemy mieć do czynienia z trzema głównymi rodzajami powiązań:
- symboli z wartościami,
- obiektów referencyjnych z wartościami,
- zmiennych dynamicznych z wartościami.
Zmienne dynamiczne są obsługiwane przez jeden z typów referencyjnych (Var) – ten
sam, który służy do obsługi zmiennych globalnych – jednak wyróżniamy je z osobna,
ponieważ cechuje je tzw. zasięg dynamiczny.
Powiązania symboli
Powiązania symboli służą do identyfikowania wartości lub obiektów referencyjnych w pewnych kontekstach. Możemy wyróżnić powiązania symboli:
-
w przestrzeniach nazw (ang. namespaces):
-
w powiązaniach leksykalnych (ang. lexical bindings):
- z lokalnymi wartościami (formy
let,loopi podobne); - z lokalnymi obiektami Var (forma
with-local-vars); - z argumentami funkcji w ich definicjach
(tzw. powiązania parametryczne – formyfn,defn);
- z lokalnymi wartościami (formy
a dodatkowo:
- w abstrakcyjnych powiązaniach strukturalnych (ang. structural bindings):
Poprawne semantycznie powiązania symboli w pewnych kontekstach będziemy też nazywali formami powiązaniowymi symboli.
Powiązania strukturalne
Powiązania strukturalne (ang. structural bindings) to powiązania leksykalne lub parametryczne, w których dochodzi do dekompozycji struktury asocjacyjnej (np. mapy) lub sekwencyjnej (np. wektora), aby za jednym razem powiązać wiele symboli z wartościami.
Dekompozycję, która będzie omówiona dalej, możemy wyobrazić sobie jako sposób wytwarzania powiązań z użyciem dwóch podobnych pod względem aranżacji struktur. Z lewej strony umieścimy strukturę zawierającą niezacytowane symbole, a z prawej izomorficzną do niej strukturę z wartościami inicjującymi. Symbole umieszczone w lewej strukturze zostaną powiązane z wartościami z prawej struktury zależnie od pozycji (w przypadku kolekcji sekwencyjnych, np. wektorów) bądź kluczy (w przypadku map).
Powiązania obiektów referencyjnych
Powiązania obiektów typu referencyjnego służą do śledzenia zmieniających się, współdzielonych stanów wyrażanych różnymi wartościami na przestrzeni czasu. Miejscami, w których przechowywane są informacje o powiązaniach są obiekty referencyjne, np.:
- zmienne globalne, lokalne
i dynamiczne (typ
Var), - Atomy (typ
Atom), - Agenty (typ
Agent), - Refy (typ
Ref), - Future’y (typ
Future), - Promise’y (typ
Promise), - Delay’e (typ
Delay), - Volatile’e (typ
Volatile).
Powiązania dynamiczne
Powiązania dynamiczne (ang. dynamic bindings) służą do tymczasowego
przesłaniania wartości zmiennych globalnych,
którym ustawiono flagę :dynamic w metadanych. Zmienne takie nazywamy wtedy
zmiennymi dynamicznymi. Od zwykłych zmiennych globalnych
różnią się sposobem inicjowania obiektu typu Var, a skorzystanie z dynamicznego
powiązania realizowane jest z użyciem formy powiązaniowej binding
i konstrukcji, które z niej korzystają.
Zasięgi powiązań
Zasięg powiązania to obszar programu, w którym dane powiązanie może być użyte.
Poza zasięgiem powiązania możemy też mówić o widoczności identyfikowanej wartości, czyli o obszarze, w którym można się do niej odwoływać. Widoczność wartości zależy od zasięgu powiązania, ale można też dodatkowo nią sterować, korzystając z przestrzeni nazw.
Widoczność może być mniejsza niż zasięg, jeżeli w danym kontekście ten sam symbol jest używany do oznaczenia więcej niż jednego powiązania. Mówimy wtedy o przesłanianiu.
W Clojure możemy mieć do czynienia z kilkoma rodzajami zasięgów: nieograniczonym, leksykalnym i dynamicznym.
Zasięg nieograniczony
W przypadku symbolicznie identyfikowanych zmiennych globalnych bądź klas Javy, będziemy mówić o zasięgu nieograniczonym (ang. indefinite scope), to znaczy o potencjalnej możliwości odwołania się do wskazywanych obiektów z dowolnego miejsca w programie.
Dzięki zasięgowi tego rodzaju jesteśmy w stanie wyrażać w programach globalne, współdzielone stany, które identyfikowane będą stałymi nazwami. Wartości mogą zmieniać się na przestrzeni czasu, lecz identyfikujące je tożsamości pozostaną stałe w całym programie.
Przykładem powszechnego wykorzystywania nieograniczonego zasięgu są nazwy
funkcji. Symboliczne identyfikatory są w przestrzeniach nazw powiązane
z obiektami referencyjnymi typu Var, które z kolei zawierają odniesienia
do obiektów typu funkcyjnego. Właśnie dzięki przestrzeniom nazw możliwe jest
sterowanie widocznością w tym zasięgu.
1(ns nasza) ; przełączenie przestrzeni nazw
2(def x 5) ; zmienna globalna x (powiązanie główne z wartością 5)
3(defn funk [] x) ; funkcja, która zwraca wartość zmiennej globalnej x
4(funk) ; wywołanie funkcji
5; => 5 ; rezultat wywołania
6
7(ns inna) ; przełączenie przestrzeni nazw
8(funk) ; próba wywołania funkcji
9; >> Unable to resolve symbol: funk in this context
10
11(nasza/funk) ; wywołanie funkcji symbolem z dookreśloną przestrzenią
12; => 5
(ns nasza) ; przełączenie przestrzeni nazw
(def x 5) ; zmienna globalna x (powiązanie główne z wartością 5)
(defn funk [] x) ; funkcja, która zwraca wartość zmiennej globalnej x
(funk) ; wywołanie funkcji
; => 5 ; rezultat wywołania
(ns inna) ; przełączenie przestrzeni nazw
(funk) ; próba wywołania funkcji
; >> Unable to resolve symbol: funk in this context
(nasza/funk) ; wywołanie funkcji symbolem z dookreśloną przestrzenią
; => 5
Zwróćmy uwagę, że po przełączeniu bieżącej przestrzeni nazw na przestrzeń inna
utraciliśmy widoczność wartości powiązanej ze zmienną globalną funk nazywającą
funkcję. Powiązanie nie zniknęło, dlatego korzystając
z formy symbolowej
z dookreśloną przestrzenią możemy z niego skorzystać.
Zasięg leksykalny
Z zasięgiem leksykalnym (ang. lexical scope) mamy do czynienia w przypadku powiązań leksykalnych (ang. lexical bindings). Możliwość korzystania z powiązań objętych tym zasięgiem zależy od umiejscowienia identyfikujących je symboli w kodzie źródłowym.
Zasięg leksykalny jest wykorzystywany w wielu językach programowania. Można mówić wtedy np. o lokalnym zasięgu leksykalnym (w obrębie ciała funkcji czy pewnego bloku kodu).
W Clojure zasięg leksykalny:
- tworzymy wprost z użyciem formy specjalnej
letlub podobnych; - tworzony jest automatycznie dla parametrów funkcji i makr.
Forma let i wektor powiązań
Korzystając z formy specjalnej let, możemy tworzyć powiązania leksykalne,
których zasięg będzie ograniczony do S-wyrażeń podanych jako jej argumenty.
Forma let jest bardzo często używana w Clojure i w innych dialektach języka
Lisp. Można powiedzieć, że obok form tworzących funkcje czy listy jest jedną
z fundamentalnych konstrukcji języka. Dzięki niej możemy pisać czytelny, deklaratywny
kod i nadawać wartościom symboliczne etykiety w wybranych obszarach programu.
Użycie:
(let wektor-powiązań & wyrażenie…),
gdzie wektor-powiązań to:
[forma-powiązaniowa wyrażenie-inicjujące …].
Pierwszym argumentem, jaki należy przekazać konstrukcji let, jest wektor
powiązań (ang. binding vector). Jest to
wektorowe S-wyrażenie, które powinno składać się
z tzw. par powiązaniowych (ang. binding pairs). Pierwsze elementy tych
par powinny być formami powiązaniowymi, a drugie tzw. wyrażeniami
inicjującymi (ang. initialization expressions), które zostaną
przeliczone do wartości stałych.
Formy powiązaniowe w wektorze powiązań formy let możemy wyrażać z użyciem:
-
pojedynczych symboli,
np.aczybdla wektora[a 5 b 10]; -
wektorowych wyrażeń powiązaniowych,
np.[a b]dla wektora[[a b] [5 10]]; -
map powiązaniowych,
np.{a :a b :b}dla wektora[{a :a b :b} {:a 5 :b 10}].
Symbole powinny wyrażać formy powiązaniowe, a więc występować w postaci niezacytowanej, natomiast mapy bądź wektory mają zastosowanie w przypadku tzw. dekompozycji (zwanej też destrukturyzacją), która omówiona będzie później i pozwala na tworzenie abstrakcyjnych powiązań strukturalnych. Znajdują one zastosowanie wtedy, gdy zachodzi potrzeba powiązania symboli z wartościami konkretnych elementów pochodzących z wieloelementowych struktur.
let
1(let [a 1 ; powiązanie symbolu a z wartością 1
2 b (inc a) ; powiązanie symbolu b z wartością a+1
3 c 3] ; powiązanie symbolu c z wartością 3
4 (+ a b c)) ; powiązania widoczne tylko w wyrażeniu let
5; => 6
(let [a 1 ; powiązanie symbolu a z wartością 1
b (inc a) ; powiązanie symbolu b z wartością a+1
c 3] ; powiązanie symbolu c z wartością 3
(+ a b c)) ; powiązania widoczne tylko w wyrażeniu let
; => 6
Przypisane do form powiązaniowych wartości mogą być reprezentowane dowolnymi S-wyrażeniami, które staną się poprawnymi formami. Nazywamy je w tym kontekście wyrażeniami inicjującymi. W wyrażeniach inicjujących możemy odwoływać się do symboli, które zostały powiązane z wartościami na wcześniejszych pozycjach wektora powiązaniowego.
Kolejne, opcjonalne argumenty let to S-wyrażenia do przeliczenia, w których
można korzystać z powiązanych wcześniej symboli. Gdy dany symbol zostanie podany,
jego forma symbolowa zostanie przeliczona do wartości.
Warto zaznaczyć, że w przypadku let nie mamy do czynienia z obiektami typu Var,
lecz z lokalnymi powiązaniami służącymi do identyfikacji przypisanych
wartości. Powiązania symboli z wartościami utworzone w wektorze powiązań
przechowywane są na specjalnym lokalnym stosie powiązaniowym (ang. local binding
stack), natomiast nowe wartości powstające w rezultacie obliczania wyrażeń
inicjujących zajmują przestrzeń sterty (ang. heap) programu.
Możemy przesłaniać wartości powiązań leksykalnych tworząc nowe, które bazują na tych samych symbolicznych nazwach:
1(let [a 1 ; powiązanie symbolu a z wartością 1
2 b (inc a) ; powiązanie symbolu b z wartością powiązaną z a + 1
3 a b] ; powiązanie symbolu a z wartością powiązaną z b
4 a)
5; => 2
(let [a 1 ; powiązanie symbolu a z wartością 1
b (inc a) ; powiązanie symbolu b z wartością powiązaną z a + 1
a b] ; powiązanie symbolu a z wartością powiązaną z b
a)
; => 2
Forma let ewaluowana jest do wartości ostatnio obliczonego S-wyrażenia lub wartości
nil, jeżeli żadnego wyrażenia nie podano.
Leksykalny zasięg powiązań utworzonych w wektorze powiązań formy let jest
ograniczony do wyrażeń inicjujących jej wektora i S-wyrażeń podanych jako jej
argumenty. Zasięg każdego powiązania w wektorze rozpoczyna się od miejsca jego
utworzenia – w wyrażeniach inicjujących wektora możemy korzystać z powiązań
powstałych na wcześniejszych pozycjach.
Powiązanie warunkowe, if-let
Makro if-let działa podobnie jak forma specjalna let, czyniąc wewnętrznie
użytek z formy if. Umożliwia tworzenie jednego powiązania leksykalnego
widocznego w S-wyrażeniach, które będą wartościowane w zależności od tego, czy
pochodząca z wyrażenia inicjującego wartość będzie reprezentowała logiczną prawdę czy
fałsz.
Pierwszym argumentem makra if-let jest wektor powiązań, drugim powinno być
S-wyrażenie, które zostanie przeliczone, jeżeli wartość wyrażenia inicjującego
z wektora będzie prawdziwa (nie będzie równa false ani nil). Po nim może pojawić
się opcjonalny trzeci argument, który zostanie przeliczony, jeżeli wartość drugiego
okaże się fałszywa (równa false lub nil). Warto pamiętać, że w wyrażeniu tym nie
można korzystać z powiązania, ponieważ nie zostanie ono utworzone.
Wartością zwracaną jest wartość ostatnio przeliczanego wyrażenia lub nil, jeżeli
żadne wyrażenie nie było wartościowane (ponieważ np. nie był spełniony warunek
prawdy, a nie podano dodatkowego wyrażenia do przeliczenia).
Użycie:
(if-let wektor-powiązań wyrażenie-prawda wyrażenie-fałsz?)
if-let
1(if-let [a 1] a) ; => 1
2(if-let [a 0] a) ; => 0
3(if-let [a false] a) ; => nil
4(if-let [a nil] a) ; => nil
5(if-let [a nil] a "brak") ; => "brak"
(if-let [a 1] a) ; => 1
(if-let [a 0] a) ; => 0
(if-let [a false] a) ; => nil
(if-let [a nil] a) ; => nil
(if-let [a nil] a "brak") ; => "brak"
Leksykalny zasięg powiązania utworzonego w wektorze powiązań formy if-let jest
ograniczony do S-wyrażeń podanych jako jej argumenty.
Powiązanie funkcji, letfn
Makro letfn jest wersją formy specjalnej let, które pozwala definiować
funkcje i dokonywać ich leksykalnych powiązań z symbolami w taki sposób, że stają
się one widoczne we wszystkich wyrażeniach inicjujących danego wektora
powiązań (nawet w umieszczonych wcześniej).
W prostych przypadkach możemy użyć let do powiązania symbolu z anonimową
funkcją, a potem tę funkcję wywołać:
(let [x (fn [a] (+ 2 a))]
(x 2))
; => 4
Funkcje możemy też wywoływać w wektorze powiązań, podczas stwarzania powiązań, a więc zwracane wartości traktować jak wyrażenia inicjujące lub ich składniki:
1(let [x (fn [a] (+ 2 a)) ; funkcja x
2 y (fn [a] (+ 3 (x a)))] ; funkcja y korzysta z funkcji x
3 (y 2)) ; wywołanie funkcji y
4
5; => 7
(let [x (fn [a] (+ 2 a)) ; funkcja x
y (fn [a] (+ 3 (x a)))] ; funkcja y korzysta z funkcji x
(y 2)) ; wywołanie funkcji y
; => 7
Spójrzmy jednak co się stanie, gdy w wektorze powiązań odwołamy się do funkcji wcześniej, niż doszło do powiązania jej z symbolem:
1(let [y (fn [a] (+ 3 (x a))) ; funkcja y korzysta z funkcji x
2 x (fn [a] (+ 2 a))] ; funkcja x
3 (y 2)) ; wywołanie funkcji y
4
5; >> java.lang.RuntimeException:
6; >> Unable to resolve symbol: x in this context
(let [y (fn [a] (+ 3 (x a))) ; funkcja y korzysta z funkcji x
x (fn [a] (+ 2 a))] ; funkcja x
(y 2)) ; wywołanie funkcji y
; >> java.lang.RuntimeException:
; >> Unable to resolve symbol: x in this context
Widzimy, że nie jest to możliwe, bo wyrażenia wektora powiązań przetwarzane są
w określonej kolejności. Jednak są pewne dziedziny zastosowań, gdzie musimy odwoływać
się do obiektu funkcji, która dopiero zostanie zdefiniowana (np. w tzw. rekurencji
wzajemnej). W takich przypadkach z pomocą przychodzi letfn.
Użycie:
(letfn wektor-specyfikacji-funkcji & wyrażenie…);
gdzie wektor-specyfikacji-funkcji to:
[(nazwa wektor-parametryczny wyrażenie…)],[(nazwa (wektor-parametryczny wyrażenie…)+)].
Drugi wariant wektora specyfikacji funkcji służy do tworzenia tzw. funkcji wieloczłonowych, które są omówione w rozdziale poświęconym funkcjom.
letfn
(letfn [(y [a] (+ 3 (x a)))
(x [a] (+ 2 a))]
(y 2))
; => 7
Leksykalny zasięg powiązań utworzonych w wektorze powiązań formy letfn jest
ograniczony do wyrażeń inicjujących jej wektora i S-wyrażeń podanych jako jej
argumenty. Zasięg każdego powiązania w wektorze jest obejmuje cały wektor
– w wyrażeniach inicjujących wektora możemy korzystać z każdego umieszczonego w nim
powiązania bez względu na kolejność powstawania.
Zobacz także:
- „Funkcje”, rozdział III.
Powiązanie warunkowe, when-let
Makro when-let jest wersją formy specjalnej let, które wewnętrznie korzysta
z makra when. Umożliwia ono tworzenie jednego powiązania leksykalnego
widocznego w wyrażeniach, które będą wartościowane pod warunkiem, że pochodząca
z wyrażenia inicjującego wartość będzie reprezentowała logiczną prawdę (nie będzie
równa false ani nil).
Pierwszy argument when-let powinien być wektorem powiązań
zawierającym dokładnie jedną parę powiązaniową, a każdy następny
zostanie potraktowany jak wyrażenie, które ma być obliczone i w którym można
korzystać z formy symbolowej odwołującej się do powiązanej w wektorze wartości.
Makro zwraca wartość ostatnio wartościowanego wyrażenia lub nil, gdy nie doszło do
wartościowania, ponieważ warunek prawdy nie został spełniony.
Użycie:
(when-let wektor-powiązań & wyrażenie…).
when-let
1(when-let [a 0] (str "mam " a)) ; => "mam 0"
2(when-let [a 1] (str "mam " a)) ; => "mam 1"
3(when-let [a nil] (str "mam " a)) ; => nil
4(when-let [a false] (str "mam " a)) ; => nil
(when-let [a 0] (str "mam " a)) ; => "mam 0"
(when-let [a 1] (str "mam " a)) ; => "mam 1"
(when-let [a nil] (str "mam " a)) ; => nil
(when-let [a false] (str "mam " a)) ; => nil
Leksykalny zasięg powiązania utworzonego w wektorze powiązań formy when-let
jest ograniczony do S-wyrażeń podanych jako jej argumenty.
Powiązanie 1-go niepustego, when-first
Makro when-first jest wersją makra when-let. Umożliwia tworzenie powiązania
leksykalnego widocznego w wyrażeniach, które będą wartościowane pod warunkiem, że
pochodząca z wyrażenia inicjującego wartość będzie strukturą, którą da się
przekształcić do niepustej sekwencji.
Pierwszy argument when-first powinien być
wektorem powiązań, zawierającym dokładnie jedną
parę powiązaniową, a każdy następny zostanie potraktowany jak wyrażenie, które
ma być obliczone i w którym można korzystać z formy symbolowej odwołującej się
do powiązanej w wektorze wartości. Powiązany zostanie pierwszy element
reprezentowany przez wyrażenie inicjujące.
Makro zwraca wartość ostatnio wartościowanego wyrażenia lub nil, gdy nie doszło do
wartościowania, ponieważ warunek prawdy nie został spełniony.
Użycie:
(when-first wektor-powiązań & wyrażenie…).
when-first
1(when-first [a [0 1 2]] (str "mam " a)) ; => "mam 0"
2(when-first [a [false 2 3]] (str "mam " a)) ; => "mam false"
3(when-first [a [nil 2 3]] (str "mam " a)) ; => "mam "
4(when-first [a "123"] (str "mam " a)) ; => "mam 1"
5(when-first [a nil] (str "mam " a)) ; => nil
6(when-first [a []] (str "mam " a)) ; => nil
7(when-first [a ""] (str "mam " a)) ; => nil
(when-first [a [0 1 2]] (str "mam " a)) ; => "mam 0"
(when-first [a [false 2 3]] (str "mam " a)) ; => "mam false"
(when-first [a [nil 2 3]] (str "mam " a)) ; => "mam "
(when-first [a "123"] (str "mam " a)) ; => "mam 1"
(when-first [a nil] (str "mam " a)) ; => nil
(when-first [a []] (str "mam " a)) ; => nil
(when-first [a ""] (str "mam " a)) ; => nil
Uwaga: Makro when-first wywołuje funkcję seq na wartości wyrażenia
inicjującego (drugim elemencie pary powiązaniowej) i mogą pojawiać się błędy, jeżeli
taka operacja nie jest możliwa (np. podano liczbę całkowitą lub wartość logiczną).
Leksykalny zasięg powiązania utworzonego w wektorze powiązań formy when-first
jest ograniczony do S-wyrażeń podanych jako jej argumenty.
Powiązanie wartościowych, when-some
Makro when-some jest wersją formy specjalnej let, które wewnętrznie korzysta
z makra when. Umożliwia tworzenie jednego powiązania leksykalnego
widocznego w wyrażeniach, które będą wartościowane pod warunkiem, że pochodząca
z wyrażenia inicjującego wartość będzie różna od nil.
Pierwszy argument when-some powinien być
wektorem powiązań, zawierającym dokładnie jedną
parę powiązaniową, a każdy następny zostanie potraktowany jak wyrażenie, które
ma być obliczone i w którym można korzystać z formy symbolowej odwołującej się
do powiązanej w wektorze wartości.
Makro zwraca wartość ostatnio wartościowanego wyrażenia lub nil, gdy nie doszło do
wartościowania, ponieważ warunek nie został spełniony.
Użycie:
(when-some wektor-powiązań & wyrażenie…).
when-some
1(when-some [a 0] (str "mam " a)) ; => "mam 0"
2(when-some [a 1] (str "mam " a)) ; => "mam 1"
3(when-some [a false] (str "mam " a)) ; => "mam false"
4(when-some [a nil] (str "mam " a)) ; => nil
(when-some [a 0] (str "mam " a)) ; => "mam 0"
(when-some [a 1] (str "mam " a)) ; => "mam 1"
(when-some [a false] (str "mam " a)) ; => "mam false"
(when-some [a nil] (str "mam " a)) ; => nil
Leksykalny zasięg powiązania utworzonego w wektorze powiązań formy when-some
jest ograniczony do S-wyrażeń podanych jako jej argumenty.
Powiązanie wartościowych, if-some
Makro if-some jest wersją formy specjalnej let, które wewnętrznie korzysta
z formy specjalnej if. Umożliwia tworzenie jednego powiązania
leksykalnego widocznego w wyrażeniu, które będzie wartościowane pod warunkiem, że
pochodząca z wyrażenia inicjującego wartość będzie różna od nil. Opcjonalnie
można również podać drugie wyrażenie, które zostanie obliczone w przeciwnym razie.
Pierwszy argument if-some powinien być wektorem powiązań,
zawierającym dokładnie jedną parę powiązaniową, a następny (także
obowiązkowy) zostanie potraktowany jak wyrażenie, które ma być obliczone i w którym
można korzystać z formy symbolowej odwołującej się do powiązanej w wektorze wartości,
jeżeli wyrażenie inicjujące nie ma wartości nil. Opcjonalny, trzeci argument
powinien zawierać drugie wyrażenie, które zostanie wykonane, gdy wartością wyrażenia
inicjującego będzie nil. Warto pamiętać, że nie będzie w nim widoczne
powiązanie, ponieważ nie zostanie ono stworzone.
Makro zwraca wartość ostatnio wartościowanego wyrażenia lub nil, gdy nie doszło do
wartościowania, ponieważ warunek nie został spełniony.
Użycie:
(if-some wektor-powiązań wyrażenie-nie-nil & wyrażenie-nil).
if-some
1(if-some [a 0] (str "mam " a)) ; => "mam 0"
2(if-some [a 1] (str "mam " a)) ; => "mam 1"
3(if-some [a false] (str "mam " a)) ; => "mam false"
4(if-some [a nil] (str "mam " a)) ; => nil
5(if-some [a nil] (str "mam " a) "brak") ; => "brak"
(if-some [a 0] (str "mam " a)) ; => "mam 0"
(if-some [a 1] (str "mam " a)) ; => "mam 1"
(if-some [a false] (str "mam " a)) ; => "mam false"
(if-some [a nil] (str "mam " a)) ; => nil
(if-some [a nil] (str "mam " a) "brak") ; => "brak"
Leksykalny zasięg powiązania utworzonego w wektorze powiązań formy
if-some jest ograniczony do S-wyrażeń podanych jako jej argumenty.
Powiązanie w pętli, loop i recur
Forma specjalna loop działa podobnie do let, ale pozwala na
rekurencyjne wykonywanie fragmentu programu. Przyjmuje jeden
obowiązkowy argument, którym powinien być wektor powiązań i zero lub więcej
argumentów będących wyrażeniami, w których można korzystać z powiązań leksykalnych
utworzonych w wektorze. Wartością zwracaną jest wartość ostatnio obliczonego
wyrażenia.
Powiązania używane w wyrażeniach wewnątrz loop mogą być aktualizowane
w wywołaniu recur. Argumenty przekazywane do recur staną się nowymi wartościami
powiązań o odpowiadających im w wektorze pozycjach podczas kolejnego,
rekursywnego wywołania wyrażeń z loop. Dzięki temu możliwa jest
tzw. rekurencja ogonowa, która nie wyczerpuje zasobów pamięciowych stosu.
Użycie:
(loop wektor-powiązań & wyrażenie…).
loop
1(loop [x 1] ; pętla i powiązanie leksykalne
2 (when (< x 10) ; warunek zakończenia rekurencji
3 (println x) ; wyświetlenie; powiązanie widoczne tylko w pętli
4 (recur (inc x)))) ; zmiana powiązania x i skok na początek
(loop [x 1] ; pętla i powiązanie leksykalne
(when (< x 10) ; warunek zakończenia rekurencji
(println x) ; wyświetlenie; powiązanie widoczne tylko w pętli
(recur (inc x)))) ; zmiana powiązania x i skok na początek
Leksykalny zasięg powiązań utworzonych w wektorze powiązań formy loop jest
ograniczony do wyrażeń inicjujących jej wektora (w kolejności ich występowania) oraz
S-wyrażeń podanych jako jej argumenty. Zasięg każdego powiązania w wektorze
rozpoczyna się od miejsca jego utworzenia – w wyrażeniach inicjujących wektora możemy
korzystać z powiązań powstałych na wcześniejszych pozycjach.
Zobacz także:
- „Punkt początkowy”, rozdział XII.
Powiązanie parametryczne
Z leksykalnym zasięgiem spotkamy się również, gdy zdefiniujemy funkcję, która przyjmuje jakieś argumenty. Mówimy wtedy o powiązaniach parametrycznych (ang. parameter bindings), czyli o tworzeniu form powiązaniowych symboli w wektorach parametrycznych funkcji.
1(defn funk [a b] ; definicja funkcji funk; parametry a i b
2 (+ a b)) ; widoczne tylko w ciele funkcji (w granicach S-wyrażenia)
3
4(fn [a b] ; definicja funkcji anonimowej; parametry a i b
5 (+ a b)) ; widoczne tylko w ciele funkcji (w granicach S-wyrażenia)
(defn funk [a b] ; definicja funkcji funk; parametry a i b
(+ a b)) ; widoczne tylko w ciele funkcji (w granicach S-wyrażenia)
(fn [a b] ; definicja funkcji anonimowej; parametry a i b
(+ a b)) ; widoczne tylko w ciele funkcji (w granicach S-wyrażenia)
Leksykalny zasięg powiązań parametrycznych z wartościami przekazywanymi jako argumenty podczas wywołań jest ograniczony do ciała funkcji.
Zmienne lokalne, with-local-vars
Obiekty typu Var możemy w drodze wyjątku objąć lokalnym zasięgiem
leksykalnym. Z tego typu konstrukcji skorzystamy, gdy będziemy chcieli wyrazić jakiś
problem imperatywnie i w związku z tym zajdzie konieczność użycia odpowiednika
lokalnych zmiennych. Służy do tego makro with-local-vars, które dokładniej omówiono
w rozdziale poświęconym obiektom typu Var i zmiennym.
Użycie:
(with-local-vars wektor-powiązań wyrażenie)
with-local-vars
(with-local-vars [a 1] @a)
; => 1
Leksykalny zasięg utworzonych w wektorze powiązań formy with-local-vars jest
ograniczony do S-wyrażeń podanych jako jej argumenty. Próba odwołania się w wyrażeniu
inicjującym wektora do zmiennej powiązanej z symbolem na wcześniejszej pozycji tego
samego wektora zakończy się zgłoszeniem wyjątku.
Zobacz także:
- „Zmienne lokalne”, rozdział VII.
Powiązanie wejścia/wyjścia, with-open
Makro with-open pozwala wytworzyć leksykalny zasięg dla powiązań w podobny sposób
do let. Również powstaną powiązania leksykalne, których zasięg będzie
ograniczony do S-wyrażeń podanych jako przekazane argumenty, ale wszystkie wartości
inicjujące powiązań po przeliczeniu muszą być obiektami Javy, dla których można
wywołać metodę close().
Użycie:
(with-open wektor-powiązań & wyrażenie…),
gdzie wektor-powiązań to:
[forma-powiązaniowa-symbolu wyrażenie-inicjujące …].
Pierwszym argumentem, jaki należy przekazać konstrukcji with-open, jest wektor
powiązań (ang. binding vector). Jest to wektorowe S-wyrażenie, które powinno składać się z tzw. par powiązaniowych (ang. binding
pairs).
Pierwsze elementy tych par powinny być formami powiązaniowymi symboli (a nie jak w przypadku let dowolnymi formami powiązaniowymi),
a drugie tzw. wyrażeniami inicjującymi (ang. initialization expressions), które
zostaną przeliczone do wartości stałych.
with-open
(with-open [czytnik (clojure.java.io/reader "plik.txt")]
(doall (line-seq czytnik)))
W wyrażeniach inicjujących możemy odwoływać się do symboli, które zostały powiązane z wartościami na wcześniejszych pozycjach wektora powiązaniowego.
Kolejne, opcjonalne argumenty with-open to S-wyrażenia do przeliczenia,
w których można korzystać z powiązanych wcześniej symboli. Gdy dany symbol zostanie
podany, jego forma symbolowa zostanie przeliczona do wartości.
Podobnie jak w formie let mamy do czynienia z lokalnymi powiązaniami służącymi
do identyfikacji przypisanych wartości. Wszystkie te wartości muszą być obiektami
Javy, dla których da się wywołać metodę close(). Makro wywoła ją w bloku finally,
a więc niezależnie od tego, czy ewaluacja wyrażeń powiedzie się, czy też nie. Dzięki
temu ewentualne uchwyty otwartych plików, gniazd czy może nawet obiektów łączności
z bazami danych, zostaną zamknięte po ewaluacji wyrażeń przekazanych do makra.
Zasięg dynamiczny
Zasięg dynamiczny w Clojure to zasięg, w którym mamy do czynienia z przesłanianiem wartości istniejących powiązań zmiennych globalnych (o zasięgu nieograniczonym) przez utrzymywanie dla każdej z nich globalnego stosu powiązań. Dzieje się to niezależnie od kontekstu leksykalnego i wymaga użycia specjalnej formy.
Stos powiązań to struktura, której zadaniem jest obsługa przesłaniania wartości bieżącej zmiennej globalnej w pewnym kontekście wykonywania ograniczonym czasem.
Jeżeli istnieje zmienna globalna, dla której w pewnym momencie tworzony jest przez
programistę zasięg dynamiczny, wtedy na stosie przypisanym do tej zmiennej jest
umieszczane jej nowe powiązanie z wartością. Będzie ono ze stosu zdjęte dopiero
wtedy, gdy zakończone zostanie obliczanie wyrażenia, w którym ustanowiono dynamiczne
powiązanie (w przypadku Clojure ciało makra binding, które omówione
zostanie dalej).
Jeżeli podczas wykonywania się programu, w którym mamy zmienną globalną o dynamicznym zasięgu, pojawia się kolejne jej przesłonięcie (spowodowane wprowadzeniem nowego dynamicznego zasięgu), powiązanie znów wędruje na skojarzony z daną zmienną stos.
Każde odwołanie do zmiennej globalnej, dla której istnieje niepusty stos powiązań dynamicznych, skutkuje zwróceniem wartości, do której odnosi się ostatnie (najbardziej aktualne) powiązanie na tym stosie. Dzieje się to niezależnie od kontekstu leksykalnego. Powiązanie dynamiczne możemy więc nazwać powiązaniem, które trwa pewien czas, w przeciwieństwie do powiązań leksykalnych, które obejmują pewne obszary kodu źródłowego.
Gdy na stosie nie ma żadnego powiązania dynamicznego, to używane jest tzw. powiązanie główne zmiennej globalnej.
Powiązania dynamiczne zmiennych globalnych realizowane są przez przesłanianie
wartości w powiązaniach obiektów referencyjnych typu Var reprezentujących te
zmienne, a nie przez przesłanianie odwzorowań symboli w przestrzeniach nazw. Poza tym
dynamiczne przesłonięcia zmiennych globalnych dokonywane są zawsze w bieżącym
wątku wykonywania. Jeżeli w pozostałych wątkach nie utworzono dynamicznego
powiązania (z użyciem konstrukcji binding), zmienna zachowa w nich aktualne
powiązanie główne z wartością.
Tworzenie powiązań dynamicznych
Do tworzenia powiązań o zasięgu dynamicznym służy makro binding, które dokładniej
omówione jest w rozdziale VII. Poniżej znajdziemy przykład użycia, który
udowadnia przy okazji, że powiązania tego typu utrzymywane są w obiektach
referencyjnych, a nie w przestrzeniach nazw:
1(def ^:dynamic *x* 5) ; zmienna dynamiczna *x*
2
3(def obiekt-x ; zmienna globalna obiekt-x
4 (var *x*)) ; wskazuje na obiekt Var zmiennej *x*
5
6(defn chwal-się [] ; wyświetla wartość *x*
7 (println " *x* po nazwie:"
8 *x* "\n" ; odczyt powiązanej wartości
9 "*x* po obiekcie:"
10 @obiekt-x "\n")) ; dereferencja obiektu
11
12(defn testuj [] ; funkcja testująca
13 (binding [*x* 10] ; zasięg dynamiczny *x*
14 (println "* zasięg dynamiczny")
15 (chwal-się)) ; wywołanie funkcji w zasięgu
16 (println "* zasięg nieograniczony:") ; dynamicznym
17 (chwal-się)) ; wywołanie funkcji poza
18 ; dynamicznym zasięgiem
19(testuj)
(def ^:dynamic *x* 5) ; zmienna dynamiczna *x*
(def obiekt-x ; zmienna globalna obiekt-x
(var *x*)) ; wskazuje na obiekt Var zmiennej *x*
(defn chwal-się [] ; wyświetla wartość *x*
(println " *x* po nazwie:"
*x* "\n" ; odczyt powiązanej wartości
"*x* po obiekcie:"
@obiekt-x "\n")) ; dereferencja obiektu
(defn testuj [] ; funkcja testująca
(binding [*x* 10] ; zasięg dynamiczny *x*
(println "* zasięg dynamiczny")
(chwal-się)) ; wywołanie funkcji w zasięgu
(println "* zasięg nieograniczony:") ; dynamicznym
(chwal-się)) ; wywołanie funkcji poza
; dynamicznym zasięgiem
(testuj)
Zobacz także:
- „Zmienne dynamiczne”, rozdział VII.
Dekompozycja
Dekompozycja (ang. decomposition), zwana też destrukturyzacją (ang. destructuring) jest mechanizmem tworzenia powiązań wartości z symbolami, w którym wartości te pochodzą ze struktur złożonych z wielu elementów, a do przypisywania wybranych z nich do konkretnych symboli używa się specyficznej składni zamiast wywoływać funkcje czy makra.
Z dekompozycji możemy korzystać w wektorze powiązań formy
specjalnej let i pochodnych,
wektorze parametrycznym formy fn oraz makra
defn, a także w konstrukcjach, które korzystają z wymienionych
(np. for czy doall). Zamiast form powiązaniowych symboli
pierwszymi elementami każdej z par powiązaniowych będą wtedy formy powiązaniowe
wektorów, formy powiązaniowe map, albo nawet ich kombinacje.
Aby zademonstrować korzyści ze stosowania destrukturyzacji, spójrzmy na prosty przykład, w którym najpierw dokonujemy powiązania elementów wektora z symbolami (korzystając z funkcji operujących na wektorze), a następnie używamy w tym celu celu dekompozycji.
1(def dane [1 2 3]) ; wektor z trzema wartościami
2
3;; ręczne powiązywanie wybranych elementów z symbolami
4
5(let [a (first dane)
6 b (first (rest dane))
7 c (first (rest (rest dane)))]
8 (list a b c))
9; => (1 2 3)
10
11;; dekompozycja
12
13(let [[a b c] dane] (list a b c))
14; => (1 2 3)
(def dane [1 2 3]) ; wektor z trzema wartościami
;; ręczne powiązywanie wybranych elementów z symbolami
(let [a (first dane)
b (first (rest dane))
c (first (rest (rest dane)))]
(list a b c))
; => (1 2 3)
;; dekompozycja
(let [[a b c] dane] (list a b c))
; => (1 2 3)
W przedostatniej linii widzimy, że zamiast pojedynczego symbolu użyliśmy wektorowego
S-wyrażenia zawierającego listę symboli, które zostały powiązane z odpowiadającymi im
pozycyjnie wartościami wektora o nazwie dane.
Dekompozycja jest rodzajem powiązywania symboli z wartościami. Również mamy do czynienia z parami powiązaniowymi przy czym:
-
w miejscu pojedynczego symbolu pojawia się (zawierające różne symbole) wyrażenie powiązaniowe (wektorowe wyrażenie powiązaniowe lub mapowe wyrażenie powiązaniowe), czyli forma powiązaniowa wektora lub mapy;
-
wartością przypisanego wyrażenia inicjującego jest wieloelementowa struktura (np. wektor, mapa, lista, rekord itp.).
let
1(let [ ; wektor powiązań:
2 ; · pierwsza para:
3 dane ; · symbol (forma powiązaniowa symbolu)
4 [1 2 3] ; · wyrażenie inicjujące (forma wektorowa)
5 ; · druga para:
6 [a b c] ; · wektorowe wyrażenie powiązaniowe (forma powiązaniowa wektora)
7 dane] ; · wyrażenie inicjujące (forma symbolowa)
8 (list a b c))
(let [ ; wektor powiązań:
; · pierwsza para:
dane ; · symbol (forma powiązaniowa symbolu)
[1 2 3] ; · wyrażenie inicjujące (forma wektorowa)
; · druga para:
[a b c] ; · wektorowe wyrażenie powiązaniowe (forma powiązaniowa wektora)
dane] ; · wyrażenie inicjujące (forma symbolowa)
(list a b c))
Dekompozycja pozycyjna
Dekompozycja pozycyjna (ang. positional decomposition), zwana też destrukturyzacją pozycyjną (ang. positional destructuring) umożliwia tworzenie powiązań symboli z wartościami wybranych elementów struktur o sekwencyjnym interfejsie dostępu (np. wektorów, list czy nawet łańcuchów znakowych). Przypomina korzystanie z wzorców dopasowania i polega na kojarzeniu podanych w pewnym porządku symboli z odpowiadającymi im pozycyjnie elementami struktury podanej w wyrażeniu inicjującym.
Dekompozycji pozycyjnej możemy używać zarówno w wektorach powiązań form
specjalnych (takich jak np. let czy binding), jak również
w wektorach parametrycznych definicji funkcji.
Tak naprawdę możemy destrukturyzować nie tylko sekwencje, lecz dowolne kolekcje,
na których da się operować funkcją nth.
Wektorowa forma powiązaniowa
Korzystanie z dekompozycji pozycyjnej wymaga umieszczenia wektorowego wyrażenia powiązaniowego (ang. vector binding expression) w miejscu, w którym zwykle podajemy pojedynczy symbol (jako pierwszy element pary powiązaniowej). Powinno to być wektorowe S-wyrażenie zawierające formy powiązaniowe (np. niezacytowane symbole), których pozycje odpowiadają pozycjom elementów ze źródłowej struktury (podanej jako wyrażenie inicjujące).
Użycie:
[[symbol…] wyrażenie-inicjujące].
let
1(let [[a b c] [1 2 3]] ; a -> 1, b -> 2, c -> 3
2 (list a b c))
3; => (1 2 3)
4
5(let
6 [wektor [4 5 6] ; powiązanie z wektorem
7 sekwencja (seq wektor) ; powiązanie z sekwencją na bazie wektora
8 [a b c] [1 2 3] ; powiązania z dekompozycji wyrażenia wektorowego
9 [d e f] wektor ; powiązania z dekompozycji wektora
10 [g ] sekwencja] ; powiązania z dekompozycji sekwencji
11
12 (list a b c d e f g)) ; utworzenie listy z wartościami powiązań
13; => (1 2 3 4 5 6 4)
(let [[a b c] [1 2 3]] ; a -> 1, b -> 2, c -> 3
(list a b c))
; => (1 2 3)
(let
[wektor [4 5 6] ; powiązanie z wektorem
sekwencja (seq wektor) ; powiązanie z sekwencją na bazie wektora
[a b c] [1 2 3] ; powiązania z dekompozycji wyrażenia wektorowego
[d e f] wektor ; powiązania z dekompozycji wektora
[g ] sekwencja] ; powiązania z dekompozycji sekwencji
(list a b c d e f g)) ; utworzenie listy z wartościami powiązań
; => (1 2 3 4 5 6 4)
W przypadku wektorów parametrycznych, z którymi mamy do czynienia np. w definicjach funkcji, wyrażeniem inicjującym będzie zestaw przekazywanych argumentów.
(defn funkcja [a b c]
(list a b c))
(funkcja 1 2 3)
; => (1 2 3)
Ignorowanie elementów
Zauważmy, że w linii nr 9 przedostatniego przykładu podajemy tylko jeden symbol
(g), natomiast sekwencja źródłowa zawiera trzy wartości (4, 5, 6). Zgodnie
z oczekiwaniami powiązana z symbolem zostanie pierwsza z nich. Jednak czy istnieje
możliwość, aby pobrać tylko wybraną, ignorując pozostałe? Z pomocą przychodzi tu
symbol _, który oznacza, że element o odpowiadającej mu pozycji powinien być
zignorowany.
Użycie:
[[… _…] wyrażenie-inicjujące].
_ w dekompozycji pozycyjnej
(let [[_ b _] [1 2 3]] ; powiązania z dekompozycji
b) ; wartościowanie formy symbolowej
; => 2
Warto wiedzieć, że symbol _ ma specjalne znaczenie tylko na zasadzie
konwencji. W jego miejsce można podać dowolny inny symbol, który nie będzie używany,
a jego wartość może zostać wielokrotnie przesłonięta bez uszczerbku na logice
aplikacji.
Grupowanie elementów
Ciekawym przypadkiem jest grupowanie wszystkich pozostałych, nieprzypisanych pozycyjnie wartości w jednym, wariadycznym powiązaniu. Służy do tego symbol ampersandu umieszczony przed nazwą symbolu.
Użycie:
[[… & symbol] wyrażenie-inicjujące].
& w dekompozycji pozycyjnej
1(let [[_ & reszta] [1 2 3]] ; powiązania z dekompozycji
2 reszta) ; wartościowanie formy symbolowej
3; => (2 3)
(let [[_ & reszta] [1 2 3]] ; powiązania z dekompozycji
reszta) ; wartościowanie formy symbolowej
; => (2 3)
Dostęp do oryginalnej sekwencji
Może zdarzyć się tak, że pomimo dekompozycji będziemy potrzebowali dostępu do
oryginalnie przekazywanej struktury danych wyrażenia inicjującego. Z pomocą
przychodzi tu dyrektywa :as, która powinna być umieszczona w wyrażeniu
destrukturyzacyjnym. Tuż za nią powinien znajdować się niezacytowany symbol, z którym
struktura powinna być powiązana.
Użycie:
[[… :as symbol] wyrażenie-inicjujące].
:as w dekompozycji pozycyjnej
1(let [[a b c :as wszystko] [1 2 3]] ; powiązania z dekompozycji
2 wszystko) ; wartościowanie formy symbolowej
3; => [1 2 3]
(let [[a b c :as wszystko] [1 2 3]] ; powiązania z dekompozycji
wszystko) ; wartościowanie formy symbolowej
; => [1 2 3]
Dyrektywa :as i przypisany do niej symbol powinny być podane jako ostatnia
para w wektorze dekompozycyjnym.
Dekompozycja asocjacyjna
Dekompozycja asocjacyjna (ang. associative decomposition), zwana też destrukturyzacją asocjacyjną (ang. associative destructuring) umożliwia tworzenie powiązań symboli z wartościami pochodzącymi z wybranych elementów struktur o asocjacyjnym interfejsie dostępu (np. map czy rekordów).
Dekompozycji asocjacyjnej możemy używać zarówno w wektorach powiązań
(np. formy specjalnej let czy makra binding), jak również
w wektorach parametrycznych definicji funkcji.
Mapowa forma powiązaniowa
Struktury asocjacyjne (np. mapy) wyrażają relację klucz–wartość, a ich dekompozycja polega na określeniu kluczy, pod którymi znaleźć można wartości powiązywane z podanymi symbolami.
Do wyrażania tej operacji służy mapowe wyrażenie powiązaniowe (ang. map binding expression), które skrótowo można nazywać mapą powiązaniową (ang. binding map). Jest to mapowe S-wyrażenie, które należy umieścić jako pierwszy element każdej pary powiązaniowej w wektorze powiązań lub zamiast pojedynczego parametru w wektorze parametrycznym funkcji. Kluczami mapy mogą być formy powiązaniowe (np. symboli, map czy wektorów), a wartościami klucze źródłowej struktury, pod którymi odnajdziemy właściwe wartości inicjujące lub dalsze struktury.
Źródłową strukturą, z której pobierane będą wartości w celu ich powiązania z symbolami lub dalszego destrukturyzowania, będzie mapowe wyrażenie inicjujące podane jako drugi element każdej pary powiązaniowej.
Użycie:
[{symbol klucz …} wyrażenie-inicjujące].
1;; W E K T O R P O W I Ą Z A Ń (składający się z par)
2;; mapa powiązaniowa wyrażenie inicjujące (pary powiązaniowe)
3
4(let [ {a :a b :b c :c} {:a 1, :b 2, :c 3} ]
5 (list a b c))
6; => (1 2 3)
;; W E K T O R P O W I Ą Z A Ń (składający się z par)
;; mapa powiązaniowa wyrażenie inicjujące (pary powiązaniowe)
(let [ {a :a b :b c :c} {:a 1, :b 2, :c 3} ]
(list a b c))
; => (1 2 3)
Specyfikatorami kluczy mogą być również inne wartości, nie tylko słowa kluczowe.
(let [{a 'a b 'b c 'c} '{a 1, b 2, c 3}]
(list a b c))
; => (1 2 3)
Zauważmy, że w powyższym przykładzie zastosowaliśmy cytowanie mapowego S-wyrażenia, aby nie musieć z osobna cytować każdego podanego w nim symbolu.
W przypadku wektorów parametrycznych funkcji wyrażenie inicjujące pochodzi z przekazywanych do funkcji argumentów, a kluczami są ich symboliczne nazwy.
1;; WEKTOR PARAMETRYCZNY
2;; mapa powiązaniowa
3
4(defn funkcja [ & {a :a, b :b, c :c} ]
5 (list a b c))
6
7;; argumenty (wyrażenie inicjujące)
8
9(funkcja :a 1, :b 2, :c 3)
10; => (1 2 3)
;; WEKTOR PARAMETRYCZNY
;; mapa powiązaniowa
(defn funkcja [ & {a :a, b :b, c :c} ]
(list a b c))
;; argumenty (wyrażenie inicjujące)
(funkcja :a 1, :b 2, :c 3)
; => (1 2 3)
Klucze mapy powiązaniowej
Jeżeli nazwy symboli, z którymi będą powiązywane wartości pochodzące z podanej
struktury asocjacyjnej, mają być takie same jak nazwy kluczy w tej mapie, to
możemy skorzystać z dyrektywy :keys. Pozwala ona uniknąć powtórzeń i uczytelnia
kod.
W mapie powiązaniowej należy podać parę, której kluczem jest słowo kluczowe :keys,
a przypisaną wartością wektorowe S-wyrażenie zawierające niezacytowane symbole lub
słowa kluczowe określające klucze dekomponowanej struktury, których wartości chcemy
powiązać z symbolami o takich samych nazwach.
Użycie:
[{:keys [klucz…]} wyrażenie-inicjujące].
:keys
1(let [{:keys [:a :b :c]} {:a 1, :b 2, :c 3}]
2 (list a b c))
3; => (1 2 3)
4
5(let [{:keys [a b c]} {:a 1, :b 2, :c 3}]
6 (list a b c))
7; => (1 2 3)
(let [{:keys [:a :b :c]} {:a 1, :b 2, :c 3}]
(list a b c))
; => (1 2 3)
(let [{:keys [a b c]} {:a 1, :b 2, :c 3}]
(list a b c))
; => (1 2 3)
Kluczami dekomponowanej struktury inicjującej mogą być również łańcuchy znakowe
lub symbole. W takich przypadkach można zamiast z :keys użyć dyrektywy :strs
albo :syms. W obydwu przypadkach, specyfikując nazwy, należy skorzystać
z niezacytowanych symboli.
Użycie:
[{:strs [klucz…]} wyrażenie-inicjujące],[{:syms [klucz…]} wyrażenie-inicjujące].
:strs i :syms
1(let [{:strs [a b c]} {"a" 1, "b" 2, "c" 3}]
2 (list a b c))
3; => (1 2 3)
4
5(let [{:syms [a b c]} '{a 1, b 2, c 3}]
6 (list a b c))
7; => (1 2 3)
(let [{:strs [a b c]} {"a" 1, "b" 2, "c" 3}]
(list a b c))
; => (1 2 3)
(let [{:syms [a b c]} '{a 1, b 2, c 3}]
(list a b c))
; => (1 2 3)
Dostęp do oryginalnej asocjacji
Może zdarzyć się, że pomimo dekompozycji będziemy potrzebowali dostępu do oryginalnie
przekazywanej struktury danych. Podobnie jak w przypadku dekompozycji pozycyjnej
z pomocą przychodzi tu dyrektywa :as. Powinna ona być umieszczona w mapie
powiązaniowej, a przypisaną do niej wartością musi być niezacytowany symbol, z którym
powiązana zostanie struktura wyrażenia inicjującego.
Użycie:
[{:as symbol} wyrażenie-inicjujące].
:as w dekompozycji asocjacyjnej
1(let [{:keys [a b c]
2 :as wszystko} [1 2 3]] ; powiązania z dekompozycji
3 wszystko) ; wartościowanie formy symbolowej
4; => [1 2 3]
(let [{:keys [a b c]
:as wszystko} [1 2 3]] ; powiązania z dekompozycji
wszystko) ; wartościowanie formy symbolowej
; => [1 2 3]
Dyrektywa :as i przypisany do niej symbol powinny być podane jako ostatnia para
w wektorze dekompozycyjnym.
Wartości domyślne
W mapie powiązaniowej możemy określać wartości domyślne, które zostaną powiązane
z symbolami, jeżeli w źródłowej strukturze nie odnaleziono podanych kluczy. Służy do
tego dyrektywa :or.
Po słowie kluczowym :or należy podać mapę określającą domyślne wartości dla
kluczy.
Użycie:
[{:or {klucz wartość …}} wyrażenie-inicjujące].
:or
(let [{:keys [:a :b :c]
:or {:a 1, :c 3}} {:b 2}]
(list a b c))
; => (1 2 3)
Dekompozycja asocjacyjna wektorów
Istnieje możliwość zastosowania dekompozycji asocjacyjnej w odniesieniu do wektorów. W mapie powiązaniowej zamiast kluczy należy wtedy podać pozycje elementów źródłowej struktury sekwencyjnej wyrażone liczbami całkowitymi.
Użycie:
[{symbol pozycja …} wyrażenie-inicjujące].
1(let [{a 0 b 1 c 2} ["pierwszy" "drugi" "trzeci"]]
2 (list a b c))
3; => ("pierwszy" "drugi" "trzeci")
(let [{a 0 b 1 c 2} ["pierwszy" "drugi" "trzeci"]]
(list a b c))
; => ("pierwszy" "drugi" "trzeci")
Wekotory jako klucze w dekompozycji
Ciekawym przykładem dekompozycji asocjacyjnej może być mapa powiązaniowe, w której kluczami są wektory.
(let [{[a b c] :litery} {:litery [1 2 3]}]
(list a b c))
; => (1 2 3)
Widzimy, że wartością wektorowego klucza w mapowej formie powiązaniowej jest słowo
kluczowe (:litery), które będzie następnie odszukane w mapowym wyrażeniu
inicjującym, a w stosunku do znalezionej wartości przeprowadzona zostanie
dekompozycja pozycyjna. Ten rodzaj destrukturyzacji jest prostym przykładem
możliwości stosowania zagnieżdżonych struktur w formach dekompozycyjnych.
Struktury zagnieżdżone
Dekompozycja struktur zagnieżdżonych możliwa jest dzięki składni pozwalającej zagnieżdżać mapowe i wektorowe wyrażenia powiązaniowe.
1(def dane-osobowe
2 {:imię "Paweł"
3 :nazwisko "Wilk"
4 :płeć :m
5 :kontakty {:telefony [123456, 543210]
6 :e-maile ["pw-at-gnu.org"]}})
7
8(let [{:keys [imię nazwisko płeć], {[telefon] :telefony
9 [e-mail] :e-maile} :kontakty}
10 dane-osobowe
11 nazwa-płci (if (= płeć :m) "mężczyzna" "kobieta")]
12 (println "Imię i nazwisko: " imię nazwisko)
13 (println "Płeć: " nazwa-płci)
14 (println "Telefon: " telefon)
15 (println "E-mail: " e-mail))
(def dane-osobowe
{:imię "Paweł"
:nazwisko "Wilk"
:płeć :m
:kontakty {:telefony [123456, 543210]
:e-maile ["pw-at-gnu.org"]}})
(let [{:keys [imię nazwisko płeć], {[telefon] :telefony
[e-mail] :e-maile} :kontakty}
dane-osobowe
nazwa-płci (if (= płeć :m) "mężczyzna" "kobieta")]
(println "Imię i nazwisko: " imię nazwisko)
(println "Płeć: " nazwa-płci)
(println "Telefon: " telefon)
(println "E-mail: " e-mail))
Efektem działania powyższego przykładu będzie wyświetlenie następujących linii tekstu:
Imię i nazwisko: Paweł Wilk
Płeć: mężczyzna
Telefon: 123456
E-mail: pw-at-gnu.org
Zbadajmy poszczególne fragmenty wektora powiązań, aby lepiej zrozumieć, z jakimi operacjami mieliśmy do czynienia. Mamy w nim dwie pary powiązaniowe:
- Mapa powiązaniowa, w której zachodzi dekompozycja i przypisane do niej
wyrażenie inicjujące, którym jest forma symbolowa (
dane-osobowe) reprezentująca zagnieżdżoną mapę z danymi osobowymi:
{:keys [imię nazwisko płeć], {[telefon] :telefony
[e-mail] :e-maile} :kontakty}
dane-osobowe
- Forma powiązaniowa symbolu (
nazwa-płci) i przypisane jej wyrażenie inicjujące, którym jest forma specjalnaif(w zależności od wartości powiązanej z symbolempłećemituje odpowiedni łańcuch tekstowy):
1nazwa-płci (if (= płeć :m) "mężczyzna" "kobieta")
nazwa-płci (if (= płeć :m) "mężczyzna" "kobieta")
Druga para nie ma znaczenia dla destrukturyzacji, więc nie będziemy jej dalej omawiać. Przyjrzymy się za to bliżej parze pierwszej, gdzie mamy do czynienia z mapą powiązaniową złożoną z dwóch elementów (dwóch par typu klucz–wartość):
- Dyrektywa
:keyspowiązująca z odpowiednimi symbolami wartości kluczy:imię,:nazwiskoi:płeć(z mapy identyfikowanej symbolemdane-osobowe):
1:keys [imię nazwisko płeć]
:keys [imię nazwisko płeć]
- Mapa powiązaniowa, która dokonuje dekompozycji struktury identyfikowanej
kluczem
:kontaktyz mapydane-osobowe:
{[telefon] :telefony
[e-mail] :e-maile}
:kontakty
Widzimy, że mapa powiązaniowa nie zawiera prostych form powiązaniowych (wyrażonych
niezacytowanymi symbolami), lecz dwa wektorowe wyrażenia powiązaniowe, które są
kolejnym poziomem destrukturyzacji. Mamy do czynienia z dekompozycją pozycyjną,
a dokładniej z przypisaniem symbolowi telefon pierwszego elementu struktury
identyfikowanej kluczem :telefony oraz symbolowi e-mail pierwszego elementu
struktury identyfikowanej kluczem :e-maile. Obie te struktury (wektor zawierający
numery telefonów i wektor zawierający adresy e-mailowe) powinny być elementami mapy
identyfikowanej kluczem :kontakty w strukturze nadrzędnej.
Klucze w pełni kwalifikowane
W Clojure od wersji 1.6 możemy korzystać z kluczy i symboli o dookreślonych przestrzeniach nazw.
1(def dane-osobowe
2 {:imię "Paweł"
3 :kontakty/telefony [123456, 543210]
4 :kontakty/e-maile ["pw-at-gnu.org"]})
5
6(let [{:keys [imię],
7 [telefon] :kontakty/telefony,
8 [e-mail] :kontakty/e-maile} dane-osobowe]
9 (println "Imię: " imię)
10 (println "Telefon:" telefon)
11 (println "E-mail: " e-mail))
12
13(let [{:keys [imię kontakty/telefony kontakty/e-maile]} dane-osobowe]
14 (println "Imię: " imię)
15 (println "Telefony:" telefony)
16 (println "E-maile: " e-maile))
(def dane-osobowe
{:imię "Paweł"
:kontakty/telefony [123456, 543210]
:kontakty/e-maile ["pw-at-gnu.org"]})
(let [{:keys [imię],
[telefon] :kontakty/telefony,
[e-mail] :kontakty/e-maile} dane-osobowe]
(println "Imię: " imię)
(println "Telefon:" telefon)
(println "E-mail: " e-mail))
(let [{:keys [imię kontakty/telefony kontakty/e-maile]} dane-osobowe]
(println "Imię: " imię)
(println "Telefony:" telefony)
(println "E-maile: " e-maile))
1(ns user)
2(def dane-osobowe
3 {:imię "Paweł"
4 ::telefony [123456, 543210]
5 ::e-maile ["pw-at-gnu.org"]})
6
7(let [{:keys [imię ::telefony user/e-maile]} dane-osobowe]
8 (println "Imię: " imię)
9 (println "Telefony:" telefony)
10 (println "E-maile: " e-maile))
(ns user)
(def dane-osobowe
{:imię "Paweł"
::telefony [123456, 543210]
::e-maile ["pw-at-gnu.org"]})
(let [{:keys [imię ::telefony user/e-maile]} dane-osobowe]
(println "Imię: " imię)
(println "Telefony:" telefony)
(println "E-maile: " e-maile))
1(def dane-osobowe
2 {'imię "Paweł"
3 'kontakty/telefony [123456, 543210]
4 'kontakty/e-maile ["pw-at-gnu.org"]})
5
6(let [{:syms [imię],
7 [telefon] 'kontakty/telefony,
8 [e-mail] 'kontakty/e-maile} dane-osobowe]
9 (println "Imię: " imię)
10 (println "Telefon:" telefon)
11 (println "E-mail: " e-mail))
(def dane-osobowe
{'imię "Paweł"
'kontakty/telefony [123456, 543210]
'kontakty/e-maile ["pw-at-gnu.org"]})
(let [{:syms [imię],
[telefon] 'kontakty/telefony,
[e-mail] 'kontakty/e-maile} dane-osobowe]
(println "Imię: " imię)
(println "Telefon:" telefon)
(println "E-mail: " e-mail))
W powyższym przykładzie symbole o dookreślonych przestrzeniach nazw zostały zacytowane w mapie powiązaniowej, ponieważ w przeciwnym wypadku byłyby potraktowane jak formy symbolowe.
Diagnozowanie dekompozycji
Destrukturyzacja skomplikowanych kolekcji danych może być obarczona ryzykiem pomyłki. W takich przypadkach warto korzystać ze sposobów, które umożliwiają podgląd procesu dekompozycji.
Dekompozycja do tekstu, destructure
Dzięki funkcji destructure możemy obserwować, jaki efekt będzie miała dekompozycja
podanych struktur.
Użycie:
(destructure powiązania).
Funkcja przyjmuje jeden obowiązkowy argument, którym powinien być wektor powiązań w forme stałej.
Wartością zwracaną jest wektor powiązań, w którym zawarte są reprezentacje S-wyrażeń używane w procesie destrukturyzacji (formy stałe).
destructure
1(def dane-osobowe
2 {'imię "Paweł"
3 'kontakty/telefony [123456, 543210]
4 'kontakty/e-maile ["pw-at-gnu.org"]})
5
6(destructure '[{:syms
7 [imię],
8 [telefon] 'kontakty/telefony,
9 [e-mail] 'kontakty/e-maile} dane-osobowe])
10
11; => [map__10728
12; => dane-osobowe
13; => map__10728
14; => (if
15; => (clojure.core/seq? map__10728)
16; => (clojure.lang.PersistentHashMap/create
17; => (clojure.core/seq map__10728))
18; => map__10728)
19; => vec__10729
20; => (clojure.core/get map__10728 (quote kontakty/telefony))
21; => telefon
22; => (clojure.core/nth vec__10729 0 nil)
23; => vec__10730
24; => (clojure.core/get map__10728 (quote kontakty/e-maile))
25; => e-mail
26; => (clojure.core/nth vec__10730 0 nil)
27; => imię
28; => (clojure.core/get map__10728 (quote imię))]
(def dane-osobowe
{'imię "Paweł"
'kontakty/telefony [123456, 543210]
'kontakty/e-maile ["pw-at-gnu.org"]})
(destructure '[{:syms
[imię],
[telefon] 'kontakty/telefony,
[e-mail] 'kontakty/e-maile} dane-osobowe])
; => [map__10728
; => dane-osobowe
; => map__10728
; => (if
; => (clojure.core/seq? map__10728)
; => (clojure.lang.PersistentHashMap/create
; => (clojure.core/seq map__10728))
; => map__10728)
; => vec__10729
; => (clojure.core/get map__10728 (quote kontakty/telefony))
; => telefon
; => (clojure.core/nth vec__10729 0 nil)
; => vec__10730
; => (clojure.core/get map__10728 (quote kontakty/e-maile))
; => e-mail
; => (clojure.core/nth vec__10730 0 nil)
; => imię
; => (clojure.core/get map__10728 (quote imię))]
Rezultat możemy uczytelnić i przedstawić jako kod:
1(let [mapa-danych dane-osobowe
2 mapa-danych (if (seq? mapa-danych)
3 (apply hash-map (seq mapa-danych))
4 mapa-danych)
5 wektor-telefonów (get mapa-danych 'kontakty/telefony)
6 wektor-e-maili (get mapa-danych 'kontakty/e-maile)
7 imię (get mapa-danych 'imię)
8 telefon (nth wektor-telefonów 0 nil)
9 e-mail (nth wektor-e-maili 0 nil)]
10 {:imię imię
11 :telefon telefon
12 :e-mail e-mail})
13
14; => {:e-mail "pw-at-gnu.org" :imię "Paweł" :telefon 123456}
(let [mapa-danych dane-osobowe
mapa-danych (if (seq? mapa-danych)
(apply hash-map (seq mapa-danych))
mapa-danych)
wektor-telefonów (get mapa-danych 'kontakty/telefony)
wektor-e-maili (get mapa-danych 'kontakty/e-maile)
imię (get mapa-danych 'imię)
telefon (nth wektor-telefonów 0 nil)
e-mail (nth wektor-e-maili 0 nil)]
{:imię imię
:telefon telefon
:e-mail e-mail})
; => {:e-mail "pw-at-gnu.org" :imię "Paweł" :telefon 123456}